Databricks上のPyTorch - Spark PyTorch Distributor の紹介

Original Blog : PyTorch on Databricks - Introducing the Spark PyTorch Distributor
翻訳: junichi.maruyama
背景と動機
ディープラーニングのアルゴリズムは複雑で、トレーニングに時間がかかりますが、これらのアルゴリズムが実現する価値のために、研究室から生産現場へと急速に移行しつつあります。学習済みのモデルを使用して微調整する場合でも、ネットワークをゼロから構築する場合でも、学習時のメモリと計算負荷はすぐにボトルネックとなります。このような制約を克服するための手�段として、一般的な最初の防御策は、分散学習を活用することです。Tensorflowにはspark-tensorflow-distributorがありますが、PyTorchには同等のものがありませんでした。
Apache Sparkクラスタでの分散PyTorchトレーニングを簡素化するTorchDistributorライブラリをようやく発表することができました。この記事では、新しいライブラリとその使用方法について説明します。Databricksはまた、これをオープンソースコミュニティに還元することを誇りに思っています。
歴史的に、Sparkで作業する場合、Horovodが主な配布メカニズムであり、特にPyTorchの初期の形成期には配布のためのAPIが非常に未熟だったため、好ましいアプローチでした。しかし、このメカニズムでは、Horovodが提供する機能を十分に活用するために、コードの再フォーマットと追加のチューニングや最適化の両方が必要でした。
ディープラーニングのアルゴリズムを配布する場合、データ並列とモデル並列の2つのアプローチが存在する。Model Parallelトレーニングは、依然として学術研究や大規模な産業研究所の分野であり、Data Parallelismはトレーニングをスケールアップするための最も一般的な方法論である。
データ並列は、初期のtorch data parallel implementation(dp)以来、大きく進歩しています。しかし、Horovodは、基本的なData Parallelのシナリオにしか取り組んでいません。しかし、Large Language Models(LLM)の台頭により、GPU Ramが共通のボトルネックとなり、より効率的な新しいData Parallelの方法論が求められています。
