Mosaic AIモデルサービングでDBRX推論を高速化

イントロダクション
このブログポストでは、Databricksが作成したオープンな最新大規模言語モデル(LLM)であるDBRXを使った推論を紹介します(DBRXの紹介を参照 )。DBRXがどのように効率的な推論と高度なモデル品質の両方を実現するために一から設計されたかを説明し、私たちのプラットフォームでどのように最先端のパフォーマンスを達成したかを要約し、最後にモデルとの対話方法に関する実践的なヒントを紹介します。
Mosaic AIモデルサービングは、 ハイパフォーマンスでプロダクショングレードのエンタープライズ対応プラットフォーム上のDBRX Instructに即座にアクセスすることができます。 ユーザーは即座に実験やプロトタイプアプリケーションを構築し、その後スムーズに本番グレードの推論プラットフォームへ移行することができます。
今すぐDBRXをお試しください!
- Databricksワークスペース内のAI Playground(米国のみ)
- OpenAI SDKを使って Databricks上のLLMのクエリを始めるには
- 公開デモ: huggingface.co/spaces/databricks/dbrx-instruct
DBRX Instructに対する需要は非常に巨大です。 何百もの企業が、Databricks��プラットフォーム上でこのモデルの機能を探求し始めています。
Databricksは、Nasdaqの最も重要なデータシステムのいくつかにおいて、重要なパートナーです。 DBRXのリリースに興奮しています。 強力なモデル性能と有利なサービングエコノミクスの組み合わせは、Nasdaqで生成AIの利用を拡大する上で、私たちが求めているイノベーションです。 - Nasdaq、AIおよびデータサービス部門責任者、Mike O'Rourke氏
また、MLコミュニティをサポートするために、モデルのアーキテクチャと重みをオープンソース化し、最適化された推論コードをvLLMやTRT-LLMのような主要なオープンソースプロジェクトに提供しました。
DBRX-Instructの統合は、私たちのAIモデル群に驚異的な付加価値をもたらし、オープンソースのサポートに対する私たちの取り組みを強調しています。 ユーザーからの様々な質問に対して、迅速かつ質の高い回�答を提供しています。 You.comではまだ新しいサービスですが、すでにユーザーの間で盛り上がりを見せており、利用が広がることを楽しみにしています。 - You.com、シニアエンジニアリングマネージャー、Saahil Jain氏
Databricks ではデータインテリジェンスプラットフォームの構築に注力しています。データインテリジェンスプラットフォームとは、統合されたデータレイクハウスの上に構築された、生成AIを組み込んだインテリジェンスエンジンです。DBRX Instructのような強力で即座に利用可能なLLMは、このための重要なビルディングブロックです。さらに、DBRXのオープンな重みは、お客様がDBRXをさらに訓練し、適応させることで、ターゲットドメインや独自データのユニークなニュアンスまで理解できるようになります。
