機械学習で母親を助ける:CareSourceはハイリスク妊娠のヘルスケア改善のためにどのようにMLOpsを活用したか

公開日: April 4, 2023
によって Chengyin Eng、Russ Scoville、Arpit Gupta、Alvaro Aleman による投稿
このブログ投稿はCareSourceのRuss Scoville (Vice President of Enterprise Data Services)、Arpit Gupta (Director of Predictive Analytics and Data Science)、and Alvaro Aleman (Senior Data Scientist) との共同によるものです。
Original Post:Saving Mothers with ML: How CareSource uses MLOps to Improve Healthcare in High-Risk Obstetrics
翻訳:motokazu.ishikawa
アメリカでは、毎年およそ1000人に7人の割合で母親が妊娠と分娩合併症に苦しんでいます1。CDCによると、分娩合併症となった母親は700人が亡くなるが、そのうち60%は適切な治療を受けることで防げるものであることのことです。370万の成功した出産のうちでも、19%は低出生体重児であるかまたは出産予定日より早く生まれてしまいます。医学的には産科と言われる、これらハイリスク妊娠や分娩は、人命に対するリスクであるだけでなく、家族に対しても感情的、経済的な重荷となり得ます。ハイリスク妊娠は通常の出産より10倍近くお金がかかるものであり、平均するとハイリスク妊娠が57,000ドルに対し典型的な妊娠は8,000ドルです2。アメリカ最大のメディケイド提供事業者の1つであるCareSourceは、これらのハイリスク妊娠を見分けるだけでなく、手遅れになる前にこれらの両親に救命となる産科ケアを提供する医療事業者と提携することを目標にしています。しかしながら、解決すべき課題としてデータのボトルネックがあります。
CareSourceは彼らの過去の全データを機械学習のモデルのトレーニングに使うことができないという問題と格闘していました。機械学習の実験の体系的なトラッキングとモデルの更新のトリガーを実現することについても悩みの種となっていました。これら全ての制約が、医療パートナーに時間の制約のある産科リスク予測を提供することに遅れをもたらしていました。このブログ投稿では、CareSourceがハイリスク妊娠を同定するための機械学習モデルをどのように開発したのかを簡単に議論し、さらに、機械学習モデル開発を加速するために標準化、自動化された本番フレームワークをどのように構築したのかに注目します。
環境と人々についての背景
CareSourceにはデータサイエン�ティストとDevOpsエンジニアからなるチームがいます。データサイエンティストは機械学習のパイプラインを開発することが責任なのに対し、DevOpsエンジニアは本番の機械学習パイプラインを支援するのに必要な環境を設定することが役割になっています。
環境のセットアップの面では、CareSourceはdev、staging、productionに対して単一のAzure Databricksのワークスペースを使っています。チームは環境ごとにAzure Repoを使ってそれぞれ異なるGitブランチを活用しています:
- dev またはfeatureブランチ: development
- main ブランチ: staging
- release ブランチ: production
機械学習開発
ハイリスク妊娠 (high-risk obstetrics, HROB)で際立っているのは、健康のプロファイルに関連するだけでなく、それ以外の環境的因子、例えば経済的安定性などが、妊婦の家族の健康に影響を与えることです。合わせると500以上の特徴量があり、これら医療関連の特徴量の多くは再入院リスクモデルなどの関連する機械学習モデルに有用です。そのため、クレンジングされエンジニアリング済みの特徴量を保存してプロジェクト間やチーム間で再利用するために、私たちはDatabricks Feature Storeを採用しました。
