J&J 社におけるデータの民主化によるサプライチェーン最適化の事例
ジョンソン・エンド・ジョンソン社、Databricks レイクハウスを導入

本ブログは、ジョンソン・エンド・ジョンソン社の先端技術(データ、インテリジェントオートメーション、先端技術インキュベーション)部門シニアディレクター、 Mrunal Saraiya 氏の執筆によるゲストブログです。
ジョンソン・エンド・ジョンソン(J&J)は、グローバルな消費財および医薬品プロバイダーの中核的企業として 150 年以上にわたり、世界中の企業、患者、医師、人々にサービスを提供しています。私たちは、生命を維持する医療機器やワクチンをはじめ、市販薬、処方箋薬(これらの創薬に必要なツールや資源)など、市場に送り出す全てのものを入手可能な状態にし、多様な商品の品質、保管、お客様へのタイムリーな配送の一貫性を保証しなければなりません。
製品やサービスをどのように地域社会に提供するかは、私たちの事業戦略の中核をなすものです。特に、消費者が製品に効果的にアクセスして使用できるように��するために、製品の配送時間、場所の厳守、公正な販売価格の保証を重要視しています。市場のサプライチェーンには、以前から物流に関する課題がありますが、物流経路を効率化し、在庫管理とコストをグローバル規模で最適化するためには、膨大な量のデータの活用が不可欠です。
そして、そのデータは正確である必要があります。そのためには、極めて複雑な情報を抽出して解釈し、データを有用化できるツールを用意しなければなりません。サプライチェーン分析に有用なデータを利用し、データの民主化を実現することで、サプライチェーンのさまざまな側面の最適化が可能になります。
例えば、小売パートナーの棚に在庫を確保し、私たちが提供するワクチンの温度管理と納期を保証することや、カテゴリー支出のグローバルな管理、さらなるコスト改善策の特定などができるようになります。
こうしたデータの民主化によるサプライチェーン最適化によってもたらされる成果は計り知れません。私たちのグルーブ部門ヤンセンのグローバルサプライチェーン調達組織では、支出や価格設定を把握、管理できなければ、将来の戦略的意思決定やイニシアチブの特定が制限され、効果的なグローバル調達が困難になる可能性があります。すなわち、この問題を解決しなければ、私たちは 600万ドルのアップサイドを達成する機会を逃すことになりかねません。
J&J は、数多くの買収も含めて、この数十年で多岐に渡る組織を抱える企業に成長しました。複数の組織が J&J の傘下に入り、独自のリソースを持ち込んだ結果、これまで私たちのサプライチェーンデータは、優先順位��もばらばらで、独自の構成の断片化したシステムからエンジニアに供給されていました。さらに、データの抽出や分析はほぼ手動で行われ、スピードやスケーラビリティには限界があり、実用的な知見の入手には時間がかかっていました。システムのサイロ化はお客様へのサービスに悪影響を及ぼし、次に何をすべきかの戦略的な意思決定にも支障をきたしている状態でした。
Hadoop から Databricks 統合アプローチへの移行
