正確性、安全性、ガバナンス:生成AIをPOCからプロダクションに移行する方法

生成AIの企業導入に関して、ほとんどの組織は過渡期にあります。私たちが話をした顧客の88%は、現在、生成AIのパイロットプロジェクトを実行していると述べていますが、大多数は、テスト環境から本番環境に実験を移行することに神経質になりすぎているとも述べています。
では、何がこの格差を引き起こしているのでしょうか? それがコストとリスクに関する懸念です。 以前は、IT投資を行う場合、企業は「構築すれば価値は後からやってくる」という考え方をすることができましたが、もう違います。現在は、新しいプロジェクトは、ビジネスにとって価値あるものを迅速に生み出すことが求められています。 かつては、役員や投資家はIT投資に対するリターンが得られるまで数年待っても構わなかったかもしれませんが、今ではわずか6ヶ月での進展を求めています。
企業は、生成AI開発コストのROIを懸念しているだけでなく、AIシステムが悪い結果や不正確な結果(ハルシネーションなど)を吐き出し、ビジネスに損害を与えたり、企業の機密情報が漏洩する可能性があることも懸念しています。 また、法務部門も技術プロジェクトを以前より詳しく見るようになりました。 彼らは、システムが説明可能で信頼できる結果を生み出しているという保証を求めています。 一方、運用チームは、誰が、または何が独自の情報にアクセスできるかを管理し、データがコンプライアンスに準拠した方法で使用されていることを確認したいと考えています。
Robert Johnsonには申し訳ありませんが、もしあなたが岐路に立っているのであれば、生成AIによるイノベーションを見逃さないでください。 テスト環境が提供できる情報は限られており、AIシステムが実世界に導入されるまで、企業はその真価を理解し、恩恵を受けることはできません。 しかし、そこまで到達するには、しばしば組織の見直しが必要です。
生成AIプロジェクトを実験から本番に移行させるには(そして企業全体に拡大させるには)、企業はこれらのアプリケーションを強化する複合AIシステムが正確かつ安全で、管理されていることを確認しなければなりません。
正確性
コンピューターサイエン��スの古い定説があります:「ガベージ・イン、ガベージ・アウト」。つまり、優れたAIには優れたデータが必要なのです。 AIモデルが正確で文脈に関連した結果を出すためには、インプットとして質の高い関連データが必要です。
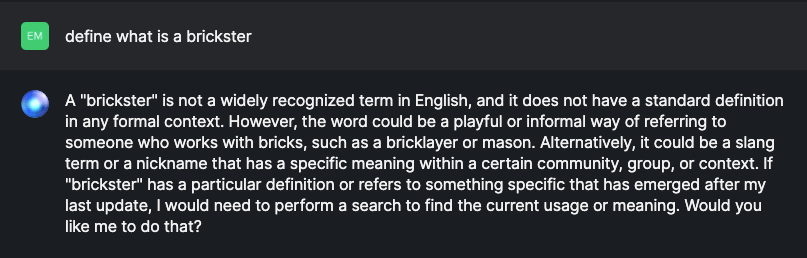
既成の商用モデルでは、企業独自の運用に関する必要な知識が不足していることがあり、十分なビジネスインパクトをもたらす知見を得ることができません。 これらのモデルは、会社の専門用語を誤って解釈したり、ビジネスの文脈にそぐわない情報を返すことがあります。 例えば、Databricksの社員は社内で「Bricksters」と呼ばれていますが、これは公開モデルへのクエリには表示されない定義です。
この問題に対処する最も一般的な方法の1つは、RAG(Retrieval Augmented Generation)を使用することです。 RAGは、このような大規模なモデルにさらなるコンテキストを提供する方法を企業に提供します。 完全なカスタムモデルではないものの、RAGを適用することで、既存の商用モデルのユース�ケースの可能性が大きく広がります。 これは、これらのシステムから価値を引き出したい企業にとって重要な要素です。