PyTorchのデータ並列の新しいネイティブ実装には、Distributed Data Parallel, `ddp` と Fully Shared Data Parallel`fsdp` があります。ddpがレガシーなdpよりずっと好まれる理由はこちらを、fsdpについてはこちらを参照してください。要するに、ddpは各トレーニング反復の一部としてGPU間でそれほど多くのデータを転送せず、またより効率的に並列化し、オーバーヘッドを削減します。Fsdpは、RAMを節約するためにモデルを異なるGPUに分割し、モデル並列技術に切り替えることなく、バッチサイズを大きくしてより大きなモデルの学習を可能にします。
オープンソースコミュニティでは、 `deepspeed` や`colossal`といったライブラリが、不足するGPUリソースを効率的に使用する上で有望であることが示されています。ddp、fsdp、deepspeed、colossalなどを利用するためには、Horovodを大幅に作り直すか、新しい配布メカニズムが必要でした。
TorchDistributorは、このような進化を念頭に置いて開発されました。TorchDistributorがあれば、これらの新しい配布技術をよりよくサポートし、OSSコミュニティの新しいイノベーションを容易にサポートできるようになるでしょう。
アーキテクチャーのアプローチ
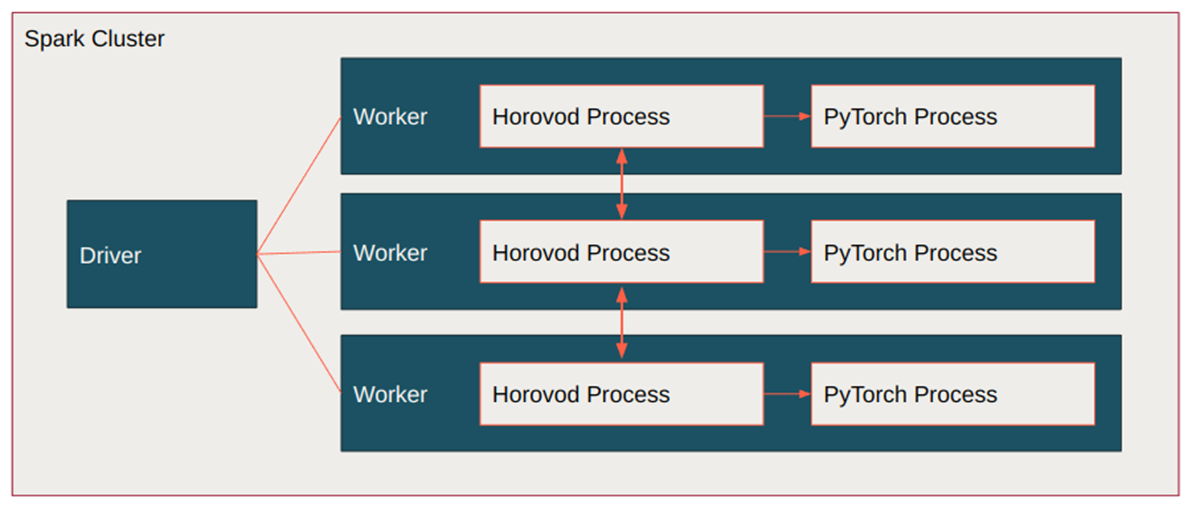
Horovodでは、配布の仕組みやノード間通信を制御しているため、`fsdp`のような新しい開発は、Horovodのプロセスに戻って再実装する必要がありました。
一方、Spark-Tensorflow-Distributor ライブラリをベースにしたTorchDistributorは、Apache Sparkクラスタ上でネイティブな分散PyTorchおよびPyTorch Lightning APIを直接活用する仕組みを提供します。Spark の Barrier 実行モードは、ネイティブの PyTorch `torch.distributed.run` API を実行するために使用され、これは torchrun CLI コマンドが bash スクリプトで実行するものでもある。
TorchDistributorはPyTorchのプロセスを起動し、プロセスの連携を確保するためだけに動作する配布メカニズムをPyTorchに委ねます。
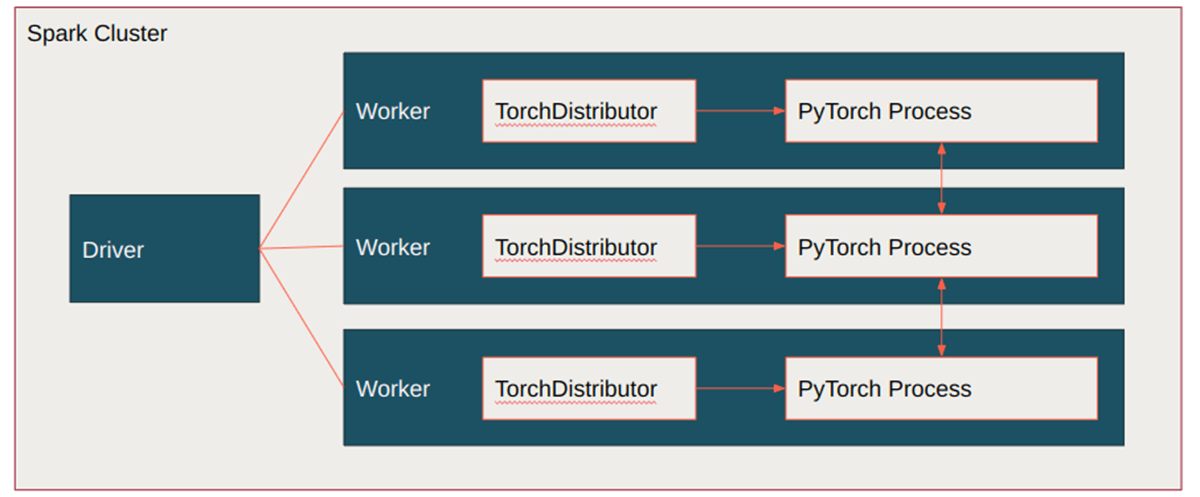
この新しいモジュールにより、コードのリファクタリングが不要になり、オープンソースコミュニティからのチュートリアルをSparkとメイントレーニングループに直接プラグインすることができます。Torchrunは、PyTorchがすべての分散トレーニングルーチンに向けて進んでいる方向性であり、これを活用することで、私たちのアプローチの将来性を確保することができます。
