Databricks SQLにおいてマテリアライズドビューとストリーミングテーブルが正式リリース!
Databricks SQLにシンプル・高速・効率的なデータ取り込みと変換が登場!AWSとAzureで正式リリース!
によって ポール・ラッパス, Michael Armbrust, Md Enzam Hossain, Meixian Li, Michael Lu, Eun-Gyu Kim 、 Ritwik Yadav による投稿
- MV はクエリ結果を事前に計算・保存することで、SQL 分析や BI ダッシュボードのパフォーマンスを向上させ、クエリの遅延を大幅に削減します。
- ST と MV を組み合わせることで、完全な増分データパイプラインが実現し、リアルタイムユースケースに最適です。
- MV と ST の新機能であるモニタリング、エラー対応、コスト追跡の強化についてもご紹介します。
Databricks SQL において、マテリアライズドビュー(MV)とストリーミングテーブル(STs)が AWS と Azure で正式リリースされました!ストリーミングテーブルは、クラウドストレージやメッセージバスといったソースから、SQL 数行でシンプルかつ増分でデータ取り込みが可能です。マテリアライズドビューは、クエリ結果を事前に計算し、増分で更新することで、ダッシュボードやクエリの実行速度を大幅に向上させます。この2つを組み合わせることで、データ取り込みから変換まで、SQL だけで効率的かつスケーラブルなデータパイプラインを作成できます。
このブログでは、これらのツールがアナリストやアナリティクスエンジニアにどのように力を与え、DBSQL ウェアハウス内でデータおよび分析アプリケーションをより効果的に提供できるようにするかについて詳しく説明します。また、MV と ST の新機能であるモニタリング、エラー対応、コスト追跡の強化についてもご紹介します。
データウェアハウスユーザーが直面する課題
データウェアハウスは、ビジネスインテリジェンス (BI) アプリケーションを通じた分析と社内レポートの主な場所です。SQL アナリストは、大規模なデータセットを効率的に取り込み、変換し、リアルタイム分析のための高速クエリパフォーマンスを確保し、迅速なデータアクセスとコスト管理のバランスを取らなければなりませ�ん。これらの目標を達成するために、いくつかの課題に直面しています:
- エンドユーザーのクエリやダッシュボードの遅延: 大規模な BI ダッシュボードは、複雑なデータセットのビューを処理するため、クエリが遅くなり、インタラクティブ性が低下し、データの再処理が繰り返されることでコストが増大します。
- データの鮮度向上とコストの維持: 結果を事前計算することでクエリの遅延を削減できますが、データの鮮度が低下しコストが高くなる傾向があり、適切なコストで鮮度を保つには複雑な増分処理が必要です。
- セルフサービス: 従来の SQL パイプラインは複雑な手動コーディングに依存しており、ビジネスニーズへの対応が遅れる原因となります。
マテリアライズドビューとストリーミングテーブルで高速かつ新鮮なデータを提供
マテリアライズドビュー(MV)とストリーミングテーブル(ST)は、ビューの使いやすさと事前計算データの高速性を自動エンドツーエンドの増分処理によって実現し、複雑なコードを書くことなく高速なクエリを提供し、ビジネスのニーズに応じて最新のデータを確保できます。
MVによる高速クエリとダッシュボード
MV はクエリ結果を事前に計算・保存することで、SQL 分析や BI ダッシュボードのパフォーマンスを向上させ、クエリの遅延を大幅に削減します。ベーステーブルに対して繰り返しクエリを実行する代わりに、MV により事前集計や事前結合されたデータをダッシュボードやエンドユーザーのクエリで即座に取得できるため、処理速度が格段に向上します。また、MV の�クエリはビューに比べてコスト効率が高く、MV に保存されたデータだけにアクセスすることで、ベーステーブルの再処理のオーバーヘッドを回避できます。
低コストでリアルタイムユースケースを実現
ST と MV を組み合わせることで、完全な増分データパイプラインが実現し、リアルタイムユースケースに最適です。ST はストリーミングデータを継続的に取り込み、処理するため、BI ダッシュボードや機械学習モデル、運用システムが常に最新情報を利用できます。一方、MV は新しいデータが到着すると自動で増分更新されるため、手動操作なしでデータの鮮度を維持しつつ、ビュー全体の再構築を回避して処理コストを削減します。ST と MV の組み合わせは、リアルタイム分析とレポートのコストパフォーマンスを最適化します。
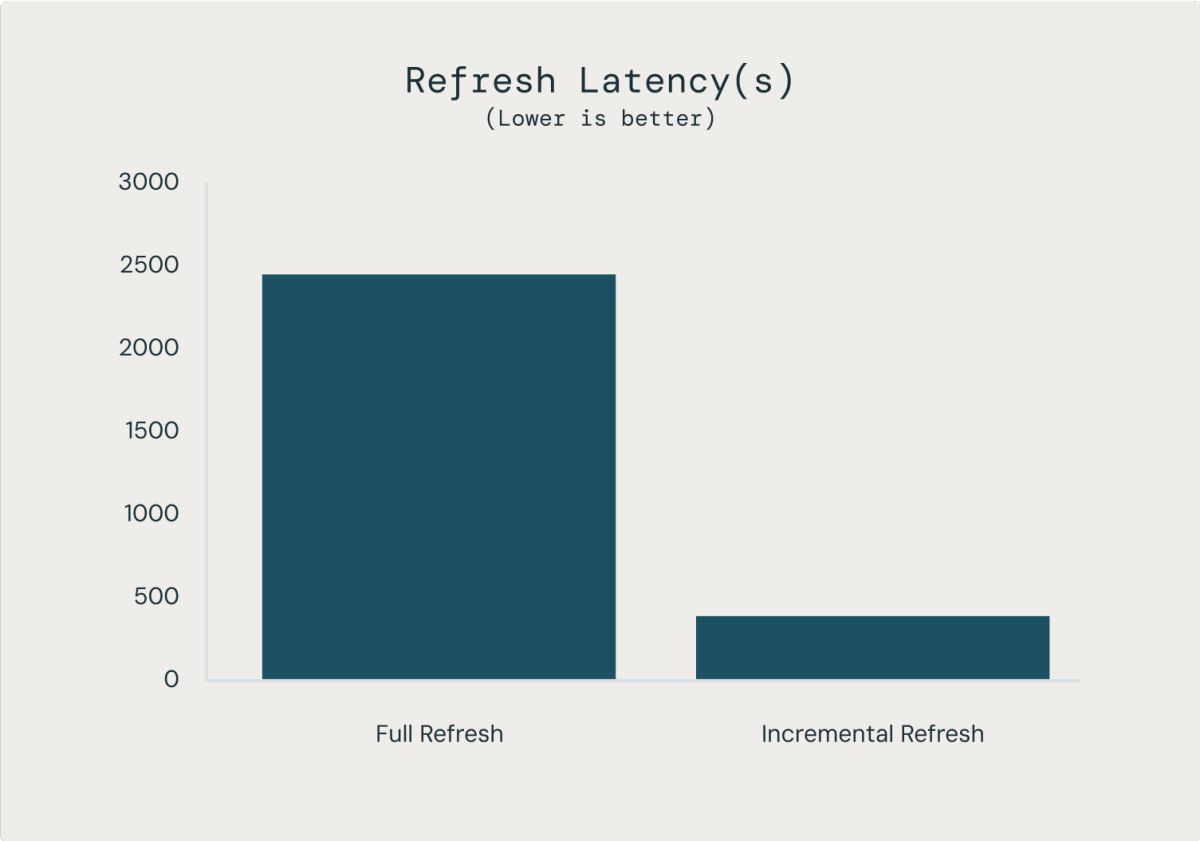