ファインチューニングは、企業がこれらのモデルをさらにカスタマイズする機会を提供します。 例えば、 Stardogは、Databricks Mosaic AIを使用して、会話のクエリに対してより良い応答を提供するモデルを微調整しました。高度なデータサイエンスチームと高品質なデータを持つ企業にとって、AIモデルの事前トレーニングは特注の結果をもたらします。Replitは 、カスタムコード生成モデルをわずか3週間でゼロから構築することができ 、製品立ち上げのタイムラインに間に合わせることができました。
企業が自社のデータを使ってモデルの強化や構築を考える前に、データを収集し、整理する必要があります。 企業は過去数十年にわたり構築してきたデータのサイロ化を打破するのに苦労しています。 多くの企業はまだクラウドに移行している最中です。 現在の環境は、オンプレミスとAWS、Google Cloud、Azureが混在しています。 そして、何百、何千という他のシステムがあり、その多くは独自のデータベースをもっています。
その上、企業はテキスト、ビデオ、PDF、音声ファイルなどの膨大な非構造化データを活用し、AIアプリケーションの改善に役立てたいと考えています。その結果、多くの企業が AIの未来の基盤としてDatabricksデータインテリジェンスプラットフォームを利用して います。 レイクハウスの基盤上に構築されたプラットフォームは、データ(コンテンツとメタデータ)の分析と、その使用方法 (クエリ、レポート、リネージなど)の監視を支援し、自然言語アクセスやガバナンスの強化、高度なAIワークロードのサポートなどの新機能を追加します。 つまり、Databricksは、データの取り込みからガバナンス、正確で信頼性の高い知見をビジネスにもたらす生成AIモデルの構築と展開まで、完全なツール一式を顧客に提供する唯一のプラットフォームです。
安全
AIモデルに大量のデータを与えて最善の結果を期待するだけでは十分ではありません。多くのことがうまくいかない可能性があります。 そのチャットボットが顧客に誤った情報を提供した場合、エア・カナダに対する最近の訴訟に見られるように、企業はその出力を尊重する法的義務を負う可能性があります。
別の例として、小売業者は自動化された商品説明を作成するために��、既製のモデルに依存するかもしれません。 しかし、プロバイダーがそのモデルに変更を加えると、下流に影響を及ぼし、製品ページ全体が使えなくなる可能性があります。
そのため、自社のデータが商用モデルやオープンソースモデルでどのように使用されているかを監視できるとともに、独自のモデルを微調整したりカスタマイズしたりできる、基盤となるAI開発プラットフォームを選択することが重要です。最終的には、企業はさまざまなモデルをミックスして使用することになるでしょう。 Databricks AI Playgroundは、顧客が商用、カスタム、そして汎用のDBRXのようなオープンソースLLM と対話することを可能に します 。
プロジェクトが実験から本番へと移行するにつれ、企業はこれらすべての異なるシステムを継続的に監視できる必要もあります。当社のお客様は、Databricksデータインテリジェンスプラットフォームを使用してデータを取り込み、クリーニングし、処理し、そのデータを使用して最先端のLLMを稼働させ、結果を監視することができます。実際、レイクハウスモニタリングは、上流のデータパイプラインやモデル、アプリケーションをスキャンし、AIシステムの健全性を1つの包括的なウィンドウで完全に把握することができます。
ガバナンス
データが企業全体でより自由に流通し始めると、ガバナンスは譲れないものになります。 実際、私たちがCEOと話をする際には必ずと言っていいほど、データへのアクセスを効果的に管理し、その利用状況を把握する方法が最重要課題として挙げられます。
ガバナンスがなければ、同僚が会社のシステムを照会して同僚の給与を知ることができるかもしれません。従業員の一般的な質問に対応するために設計されたシステムが、一般に公開される前に会社の業績に関する機密情報を表に出し始めるかもしれません。データリネージへの詳細なアクセスがなければ、この 情�報は、顧客データの使用に関する現地の法律に違反する可能性のあるモデルを動かす可能性が あります。

幸いなことに、DatabricksのUnity Catalogを用いることで、データとAIの取り込みを加速し、同時に規制上のコンプライアンスを確保することができます。 組織は、構造化・非構造化データ、機械学習モデル、ノートブック、ダッシュボード、ファイルを、主要なクラウドやプラットフォーム上でシームレスに管理・共有することができます。
適切なガバナンス技術に加え、企業は組織��の戦略目標がAIの進歩と同期していることを確認する必要があります。 AIが法的・倫理的基準を遵守するよう、新たなポリシーやプロセスを導入する必要があるかもしれません。 AI最高責任者またはAI戦略委員会を選ぶことは、このガイダンスの助けとなります。
飛び立つ前に見てください!
企業が生成AI技術の導入に懸念を持つのは理解できます。 誰も(特に弁護士は)、AIモデルが顧客に誤った情報を提供することを望んでいません。 しかし、生成AIシステムの付加価値は明らかです。企業はイノベーションを迅速に市場に投入し、製品提供のパーソナライゼーションを向上させ、労働力のパフォーマンスを高めることができます。 成功の鍵は、正確で、安全で、管理された生成AIシステムで作業することです。
Databricksで次のステップを踏み出しましょう:
AWS、Microsoft Azure、Google Cloudのいずれかを選択し、当社のプラットフォームを2週間お試しください。
既にDatabricksをご利用のお客様:詳細は以下をご覧ください