このような背景を踏まえて、私たちは組織全体でデータの民主化をする重要な取り組みに着手しました。この計画は、共通のデータレイヤーを作成し、性能と汎用性の向上、意思決定の改善、エンジニアリングとサプライチェーン運用におけるスケーラビリティの確保、クエリと分析結果のリアルタイムかつ効率的な変更を可能にすることでした。そして選択したのが、 Azure クラウド上の Databricks レイクハウスプラットフォームの導入です。
J&J では、データの民主化の一環として、全てのグローバルデータの統合を目指していました。具体的には、複数に分散されたシステムによって生成された 35 以上のグローバルデータソースを単一のデータビューに置き換え、データサイエンティスト、エンジニア、アナリスト、アプリケーションが、必要に応じてデータをすぐに利用できるようにすることです。
そこで私たちは、これまでのパイプラインのデータアクティビティを繰り返すのではなく、データの単一の式を作成し、データ自体をプロバイダーにするように変更しました。それにより、ざまざまなユーザーが、共通レイヤーを利用して J&J に関連する多様なユ�ースケースを分析に用いて知見を取得できるようになりました。また、共通レイヤーにより、サービスを提供するお客様や企業に真の価値をもたらすアプリケーションの開発、データに対するより深い知見取得の迅速化、複数の部門に横断するサプライチェーン管理プロセスの相乗効果の向上、在庫管理と予測可能性の改善ができるようになったのです。
しかし、データ供給とアクセシビリティを 15 分程度で処理する SLA の要件を満たすデータインフラへの変更には、スケーラビリティの課題に取り組む必要がありました。既存の Hadoop インフラでは、データ分析要件のサポートと SLA を同時に満たすことができませんでした。レガシーシステムを使用して、大規模な処理を時間内に実行するには、膨大なコストとリソースが必要でした。
次に、サプライチェーン戦略とデータの最適化に関する重要な戦略的課題がありましたが、スケーラビリティの欠如により、解決できていませんでした。さらに、柔軟性と成長性には限界があり、ユースケースは少なく、データモデルの精度が低下していたことも課題でした。それらは、レイクハウスアプローチをデータ管理に適用して共通レイヤーを作成したことで、ビジネスニーズに合わせて拡張できる無数のデータパイプラインにデータを供給できるようになりました。
その結果、データから実用的な気づきと価値を引き出すためのユースケースが大幅に増加しました。また、幅広いビジネスにとどまらず、予測分析を用いることで、物流の最適化に関する主要な傾向やニーズの予測、顧客の治療ニーズの理解、それがサプライチェーンにおよぼす影響を�確実かつ迅速に把握できるようになりました。
高確度なヘルスケアソリューションの提供が可能に
J&J ではサプライチェーン最適化の成果を最大化するために、Databricks と契約してリソースを拡大し、データ分析と機械学習に効果的な共通データの取り込みレイヤーを展開しました。エンジニアリングと AI 部門が戦略的かつ意図的に連携することで、システムが完全に最適化され、はるかに優れた処理能力が実現しました。