増分リフレッシュ対応の MV は、時間とコストを大幅に節約することも可能です。2000 億行のテーブルでの社内ベンチマーク(internal benchmarks)では、MV のリフレッシュはテーブル全体のリフレッシュに比べ、コストが 98% 削減され、処理時間が 85% 短縮されました。データの鮮度が約 7 倍向上し、同等の CREATE TABLE AS ステートメントと比較してコストは 1/50 程度に抑えられました。
{kind=link}
アナリストが DBSQL でデータパイプラインを構築できる環境を提供
MV と ST を活用したデータパイプラインの構築により、テーブル管理や DML コードに関する手作業が大幅に自動化され、アナリティクスエンジニアはビジネスロジックに集中できるようになります。シンプルな SQL 構文で組織への価値提供を加速します。また、ST はクラウドストレージやメッセージバスなどからのデータ取り込みを簡素化し、複雑な設定を排除してさらに効率化を図ります。
「取引テーブル上でマテリアライズドビューを効果的に活用することで、分析レイヤーのクエリパフォーマンスが劇的に向上し、500 万行のファクトテーブルにおいてクエリ時間が最大 85% 短縮されました。これにより、ビジネスチームは分析ダッシュボードをより効率的に活用し、データから得たインサイトに基づいて迅速に意思決定を行えるようになりました。」
「Databricks のマテリアライズドビューを活用することで、大量のデータ処理にかかる時間を大幅に短縮しました。この改善によりランタイムが 85% 削減され、チームはより効率的に作業できるようになり、機械学習やビジネスインテリジェンスのインサイトに集中できるようになりました。プロセスの簡素化により、より大規模なデータボリュームをサポートし、全体的なコスト削減とプロジェクトの機動性向上に寄与しています。」—Sam Adams, Paylocity シニア機械学習エンジニア
「マテリアライズドビューへの変換により、クエリパフォーマンスが劇的に向上しました… さらに、コスト削減の効果も非常に助かっています。」—Karthik Venkatesan, Adobe セキュリティソフトウェアエンジニアリング シニアマネージャー
