Delta Live Tables の一般提供開始を発表

Databricks は本日、Delta Live Tables(DLT)の Amazon AWS と Microsoft Azure クラウドにおける一般公開、および Google Cloud におけるパブリックプレビューの提供開始を発表しました。このブログでは、DLT が大手企業のデータエンジニアやア��ナリストをどのように支援し、本番環境に対応したストリーミングとバッチパイプラインの簡単な構築や、大規模なインフラストラクチャの自動管理、および、新世代のデータ、分析、AI アプリケーションの提供に役立つかについて解説します。
レイクハウスにおけるシンプルなストリーミングとバッチ ETL
ETL(抽出・変換・ロード)に対するストリーミング、バッチワークロードの処理は、分析、データサイエンス、機械学習ワークロードの基本的な取り組みです。企業が生み出す膨大なデータ量がこの傾向を加速させています。しかし、未加工の構造化されていないデータを、クリーンで文書化された信頼のおける情報に処理することは、ビジネスの知見を推進するために使用する前の重要なステップです。SQL クエリを本番の ETL パイプラインに変換するには、通常、面倒で複雑な運用作業が多く含まれることをお客様から学びました。小規模なケースにおいても、データエンジニアの時間の大部分は、データの変換よりもインフラストラクチャの準備や管理に費やされています。また、可観測性とガバナンスの実装が非常に困難であり、結果として多くの場合、これらの機能がソリューションから完全に除外されることもお客様から学びました。多くの時間をタスクの理解に費やし、信頼性のないコストのかかるデータにつながっていました。
これが、Databricks が Delta Live Tables を開発した理由です。信頼性の高いデータパイプラインを構築し、大規模インフラストラクチャを自動で管理するシンプルな宣言型アプローチを使用した初の ETL フレームワークは、データアナリストやデータエンジニアがツールの準備に費やす時間を削減し、データから価値を引き出すことに集中できます。エンジニアやアナリストは、DLT を用いることで開発を加速し、複雑な運用タスクを自動化することで、実装時間を劇的に削減できます。
DLT は、既に世界中の大手企業において本番運用でのユースケースを支援しています。スタートアップからエンタープライズまで、ADP、シェル、H&R Block、Jumbo、Bread Finance、JLL を含む 400 社以上の企業が、DLT を使用して次世代のセルフサービス分析とデータアプリケーションを強化しています。
- ADP:「ADP では、人事管理データをレイクハウスで統合されたデータストアに移行しています。Delta Live Tables は、品質管理を構築するのに役立ち、宣言型 API、SQL のみによるバッチとリアルタイムのサポートにより、チームはデータ管理の時間と労力を節約できました。」
ADP 最高データ責任者 ジャック・バーコウィツ(Jack Berkowitz)氏 - Audantic:「我々のゴールは、革新的な製品を開発するために機械学習を活用し続け、新しい市場や地域に拡大することです。Databricks はこの戦略の基盤となっており、より迅速かつ効率的に到達するのに役立ちます。Delta Live Tables を用いることで、市場投入までの時間が 86% 短縮されたというような、規模と性能の面でこれまで到達できなかったさまざまなことが可能になりました。これまでは、週次や月次でパイプラインを実行していましたが、今では日次ベースで実行しています。これは劇的な改善です。」
