データブリックス上での教師なし外れ値検出
Kakapo - integration for PyOD, MLflow and Hyperopt

![]()
Kakapo(KAH-kə-poh))は、Databricks上でスケールアップした外れ値検出のための標準APIセットを実装しています。これは外れ値検出アルゴリズムの膨大なPyODライブラリと、モデルの追跡とパッケージングのためのMLFlow、広大で複雑かつ異質な探索空間の探索のためのHyperopt との統合を提供します。
The views expressed in this article are privately held by the author and cannot be attributed to the European Securities and Markets Authority (ESMA)
Original Blog : Unsupervised Outlier Detection on Databricks
翻訳: junichi.maruyama
異常値検出の手法は多くの業界に浸透しています。不正行為、サービス低下、交通渋滞、ネットワーク監視などのユースケースを問わず、洞察を得るためには異常値検出ツールやテクニックが必要です。データがクリーニングされ特注の機能で補強された後、予測モデルは外れ値が存在すると最適な結果を得られない可能性があります。また異常値を特定することが最終目標になる場合もあります。いずれの場合もシンプルでスケーラブルなフレームワークがあれば、実装が容易で進化する要件に適応できることが望ましいです。
このブログでは、Wikipediaのアノマリー検出の定義に従うことにします。「データ分析において、異常検知(外れ値検知や新規性検知とも呼ばれる)とは、一般的に、データの大部分から著しく逸脱し、正常な動作の定義に適合していない稀なアイテム、イベント、または観察を識別することであると理解されている」。そこでこの2つの用語は同義語と考えることにします。
外れ値検出を行う場合、何から始めればよいのでしょうか?どのフレームワークを選べばいいのか?どのような手法を採用すべきなのか?ラベル付きデータがない場合はどうすればいいのか?予想される異常値の数が不明な場合はどうすればよいでしょうか?
外れ値検出の技術的な側面だけでなく、堅牢なソリューションの実装に着手する際に思い浮かぶ、より広範な考慮事項がいくつか存在します。
- 将来への備えと拡張性。つまり、現在のワークロードを処理するだけでなく、要件の変化(例:量、速度、複雑さの増加)に応じて拡張できるフレームワークを持つ方法。
- 生産性とコラボレーション、すなわち仕事やアイデアを簡単に共有できるようにする方法
- ガバナンスと監査可能性、すなわちメタデータの収集と記録、強固な監査証跡の確保、そして最終的に信頼できるデータの作成方法。
このブログ記事では、Databricks上で大規模に異常検知を行うための標準的なAPIセットを提供します。このソリューションは、MLflow (モデルのトラッキングとパッケージング)およびHyperopt (モデルとハイパーパラメータのチューニング)と統合されています。PyOD ライブラリに含まれる多くの外れ値検出アルゴリズムをMLflowと統合し、簡単でスケーラブルな追跡と監査ができるようにするシンプルなモデルラッパーテンプレートから始まるステップバイステップのガイドを提供する予定です。出力は、そのまま使用することも、さらに強化することもできる拡張可能なフレームワークであることを意図しています。このフレームワークの中心は、ライブラリKakapo、MLflow、Hyperoptです。
なぜ外れ値が問題になるのか?
