機械学習を向上させる合成データ
Leverage AI to generate synthetic data for better models, or safer data sharing with data teams

Original Blog : Synthetic Data for Better Machine Learning
翻訳: junichi.maruyama
この1年で最も話題になった、ChatGPTやDALL-Eのような生成AIの進化を試したことがある人も多いでしょう。これらのツールは、複雑なデータを消費し、より多くのデータを生成することで、驚くほど知的なもののように感じられるのです。これらやその他の新しいアイデア(diffusion models、generative adversarial networks、GAN)は、遊んでみると楽しく、恐ろしいとさえ感じます。
しかし、日常的な機械学習のタスクは、表形式のデータと「通常の」データサイエンス・ツールを使って、売上予測や顧客離れを予測することなどであり、ボッシュが火星の生物をどう描いたかを想像することではない。

生成AIが、例えば単純な回帰の問題に役立つとしたらどうだろう。あなたが持っている実際のビジネスデータのような合成データを生成することができるアイデアの関連クラスがあります。合成データは、広く考えられているジェネレーティブAIの重要なアプリケーションです。
このブログでは、典型的な機械学習プロセスにおける合成データのいくつかの使用法を検討します。その回帰問題をどのように支援できるのか、あるいは機密データの取り扱いに関する運用上の懸念に役立つのか。合成データのモデリングにはオープンソースのライブラリSDV (Synthetic Data Vault) を使用し、合成データの生成にはMLflow, Apache Spark , Deltaを使用して管理し、最後にDatabricks Auto MLで回帰問題にどのように影響するかを探ります。
なぜ機械学習に合成データなのか?
作りかけのデータは、現実世界を学ぶのに何の役に立つのか?適当に作ったデータは役に立ちません。しかし、現実のデータによく似たデータであれば、役に立つかもしれません。
まず、誰もがより多くのデータを求めています。それは、より良い機械学習モデルを意味する(こともあるからです)。機械学習は現実の世界をモデル化するので、より多くのデータがあれば、その世界の全体像を把握することができます。角のあるケースで何が起こるのか、何が異常なのか、何が繰り返し観察されるのか。本物のデータは入手困難ですが、本物そっくりのデータを無限に入手するのは簡単です。
しかし、合成データは、実際に存在するデータを模倣することしかできない。合成データは、実際のデータを模倣するだけであり、実際のデータセットにはない新たな機微を明らかにすることはできない。しかし、実際のデータが意味することを外挿することは可能であり、場合によっては有益であることもあります。
第二に、データは自由に共有できない場合があります。個人を特定できる機密情報(PII)が含まれている可能性があります。新しいチームとデータを共有し、探査や分析作業を迅速に�行うことが望ましいかもしれませんが、共有するためには、長時間の再編集、特別な取り扱い、フォームへの記入など、官僚的な作業が必要になる可能性があります。
合成データは、機密データのようでありながら、実際のデータではないデータを共有することで、その中間的な役割を果たします。場合によっては、この方法にも問題があるかもしれません。合成データが実際のデータポイントに少し似ているとしたら、どうでしょうか。また、不十分な場合もあります。
しかし、合成データを共有することで十分なデータセキュリティを確保しつつ、コラボレーションを加速させることができるユースケースはたくさんある。例えば、新しい問題を解決する信頼性の高い機械学習パイプラインを開発するために、請負業者のチームに協力してもらいたいと考えています。しかし、機密性の高いデータセットを彼らと共有することはできません。合成データを共有すれば、彼らが実際のデータで実行してもうまく機能するパイプラインを構築するのに十分すぎるほど役立つでしょう。
問題:ビッグティッパー
このブログでは、よく知られているNYCタクシーのデータセットを使って説明します。Databricksでは、/databricks-datasets/nyctaxi/tables/nyctaxi_yellowで利用可能です。これは、10年以上にわたってニューヨークでタクシーに乗ったときの基本的な情報を記録したもので、ピックアップとドロップオフポイント、距離、料金、通行料、チップなどが含まれています。何十億行もある大きなもので、このサンプルはこのように始まるサンプルで動作します:

ここでは、ライダーが旅行の終わりに追加するチップを予測することが問題になります。タクシー内の支払いシステムは、チップの額を機転を利かせて提案したいのかもしれない。その場合、高すぎる、あるいは低すぎる金額を提案しないようにするのが得策である。
これはよくある回帰問題である。しかし、さまざまな理由から、このデータが機密であると考えられているとしよう。請負業者やデータサイエンス・チームと共有できればいいのですが、そうすると、あらゆる法的手続きを踏むことになります。このデータを共有せずに、どうやって正確なモデルを作ることができるでしょうか?