DBRX Instructは、企業顧客にとって重要なアプリケーション(コード生成、SQL 、およびRAG)にとって特に有能なモデルです。検索拡張生成(RAG)では、プロンプトに関連するコンテンツがデータベースから検索され、プロンプトと一緒に提示されることで、そうでない場合よりも多くの情報をモデルに与えます。 RAGのユースケースで優れた結果を出すためには、モデルは長い入力をサポートする必要があるだけでなく(DBRXは最大32Kトークンの入力で学習されました)、入力��の奥深くに埋もれている関連情報を見つけることもできなければなりません(Lost in the Middleの論文参照 )。
ロングコンテクストおよびRAGベンチマークにおいて、DBRX InstructはGPT-3.5 Turboおよび主要なオープンLLMよりも優れた性能を発揮します。 表1は、2つのRAGベンチマーク(Natural QuestionsとHotPotQA)において、Wikipediaの記事コーパスから検索された上位10行をモデルに与えた場合のDBRX Instructの品質を示しています。
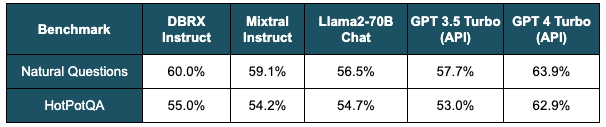
表1:RAGベンチマーク。bge-large-en-v1.5を用いてWikipediaコーパスから検索された上位10行を各モデルに与えた場合の各モデルの性能。 精度は、モデルの答えの範囲内で一致するかどうかで測定されました。 GPT-4 Turbo以外ではDBRX Instructが最高スコア。
本質的に効率的なアーキテクチャ
DBRXはMoE(Mixture-of-Experts)デコーダ専用のトランスフォーマーモデルです。総パラメータは1,320億ですが、推論時に1トークンあたり360億のアクティブパラメータしか使用しません。 学習方法の詳細については、以前のブログ記事を参照してください。
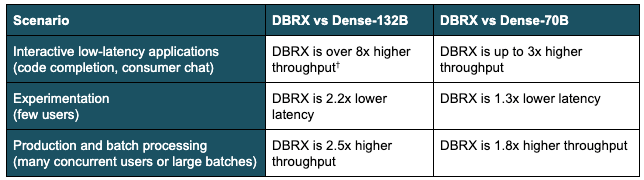
表2:さまざまなシナリオにおけるMoEの推論効率。この表は、DBRXのようなMoEが、比較可能なサイズの高密度モデルや、一般的な高密度70Bモデルのフォームファクター(最大出力トークン/秒、出力トークンあたりの目標時間< 30ms)に対して持つ利点をまとめたものです。この要約は、8ウェイテンソル並列と16ビット精度のH100サーバー上のさまざまなベンチマークに基づいています。図1と図2にその詳細を示します。
密なモデルではなくMoEアーキテクチャを選んだのは、MoEがより効率的にトレーニングできるからだけでなく、サービング時間の利点もあります。 モデルの改良は難しい課題です。私たちは、モデルの使いやすさとスピードを損なうことなく、予測可能かつ確実にモデルの能力を向上させることが私たちの研究で示されている、パラメータ数のスケーリングを行いたいと考えています。 MoEは、トレーニングやサービスのコストを比例して大きく増加させることなく、パラメータ数を拡大することを可能にし�ます。
DBRXのスパース性は、推論効率をアーキテクチャに組み込むことで、全パラメータをアクティブにする代わりに、入力トークンごとにレイヤーあたり全16個のうち4個のエキスパートのみをアクティブにします。このスパース性が性能に与える影響は、図1と2に示すようにバッチサイズに依存します。 以前のブログ記事で説明したように 、モデル帯域幅利用率(MBU)とモデルフロップス利用率(MFU)の両方が、与えられたハードウェアセットアップで推論速度をどこまで押し上げられるかを決定します。