「数テラバイトのデータを持ついくつかのテーブルで、クエリパフォーマンスが 98% 向上しました。」—Gal Doron, AnyClip データ部門責任者
「トランザクションテーブル上でマテリアライズドビューを活用することで、分析レイヤーのクエリパフォーマンスが劇的に向上し、5億行のファクトテーブルで実行時間が最大85%短縮されました。」—Nikita Raje, DigiCert データエンジニアリング ディレクター
例: Databricks でボリュームからデータを取��り込み、変換する
ST(ストリーミングテーブル)と MV(マテリアライズドビュー)の一般的なユースケースとして、クラウドストレージバケットに到着するデータを継続的に取り込み、変換する方法があります。以下の例では、外部の設定やオーケストレーションを必要とせず、すべてを SQL で実行する方法を示します。まず、データをレイクハウスに取り込むストリーミングテーブルを作成し、次に取り込まれた行数をカウントするマテリアライズドビューを作成します。
- ボリュームから5分ごとにデータを取り込む ST を作成します。ストリーミングテーブルは新しいデータの正確な1回だけの配信を保証します。また、ST はデータ処理のためにサーバーレスのバックグラウンドコンピュートを利用するため、データボリュームの急増にも自動でスケーリングして対応します。
- 毎時データを変換するための MV(マテリアライズドビュー)を作成します。この MV は、定義されたクエリの結果を常に反映し、可能な場合には増分リフレッシュが行われます。
新機能
プレビュー版のリリース以降、MV と ST のためのカタログエクスプローラーを強化し、リアルタイムのステータスやリフレッシュスケジュールにアクセスできるようにしました。さらに、MV は CREATE OR REPLACE 機能に対応し、その場での更新が可能になりました。MV では、より幅広いクエリに対して増分リフレッシュ機能が拡張され、新たに内部結合、左結合、UNION ALL、およびウィンドウ関数のサポートも追加されました。これらの新機能について詳しく見ていきましょう。
オブザーバビリティ
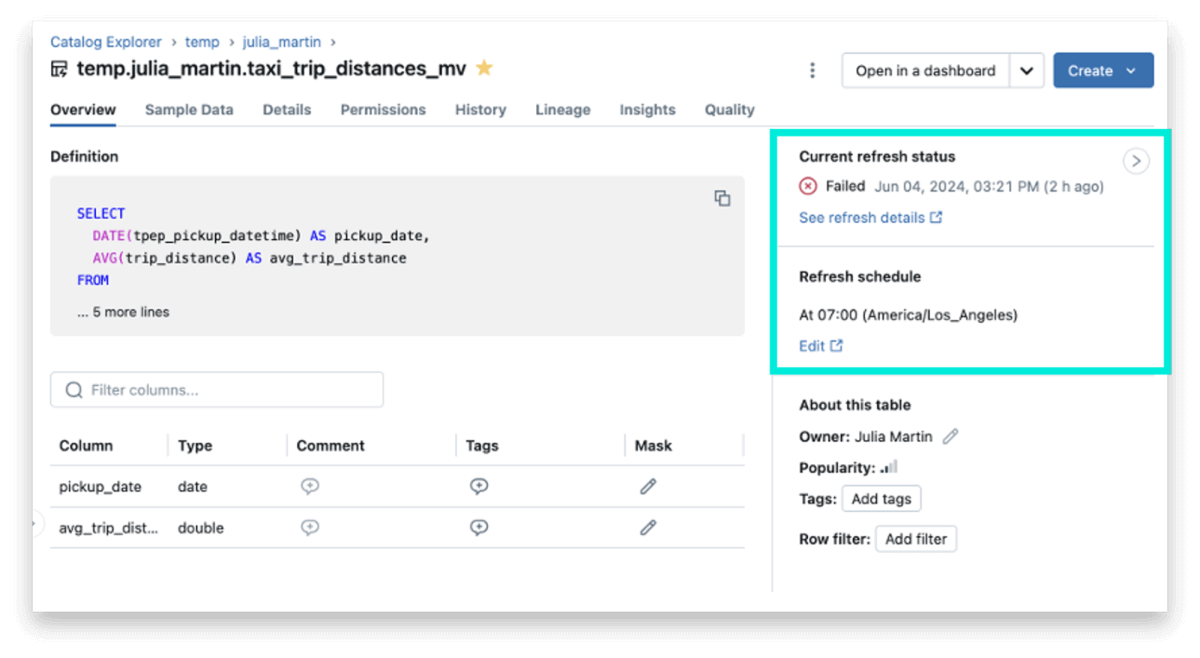
カタログエクスプローラーが強化され、MV および ST のステータスやスケジュールに関するコンテキストに応じたリアルタイム情報が表示されるようになりました。