生データを共有するのではなく、その合成版を共有することを試してみてください。
数分で合成データ
SDV は、データを合成するためのPythonライブラリです。テーブル内のデータ、複数のリレーショナルテーブルのデータ、時系列データを模倣することができます。variational autoencoders(VAE)、generative adversarial networks (GAN)、copulasなど、データをモデリングするためのアプロ�ーチもサポートしています。SDVは、生成されたデータの制約を強制したり、個人情報を再編集したりすることができます。実際、モデリングに必要なのは、簡単モードのTabularPresetクラスを使用した、このスニペットだけである:

At a glance, it sure looks plausible! Also included are data quality reports, which give some sense of how well the model believes its results match original data:
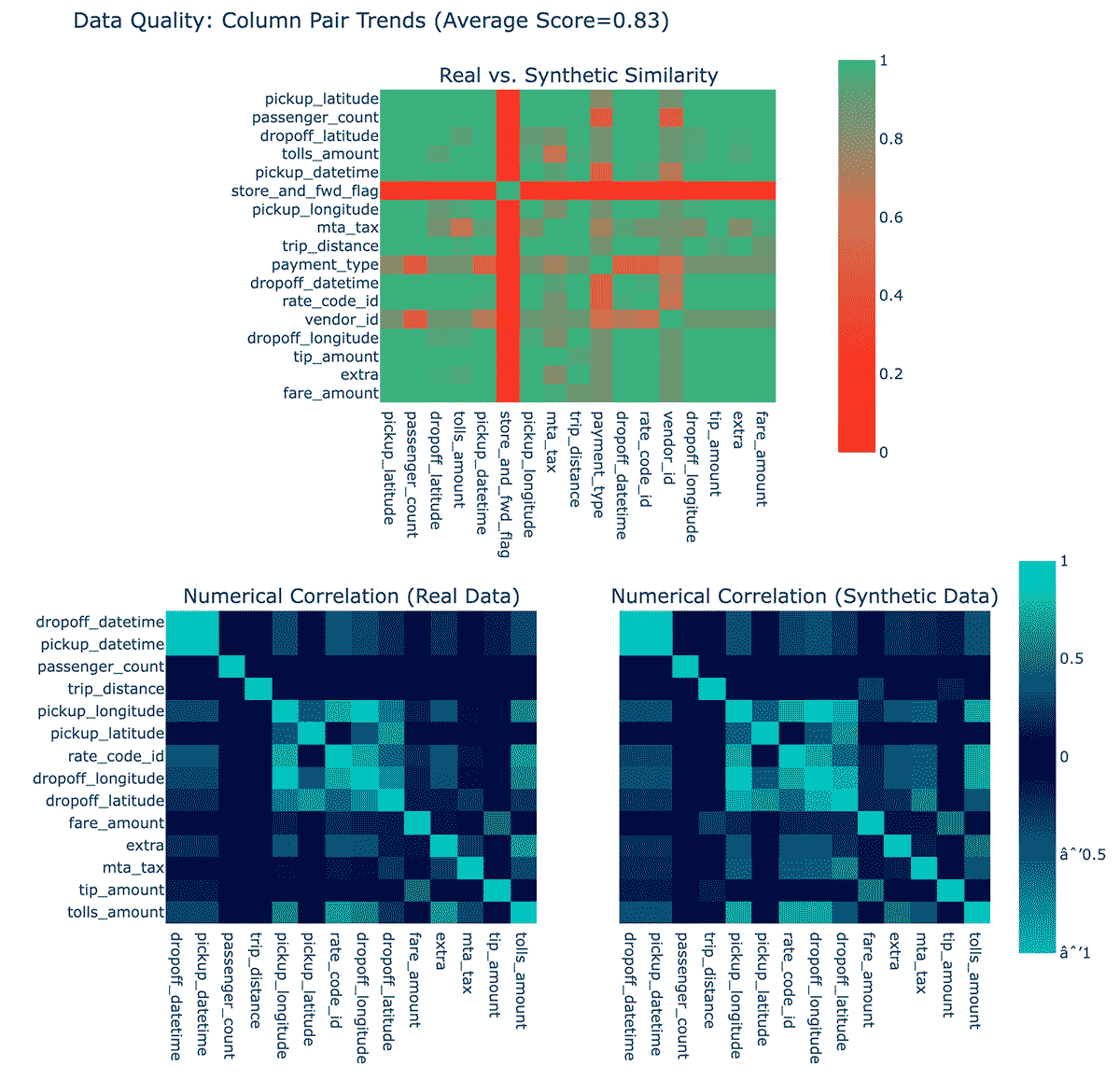
これらのプロットは、各列の合成データの分布がオリジナルとどの程度一致しているか、また合成データと実データの相関関係を示しています。これらを0~100%の間で点数化し、全体として75%を与えています。これは「OK」です。(SDMetricsライブラリでもう少し詳しく説明しています)この時点では、なぜstore_and_fwd_flag列が他の列よりも忠実度が低いのかは不明です。
合成データの品質を評価する
その合成データを詳しく見てみると(おそらくDatabricksのData Visualizationタブを使用!)、問題があることがわかります:
- MTAの税金やチップなど、金額がマイナスになっているものがある。
