Delta Live Tablesを用いたサイバーセキュリティのレイクハウス向けETLパイプラインの構築

翻訳: Masahiko Kitamura
オリジナル記事: Building ETL pipelines for the cybersecurity lakehouse with Delta Live Tables
Databricksはこのほど、データエンジニア、データサイエンティスト、アナリストが、複雑なインフラを管理することなく、あらゆるクラウド上で信頼性の高いデータ、分析、MLワークフローを構築できるようにするWorkflowsを発表しました。Workflowsでは、Delta Live Tablesを使用して、インジェストやリネージを含む自動管理され�たETLパイプラインを構築することができます。ワークフローとDelta Live Tablesの利点は、セキュリティデータソースに簡単に適用でき、運用ニーズに合わせて必要なボリュームやレイテンシーに拡張することが可能です。
この記事では、セキュリティログの取り込みと処理におけるDelta Live Tablesの主な利点を、お客様がサイバーレイクハウスに読み込む一般的なデータソースの例をいくつか挙げて紹介します。
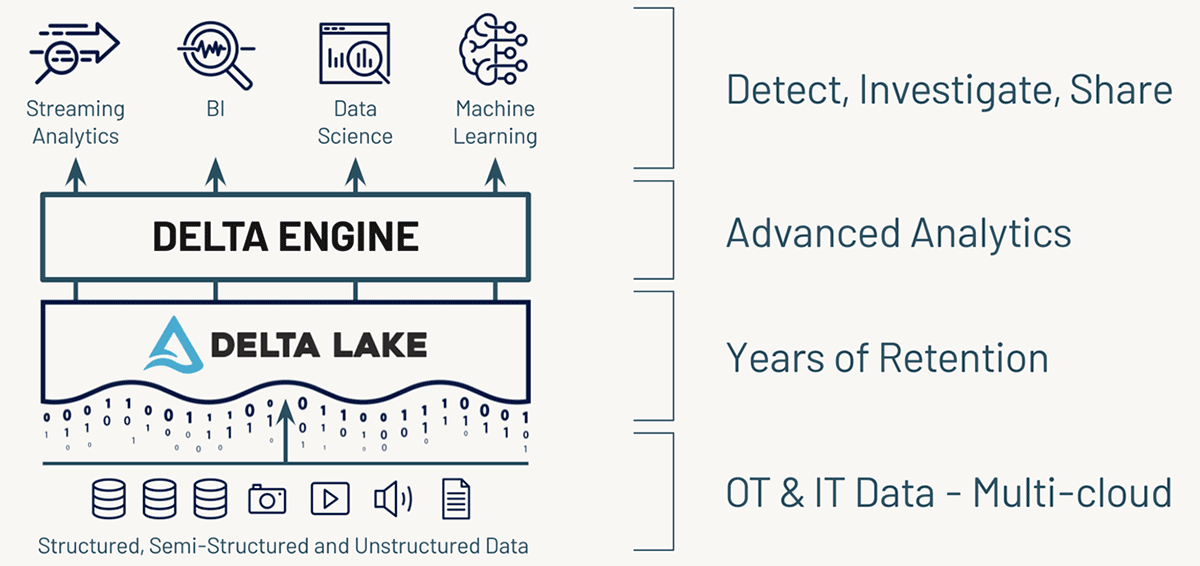
Databricksでセキュリティログのデータソースを操作する
最初に取り上げるデータソースはCloudTrailで、AWSアカウントのアクティビティを監視するために使用できるログを生成することができます。CloudTrailのログは、5分ごとに圧縮されたJSONフォーマットでS3バケットに公開されます。JSONはこれらのログをクエリするのは簡単ですが、これは分析およびレポーティングのニーズ、特に数ヶ月または数年のデータに必要なスケールでは非効率なフォーマットです。インシデントレスポンスや高度なモニタリング、MLのユースケースをサポートするためには、Delta Lakeのようなより効率的なオープンソースフォーマットを使用すれば、データのバージョン管理はもちろん、パフォーマンスや信頼性も格段に向上するはずです。
CloudTrailはまた、かなり複雑で高度にネストされたスキーマを持っており、新しいサービスが導入されたり、リクエスト/レスポ�ンスパターンが変化したりすると、時間とともに進化していく可能性があります。スキーマの変更を手動で管理する必要はなく、さらに悪いことに、実行時にイベントの解析に失敗してデータが失われる可能性もあります。そのためには、ダウンタイムを最小限に抑え、SLAに違反するようなコード変更を避ける、柔軟で信頼性の高いスキーマの進化が必要です。
AWSでは、VPCフローログを使用して、環境を流れるネットワークトラフィックを監視・分析することも可能です。この場合も、S3バケットに設定可能な頻度で、テキストまたはParquetフォーマットで配信されます。この場合のスキーマとフォーマットはCloudTrailよりも一貫性がありますが、やはり私たちはサイバー脅威の分析とレポートのニーズに対して、信頼性が高くパフォーマンスの高い方法でこのデータを利用できるようにしたいのです。