- 現在のリフレッシュ状況: MV または ST が最後にリフレッシュされた正確な時間を表示します。これにより、データの鮮度が確認できます。
- リフレッシュスケジュール: マテリアライズドビューが時間ベースのスケジュール(time-based schedule)で自動リフレッシュされるように設定されている場合、カタログエクスプローラーに読みやすい形式でスケジュールが表示されます。これにより、エンドユーザーが MV のデータ鮮度を簡単に確認できます。
スケジューリングと管理がさらに簡単に
MV および ST のリフレッシュを DDL でスケジューリングするための EVERY 構文を導入しました。EVERY により、CRON 構文を使わずに時間ベースのスケジュールを簡単に設定できます。CRON の柔軟な表現力が必要なユーザー向けには、引き続き CRON スケジューリングもサポートします。
Example:
さらに、マテリアライズドビューで CREATE OR REPLACE をサポートし、ドロップや再作成の必要なく、定義をその場で簡単に更新できるようにしました。これにより、既存の権限や ACL が保持されます。
左結合、内部結合、ウィンドウ関数の増分リフレッシュをサポート
{kind=link}
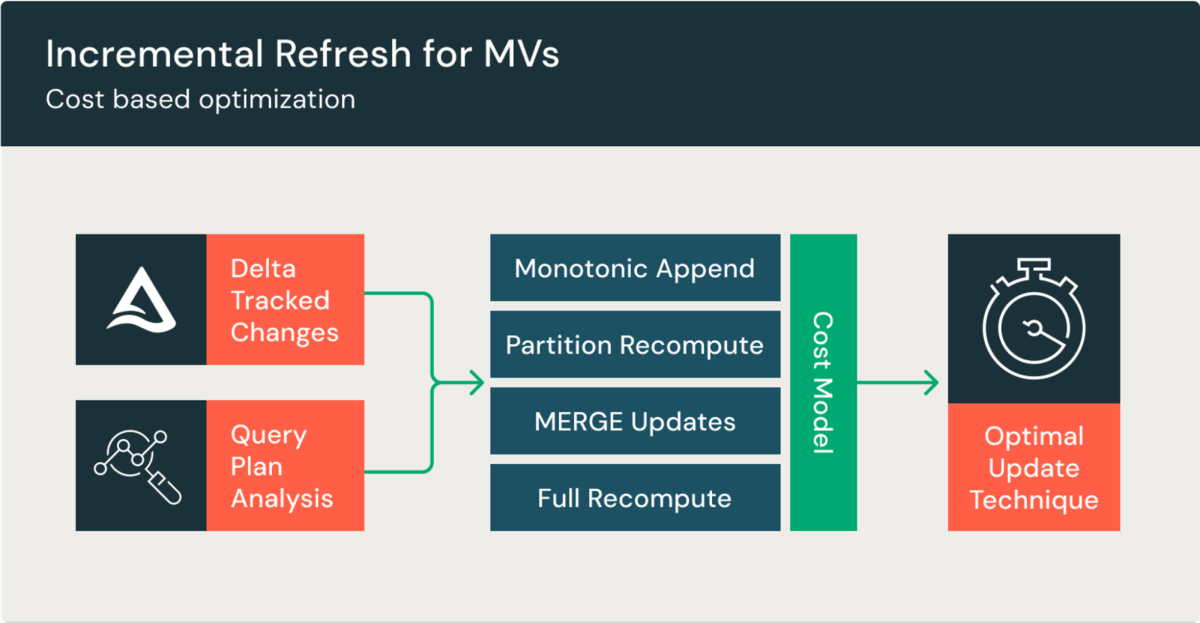
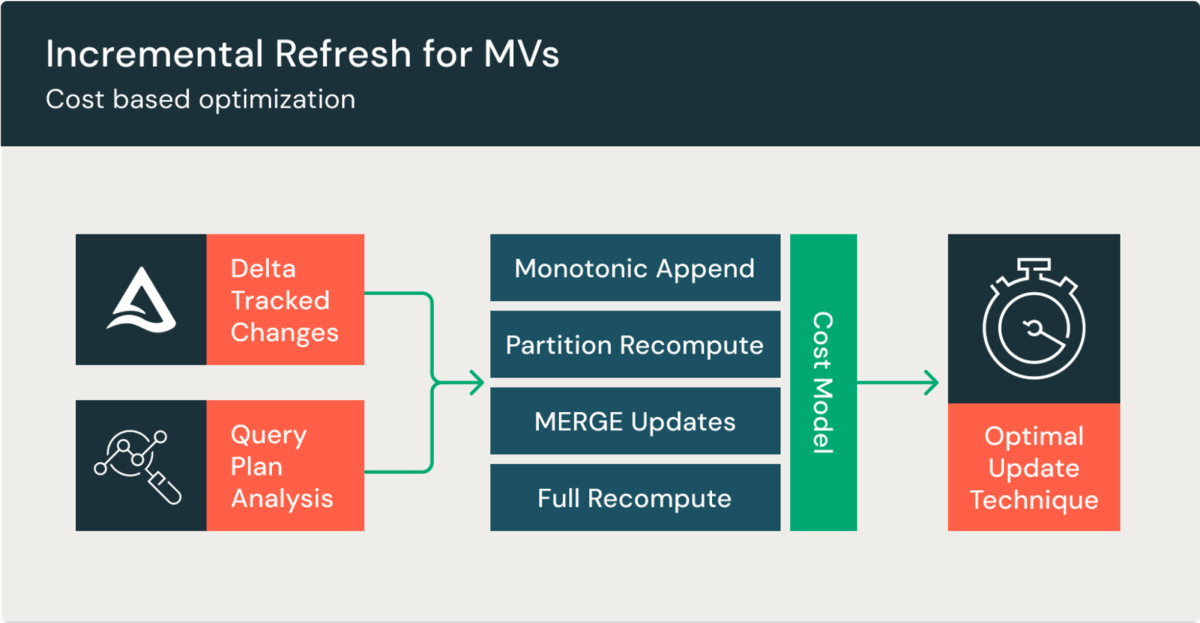
大規模な MV の再計算はコストが高く、時間がかかりますが、MV は増分計算により更新することで、コストを抑え、リフレッシュを高速化します。これにより、コストの一部でデータの鮮度が向上し、エンドユーザーは事前計算されたデータに対してクエリを実行できます。MV は、DBSQL Pro、サーバーレスウェアハウス、または Delta Live Tables (DLT) パイプラインで増分リフレッシュが行われます。
クエリが増分リフレッシュをサポートする場合、MV は自動的に増分リフレッシュされます。クエリにサポートされていない表現が含まれる場合は、全体リフレッシュが実行されます。増分リフレッシュは、前回の更新以降の変更のみを処理し、そのデータをテーブルに追加または更新します。