第一に、低いバッチサイズでは、DBRXは同サイズの密なモデルの0.4倍以下のリクエストレイテンシです。 この領域では、NVIDIA H100のようなハイエンドGPUでは、モデルはメモリ帯域幅に制限されます。 簡単に言うと、最新のGPUは、1秒間に数兆の浮動小数点演算、運用を実行できるテンソルコアを備えているため、サービングエンジンは、メモリがコンピュートユニットにデータを提供できる速度がボトルネックになります。 DBRXが1つのリクエストを処理するとき、1320億のパラメータをすべてロードする必要はありません。360億のパラメータをロードするだけで終わります。 図1は、バッチサイズが小さい場合のDBRXの優位性を強調したもので、この優位性はバッチサイズが大きくなると狭まりますが、依然として大きいままです。
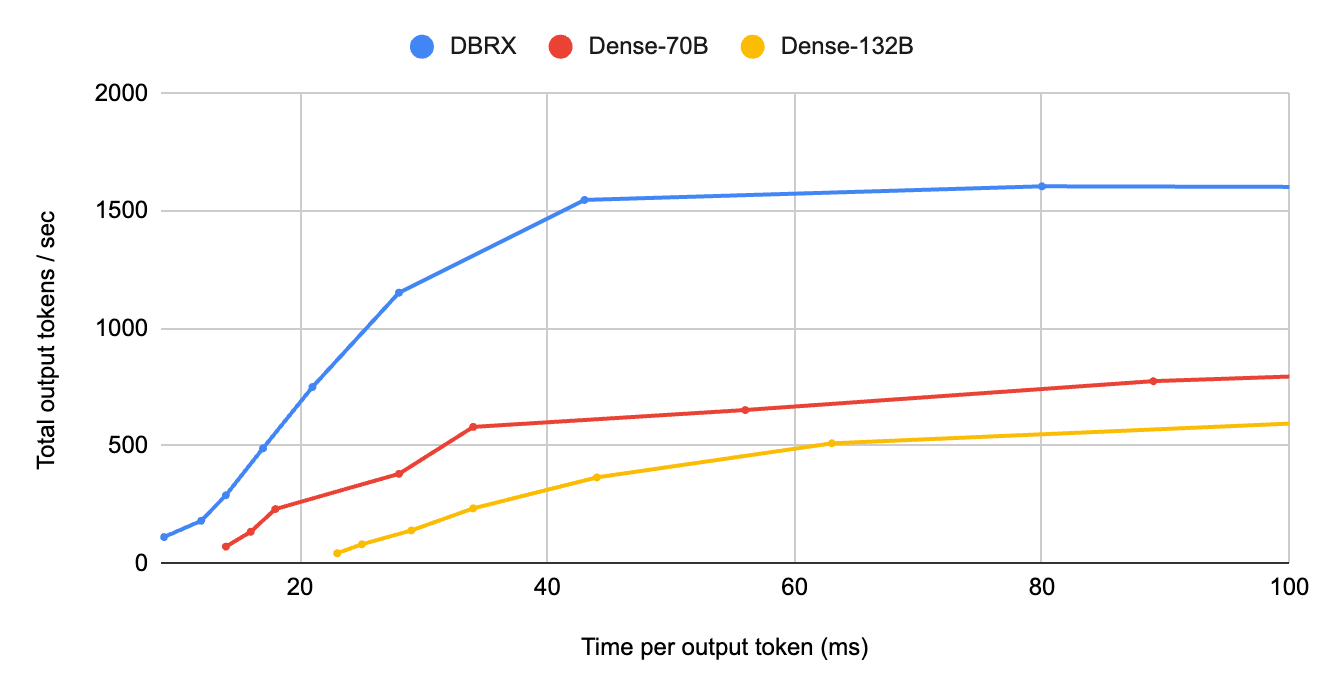
図1:MoEは、インタラクティブなアプリケーションに適しています。 多くのアプリケーションは厳しい時間予算内でレスポンスを生成する必要があります。DBRXのようなMoEと高密度モデルを比較すると、DBRXは出力トークンあたり30ミリ秒以下を目標にした場合、1秒あたり8倍以上の総トークンを生成できることがわかります。これは、モデルサーバーが個々のユーザーエクスペリエンスを損なうことなく、桁違いの同時リクエストを処理できることを意味します。これらのベンチマークは、各モデルに最適化された推論実装を用い、16ビット精度と8ウェイテンソル並列を使用してH100サーバー上で実行されました。
第二に、コンピュートバウンド、つまりGPUの速度がボトルネックとなるワークロードの場合、MoEアーキテクチャは、必要な計算の総数を大幅に削減します。 つまり、同時リクエストや入力プロンプトの長さが長くなるにつれて、MoEモデルは、密な対応するモデルよりも大幅にスケーリングが向上します。 このような領域では、図2で強調されているように、DBRXは同等の高密度モ��デルと比較して、デコードスループットを最大2.5倍まで向上させることができます。検索拡張世代(RAG)ワークロードを実行するユーザーは、特に大きな利点を享受できます。 Sparkや他のバッチパイプラインで多数のドキュメントを処理するためにDBRXを使用するワークロードも同様です。
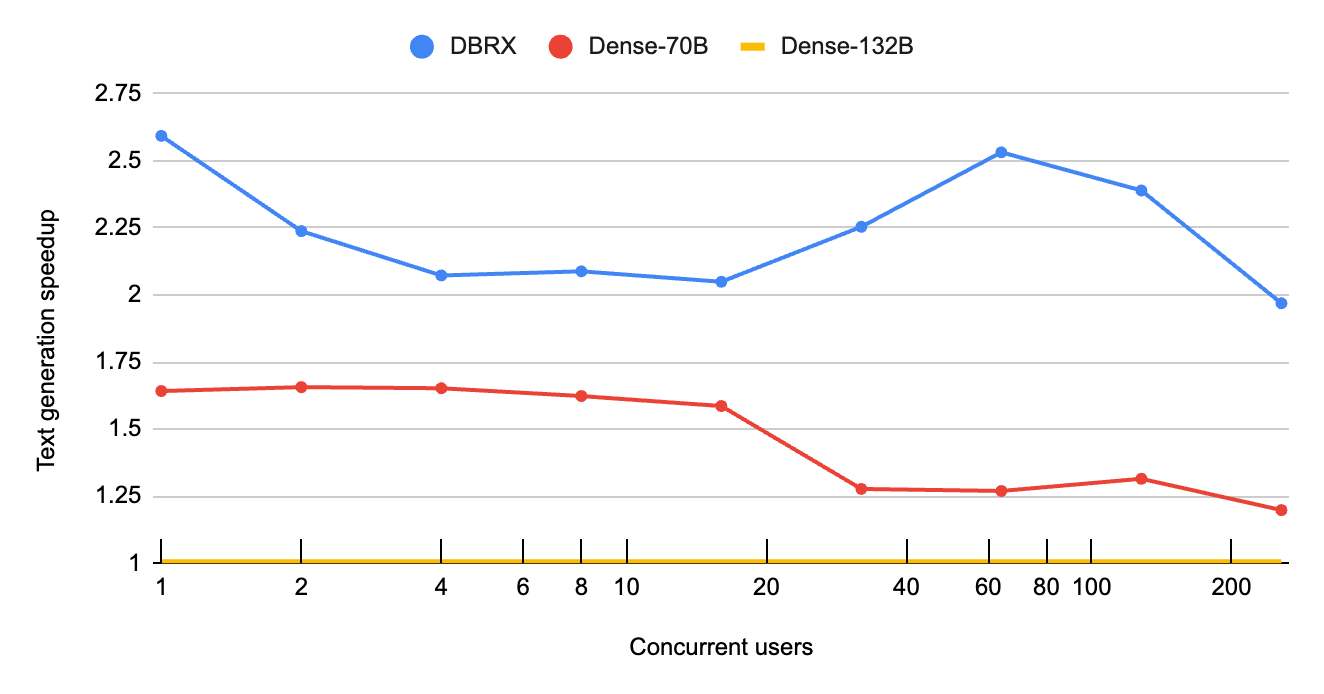
図2:MoEはスケーリングに優れています。 DBRXのようなMoEを密なモデルと比較すると、テキスト生成率*はバッチサイズ(*1秒あたりの総出力トークン数)が大きいほどスケーリングに優れていることがわかります。DBRXは同サイズの密なモデル(Dense-132B)と比較して、一貫して2倍以上のスループットを実現しています。DBRXのスピードアップはバッチのサイズが大きくなるほど加速します。同時ユーザー数が32を超えると、DBRXは主要な高密度70Bモデルの2倍のスピードに達します。これらのベンチマークは図1と同じセットアップを使用しています。
きめ細かい専門家の混合