TorchDistributorを使用する
NOTE ML Runtime 13.x and above required
TorchDistributorの使い方はシンプルで、いくつかの主な設定を考慮する必要があります。
一般的な構成は
TorchDistributorは、主に3つの構成があります。
- num_processesは、実行するsparkタスクの数を指します
- local_modeは、ドライバノードでのトレーニングとワーカーノードでのトレーニングのことを指します。1つのノードでトレーニングする場合は、local_mode=Trueとします
- use_gpuは、GPUを使ったトレーニングを行うか否かを決定します
GPUを使ったトレーニングを行う場合、TorchDistributorはSpark Task1つにつき1GPUを割り当てるように設定されています。つまり、num_processes=2であれば、1GPUずつ2つのSpark Taskが作成されます。また、マルチノードでトレーニングする場合、local_mode=Falseにすると、ドライバノードはトレーニングに使用されないので、コスト削減のため、小さなGPUノードに設定することをお勧めします。これはクラスタ作成ページから設定することができます。
runコマンドでは、<function_or_script>はノートブックにあるpython関数か、オブジェクトストアにあるトレーニングスクリプトへのパスとなります。<args>は<function_or_script>に入力する引数のカンマ区切りリストです。
TorchDistributorは、関数を実行すると、その戻り値を出力します。スクリプトファイルを実行するように設定されている場合は、スクリプトの出力を返します。
�例として、DataBricksノートブックの引数arg1を受け取るtrain関数を使って、2つのGPUを持つ1つのノードでTorchDistributorを実行する方法を紹介します:
TorchDistributorの同機能をマルチノードクラスターで実行する場合、8GPUを使用し、デフォルトの1GPU/sparkタスク設定で実行します:
train関数の構造については、このpytorch ddpの例を参照してください。しかし、いくつかの変更が必要です。'rank`、`local_rank`、`world_size`はTorchDistributorが計算し、環境変数RANK、WORLD_SIZE、LOCAL_RANKに設定されるので、手動で管理・設定するのではなく、os.environ[]から読み込む必要がある。