- 旅客数と距離が0になることも
- 距離は直線距離よりも時折、ありえないほど短くなることがある
- 経度・緯度がニューヨークのどこにもない(あるいは緯度90度以上など全く無効な)場合がある
- 金銭の額が小数点以下2桁以上ある
- ピックアップの時間がドロップオフの時間より後になることもあれば、12時間以上の長時間のシフトになることもある
実際、これらの問題の多くは、元のデータセットに見いだされています。機械学習モデルと同じで、ゴミが入ればゴミが出る。明らかに問題があるデータをエミュレートしようとするよりも、元データの問題を修正する方が価値があります。簡単のために、明らかに悪いデータの行は、他の行と同様に削除することができます:
- 金額がマイナスである
- ドロップオフがピックアップの前にある、またはピックアップの後に不当に長い時間がかかる。
- ロケ地はニューヨークの近郊
- 距離が正しくない、または不当に大きい
- 始点と終点で距離がありえないほど短くなる
本題に入りますが、改善されたフィルター付きのデータセットでやり直すと、品質スコアは82%になります。しかし、品質を向上させるためには、ソースデータを修正する以外にもやるべきことがあります。
制約条件の使用
上記は、実データと合成データが満たすべきいくつかの条件です。データを生成するモ�デルは、本来、生成する値を意味的に理解しているわけではありません。例えば、元のデータセットには、端数のある乗客数やマイナスの距離はない(少なくとも今はない)。優れたモデルであれば、一般的にこれを模倣するように学習しますが、これらが整数でなければならないことがわからない場合は、完璧に模倣できないことがあります。
SDVは、このような制約を表現する手段を提供します。これにより、モデリングプロセスが明らかに悪いデータを出力しないようにするための学習に時間を費やす必要がなくなります。制約は次のようなものです:
また、ユーザーが提供するロジックと複数のカラムを含むカスタム制約を記述することも可能です。例えば、ピックアップとドロップオフの緯度/経度、およびタクシー移動距離が与えられます。この2点間の移動距離は、2点間の直線距離よりも長くすることができますが、短くすることはできません!これは、ハバーシン距離の関係で、5つの列の間にある自明ではない要求関係だ。これをカスタム制約として書くのは簡単で、タクシーのGPSによる緯度経度の不正確さを考慮するために、少し余裕を持たせてもよいでしょう:
再挑戦する前に、より強力なモデルも視野に入れておくとよいでしょう。
高度な合成データモデリング
上記で使用したSDVの簡単なTabularPresetのアプローチでは、Gaussian copulasを採用しています。聞き慣れない名前かもしれませんが、驚くほどシンプルで速く、多くの問題で効果的です。TabularPresetが問題に対してうまく機能しているのであれば、これ以上探す必要はありません。
複雑な問題では、より複雑なモデルがより良い結果をもたらす可能性があります。SDVは、GANやVAEに基づくアプローチもサポートしています。どちらもディープラーニングを採用したアイデアですが、その方法はさまざまです。GANは、データを生成するモデルと、合成データを検出するために学習するモデルの2つを互いに戦わせ、その出力が本物と見分けがつかなくなるまで生成モデルを改良していきます。VAEは、実データを解読するだけでなく、新しい合成データも空中から「解読」できるように、実データの暗号化を学習します。
どちらも計算量が多く、合理的な時間で処理するにはGPUが必要です。単純なアプローチではエミュレートが難しいデータセットや、カクテルパーティーで「GANを活用しているんですよ」と言えるようなデータセットであれば、SDVの CTGANとTVAEがおすすめです。
この後のアップグレードされた例でTVAEを試すのは、もう手間ではありません。また、MLflowを追加することで、メトリクスのログを取り、さらにTVAEモデル自体をpredict関数でデータを増やすだけのモデルとして管理することも可能です:
MLflowの使用について! モデルを MLflow に登録すると、正確なモデルがバージョン管理されたレジストリに記録されます。 反復開発中に作成されたさまざまなモデルの記録を提供するだけでなく、MLflow レジストリを使用すると、他のユーザーにアクセスを許可して、モデルを取得し、合成データを自分で生成することができます。
実際、MLflow からこれらのプロットを確認できます。 品質は 83% までわずかに向上し、新しいプロットが利用可能になり、各列の合成の品質がそれ自体で分類されます。
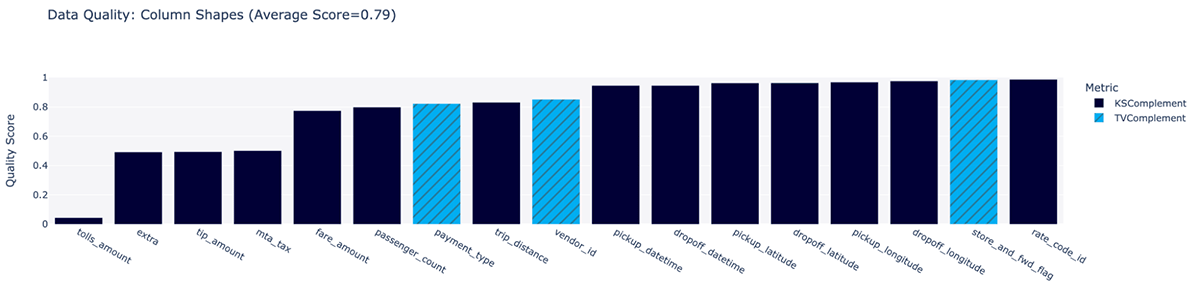
合成データの生成
宿題が終われば、いくらでも合成データを簡単に生成できます。 ここでは、いくつかの新しく生成されたデータがデルタ テーブルに配置されます。 MLflow からモデルをロードし、データ生成モデルを使用する単純な Python 関数を記述し、それを Spark と並行してダミー入力に "適用" するだけです (UDF には入力が必要ですが、データ生成プロセスには実際には何も必要ありません) 単に結果を書き込みます。

Spark は、テラバイト単位で生成する必要がある場合に備えて、生成を並列化するのに非常に役立ちます。 これは、必要なだけ並列化します。
時間、場所などは確かに良くなっています。 pandas-profiling は、実際のデータと合成データを比較する方法を異なる方法で提供できます。 これはレポートのほんの一部です。
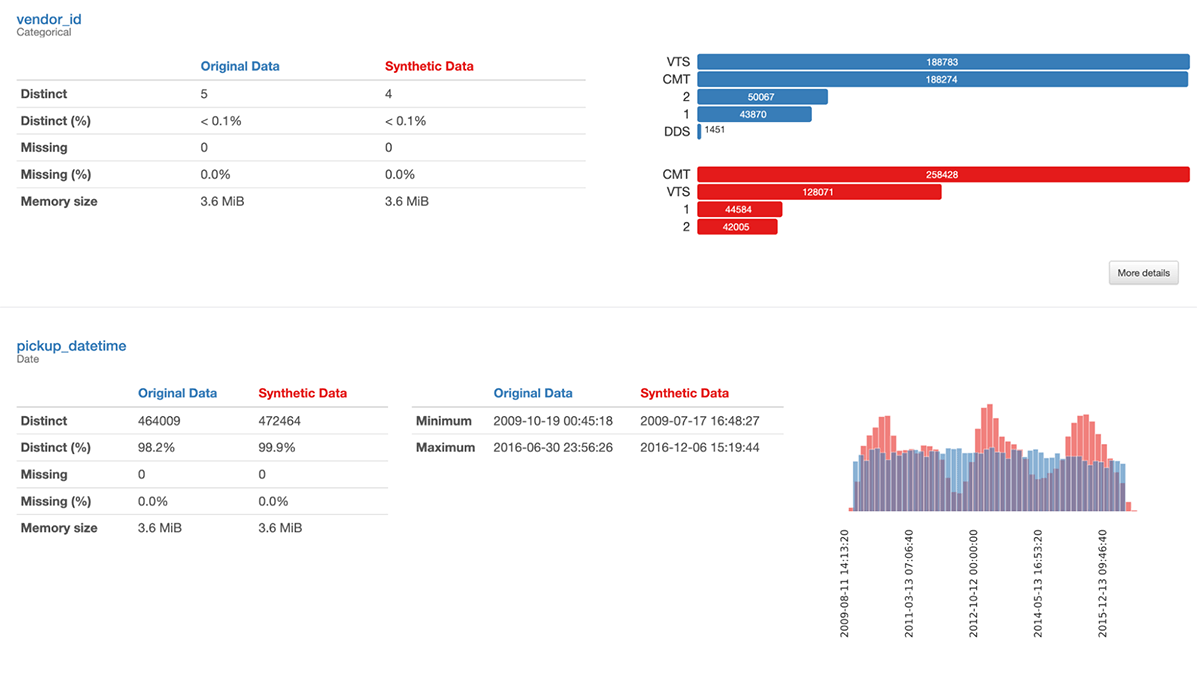
これにより、品質が 100% ではない理由が詳しくわかります。 たとえば、元のデータはかなり均一であったのに対し、合成データの乗車時間と降車時間には奇妙な不均一性があります。