統計や洞察は、基礎とな�るデータがあってこそのものです。上記の異常検知の定義では、「有意」という用語はケースバイケースで判断されるものであり、それはやや主観的なものであることを確認しています。これは、異常値とは何かという数学的な厳密な定義がないためです。Chebyshev's inequality、Dixon's Q test, Chauvenet's criterion, Mahalanobis distance、あるいはその他かもしれませんが、これらはすべて、"期待値と異なるものはどのようなものか?"という問いに答えることを目的としたアプローチです。- という期待値の問いは、「どのようにして『異なるもの』(観察)を識別することができるのか」という問いによって補完されます。不平等の定義の小さな違いは、文脈が違うだけで、パフォーマンスに大きな影響を与えるかもしれません。
期待値の問題は、業界を横断するものである。それは、規制される業界によって前面に押し出され、それぞれの業界の監視に警戒することが規制当局の義務であるためである。「規制当局は、自らの責任範囲における優先的なリスクを決定するために、証拠に基づくアプローチを取るべきである」-UK Regulators' Code。エビデンスに基づくアプローチは、基本的に、データを消費し、正しく解釈する我々の能力と同じくらい効果的である。データポイントの統計的性質(つまり、何かが異常であるかどうか)は、これらの検討にとって重要である。期待値の問題の重要性を示すもう一つの例は、まさに欧州証券市場庁(ESMA)のミッションステートメント「一つの使命:投資家保護を強化し、安定した秩序ある金融市場を促進する」に見出すことができる。安定した秩序ある市場を適切にモデル化するためには、不安定で秩序がない行動がどのようなものかを理解する必要があります。そこで、データ主導の規制活動を実現するために、異常検知を行うことで大きな価値をもたらすことができます。最後に、規制当局が課し、監視する規範や基準を遵守することは、規制当局の義務である。そして、これらの規範を遵守するために、規制当局は、ビジネスの提供方法における異常や誤った事象を検出し、これらの問題をプロアクティブに修正するために、同じツールを必要としています。
同じ原則は、規制された業界以外でも当てはまります。民間企業や第三セクターでは、期待値の問題はこれまでと同様に重要であり、異なるユースケースに適用されるだけである。これらの分野では、通常とは異なるデータを検出することで、望ましくない顧客離れや競合他社への流出を防いだり、詐欺事件の増加に対処して詐欺検出を自動化したり、あるいは予知保全の改善に役立てることができる。通常とは異なる観測は、予期せぬ出来事の証拠であ�り、来るべき出来事の前触れでもあります。データ駆動型の正しい意思決定は、利用可能なデータの全特性を考慮することなしには不可能である。
ラベルレスモデル評価の事例
大半ではないにせよ、多くの場合ラベル付けされた異常データを手に取ることも、データアセットごとに予想される異常数の量を定量化することも困難である。それはエネルギー的にもコスト的にも時間のかかる複雑な作業です。ラベル付けされたデータであっても、他の多くの異常値が存在し、評価基準を濁す可能性があります。さらに多くの企業にとって、潜在的な異常値を持つ可能性のある(あるいは持つ)何百ものデータ資産にラベルを付けることは法外な負担となります。
私たちは、このことを念頭に置いてkakapoライブラリを設計し、全く同じAPIセットを公開することで、コードに変更を加えることなく、シンプルなフラグパラメータを渡すだけで教師あり・教師なし両方のモデル評価を実行できるようにしています。ラベル付きデータがない場合は、特徴量とその分布にのみ依存する教師なしメトリクスを計算する(この場合、N. Goix et al.に基づいてEM/MV メトリクスを計算した)。
また、このブログで取り上げているKakapoライブラリの統合機能を活用することで、ハイパーパラメータを変化させた数百のモデルを大規模に訓練することができ、単一のモデルに依存することなく、自由に「アンサンブル」モデル(複数のモデルを並行して使用)を作成して合意型の異常予測を生成することができるようになりました�。
単純化、標準化、統一化によって、先に述べたような複雑な状況から価値を引き出すことができるのです。このブログを通して、私たちはPyOD、MLflow、Hyperoptを使ってこれらの原則を推進し、異常検知のユースケースにおけるベストプラクティスとクリーンなシステム設計を推進するつもりです。
PyOD - 識別ツールボックス
"PyODは、多変量データから外れ値を検出するための最も包括的でスケーラブルなPythonライブラリです。" - PyOD.