異なる特�徴量の組み合わせを使った実験を容易にするため、特徴量選択と補完の方法を表現するためにYAMLファイルを使うことで、モデルのトレーニングのコードの変更を不要としました。まず最初にfeature_mappings.ymlの中で異なるグループに特徴量をマッピングしました。そして、以下に示したようにfeature_selection_config.ymlの中でどの特徴量グループを保持し、捨てるかを記述しました。このアプローチが優れているのは、モデルのトレーニングコードを直接変更する必要がないことです。
全過去データを使った大規模トレーニングを可能とするため、データ処理のために分散化されたPySparkフレームワークを活用しました。また、ベイジアンハイパーパラメータ探索のオープンソースツールであるHyperoptを活用して、過去のモデル調整ランの結果を活かしPySparkモデルのチューニングをしました。MLflowにより、これらハイパーパラメータの試行は自動的に捕捉されます。これは、これらのハイパーパラメータ、指標値、任意のファイル(例:画像、特徴量重要度ファイルなど)を含みます。MLflowの利用により各種の実験ランの記録を保存するための手動作業で苦戦することはなくなります。Center for American Progressによる2022年の周産期保健に関するレポートの内容と同じように、妊娠中のリスクは確かに多面的な問題であり、健康履歴のみならず、社会経済学的�因子により影響を受けるものであることを予備的な実験から見出しました。
機械学習の本番移行
概して、モデルの本番移行に関して、同じ組織の中のプロジェクト間やチーム間でもばらつきがあるものです。CareSourceでも同様でした。CareSourceは、プロジェクトごとの本番移行の基準の差異に苦しみ、モデルの展開は遅れがちになりました。さらに、多様度の増加は、エンジニアリングのオーバーヘッドや習熟の複雑さも増加することを意味しています。そのため、CareSourceが達成したい主要なゴールは、モデルの本番移行のための標準化され自動化されたフレームワークを実現することとなりました。
私たちのワークフローの核として、テンプレートツールであるStacks (プライベートプレビュー中のDatabricksの製品)を活用し、機械学習モデルを展開しテストするための標準化され自動化されたCI/CDワークフローを生成しました。
Stacksの紹介*
Stacksはコードデプロイパターンを活用しており、モデルのアーティファクトではなくトレーニングのコードをstagingやproductionへ昇格させます。(デプロイコードとデプロイモデルの比較についてはBig Book of MLOpsで詳しく知ることができます。)これは、機械学習モデルの本番移行のためのInfrastructure-as-Code (IaC)やCI/CDを構築するためのcookiecutterテンプレートを提供しています。cookiecutterのプロンプトを介して、DatabricksワークスペースURL、Azureストレージアカウント名などのAzure Databricksの環境値についてテンプレートを設定しました。Stacksはデフォルトでstagingとproductionで異な�るDatabricksワークスペースを仮定します。そのため、Azureサービスプリンシパルの生成についてカスタマイズして、同じワークスペースにstaging-sp and prod-spという2つのサービスプリンシパルを持つことにしました。これでCI/CDパイプラインが備わったので、cookiecuterテンプレートに従っての機械学習コードの採り入れへと進みました。下図は私たちが実装した機械学習の開発と自動的な本番移行のための全体的なアーキテクチャです。
*注釈:StacksはDatabricksのプライベートプレビュー中の製品であり、将来のモデル開発をさらに簡単にすべく継続的に改良中です。今後のリリースにご期待ください!