私たちのデータフローは、今では大幅に効率化されています。データ部門は Databricks の次世代クエリエンジンである Photon を使用して、SQL ワークロードに対して極めて高速なクエリを低コストで実行しています。全てのデータパイプラインが Delta Lake を経由するようになり、Photon でのデータ変換は簡素化されます。そこから、Databricks SQL の高性能なデータウェアハウス機能により、最適化されたコネクタを介してさまざまなアプリケーションや BI ツール(PowerBI、Qlik、Synapse、Teradata、Tableau、ThoughtSpot など)にデータが供給されるため、アナリストやサイエンティストは、データをほぼリアルタイムで利用できます。
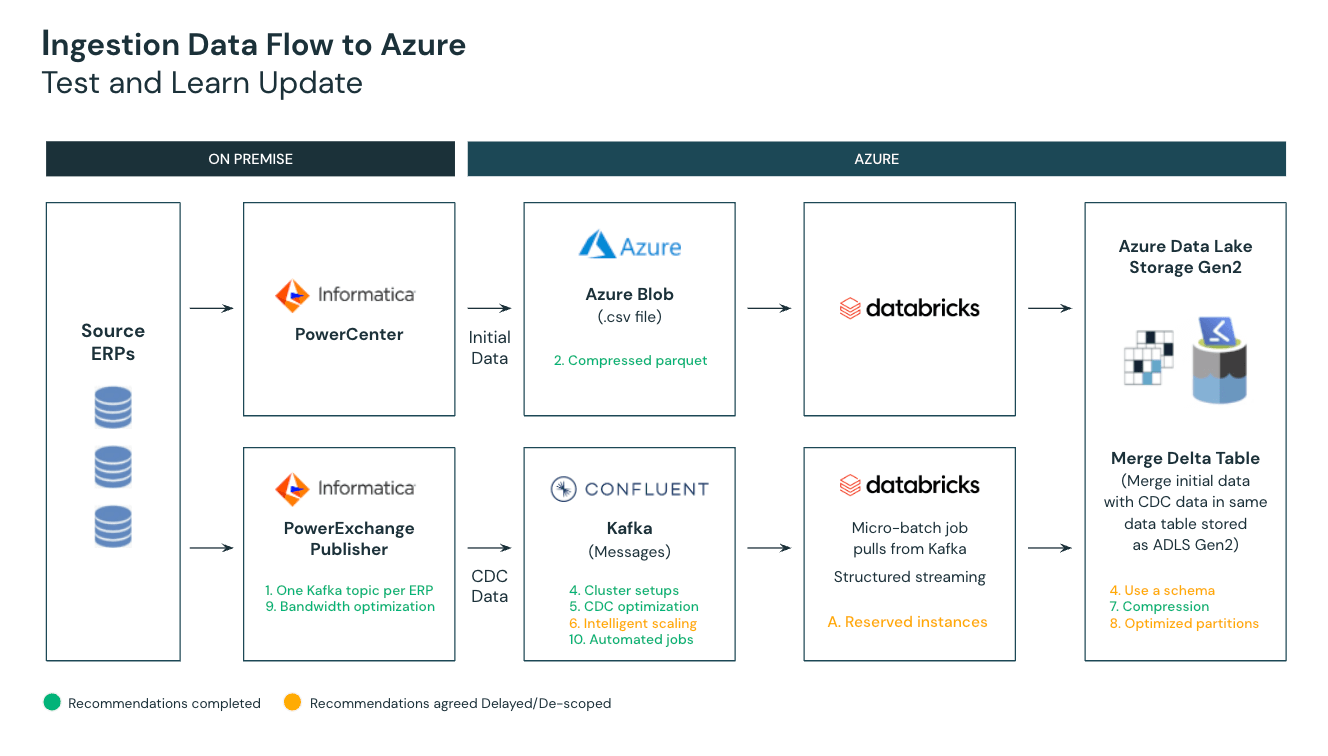
データエンジニアリングワークロードのコストは現在までに 45~50% 削減されました。また、データ配信のラグは約 24 時間から 10 分以下に短縮されています。
従来のデータウェアハウスではなく、Databricks SQL を使用することで、Data Lake で現行の BI ワークロードを直接実行できます。これにより、消費者やビジネスのニーズをいっそう深く理解できるようになりました。この知見にもとづいて、継続的なビジネス機会の創出に注力できています。
具体的には、小売パートナーが消費者に適切なレベルの在庫を確保するための製品需要の予測、世界各地でのコスト効率の高い医薬品流通の確保ができるようになりました。さらに、Databricks SQL を使用して Delta Lake から直接分析を実行できることは、需要計画プロセスに費やす時間とコストのさらなる削減につながると期待しています。
興味深いソリューションの 1 つは、患者治療のための製品をサプライチェーン全体で追跡できるようになったことです。私たちの細胞治療プログラムでは、アフェレシス治療を行っている患者の治療経過において、14 以上のマイルストーンの追跡が可能になりました。また、J&J の 18 社を超えるグローバル子会社とベンダーパートナーが、患者をサポートするためにどのように連携してドナーを収集し、製造、最終製品を管理するかについても追跡できています。
クラウドベースの Databricks レイクハウスプラットフォームを導入したことで、数多くのメリットを享受しています。Azure クラウドでの運用データインフラが大幅に簡素化され、 SLA を一貫して満たし、全体的なコスト削減を実現しています。その結果、優れたサービスをお客様とコミュニティに提供できるようになりました。
Databricks を活用した今後の展��望
データの可能性は無限です。データサイエンスの領域において、探索は収集と分析と同じくらい優先事項です。J&J は、レガシーな Hadoop インフラから Databricks レイクハウスプラットフォームに移行したことにより、データの民主化を実現し、ビジネスをまたがるユーザーのデータパスを効率化し、障害を取り除くことができました。
J&J ではかつてないほど、革新的な探求を真のソリューションに変換できるようになり、世界中の人々の健康を支援しています。