最後に、ネットワーク監視のもう一つの例として、Zeekログを使用します。VPCフローログと同様に、環境内のネットワークアクティビティを監視するのに役立ちますが、Zeekはプロトコルに基づいてより詳細なログを生成し、異常なアクティビティに対する軽量な検出を含んでいます。
3つのデータソースすべてについて、実装、展開、監視が簡単なパイプラインを求めます。データの品質と信頼性を確保するために、私たちはDelta Live TablesのExpect(期待値)も使うつもりです。これは、データ品質の制約と、パイプラインに取り込まれたレコードの処理方法を定義するための宣言型モデルです。Delta Live Tablesは、これらの条件に対するビルトインモニタリングを提供し、データソースの脅威検出にも利用することができます。
Delta Live Tablesを使って実装
これら3つのユースケースでは、サンプルログはS3に置かれ、Delta Live Tables(DLT)を使って私たちのLakehouseにインクリメンタルにインジェストされます。DLTは、Structured StreamingとDelta Lakeをベースにした、データフローパイプラインを定義する新しい宣言型モデルです。DLTを使えば、自動インデックス作成、ファイル最適化、さらには統合データ品質管理など、信頼性、拡張性、効率性の高いデータパイプラインを構築することができます。さらに、DatabricksはDLTパイプラインの展開と実行に関する運用の複雑さ(受信データのバックログに基づく再試行や自動スケーリングなど)を管理するので、パイプラインの宣言だけに集中し、それ以外はDLTに任せることができます。
For more details about DLT, please see previous articles such as Announcing the Launch of Delta Live Tables and Implementing Intelligent Data Pipelines with Delta Live Tables.
DLTの詳細については、過去記事「Delta Live Tablesの提供開始を発表」、「Delta Live Tablesでインテリジェントなデータパイプラインを実装」をご参照ください。
CloudTrail
最初にレビューするのは、CloudTrail用のパイプラインです。前述の通り、AWSはCloudTrailのログを含む圧縮JSONファイルをS3バケットに配置しています。私たちはDatabricks Auto Loaderを使用して、実行ごとに新しいファイルを効率的に発見してロードしています。本番シナリオでは、S3イベントがSQSトピックにプッシュされるファイル通知モードを使用することをお勧めします。これにより、新しいファイルを検出するためにS3ファイルのリストアップを低速で実行する必要がなくなります。