DBRXは きめ細かい MoEで、より多くの小さなエキスパートを使用することを意味します。 DBRXは16人のエキスパートを持ち、4人を選びますが、MixtralとGrok-1は8人のエキスパートを持ち、2人を選びます。これにより65倍の専門家の組み合わせが可能になり、モデルの品質が向上することがわかりました。
さらに、DBRXは比較的浅く広いモデルであるため、テンソル並列の方が推論のパフォーマンスが向上します。 DBRXとMixtral-8x22Bのパラメーター数はほぼ同じ(DBRXは132B、Mixtralは140B)ですが、Mixtralのレイヤー数は1.4倍(40対56)です。 高密度のモデルであるLlama2と比べると、DBRXのレイヤー数は半分(40対80)です。 レイヤーが多くなると、複数のGPUで推論を実行する際に、クロスGPUコールがより高価になる傾向があります(このような大規模モデルの要件)。 DBRXの相対的な浅さは、Llama2-70Bと比較して、中程度のバッチサイズ(4~16)で高いスループットを示す理由のひとつです(図1参照)。
DBRXは多くの小さなエキスパートで高品質を維持するために、「ドロップレス」MoEルーティングを使用しています。これはオープンソースのトレーニングライブラリ MegaBlocksによって開拓されたテクニック です (MegaBlocksをDatabricksに導入するを参照 )。MegaBlocksは、Mixtralのような他の主要なMoEモデルの開発にも使用されています。
これまでのMoEフレームワーク(図3)では、モデルの品質とハードウェア効率のトレードオフを余儀なくされていました。エキスパートには固定容量があるため、ユーザーはトークンを時折削除するか(品質低下)、パディングによって計算を無駄にするか(ハードウェア効率低下)のどちらかを選択しなければなりませんでした。これとは対照的に(図4)、MegaBlocks(論文)はブロック・スパース・オペレーション、運用を使用してMoE計算を再定式化し、エキスパートの容量を動的にサイズ調整し、最新のGPUカーネルで効率的に計算できるようにしました。

図3:従来のMoE(Mixture-of-Experts)レイヤ。 ルーターは入力トークンのエキスパートへのマッピングを生成し、割り当ての信頼性を反映する確率を生�成します。 トークンはtop_kの エキスパートに 送られます (DBRXでは top_kは4)。 エキスパートには固定の入力容量があり、動的にルーティングされたトークンがこの容量を超えた場合、いくつかのトークンはドロップされます(上部の赤い領域を参照)。逆に、エキスパートにルーティングされるトークンが少ないと、パディングによって計算容量が無駄になります(下部の赤い部分を参照)。
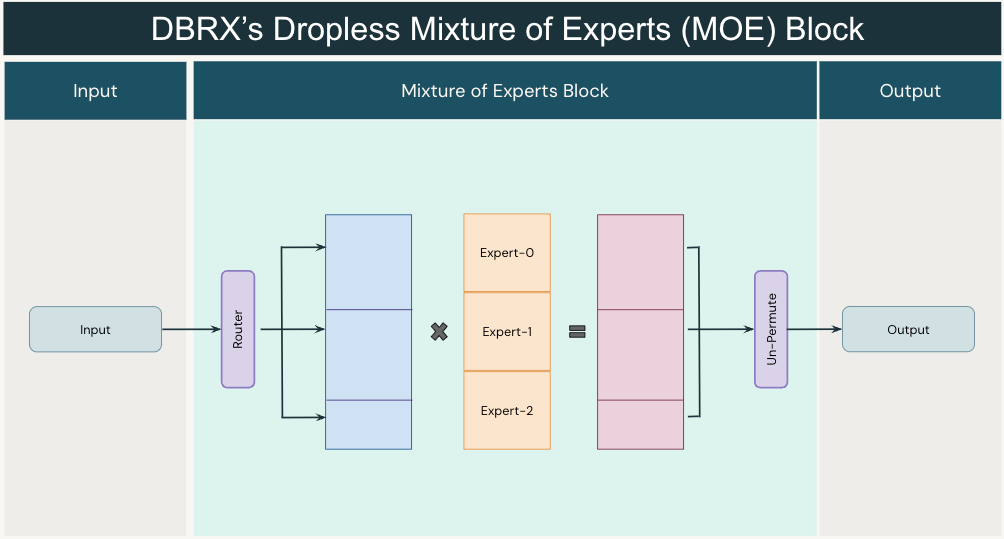
図4:ドロップレスMoEレイヤー。 ルーターは以前と同様に動作し、各トークンをトップ_kのエキスパートにルーティングします。 しかし、トークンのドロップや容量の浪費を避けるために、可変サイズのブロックと効率的な行列乗算を使用します。MegaBlocksはブロック・スパース行列乗算の使用を提案しています。実際には最適化されたGroupGEMMカーネルを推論に使用します。
パフォーマンスのための設計
前節で説明したように、DBRXアーキテクチャによる推論には固有の利点があります。 それにもかかわらず、最先端の推論性能を達成するには、相当量の慎重なエンジニアリングが必要です。