Audantic 最高情報責任者 ジョエル・ローリー(Joel Lowery)氏 - シェル:「��シェルでは、統合されたデータストアに全センサーデータを集積しています。Delta Live Tables により、このような大規模なデータ管理の負荷が低減され、 AI エンジニアリングの能力が高まっています。Databricks は、既存のレイクハウスアーキテクチャを補強するケイパビリティによって、ETL およびデータウェアハウス市場に破壊的イノベーションをもたらしています。このことは、私たちのような企業にとって大きな意味があります。今後もイノベーションパートナーとして Databricks との連携を継続したいと考えています。」
シェル データサイエンス部門ゼネラルマネージャー ダン・ジーボンズ(Dan Jeavons)氏 - Bread Finance:「Delta Live Tables は、コラボレーションを可能にし、データエンジニアリングリソースの阻害要因を排除することで、分析チームと BI(ビジネスインテリジェンス)チームが Spark や Scala を知らなくてもセルフサービスを行えるようになります。実際、これまでに Databricks や Spark の経験のないデータアナリストが SQL を使用して DLT パイプラインを数時間で構築し、S3 へのファイルストリームを利用可能な探索用データセットに変換できました。」
Bread Finance シニアデータエンジニア クリスティーナ・テイラー(Christina Taylor)氏
ETL 処理のための最新のソフトウェアエンジニアリング
Delta Live Tables を用いることで、アナリストとデータエンジニアは、SQL や Python を使用して本番環境に対応したストリーミング、またはバッチ ETL パイプラインを簡単に構築できます。完全なデータパイプラインの宣言型記述を一位にキャプチャして依存関係をライブで理解し、内在する運用の複雑性を自動化することで ETL 開発をシンプルにします。DLT を使用すると、エンジニアはパイプラインの運用や保守ではなくデータの配信に集中することができ、次の主要なメリットを活用できます。
- ETL 開発の加速:エンドツーエンドのパイプラインを構築するためにコードの断片を手動で繋ぎ合わせる必要があるソリューションとは異なり、DLT では SQL や Python で全体のデータフローを宣言的に表現できます。さらに、DLT は、本番環境から分離された環境で開発する機能、デプロイ前のテストの容易性、パラメータ化によるデプロイと環境の管理、ユニットテストや文書化といった最新のソフトウェアエンジニアリングのベストプラクティスをネイティブにサポートしています。その結果、変換、CI/CD、SLA(サービス品質保証)、期待品質を表現し、単一 API でバッチとストリーミングをシームレスに処理するファーストクラスの構造を使用して、ETL パイプラインの開発、テスト、デプロイメント、運用と監視を簡素化できます。