MV は、内部結合、左結合、UNION ALL、およびウィンドウ関数 (OVER) の増分リフレッシュをサポートします。結合で任意の数のテーブルを指定でき、結合に含まれるすべてのテーブルの更新がクエリ結果に反映されます。サポートされるクエリタイプは随時追加されているため、最新の機能についてはドキュメントをご参照ください。
コストの割り当て
請求対象の使用量システムテーブルで、リフレッシュのアイデンティティ情報を確認できるようになりました。この情報を取得するには、usage_metadata.dlt_pipeline_id がマテリアライズドビューまたはストリーミングテーブルに関連するパイプラインの ID に設定されているレコードに対して、使用量システムテーブルへクエリを実行します。パイプライン ID は、カタログエクスプローラーでマテリアライズドビューまたはストリーミングテーブルを表示する際に「詳細」タブで確認できます。詳しくはドキュメントをご覧ください。
以下のクエリはその例です:
MV と STs の今後の予定
MV と ST は、DBSQL のデータウェアハウス機能を強化する強力なツールで、すでに 1,400 以上の顧客が増分取り込みとリフレッシュに利用しています。今後、さらに MV と ST の機能を改善する予定で、以下のような新機能のプレビューをお届けします:
- 上流データの変更に基づくリフレッシュ: 上流のデータ変更に基づいて自動リフレッシュを設定でき、更新後のリフレッシュ速度を制御してコストを管理することも可能になります。
- 所有者の変更とサービスプリンシパルとしての実行
- カタログエクスプローラーで MV と ST のコメントを直接編集する機能
- UIでの MV/ST 統合��モニタリング: Databricks の UI で全ての MV と ST を確認でき、ワークスペース全体の健全性や運用情報を簡単に監視可能。
- コストモニタリング: 請求システムのテーブルに MV や ST の名前が表示され、DBU 使用量やデータの特定、リフレッシュ履歴の確認が容易になります。
- Delta Sharing: 現在プライベートプレビュー中(Available now in private preview)
- Google Cloud サポート: 近日対応予定
ぜひ今日から MV と ST を使い始めましょう!
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。