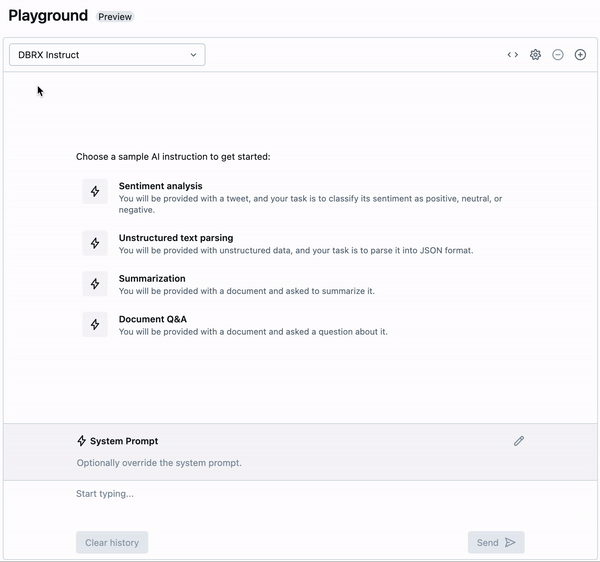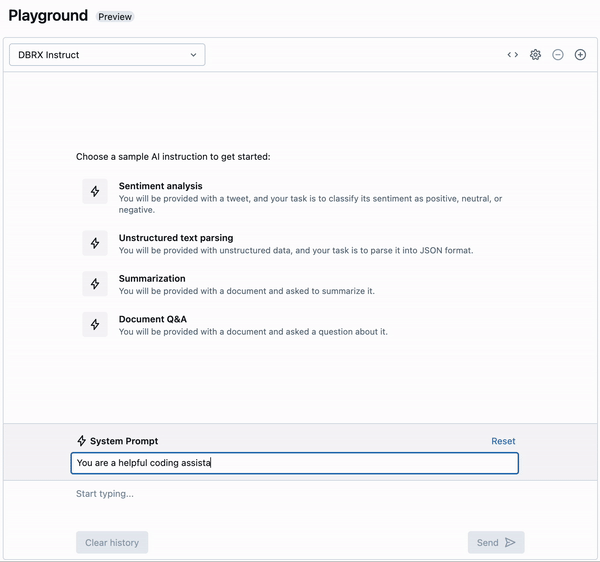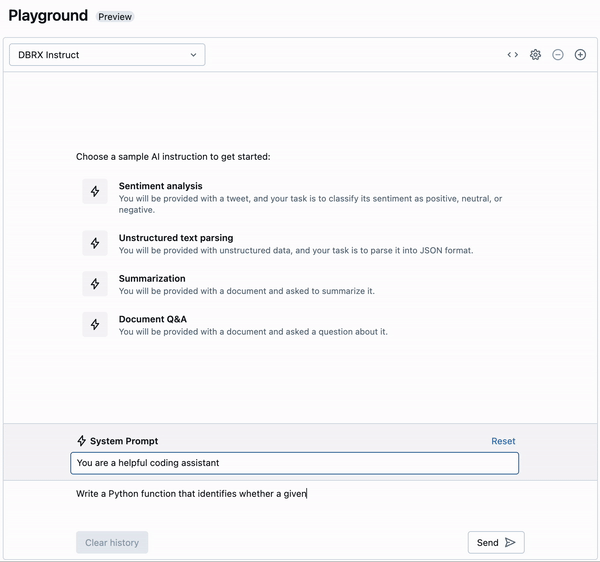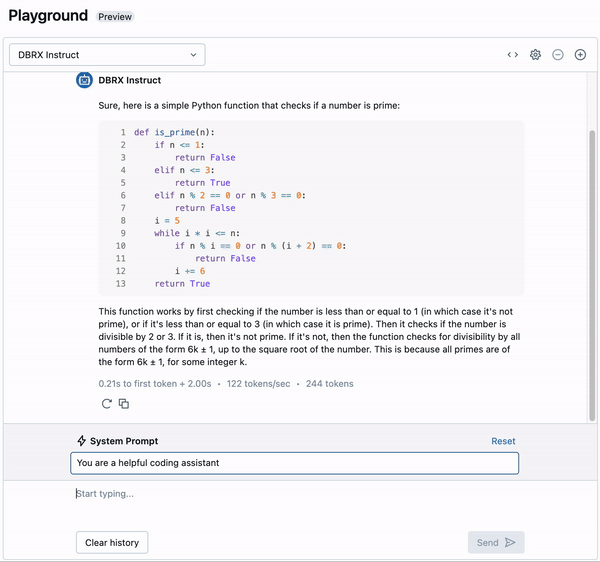
図5:Databricks AI PlaygroundにおけるDBRX。 Foundation Model APIのユーザーは、DBRXのテキスト生成速度が最大で毎秒150トークンになることを期待できます。
私たちは、高性能なLLM推論スタックに深い投資を行い、DBRXに焦点を当てた新しい最適化を実装しました。 フューズドカーネルやMoEレイヤーのGroupGEMM、DBRXの量子化など、多くの最適化を適用しました。
企業ユースケースに最適化:特にDBRXが得意とする長いコンテキストのリクエストにおいて、レイテンシを許容レベル以下に低下させることなく、高いスループットで多くのトラフィックを持つワークロードをサポートするためにサーバーを最適化しました。 特にDBRXが得意とする長いコンテキストのリク��エストでは顕著です。以前のブログ記事で説明したように 、パフォーマンスの高い推論サービスの構築は難しい問題です。高可用性と低レイテンシを維持するためには、メモリ管理とパフォーマンスチューニングに多くの注意を払う必要があります。私たちは、複数のリクエストを並列に処理するために、集約された連続バッチシステムを利用し、高いGPU使用率を維持し、強力なストリーミング性能を提供しています。
深いマルチGPU最適化:私たちは、NVIDIAのTensorRT-LLMやvLLMなどの最先端のサービングエンジンにインスパイアされたいくつかのカスタム技術を実装しました。これには、不要なGPUメモリの読み取り/書き込みを排除する演算子融合を実装したカスタムカーネルや、慎��重に調整されたテンソル並列性と同期戦略が含まれます。テンソル並列やエキスパート並列など、さまざまな形式の並列化戦略を検討し、それらの比較優位性を明らかにしました。
量子化と品質:量子化(モデルを小さく高速化する技術)は、DBRXのようなサイズのモデルにとって特に重要です。DBRX導入の主な障壁はメモリ要件です。16ビット精度の場合、最低4x80GBのNVIDIA GPUを推奨します。DBRXを8ビット精度で提供できることで、サービングコストは半減し、NVIDIA A10GのようなローエンドGPUで実行できるようになります。ハードウェアの柔軟性は、ハイエンドGPUの利用可能性が乏しい地域での地域限定配信を重視する企業ユーザーにとって特に重要です。しかし、以前のブログポストで述べたように 、量子化を取り入れる際には細心の注意が必要です。我々の厳密な品質評価では、TRT-LLMとvLLMのデフォルトのINT8量子化手法は、特定の生成タスクにおいてモデル品質の劣化につながることがわかりました。この劣化の一部は、モデルが長いシーケンスを生成しないMMLUのようなベンチマークでは明らかではありません。私たちが目にした最大の品質問題は、ドメイン固有(HumanEvalなど)とロングコンテキスト(ZeroSCROLLSなど)のベンチマークによってフラグが立てられました。 Databricksの 推論製品のユーザーは、当社の��エンジニアリングチームがモデルを高速化しながらもモデルの品質を慎重に保証していることを信頼できます。