- インフラストラクチャの自動管理:DLT は、インフラストラクチャを自動的に管理し、複雑かつ時間を費やすアクティビティを自動化するためにゼロから開発されました。変化する予測不可能なデータ量を考慮して、最適な性能を発揮するためにクラスタをサイジングすることは困難であり、過度なプロビジョニングにつながる可能性があります。DLT は、インスタンスの最小数と最大数を設定し、クラスタの利用率に応じてクラスタをサイズアップするオプションを提供することで、性能の SLA を満たすようにコンピューティングを自動的に拡張します。さらに、オーケストレーション、エラー処理とリカバリ、性能の最適化といったタスクは、全て自動的に処理されます。DLT を使用することで、運用ではなくデータの変換に集中できます。
- データの信頼性:ビルトインの品質管理、テスト、監視および実施により信頼性の高いデータを提供し、正確かつ有用な BI、データサイエンス、機械学習を確保します。DLT では、「エクスペクテーション」と呼ばれる機能を使用して、データの品質管理と監視ツールに対するファーストクラスのサポートを含めることで、信頼できるデータソースを簡単に作成します。エクスペクテーション機能は、不正なデータがテーブルへ流入するのを防ぎ、時間の経過に伴うデータ品質の追跡や、パイプラインの詳細な可観測性で不良データの問題を解決するツールを提供します。これにより、パイプラインの忠実度の高いリネージュ図の取得や、依存関係の追跡、全てのパイプラインにわたるデータ品質メトリクスを集約します。
- シンプルなバッチとストリーミング:バッチやストリーミング処理に対するデータパイプラインの自己最適化と自動スケーリングでアプリケーションに最新のデータを提供し、最適なコストパフォーマンスを選択します。ストリーミングとバッチのワークロードを別々に処理することを余儀なくされる他のツールとは異なり、DLT は単一の API であらゆるタイプのデータワークロードをサポートしています。データエンジニアとアナリストは、高度なデータエンジニアリングスキルを必要とすることなしに、クラウド規模のデータパイプ�ラインを迅速に構築できます。
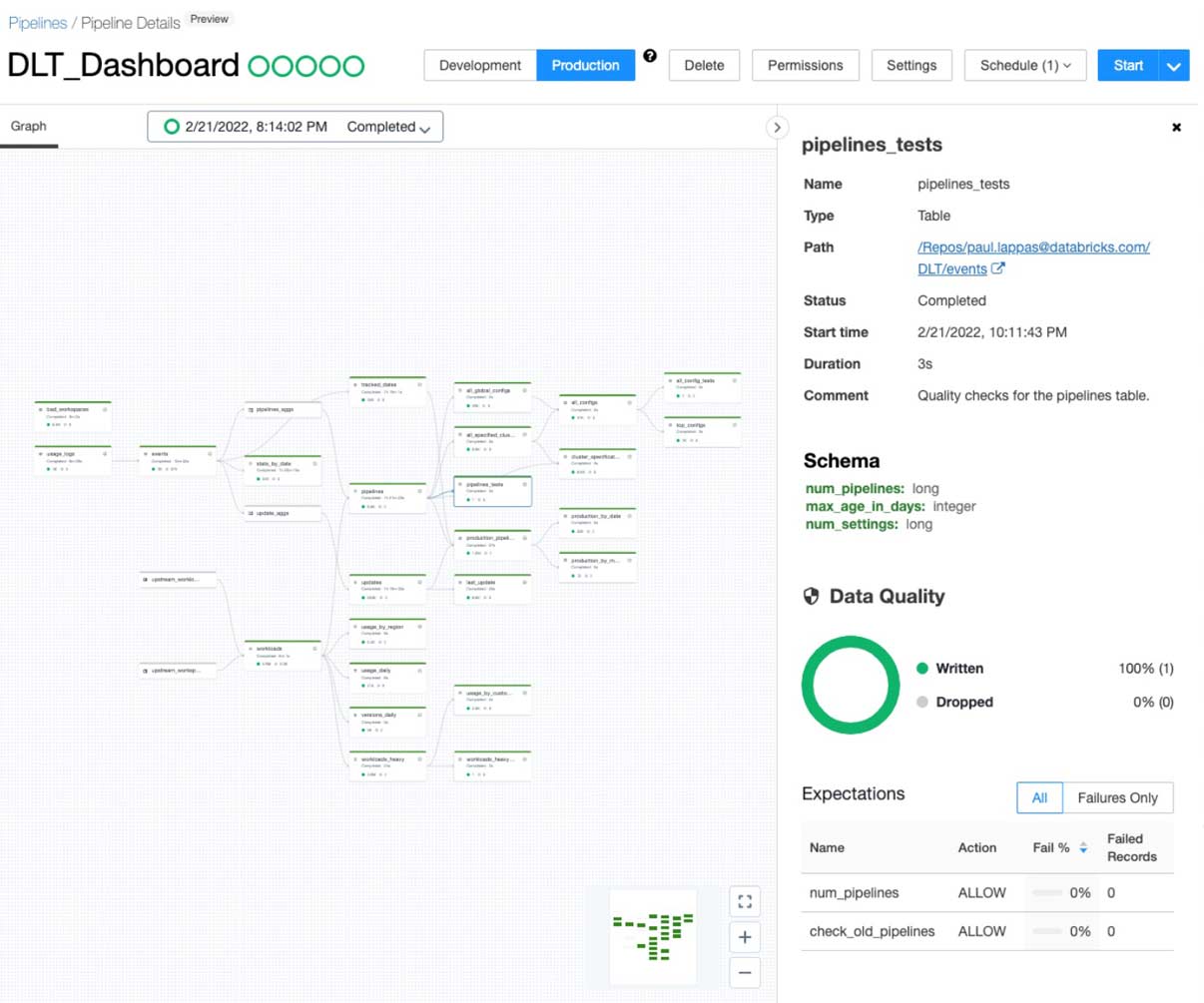
DLT のプレビューをリリースして以来、Databricks はいくつかのエンタープライズ向け機能と UX の改善を行ってきました。UI を拡張することで、DLT パイプラインのスケジュール設定、エラーの参照、ACL(アクセス制御リスト)の管理、テーブルリネージュの可視化の改善、データ品質の可観測性 UI とメトリクスの追加をシンプルにしました。さらに、継続的に到着するデータを効率的かつ簡単にキャプチャするためにの変更データキャプチャ(CDC)のサポートと、ストリーミングワークロード向けに優れた性能を提供する拡張オートスケーリングのプレビューをリリースしました。
��モダンアナリティクスへのコンパクトガイド

レイクハウスで Delta Live Tables を使用する
以下は、データエンジニアとアナリストの両者にとって使いやすい Delta Live Tables のデモ動画です。ぜひご覧ください。
すでに Databricks をお使いのお客様は、こちらのスタートガイドをご参照ください。今回の一般提供リリースに関する詳細は、リリースノートをご覧ください。まだ Databricks をご利用いただいていない場合は、無料トライアルにご登録ください。DLT の価格もご確認いただけます。
次のステップ
マイケル・アームブラスト(Michael Armbrust)と JLL 社による Delta Live Tables の Web セミナーは、こちらから登録してご覧いただけます。DLT の詳細は、こちらのページをご参照ください。