PyODが提供するサービスの幅広さは、前述の引用と完全に一致する。PyODは伝統的なモデルとディープモデルの両方を含む異常検知のための40以上の異なるモデルを提供しています。そのため、PyODはデータサイエンティストにとって、ベテランであれ新参者であれ必須のレパートリーとなっている。
PyODには統一されたAPIと、Isolation Forestのような古典的なものからECODのような新しいものまで、数多くの検出アルゴリズムが用意されており、1千万以上のダウンロード数を誇っています。
最後におそらくフレームワークの最も魅力的な点は、そのシンプルさと使いやすさです。外れ値検出アルゴリズムの実装は数行のコードで済みます。
なぜ単純にIsolation Forestを使用しないのか?これらの利点から、PyODは外れ値検出の取り組みやシステム設計を統一し簡素化するための有力な候補となります。
- コードベースはより堅牢にな�り、現在の異常値検出技術の代替や拡張を可能にする柔軟性を持つようになります。
- コードベースはよりスリムになり、より宣言的になります。
- MLflowとhyperoptを統合することで、提案するフレームワークは異常に関する事前知識がある場合とない場合の両方で異常値検出を実現することができる。
注:PyODの公式ドキュメントページには豊富な情報が掲載されており、外れ値検出に関するさらなる読み物に興味がある方には強くお勧めします。
MLOps のビッグブック

MLflowによるMLライフサイクルマネジメントのベストプラクティス
MLflowは、実験、再現性、デプロイメント、中央モデルレジストリなど、MLのライフサイクルを管理するための最も著名なオープンソースプラットフォームの1つである。MLflowの主なコンポーネントは以下の通りです。
| MLflow Tracking | MLflow Projects | MLflow Models | MLflow Registry |
|---|---|---|---|
| 実験(コード、データ、設定、結果)の記録と照会 | データサイエンス・コードを、あらゆるプラットフォームでの実行を再現するためのフォーマットでパッケージ化する。 | 多様なサービス環境でのMLモデルの展開 | 中央のリポジトリにモデルを保存、注釈、発見、管理できる |
Tracking APIは、機械学習モデルをトレーニングする際のパラメータやメトリクス、その他無数のアウトプットを、わずか数行のコードで簡単にアクセスできる方法で記録することができます
各モデルの実行を記録した後、機能豊富なAPIまたは直感的なWeb UIのいずれかを使用して実験を探索し、結果を比較したり、他のデータ科学者と共有したりすることができます。
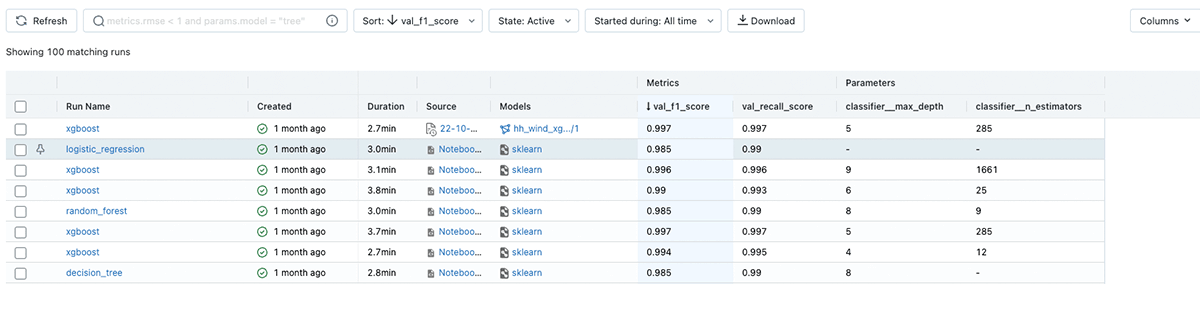
MLflowは、機械学習モデルを様々な形式(「フレーバー」とも呼ばれる)でパッケージ化し、後で簡単にデプロイできるようにします。MLflowはいくつかの標準的なフレーバーを提供し、scikit-learn、XGBoostなどの一般的なパッケージを介して実装された多数のモデルを自動的に追跡して記録することができます。
MLflowは、ネイティブにサポートされていないモデルのためのソリューションも提供します。python_function(pyfunc)モデルフレーバーは、MLflowのベストプラクティスを利用しつつ、任意のコードとモデルデータからpyfuncモデルを作成するユーティリティを提供します。
この章の残りの部分では、MLflowエコシステムの残りの部分と緊密に統合するためにKakapoパッケージを介して提供されるpyfuncモデルラッパーとして任意のPyOD外れ値検出モデルをラップするための一つのアプローチを実証します。PyodWraper は Pyod の基本モデルのリスト(コードでは「model_space」と呼ばれます)を受け取り、バックエンドに必要な統合を実装して、最小限のユーザー介入でモデルが MLflow によって記録され追跡されるようにするもので、まさにこの機能を提供するもので、以下のコードブロックが参照されます。
上記のコードでは model_spaceは、使用したいPyODアルゴリズムのキーと値のペアの辞書です。Kakapoは get_default_model_space()メソッドでアクセスできるデフォルトのモデル空間を提供します。さらにデフォルトのモデル空間を豊かにするために、自由にモデルを追加することができます。
Kakapoのような抽象化を使用する主な利点は、一般性とガバナンスを損なうことなく外れ値検出のためのモデルを訓練するために必要なコードを簡素化することです。このパッケージは、MLflowの標準APIに準拠し、相互運用性と移植性を保証する一方で、��個々のサポート対象モデルの独自性と特異性を抽象化しています。エンドユーザは複雑な、しかも定型的なコードベースの管理よりも、パラメータのチューニングやパラメータとメトリクスの解釈に集中することができます。