PyTorchのKerasであるPyTorch LightningもTorchDistributorと一緒に使うことができます。PyTorch Lightningの詳しい紹介はこちらをご覧ください。リンク先のコードをTorchDistributorで使用するには、TRAINING LOOPセクションをPython関数にラップして、必要な引数と一緒にrunコマンドに入れるだけです。
上記のように、runコマンドはPython CLIトレーニングスクリプトと一緒に使うことで、移行を容易にすることもできます。例えば、以下のような感じです:
は、2つのGPUを持つ1つのノードでファイル '/path/to/train.py' を実行し、スクリプト内の引数パーサーに引数 '--lr=0.01' を入力します。
torch.distributed.run で動作するように設計されたスクリプトは、TorchDistributorで動作します。重要な設計目標の1つは、CLI経由で起動するように設計された既存のコードベースとの互換性を確保すると同時に、完全なインタラクティブなノートブック体験をサポートできるようにすることでした。CLIソリューションとは異なり、SparkとTorchDistributorが各ノードでのコード実行をトリガーし、ネットワーク接続が完全であることを確認できるため、これらを手動で確認、設定する必要がありません。
スケーリングとパフォーマンス
新しい手法を導入する際によくある質問は、既存のソリューションと比較してどの程度のパフォーマンスが得られるか、というものです。
これを検証するために、imagenetteデータセットに対して、resnet50モデルで15エポックを学習させ、分類タスクを引き受けました。これはAWS上のg4dnノードでPyTorch Lightning 1.7.7で実行されました。ベンチマークレポはこちらのノートブックを参照し、自分の環境で再現してください。
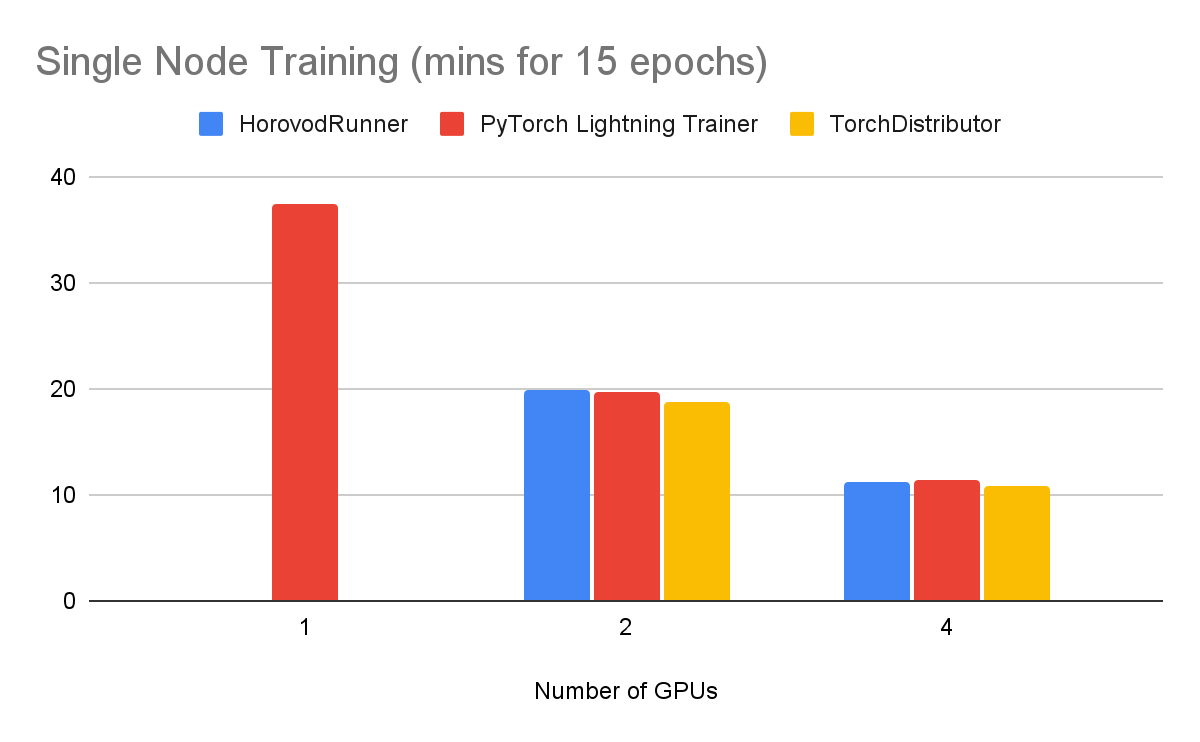
シングルノードのトレーニングでは、以下のようなパフォーマンスが得られました:
2つのノードでトレーニングしたところ、以下のようなパフォーマンスが確認されました。
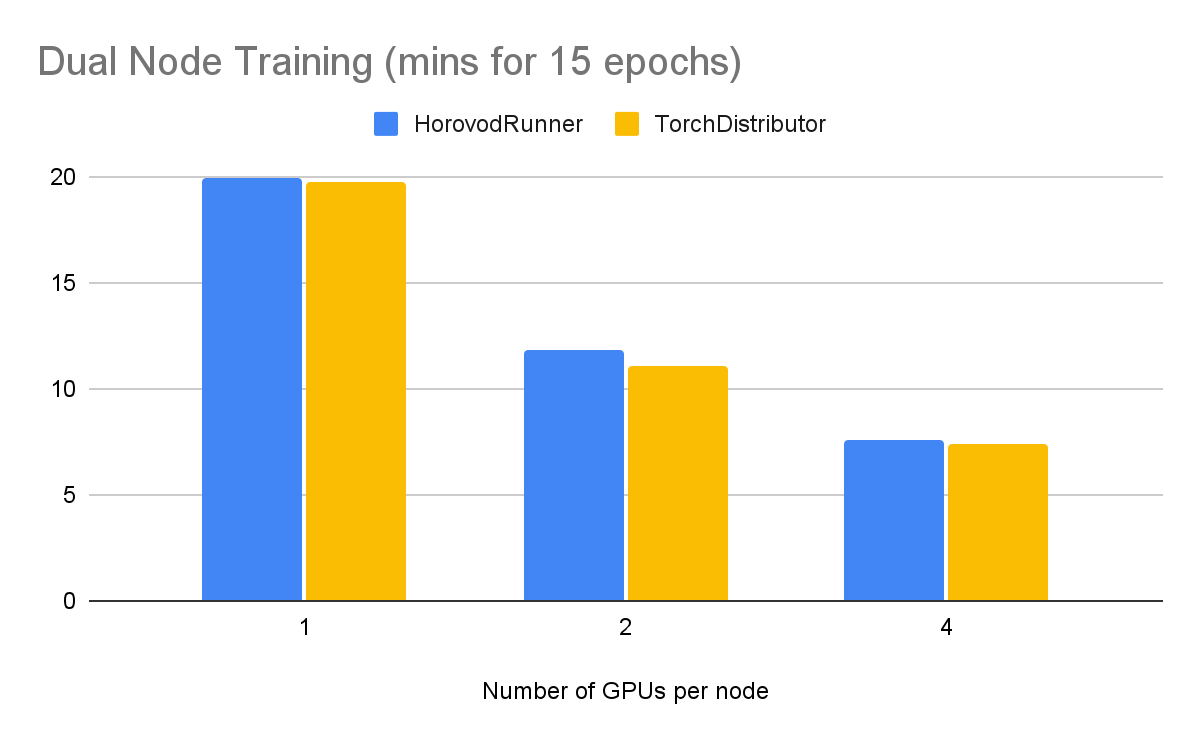
GPUを追加することで、学習時間を短縮できることがわかりますが、スケーリングは収穫が少なくなっています。
TorchDistributorによって、PyTorchとこのフレームワークの周りで成長してきた関連エコシステムのネイティブなApache Sparkサポートを提供できることを誇りに思います。完全なコード例については、こちらのノートブックを参照してください。

Databricksの投稿を見逃さないようにしましょう
次は何ですか?


データサイエンス・ML
October 30, 2024/1分未満