過去に私たちは、高速で安全な推論を提供するための私たちのエンジニアリングプラクティスについて、多くのブログを公開してきました。 詳しくは、下記リンク先の過去のブログ記事をご覧ください:
- 高速、安全、高信頼性:エンタープライズグレードのLLM推論
- NVIDIA H100 Tensor Core GPU上での量子化LLMの処理
- LLM推論パフォーマンスエンジニアリング:ベストプラクティス
図6:Xの人々はDBRXトークンの生成速度がとても気に入っています(ツイート)。 私たちの Hugging Face Space デモは、Databricks Foundation Model APIをバックエンドとして使用しています。
推論のヒントとコツ
このセクションでは、優れたプロンプトを作成するための戦略をいくつか紹介します。プロンプトの詳細は システムプロンプトにとって特に重要です。
DBRX Instructはシンプルなプロンプトで高いパフォーマンスを提供します。 しかし、他のLLMと同様に、うまく作成されたプロンプトは、パフォーマンスを大幅に向上させ、アウトプットを特定のニーズに合わせることができます。 同じプロンプトを複数回評価すると、異なる出力になる可能性があります。
それぞれのユースケースに最適なものを見つけるために、ぜひ試してみてください。 プロンプトエンジニアリングは反復プロセスです。 出発点は、多くの場合、「バイブチェック」、いくつかの入力例を用いて手動�で応答品質を評価することです。 複雑なアプリケーションの場合は、経験的な評価フレームワークを構築し、異なるプロンプト戦略を繰り返し評価することによって、これに従うことが最善です。
Databricksは、AI PlaygroundやMLflowで、このプロセスを支援する使いやすいUIを提供します。また、推論テーブルやデータ分析ワークフローなど、これらの評価を大規模に実行するためのメカニズムも提供して います。
システムプロンプト
システムプロンプトは、一般的なDBRX Instructモデルをタスク固有のモデルに変換する方法です。 これらのプロンプトは、モデルがどのように応答すべきかの枠組みを確立し、会話に追加のコンテキストを提供することができます。 また、モデルの応答スタイルを調整するために、役割を割り当てるためにもよく使われます("あなたは幼稚園の先生です" )。
DBRX Instructのデフォルトのシステムプロンプトは、モデルを基本的な安全ガードレールを備えた汎用エンタープライズチャットボットに変えます。 この動作は、すべての顧客に適しているわけではありません。システムプロンプトは、AIプレイグラウンドで簡単に変更したり、 チャットAPIリクエストの「システム」ロールを 使用して変更することができます。
カスタムシステムプロンプトが提供された場合、デフォルトのシステムプロンプトを完全に上書きします。 以下は、 DBRX InstructをPII検出器に変更するために数��ショットのプロンプトを使用するシステムプロンプトの例です。
プロンプティングのヒント
DBRX Instructのプロンプトを開始するためのヒントをいくつか紹介します。