今のところはこれで十分ですが、合成データ生成プロセスは、他の機械学習プロセスと同じようにここから繰り返され、データと合成プロセスの新しい改善点を発見して品質を向上させる可能性があります。
合成データを使ったモデリング
元のタスクは、データを構成するだけでなく、ヒントを予測することでした。 合成データで機械学習モデルを有用に構築できますか? まともなモデルがこのデータで何をするかを手動で理解するのに時間を費やすのではなく、Databricks Auto ML を使用して最初のパスを作成します。
A few hours later:
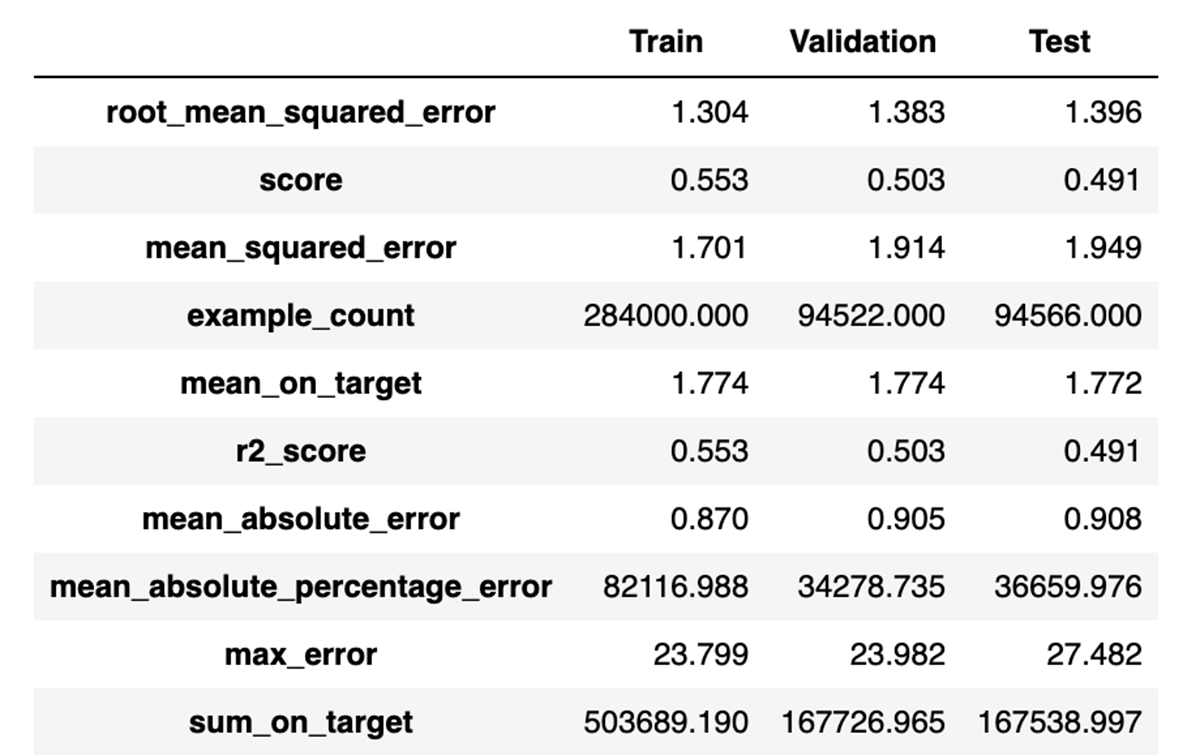
どのモデルが最もうまく機能したかの詳細はここでは問題になりません (おめでとうございます、 lightgbm) が、これは適切なモデルがヒントを予測するときに約 1.4 の RMSE を達成でき、R2 が 0.49 であることを示唆しています。
これは、ホールドアウトされた実際のデータのサンプルでモデルを評価した場合に有効ですか? はい、結局のところ、合成データに基づいて構築されたこの最良のモデルは、約 1.52 の RMSE と約 0.49 の R2 も達成しています。 これは優れたモデル パフォーマンスではありませんが、ひどいものではありません。
対照的に、合成データではなく実際のデータから始めていたら、ここで何が起こったでしょうか? Auto ML を再実行し、数時間休憩してから戻ってきて、次を見つけます。
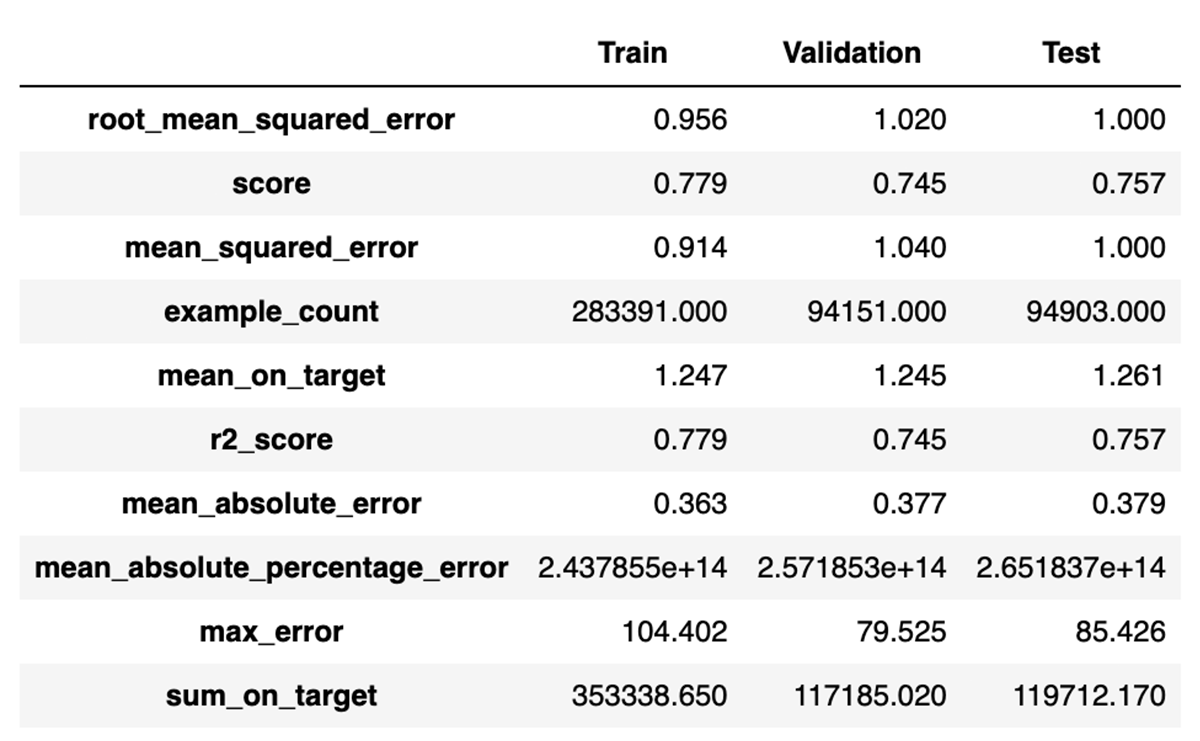
まあ、それはかなり良いです。 さらに、この最良のモデルを実際のデータの同じホールドアウト サンプルでテストすると、同様の結果が得られます。RMSE は 0.94、R2 は 0.78 です。
