レイクハウス用データクリーンルームの紹介

公開日: June 28, 2022
によって Matei Zaharia、イタイ・ワイス、スティーブ・マホニー、サチン タクール、Dan Morris、Jay Bhankharia による投稿
翻訳: Masahiko Kitamura
オリジナル記事:Introducing Data Clean Rooms for the Lakehouse
Lakehouseのデータクリーンルームを発表することで、企業はプライバシーを保護した方法で、顧客やパートナーとあらゆるクラウド上で簡単にコラボレーションできるようになります。データ・クリーン・ルームの参加者は、データのプライバシーを維持しながら、既存のデータを共有、結合し、データ上でPython、R、SQL、Java、Scalaなどあらゆる言語で複雑なワークロードを実行することができます。
外部データの需要がかつてないほど高まる中、組織はデータ主導のイノベーションを促進するため、データを安全に交換し、外部データを利用する方法を模索している。歴史的に、組織はデータ共有ソリューションを活用してパートナーとデータを共有し、データのプライバシーを守るために相互信頼に依存してきた。しかし、一度共有されたデータの管理は放棄され、さまざまなプラットフォームでデータがパートナーによってどのように消費されているかは、ほとんど可視化されていない。これは、潜在的なデータの誤用やデータ・プライバシーの侵害を露呈することになる。データ・プライバシー規制が厳しくなる中、機密データがどのように消費されるかを管理し、可視化することは組織にとって不可欠です。その結果、組織には安全で、管理された、プライベートなデータ・コラボレーション方法が必要となり、データ・クリーンルームの出番となるのです。
このブログでは、データクリーンルーム、データクリーンルームに対する需要、Databricks Lakehouse Platform上のスケーラブルなデータクリーンルームに対する当社のビジョンについて説明します。
データ・クリーン・ルームとは何か?
データ・クリーン・ルームは、複数の参加者がファーストパーティ・データに参加し、他の参加者にデータを公開するリスクなしにデータ分析を実行できる、安全で、管理された、プライバシー・セーフな環境を提供します。参加者は自分のデータを完全に管理することができ、個人を特定できる情報(PII)のようなセンシティブなデータを公開することなく、どの参加者が自分のデータに対してどのような分析を行うかを決定することができます。
データ・クリーン・ルームは、業界を超えた幅広いユースケースを可能にする。例えば、消費財(CPG)企業は、ファースト・パーティの広告データを小売パートナーのPOS(販売時点情報管理)トランザクション・データと結合させることで、売上を向上させることができる。メディア業界では、広告主やマーケティング担当者は、データのプライバシーを守りつつ、より広範なリーチ、より優れたセグメンテーション、より高い広告効果の透明性で、よりターゲットを絞った広告を配信することができる。金融サービス企業は、バリュー・チェーン全体で協力して、プロアクティブな不正検知やマネーロンダリング防止戦略を確立できる。実際、IDCは、2024年までにG2000企業の65%が、データ・クリーンルームを通じて外部の利害関係者とデータ共有パートナーシップを形成し、データ・プライバシーを保護しながら相互依存を高めると予測している。
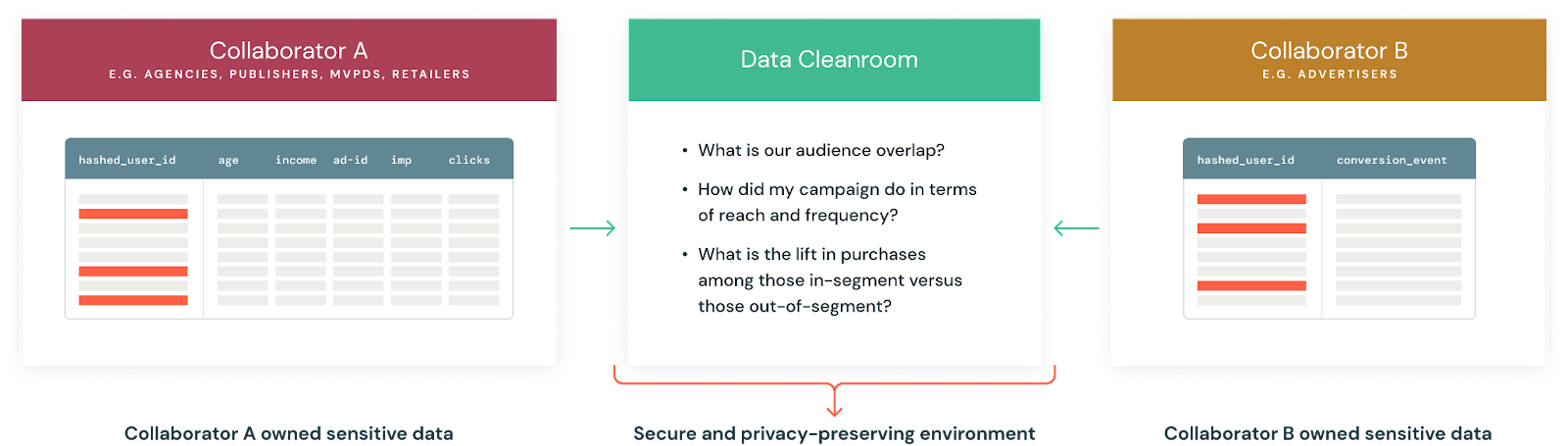
Privacy-safe data clean room
クリーンルームの需要を��牽引する説得力のある理由をいくつか見てみましょう:
セキュリティ、コンプライアンス、プライバシーの急速な変化: GDPRやCCPAのような厳しいデータプライバシー規制は、サードパーティの測定における抜本的な変化とともに、特に広告やマーケティングのユースケースにおいて、組織がデータを収集、使用、共有する方法を変革してきた。例えば、アップルのApp Tracking Transparency Framework(ATT)は、アップル製デバイスのユーザーに、アプリのトラッキングを簡単にオプトアウトできる自由と柔軟性を提供している。グーグルもまた、2023年後半までにChromeにおけるサードパーティ・クッキーのサポートを段階的に廃止する予定です。これらのプライバシーに関する法律や慣行が進化するにつれ、業界がUID 2.0のようなPIIベースの新しい識別子に移行するにつれて、データ・クリーン・ルームの需要が高まる可能性が高い。組織は、クッキーのない現実の中でビジネス目標を達成するために、プライバシーを重視した方法でパートナーとデータを結合する新しいソリューションを見つけようとするだろう。