最初のステップ。不必要な複雑さを避けるため、できるだけシンプルなプロンプトから始めます。あなたが何を望んでいるかをわかりやすく説明し、タスクの詳細と関連するコンテキストを適切に提供します。これらのモデルはあなたの心を読むことはできません。知的でまだ経験の浅いインターンだと考えてください。
正確な指示を使用してください。 DBRX Instructのような指示に従うモデルは、正確な指示で最高の結果を出す傾向があります。 能動的なコマンド(「分類」、「要約」など)と明示的な制約(たとえば "avoid "の代わりに "do not")。 的確な表現を使う(例:望ましい回答の長さを指定する場合は、「数センテンスで説明してください」ではなく、「3センテンス程度で説明してください」とする)。 例「空が青い理由を簡単な言葉で簡潔に説明しなさい」の代わりに「空が青い理由を50字以内で5歳児に説明しなさい」。
例を挙げて教えてください。場合によって、詳細な一般的な指示を作成するよりも、入力と出力のいくつかの例をモデルに提供するのが最良の方法です。上記のシステムプロンプトのサンプルはこのテクニックを使用しています。例では、モデルを特定の応答形式に基づいて、目的の解決空間に向けて導くことができます。例は多様で、十分な範囲をカバーするものでなければなりません。不正解の回答例とその理由についての情報は非常に役に立ちます。通常、少なくとも3~5つの例が必要です。
段階的な問題解決を促します。複雑なタスクの場合、DBRX Instructが解決策に向かって段階的に進むように促すと、すぐに答えを生成するよりもうまくいくことがよくあります。 解答の正確性を向上させるだけでなく、ステップバイステップの解答は透明性を提供しモデルの推論の失敗を分析しやすくします。 この分野にはいくつかのテクニックがあります。 タスクは、より単純なサブタスクのシーケンスに分解することができます(または、より単純で単純なサブタスクのツリーとして再帰的に)。 これらのサブタスクは1つのプロンプトにまとめることもできますし、プロンプトを連結して、1つのプロンプトに対するモデルの応答を次のプロンプトへの入力として渡すこともできます。 あるいは、答える前に、DBRX Instructに「思考の連鎖」を提供してもらうこともできます。 これは、モデルに「考える時間」を与え、体系的な問題解決を促すことで、より質の高い解答を導くこ��とができます。 思考の連鎖の例「マフィンを15個焼きました。 私はマフィンを2個食べ、5個を近所の人にあげました。 私のパートナーはさらに6個のマフィンを買い、2個食べました。私のマフィンは素数ですか? 一歩ずつ考えてください」
フォーマットは重要です。他のLLMと同様、DBRX Instructにとって、迅速な書式設定は重要です。指示は先頭に記述してください。構造化されたプロンプト(Few-shot、ステップバイステップなど)では、区切り記号(マークダウン形式の ## ヘッダー、XML タグ、三重引用符など)を使用してセクションの境界を示す場合、会話全体を通して一貫した区切り記号のスタイルを使用してください。
プロンプト・エンジニアリングについてもっと知りたいとお考えなら、オンラインで簡単に入手できる多くのリソースがあります。DBRX Instructも例外ではありません。しかし、モデルを超えて機能する多くの一般的なアプローチがあります。 Anthropicのプロンプトライブラリのようなコレクションは、 良いインスピレーションの源となるでしょう。
