リキッドクラスタリングの一般提供開始のお知らせ
データに合わせて拡張できる、すぐに使用できる自己調整型データレイアウト

Databricks データインテリジェンスプラットフォームで Delta Lake リキッドクラスタリングが一般提供されることをお知らせします。リキッドクラスタリングは、テーブル パーティショニングと ZORDER に代わる革新的なデータ管理手法であり、データ レイアウトを微調整することなく、最適なクエリ パフォーマンスを実現できます。
リキッドクラスタリングは、データ レイアウト関連の決定を大幅に簡素化し、データを書き換えずにクラスタリング キーを再定義する柔軟性を提供します。これにより、時間の経過とともに分析ニーズに合わせてデータ レイアウトを進化させることができます。これは、 Delta のパーティション分割では決して実現できないことです。
昨年の Data and AI Summit でリキッドクラスタリングのパブリック プレビューが公開されて以来、リキッドクラスタリングによるクエリ パフォーマンスの向上の恩恵を受けた何百人ものお客様と協力してきました。その間、1000人以上のアクティブな顧客がおり、リキッドクラスタリングが適用されたテーブルに 100ペタバイト以上の書き込み、20 エクサバイト近い読み取りが行われました。お客様は、リキッドクラスタリングによって従来の方法に比べて読み取りパフォーマンスが 2 ~ 12 倍向上したことを実感しています。
従来のアプローチ:管理が困難で、柔軟性が低く、すべてに適用可能な戦略がない
従来、お客様は、読み取りクエリを高速化し、並列の書き込みを有効にするために、Hive スタイルのパーティショニングとZORDERの組み合わせを採用していました。これにはいくつかの問題があります。
課題1:最適なパフォーマンスを得るための適切なパーティション分割戦略を見つけることが難しい
パーティション分割列の選択は複雑なプロセスです。 また、パーティション列の選択が適切でない場合、ファイル サイズが大きすぎたり小さすぎたりするため、読み取り速度が遅くなり、クエリのパフォーマンスが低下します。 これに対処するために、多くの顧客は、生成された列を使用して高カーディナリティ列でパーティション分割するなど、さらに複雑な回避策に頼っています。
課題2:ZORDER ジョブはコストがかかり、書�き込み時間が長くなる
ZORDER では、パーティション分割のみの場合よりも読み取りが高速になりますが、増分ではなく、書き込み時に実行できないため、書き込みの増幅が大幅に発生します。 その結果、クラスタリングジョブの実行時間が長くなり、コンピュートコストも高くなります。 さらに悪いことに、ZORDER はデータセット全体にわたってデータをグローバルに最適化しないため、最適なクエリ パフォーマンスが得られません。
課題3:パーティション分割戦略は、テーブルへの同時書き込みの必要性によって制限される
競合を防ぐために、パーティションは、必ずしもパーティション分割を必要としない列を中心に構成されます。 これにより、継続的なメンテナンスが行われ、ビジネスの変化に伴うクエリ パターンの進化に合わせてデータの書き換えでパーティションが調整されます。 さらに、同じパーティション内での同時書き込みは不可能です。
リキッドクラスタリングのご紹介 – クエリパフォーマンスを最大 12 倍向上させる、すぐに使える自己チューニング機能
リキッドクラスタリングは、適切なデータ レイアウトを見つけ出してこれらすべての課題を解決する画期的な手法であり、手動で調整さ�れたパーティション テーブルへの書き込みと読み取りのパフォーマンスが向上します。Liquid はDelta Lakeで利用でき、DBR 15.2 から Databricks でも一般利用できるようになりました。Databricks 内では、 Databricks データインテリジェンスプラットフォームの一部として、DatabricksIQ が AI を使用してリキッドクラスタリングを強化し、同時実行性とパフォーマンスをさらに向上させます。
リキッドクラスタリングの使い方は簡単です。クラスター化する列を次のように定義するだけです。
利点1:Liquid リキッドクラスタリングはシンプル - 最小限のデータレイアウト決定で最適なクラスタリング パフォーマンスを実現