また、CloudTrailファイルのスキーマが大きく複雑であることから、Auto Loaderのスキーマ推論モードも有効にしています。これは、新しいファイルからのサンプリングを使用して�スキーマを推論するもので、スキーマを手動で定義し管理する手間を省くことができます。スキーマが変更されると、Delta Live Tablesは、トランザクションの一部として、ターゲットDeltaテーブルの下流に自動的にそれらの変更をマージします。
CloudTrailの場合、私たちが緩やかな型付け形式で保持することを好むいくつかの列があります: requestParameters, responseElements, resources, serviceEventDetails, そして、 additionalEventData.です。これらのパラメータは、呼び出されるサービスやイベントのリクエスト/レスポンスに応じて、すべて異なる構造を持ちます。スキーマ推論では、この場合、すべての可能なフォーマットのスーパーセットから、大規模で高度にネストされたカラムを作成することになり、各イベントでほとんどの値がNULLになります。これでは、セキュリティ・アナリストにとって、カラムの理解や視覚化が難しくなります。その代わりに、スキーマヒントを使用して、これらの特定のカラムを文字列のキーと値のペアを持つ単純なマップ型として扱うように Auto Loader に指示することができます。こうすることで、必要な情報はそのままに、すっきりとした構造を保ち、アナリストが使いやすくなります。
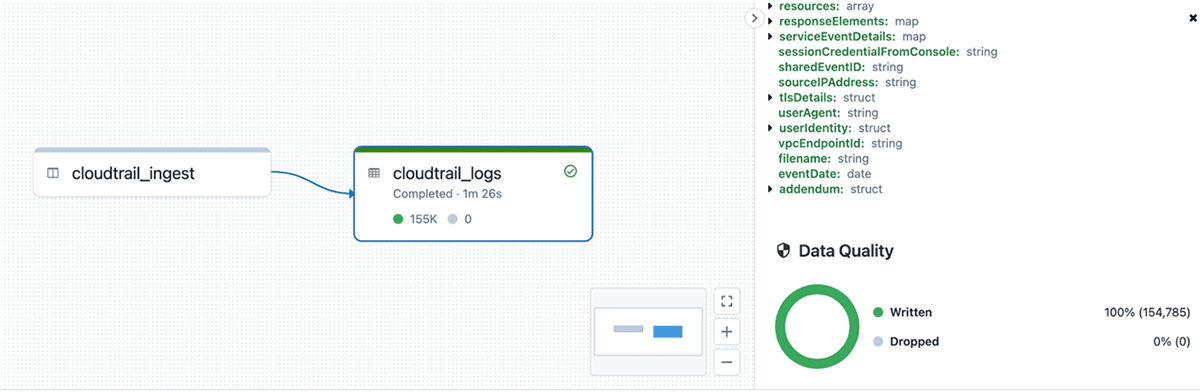
最後に、適切に解析されフォーマットされたデータを取り込んでいることを確認するため、各エントリーにDLTの期待値(expectations)を適用します。各CloudTrailエントリーはRecordオブジェクトの配列なので、ファイルが適切にパースされれば、配列に1つ以上の値があることが期待されます。また、解析に失敗し、救出されたデータ列で終わる列を見るべきではありませんので、これも期待値で検証します。これらのチェックは、追加の処理や保存(DLTではビューを使って行われる)の前に実行します。これらの品質チェックのいずれかが失敗した場合、パイプラインを停止して直ちに問題に対処し、下流のテーブルが破損するのを避けます。
これらの品質チェックに合格すると、データを分解してイベントごとに1行にし、パーティショニングのためのeventDateやオリジナルのソースファイル名など、いくつかのエンリッチメントカラムを追加することにしています。
ZeekとVPCのフローログ
この同じモデルをZeekとVPCのフローログに適用することができます。これらのログはCloudTrailと比較して固定フォーマットであるため一貫性があり、期待されるスキーマを前もって定義しておくことができます。