生成パラメータ
プロンプトだけでなく、 推論要求パラメータはDBRX Instructがどのようにテキストを生成するかに影響します。
同じプロンプトを複数回評価すると、異なる出力になることがあります。 temperatureパラメータを調整することで、ランダム性の程度を制御できます。 回答が明確に定義されているタスク(質問回答やRAGなど)には低い数値を、創造性が役立つタスク(詩の作成、ブレーンストーミング)には高い数値を選択します。これを高く設定しすぎると、無意味な回答になります。
基盤モデルAPIは、enable_safety_mode(プライベートプレビュー)のような高度なパラメータもサポートしています。これはモデルのレスポンスにガードレールを有効にし、安全でないコンテンツを検出してフィルタリングします。近日中に、高度なユースケースをアンロックし、顧客が本番AIアプリケーションをよりコントロールできるようにするため、さらに多くの機能を導入する予定です。
モデルへのクエリ
Databricksのお客様であれば、当社のAI Playgroundからすぐに実験を開始できます。SDKの使用をご希望の場合は、弊社の基盤モデルAPIエンドポイントはOpenAI SDKと互換性があります(Databricksのパーソナルアクセストークンが必要です)。
まとめ
DBRX Instructは、あらゆる企業のためにデータとAIを民主化するという私たちの使命における、もう一つの大きな前進です。 私たちはDBRXモデルの重みをリリースし、2つの主要な推論プラットフォームにパフォーマンス最適化された推論サポートを提供しました:TensorRT-LLMとvLLMです。 私たちは、DBRXの開発中にNVIDIAと緊密に協力し、MoEモデル全体に対するTensorRT-LLMの性能を押し上げました。 vLLMでは、DBRXに対するコミュニティの包括的なサポートと意欲に感謝しています。
DBRX Instructのような基盤モデルは生成AIシステムにおける中心的な柱ですが、Databricksの顧客が派手なデモを越えて高品質の生成AIアプリケーションを開発するために、複合AIシステムを構築する例が増えています。Databricksプラットフォームは、モデルとその他のコンポーネントが協調して動作するように構築されています。 例えば、RAG Studioチェーン(MLflow上に構築)を提供します。Vector Searchを 基盤モデルAPIにシームレスに接続します。推論テーブルは、安全なロギング、可視化、メトリックス、指標追跡を可能にし、DBRXのようなオープンモデルのトレーニングや適応に使用できる独自のデータセットの収集を容易にし、連続的なアプリケーションの改善を促進します。
業界として、私たちは生成AIの旅の始まりにいます。Databricksでは、皆様が私たちと共にどのようなものを構築されるかを楽しみにしています! まだDatabricksをご利用でない方は、無料トライアルにご登録ください!
Databricksの投稿を見逃さないようにしましょう
次は何ですか?


データサイエンス・ML
October 30, 2024/1分未満