断片化されたデータエコシステムにおけるコラボレーション: 今日、消費者は、いつ、どこで、どのようにコンテンツに接するかについて、かつてないほど多くの選択肢を持っている。その結果、消費者のデジタル・フットプリントはさまざまな�プラットフォームで断片化され、企業はパートナーと協力して顧客のニーズや要件を統一的に把握する必要があります。組織間のコラボレーションを促進するために、クリーンルームは、新しい洞察や能力を引き出すために、データを他のデータと組み合わせる安全でプライベートな方法を提供します。
データを収益化する新しい方法: ほとんどの組織は、既存のデータやIPの収益化戦略をすでに持っているか、開発しようとしている。今日の個人情報保護法では、企業は個人情報保護規則を破るリスクを冒すことなくデータを収益化するために、可能な限りの利点を見つけようとするだろう。このことは、データベンダーやパブリッシャーにとって、データに直接アクセスすることなくビッグデータ分析のためにデータに参加する機会を生み出す。
既存のデータクリーンルーム・ソリューションの大きな欠点
企業が様々なクリーンルーム・ソリューションを模索する中、既存のソリューションには、「クリーンルーム」の可能性を十分に実現できず、企業のビジネス要件を満たさないという欠点が目立っています。
データの移動と複製: 既存のデータクリーンルームベンダーは、参加者がデータをベンダーのプラットフォームに移動することを要求する。さらに、参加者が集計されたデータの分析を行う前に、標準化されたフォーマットでデータを準備するのは時間がかかる。さらに、参加者は、異なるクラウドや地域の参加者とのコラボレーションを促進するために、異なるクラウドや地域間でデータを複製しなければならず、その結果、運用とコストのオーバーヘッドが発生する。
SQLに制限されている: 既存のクリーンルーム・ソリューションでは、任意のワークロードや分析を実行する柔軟性があまりなく、単純なSQL文に制限されていることが多い。SQLは強力でクリーンルームには絶対に必要ですが、機械学習、APIとの統合、その他の分析ワークロードなど、SQLでは対応できない複雑な計算が必要な場合があります。
拡張が難しい: 既存のクリーンルーム・ソリューションのほとんどは、単一のベンダーに縛られており、一度に2人の参加者以上のコラボレーションを拡大する拡張性がない。例えば、広告主が異なるプラットフォームでの広告パフォーマンスを詳細に把握したい場合、複数のデータパブリッシャーから集約されたデータを分析する必要があります。コラボレーションの参加者が2社に限られているため、企業は1つのクリーンルームプラットフォームで部分的な洞察を得て、結局別のクリーンルームベンダーにデータを移動することになり、部分的な洞察を手作業で照合する運用上のオーバーヘッドが発生する。
Databricks Lakehouseプラットフォームによる拡張性と柔軟性に優れたデータクリーンルームソリューションの導入
Databricks Lakehouse Platformは、お客様のデータプライバシーとガバナンスの要件に基づき、スケーラブルで柔軟なデータクリーンルームを構築、提供、展開するための包括的なツールセットを提供します。
レプリケーションなしの安全なデータ共有: デルタ・シェアリング( Delta Sharing )により、クリーンルームの参加者は、クラウドや地域を越えてデータを複製することなく、データレイクのデータを他の参加者と安全に共有することができます。あなたのデータはあなたの手元に残り、どのプラットフォームにもロックされません。さらに、クリーンルームの参加者は、データの使用状況を一元的に監査し、監視することができます。
任意のワークロードと言語の実行をフルサポート: Databricks Lakehouseプラットフォームは、機械学習やデータワークロードなどの複雑な計算をSQL、R、Scala、Java、Pythonなどあらゆる言語でデータ上で実行できる柔軟性をクリーンルーム参加者に提供します。
ガイド付きオンボーディングエクスペリエンスで簡単に拡張可能: Databricks Lakehouse Platform上のクリーンルームは、クラウドやリージョンを問わず、複数の参加者に簡単に拡張できます。事前に定義されたテンプレート(ジョブ、ワークフロー、ダッシュボードなど)を使用して、一般的なユースケースを簡単に開始し、参加者をガイドすることができます。
きめ細かなアクセス制御でプライバシーセーフ:Unity Catalogでは、データに対するきめ細かなアクセス制御を可能にし、プライバシー要件を満たすことができます。統合されたガバナンスにより、参加者はデータに対して実行可能なクエリやジョブを完全に制御できます。データに対するクエリやジョブはすべて、Databricksがホストする信頼できるコンピュート上で実行されます。参加者が他の参加者の生データにアクセスすることはなく、データのプライバシーが保証されます。参加者は、オープンソースまたはサードパーティの差分プライバシーフレームワークを活用することもでき、クリーンルームを将来にわたって維持することができます。
Databricks Lakehouseのデータクリーンルームについて詳しくは、Databricksのアカウント担当者にお問い合わせください。