Hiveパーティショニングとは異なり、リキッドクラスタリングのパーティショニング キーは、カーディナリティ、キーの順序、ファイル サイズ、潜在的なデータ スキュー、およびアクセス パターンが将来どのように変化するかを考慮する必要はなく、クエリ アクセス パターンのみに基づいて選択できます。上記の例では、高カーディナリティ列のタイムスタンプをパーティショニング キーとして使用しています。リキッドクラスタリングは自己調整機能があり、スキュー耐性があり、一貫したファイル サイズを生成し、パーティショニングの過剰と不足を回避します。
Databricks の革新的なリキッドクラスタリングを使用することで、従来の ZORDER 方式と比較してクエリ パフォーマンスが大幅に向上しました。さらに、リキッドクラスタリングが適用されたテーブルにより、パーティション分割のボトルネックが解消され、スキャンが改善され、データの偏りが軽減され、データ処理が効率化されました。 -- YipitData ETLエンジニアリング ディレクター、Edward Goo 氏
利点2:リキッドクラスター化されたテーブルへの書き込みが高速 - 最適化されたデータ レイアウトによりコストが削減される
リキッドクラスタリング��は、書き込み増幅率が低いコスト効率の高い増分クラスタリングを提供します。業界標準のデータウェアハウジング パラメータからデータを段階的に取り込み、クラスター化した社内ベンチマークでは、 リキッドクラスタリングはパーティショニング + Zorder よりも 7 倍高速な書き込み時間を実現することがわかりました。
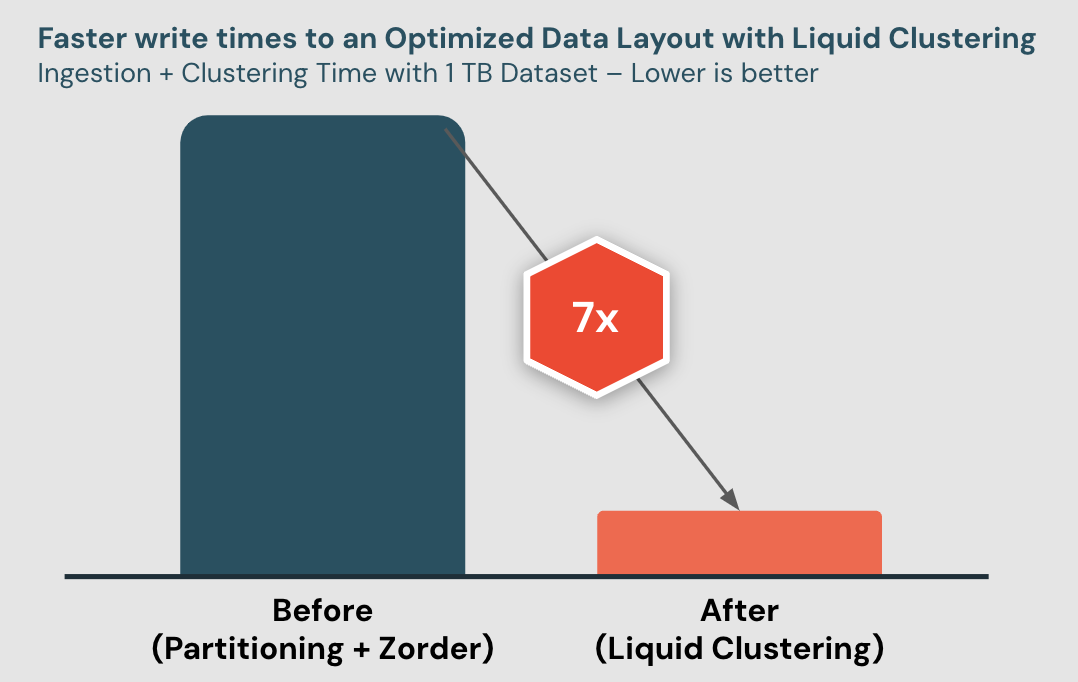
さらに、 DatabricksIQを使用すると、取り込み中の新しいデータに対して書き込み時にリキッドクラスタリング (クラスタリングオンライト) を適用できます。クラスタリングオンライトは、追加の構成なしで自動的に起動します。パーティショニングと同様に、Liquid リキッドクラスタリングは書き込み時にデータがすぐに適切にクラスター化されることを保証し、顧客がすぐに使用できるパフォーマンスの高いデータ レイアウトを作成します。
メリット3:同時実行の保証 – DatabricksIQ がリキッドクラスタリングによるレコードレベルの同時実行サポートを提供
Databricks は、行レベルの同時実行性を提供する唯一のレイクハウスです。 顧客は、同時実行性のためにパーティション分割に依存したり、リキッドクラスター化テーブルでの競合を回避するようにワークロードを設計したりする必要がなくなりました。
これらすべての利点により、顧客はパフォーマンスを絞り出すためだけにデータ レイアウトを微調整する必要がなくなりました。大手製造企業では、リキッドクラスタリングによってポイント クエリが 12 倍高速化され、時系列データ内の ID を検索するユースケースが加速しました。
Delta Lake リキッドクラスタリングにより、時系列クエリが最大 10 倍改善され、レイクハウスへの実装が驚くほど簡単になりました。これにより、カーディナリティやファイル サイズを気にせずに列をクラスター化できるようになり、読み取る必要のあるデータの量が大幅に削減されます。これは、 DeltaパーティショニングとZ-Orderファインチューニングを使用して常に自分で管理しなければならなかったことです。 -- Shell 社 チーフデジタルテクノロジーアドバイザー Bryce Bartmann 氏
さらに、多くの顧客が、この機能のシンプルさ、柔軟性、すぐに使えるパフォーマンスを高く評価しています。
リキッドクラスタリングにより、研究者が複雑なデータセットから特定の傾向やイベントを調査する能力が大幅に向上しました。この機能が成長し、 Deltaエコシステムの主要機能として採用されるのを楽しみにしています。 -- Cisco、ビッグデータ担当リーダー、Robert Batts 氏
無料トライアル
Delta テーブルでリキッドクラスタリングを数�秒で有効にできます。リキッドクラスタリングは DBR 15.2 で GA 化されました。 (ドキュメント: AWS | Azure | GCP )。 Databricks以外でリキッドクラスタリングを使用する場合は、 delta.ioのドキュメントを参照してください。