私たちが検討しているさまざまな異常検知アルゴリズムの性能を評価するためには、ある種のメトリックが必要です。ラベル付きデータにアクセスできる場合とできない場合があるので、GROUND_TRUTH_OD_EXISTSというフラグを定義しています。Kakapoはその値に応じて異なる動作をします。
- グランドトゥルースラベルが存在する - roc_auc_scoreが計算され、モデルの主要な指標として記録される
- グランドトゥルースラベルが存在しない - 特徴量とその分布にのみ依存する教師なしメトリクスを計算し、ログに記録する(このブログの作業例では、N. Goixらに基づいてEM/MVメトリクスを計算しています)
ラベルなしデータ資産のサポートを通じて、私たちは大規模データドメインにおける大きなペインポイントに取り組んでいます。何百ものデータセットを含む可能性のあるデータドメインにおいて、ラベル付きのデータ資産を提供することは困難なことかもしれません。データ資産全体にわたって外れ値を分析する方法を持つことは、アウトライン化されたアプローチの大きな利点です。
The optimizer - Hyperoptで成功するスケーリング
パズルの最後のピースは、異なるアルゴリズムとハイパーパラメータの組み合わせの多様なセットを使用して、何百ものモデルのトレーニングを並行して処理するために、我々のアプローチを拡張することです。
Hyperoptは、Pythonの最も高性能なハイパーパラメータ最適化ライブラリの1つとして知られており、データ科学者に広く使用されています。ハイパーパラメータの空間を定義するのは、数行のコードの問題です。その後、このライブラリのAPIを使用して、この空間全体でモデルの損失を最適化します。
また、複数のモデルやそれぞれのハイパーパラメータを同時にカバーするネストした探索空間を定義できることも強力な特徴です。
上記の構文を使って、多くの外れ値検出モデルを連鎖させ、それぞれのパラメータを設定し、最も性能の良いものを見つける旅に出ることができます(あるいは、多くの候補モデルを生成し、アンサンブルで組み合わせて、データに対する多数意見の採点を提供します)
Kakapoのget_default_model_space()と同様に、get_default_search_space()を使用して、デフォルトのHyperoptパラメータ空間から始めることができます。これも、内蔵のメソッド(enrich_default_search_space())を使って簡単に拡張することができます。
あとは、上記の設定でHyperoptのfmin関数を実行すれば、並行してモデル学習が開始されます。
Putting it all together
上記のトレーニングが完了したら、MLflow APIを使用して各モデルランにアクセスすることができます。以下のコードブロックでは、特定のHyperoptランを検索しそれに属するすべてのモデルを取得し、パフォーマンスメトリックでソートしています。次に最もパフォーマンスの高いモデルの一意のランIDを抽出し、それをロードするために進みます。
以下では、MLflow モデルをロードして予測を生成するための 2 つの代替アプローチを紹介します。
A) モデルをsparkのユーザー定義関数(UDF)として読み込み、sparkのデータフレームに予測する。
B) モデルをpyfuncとして読み込み、Pandasのdataframeで予測する。
最後に、出来上がったデータフレームを表示し(SparkやPandas)、先ほど生成された異常予測を観察することができます。
メトリックに基づいて最もパフォーマンスの高いモデルをロードした方法と同様に、多くのモデルを連続してロードし、観測ごとに複数の予測を生成し、個々のスコアを集計することもできます。これは、異なる強みを持つ複数のモデルを組み合わせ、アンサンブルとして使用した場合に、より質の高い予測を提供する素晴らしい方法となります。
このブログを通して、人気のあるMLライブラ�リ-PyOD-をMLflowプラットフォームのベストプラクティスと統合し、Hyperoptが提供するスケーリングを利用するための1つのアプローチを取り上げました。私たちは、教師あり・教師なしの両方の異常検知モデリングをサポートする、シンプルで拡張可能なフレームワークを提案しました。
このツールボックスは、DatabricksでのMLの旅にクイックスタートを与えることを意図しており、個人または会社のベストプラクティスを取り入れて拡張することができるものである。
このブログで取り上げたコード例は、すべてこのノートブックに掲載されています。
P.S. 因みにパッケージのネーミングセレクトについてはまだ迷っているようです。 カカポは世界で最も希少な鳥のひとつであり、希少でユニークなイベントを探すときにその名前はぴったりだと思いました