VPCフローログのパイプラインは非常にシンプルです。ここでもAuto Loaderを使ってS3から新しいファイルを取り込み、Unixのエポックタイムから開始と終了カラムのタイムスタンプへの簡単な変換を行い、eventDateパーティションカラムを生成しています。ここでも、タイムスタンプの変換が正常に行われたことを確認するために、データ品質の期待値を使用します。
Zeekパイプラインでは、コードを減らし、ログの種類ごとに複数のテーブルを管理することを簡略化するために、少し異なるパターンを使用しています。それぞれスキーマが定義されていますが、個別にテーブルを定義するのではなく、テーブル名、ログソースパス、スキーマを受け取るヘルパーメソッドを使用して、実行時に動的にテーブルを作成します。このメソッドは、これらのパラメータに基づいて動的にテーブルを生成します。すべてのログソースには、タイムスタンプなどの共通カラムがあるので、VPCフローログで行ったのと同様に、簡単な変換とデータ品質チェックを適用します。
# This method dynamically generates a live table based on path, schema, and table name
最後に、Zeekの組み込み検出から疑わしい活動を特定するために、connectionテーブルとnoticesテーブルを結合して、silver alertsテーブルを作成します。ここでは、Watermarkと時間ベースの結合を使用し、遅いイベントや順序外のイベントが発生した場合でも、無限の状態を維持する必要がないようにします。
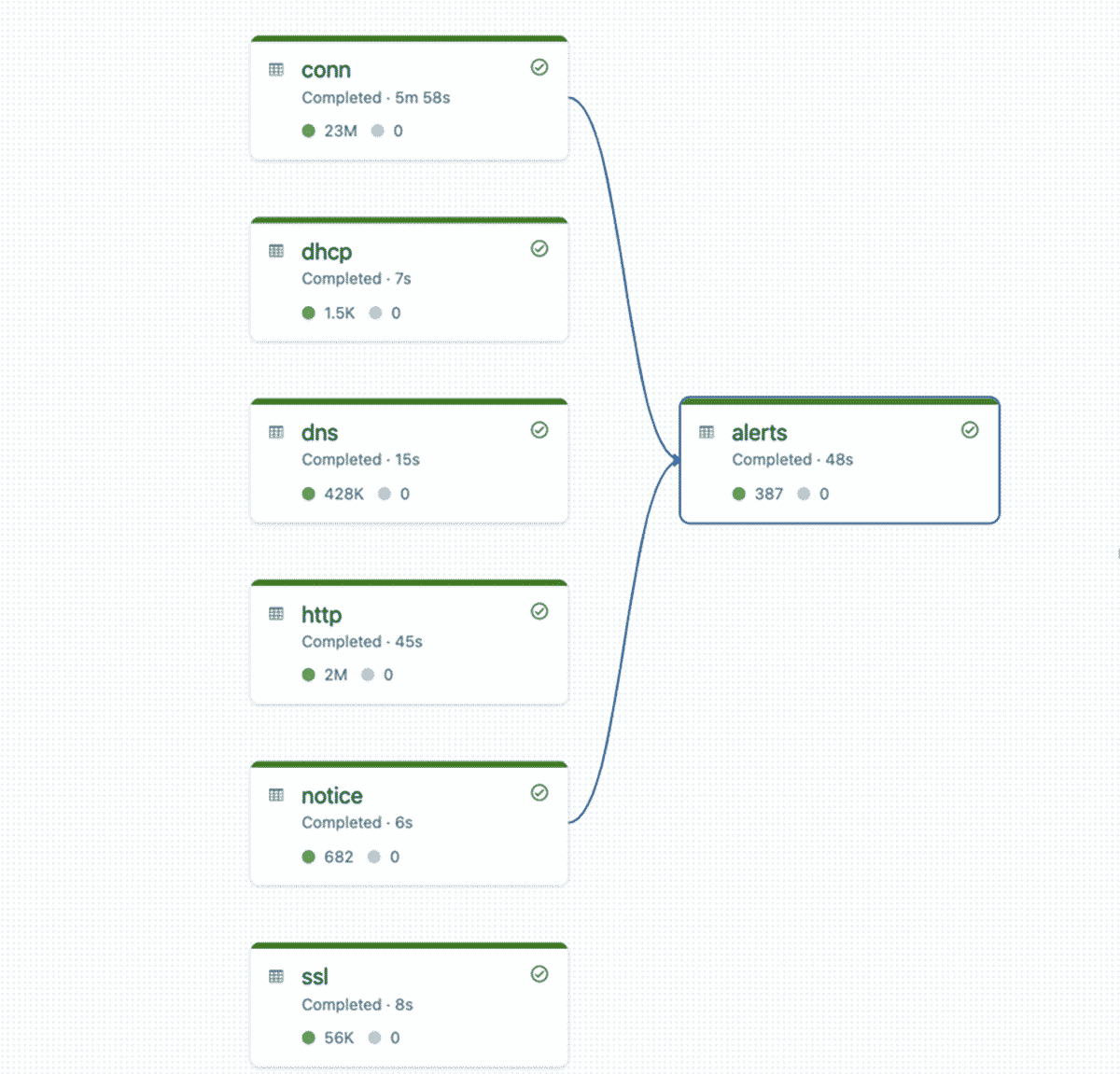
DLTがパイプラインを実行すると、ランタイムはすべてのベーステーブルとアラートテーブルの依存関係グラフを構築する。ここでも、同時ストリーム数と取り込まれたデータ量に応じてスケールするDLTに依存しています。
まとめ
各パイプラインのコードを数行書くだけで、最適化され、構造化されたセキュリティレイクハウスができあがり、元の生データよりもはるかに効率的になります。これらのパイプラインは、必要な頻度で実行できます。低レイテンシーの場合は連続的に、1時間ごとや1日ごとなどの定期的に実行することも可能です。DLTは必要に応じてパイプラインの拡張や再試行を行い、複雑なエンドツーエンドのスキーマの進化も管理してくれるため、サイバーレイクハウスの維持に必要な運用負担は大幅に軽減されます。
さらに、Databricks Lakehouse Platformでは、データをマルチペタバイト規模で保存、処理、分析することができるため、保存期間やルックバック期間を大幅に延長し、データサイエンスや機械学習による高度な脅威検出が可能になります。さらに、SIEMツールからクエリを実行し、セキュリティイベントを360度見渡すことができます。
この3つのパイプラインのコードはこちらで確認できます: CloudTrail, VPC flow logs, Zeek。
Delta Live Tables on Databricksをご自身のデータソースでお試しいただき、ご質問やご意見をお待ちしております。[email protected] までご連絡ください。