この場合、実際のデータをモデル化すると、はるかに正確なモデルが生成されます。 それでも、合成データのモデリングによって何かが達成されました。 実際のデータにアクセスせずに、このデータセットでモデルを構築するための実行可能なアプローチであることが証明されました。 それはまずまずのモデルを生成し、他のユースケースでは、��合成データのパフォーマンスは同等である可能性さえあります.
これを過小評価しないでください。 これは、機密データにアクセスできない請負業者などによって、モデリング アプローチがハッシュ アウトされる可能性があることを意味します。 パイプラインは、モデルではなく重要な成果物でした。 その後、パイプラインは他のチームによって実際のデータに適用される可能性があります。 チーム間でパイプラインの開発とデプロイを分割する方法の詳細については、Big Book of MLops を参照してください。
最後に、合成データはデータ拡張の戦略にもなります。 実際のデータにアクセスできるチームの場合、合成データを追加すると、モデルがわずかに改善される可能性があります。 好奇心のために、結果を繰り返さないでください。実際のデータと合成データを組み合わせて使用する Auto ML でのこの同じアプローチでは、0.95 の RMSE と 0.77 の R2 が得られます。 この場合は実質的に違いはありませんが、他の場合は可能性があります。
まとめ
ジェネレーティブ AI の力は、面白いチャットだけにとどまりません。 現実的な合成ビジネス データを作成できます。これは、機微な実際のデータへのアクセスを簡単に保護できない機械学習チームにとって有用な代役となる可能性があります。 SDV のようなツールを使用すると、このプロセスをわずか数行のコードで実行でき、結果のモデルとデータを管理するために Spark、Delta、および MLflow とうまく組み合わせることができます。

Databricksの投稿を見逃さないようにしましょう
次は何ですか?


データサイエンス・ML
October 30, 2024/1分未満