本番移行のためのアーキテクチャとワークフロー
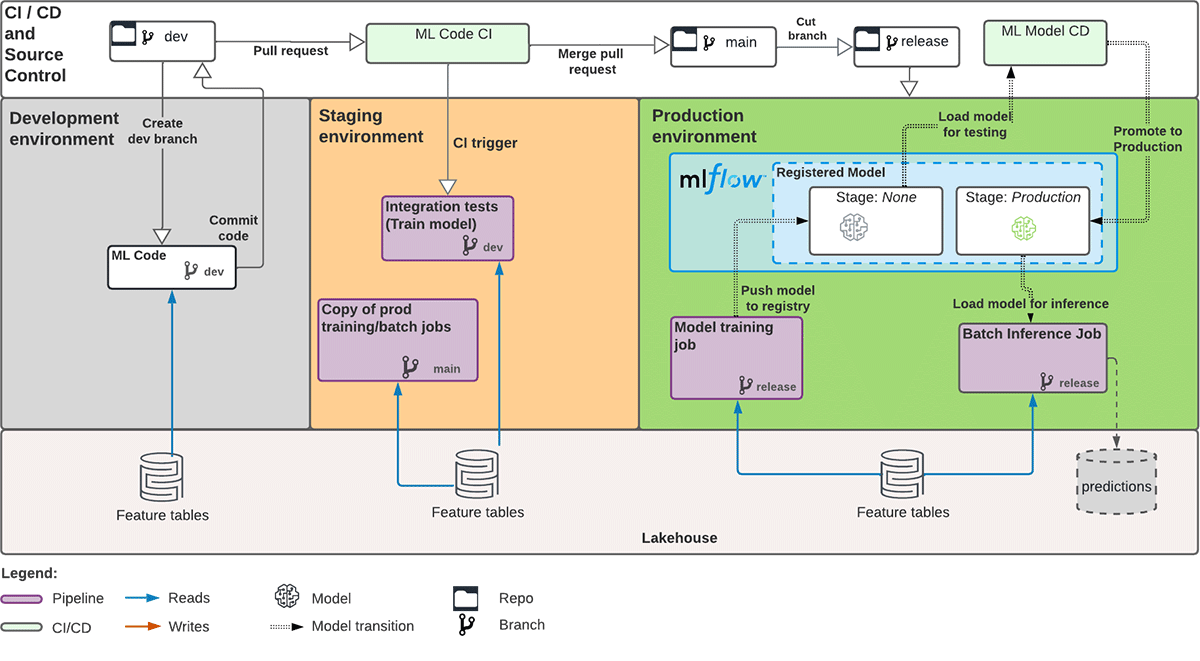
dev環境では:
- データサイエンティストはモデル開発と探索のために自由にフィーチャブランチを作成できる
- 彼らは作業中のコードをGitに定期的にコミットする
- productionへと展開できるモデルの候補をデータサイエンティストが見つけたら:
- 必要な場合、機械学習のコードをモジュール化しパラメータ化します
- ユニットテスト、結合テストを実装します
- MLflowエクスペリメントのパス、モデル、トレーニングと推論のジョブの頻度を定義します - 最後にstaging環境のmain ブランチにプルリクエストを送信します
staging環境では:
- Azure DevOpsで定義された継続的インテグレーション(CI)のステップに従い、プルリクエストが一連のユニットテストと結合テストをトリガーします
- 特徴量エンジニアリングとモデルトレーニングのパイプラインが実行に成功し期待通りの結果を出力することを確認します - 候補モデルをMLflowモデルレジストリに登録し、ステージをstagingに移行します
- 全てのテストに合格したらプルリクエストをmain ブランチにマージします
prod環境では:
- データサイエンティストはモデルを本番環境へプッシュするため main ブランチからrelease ブランチを切り出します
- Azure DevOpsの継続的デリバリー(CD)のステップがトリガーされます
- staging環境と同様に特徴量エンジニアリングとモデルトレーニングのパイプラインの実行が成功することを確認します - 全てのテストに合格したら、もし最初のモデルバージョンである場合、MLflowモデルレジストリに候補モデルを登録してProductionに移行します
- 以降のバージョンの更新では、Productionに移行する前に本番環境にある現行モデル(バージョン1)と比較してチャレンジャーモデル(バージョン2)の性能値が優れていなければなりません - MLflowモデルレジストリにあるモデルをロードし、バッチ推論をします
-これらの推論結果をDeltaテーブルに永続化して後続処理を実施します
上述した標準化されたワークフローはCareSourceの他の全ての機械学習プロジェクトに適用可能になりました。モデル管理をシンプルにするこの他の重要な要素として自動化があります。管理すべきモデルが沢山あるのでテストを手動でトリガーしたくはありません。Stacksに組み込まれた自動化のためのコンポーネントはTerraformです。特徴量エンジニアリング、モデルトレーニングそして推論のジョブを起動させるコンピューティング��リソースも含めて全ての構成をコードで表現しています。Terraformから得られる追加の恩恵としてこれらインフラの変更の構築とバージョン管理をコード化できるというものがあります。TerraformによるIaCとCI/CDをスクラッチから構築するのは簡単な作業ではありませんが、幸いなことにStacksはブートストラップの自動化とリファレンスCI/CDコードを標準で搭載しています。例えば、以下のTerraformのリソースを使うことで、毎日午前11時(UTC)にprod ブランチからコードをプルし、推論ジョブを実行するようにスケジュールすることができるのです。
このプロジェクトでは、プロジェクト全体で使う環境固有の構成ファイルも活用しました。これにより例えばdevからstagingへと環境が変わる時に、異なる構成間を容易に切り替えることが可能となりました。一般的に、パラメータ化されたファイルは機械学習のパイプラインをクリーンにし、パラメータの繰り返しにおいてもバグの無い状態に保つ手助けとなります:
結果
まとめると、私たちはDatabricks Feature Store、MLflowそしてHyperoptを使い、妊娠リスクを予測するための機械学習モデルの開発、チューニング、トラッキングを行いました。そして、Stacksを活用して、配置と医療パートナーへのタイムリーな予測結果の送信のための本番適用可能なテンプレートを実装しました。本番移行のベストプラクティスに従ったエンドツーエンドのフレームワークは、挑戦的で実装に手間のかかるものです。しかしながら、上述した機械学習の開発と本番移行のためのアーキテクチャを約6週間以内で構築しました。
では、CareSourceでの本番移行のプロセスを加速させるのに Stacksはどう役立ったでしょう?
効果
Stacks は標準化されていながらも、完全にカスタマイズ可能な機械学習のプロジェクト構成、Infrastructure-as-Code、そしてCI/CDのテンプレートです。しかもどのようにモデル開発のコードが書かれたかを問わないため、機械学習コードをどのように書いてもどのパッケージを使っても束縛されることは全くありません。CareSourceのデータサイエンティストはこのプロセスを完全に所有することができ、Stacksの提供するガードレールに従ってセルフサービスのスタイルでモデルを本番移行することができるのです。(上で触れたようにプライベートプレビューでの改善を経ることでさらに簡単にStacksを活用できるようになることでしょう!)
これで、CareSourceチームは他の機械学習のユースケースに対してテンプレートを容易に拡張することができるようになりました。今回の経験から得られた重要な学びは、データサイエンスとDevOpsエンジニアリングチームの早期のコラボレーションが、スムーズな本番移行を確実なものとする助けとなることです。
このハイリスク妊娠モデルのDatabricksへの本番移行はCareSourceにとって手始めに過ぎません。機械学習開発からの本番移行を加速させることは、データプラクティショナーがデータと機械学習の力を完全に解き放つだけに留まらず、CareSourceにおいては手遅れになる前に患者の健康と生活に直接的な影響を与えるチャンスを持つことを意味します。
CareSourceは最高の職場2020年(the Best Places to Work 2020)の1つとして選ばれ、医療分野の革新賞(Clinical Innovator Award)を受賞しました。彼らの健康改良のためにCareSourceに加わりたい方、ぜひ求人募集のページをチェックして見てください。
参照
- Blue Cross Blue Shield Organization - the Health of America. (2020, June 17). Trends in Pregnancy and Childbirth Complications in the U.S. Retrieved March 23, 2023, from https://www.bcbs.com/the-health-of-america/reports/trends-in-pregnancy-and-childbirth-complications-in-the-us
- M. Lopez. (2020, August 6). Managing Costs in High-Risk Obstetrics. AJMC. https://www.ajmc.com/view/a456_13mar_nwsltr
Databricksの投稿を見逃さないようにしましょう
次は何ですか?


データサイエンス・ML
October 30, 2024/1分未満