ノートブック、ワークフロー、Delta Live Tables 用のサーバーレス コンピューティングの一般提供開始のお知らせ
ノートブック、ジョブ、パイプラインの実行に最適な迅速かつ手間のかからないコンピューティングが、Azure および AWS で一般提供開始

Translation Reviewed by Hiroyuki Nakazato
ノートブック、ジョブ、Delta Live Tables(DLT)のサーバーレスコンピューティ�ングが AWS および Azure で一般提供開始となりましたので、お知らせいたします。お客様は Databricks SQL および Databricks モデル サービング用の高速でシンプル、かつ信頼性の高いサーバーレス コンピューティングをすでに利用しています。 同じ機能が、Apache Spark や Delta Live Tables を含む、データ インテリジェンス プラットフォーム上のすべての ETL ワークロードで利用できるようになりました。 ユーザーがコードを書き、Databricksが迅速なワークロードの開始、自動インフラストラクチャスケーリング、そしてDatabricks Runtimeのシームレスなバージョンアップグレードを提供します。 重要な点として、サーバーレス コンピューティングでは、クラウド プロバイダーからインスタンスを取得し初期化する時間ではなく、実際に行った作業に対してのみ課金されます。
現在のサーバーレスコンピューティング提供は、迅速なスタートアップ、スケーリング、パフォーマンスに最適化されています。ユーザーは近い将来、低コストなどの他の目標も設定できるようになります。 私たちは、サーバーレス コンピューティングの導入プロモーション割引を 2024 年 10 月 31 日まで提供しています。 ワークフローおよび DLT のサーバーレス コンピューティングでは 50% の値引き、ノートブック で は 30% の値引きが受けられます。
クラスターのスタートアップは私たちにとって最優先事項であり、サーバーレス ノートブックとワークフローは大きな違いを生み出しました。 ノートブックのサーバーレス コンピューティングは、ワンクリックで簡単に使用できます。サーバーレス コンピューティングはワークフローにシームレスに統合されています。 さらに、安全性も確保されています。 この待望の機能は、ゲーム チェンジャーです。 Databricks に感謝します!」— Chiranjeevi Katta 氏、Airbus社のデータエンジニア
サーバーレス コンピューティングによって解決できる課題と、データ チームに提供する独自のメリットについて詳しく見ていきましょう。
コンピューティング インフラの管理は複雑で高コスト
Spark クラスターなどのコンピューティングの設定と管理は、長い間データ エンジニアやデータ サイエンティストにとって大きな課題でした。コンピューティングの設定と管理に費やす時間は、ビジネスに価値を提供するための時間ではありません。
適切なインスタンス タイプとサイズを選択するのは時間がかかり、最適な選択肢を見つけるためには試行錯誤が必要です。クラスターのポリシー、自動スケーリング、Spark の設定を把握することはさらにこの作業を複雑にし、専門知識が求められます。クラスタ�ーのセットアップと運用が完了した後も、そのパフォーマンスを維持し調整し、Databricks Runtime のバージョンを更新して新機能を活用するための時間を費やさなければなりません。
アイドル タイム(ワークロードを処理していない時間)も、コンピューティング インフラを自前で管理することで発生する高コストの要因です。コンピューティングの初期化やスケールアップの際には、インスタンスの起動、Databricks Runtime を含むソフトウェアのインストールなどが必要です。この時間に対してクラウド プロバイダーに料金を支払います。第二に、インスタンス数やメモリ、CPUなどのリソースを過剰にプロビジョニングすると、計算能力が過剰になり、それでもプロビジョニングしたすべての計算能力に対して支払いが発生します。
これらのコストと複雑性を数百万の顧客のワークロードを通じて観察し、私たちはサーバーレス コンピューティングの革新に至りました。
サーバーレス コンピューティングは高速でシンプル、高い信頼性を持つ
従来のコンピューティングでは、複雑なクラウド ポリシーやロールを通じて Databricks に委任権限を与え、ワークロードに必要なインスタンスのライフサイクルを管理していました。サーバーレス コンピューティングでは、この複雑さが排除され、Databricks がユーザーに代わって広範で安全なコンピューティングを管理します。設定なしでただ Databricks を使い始めるだけで済みます。
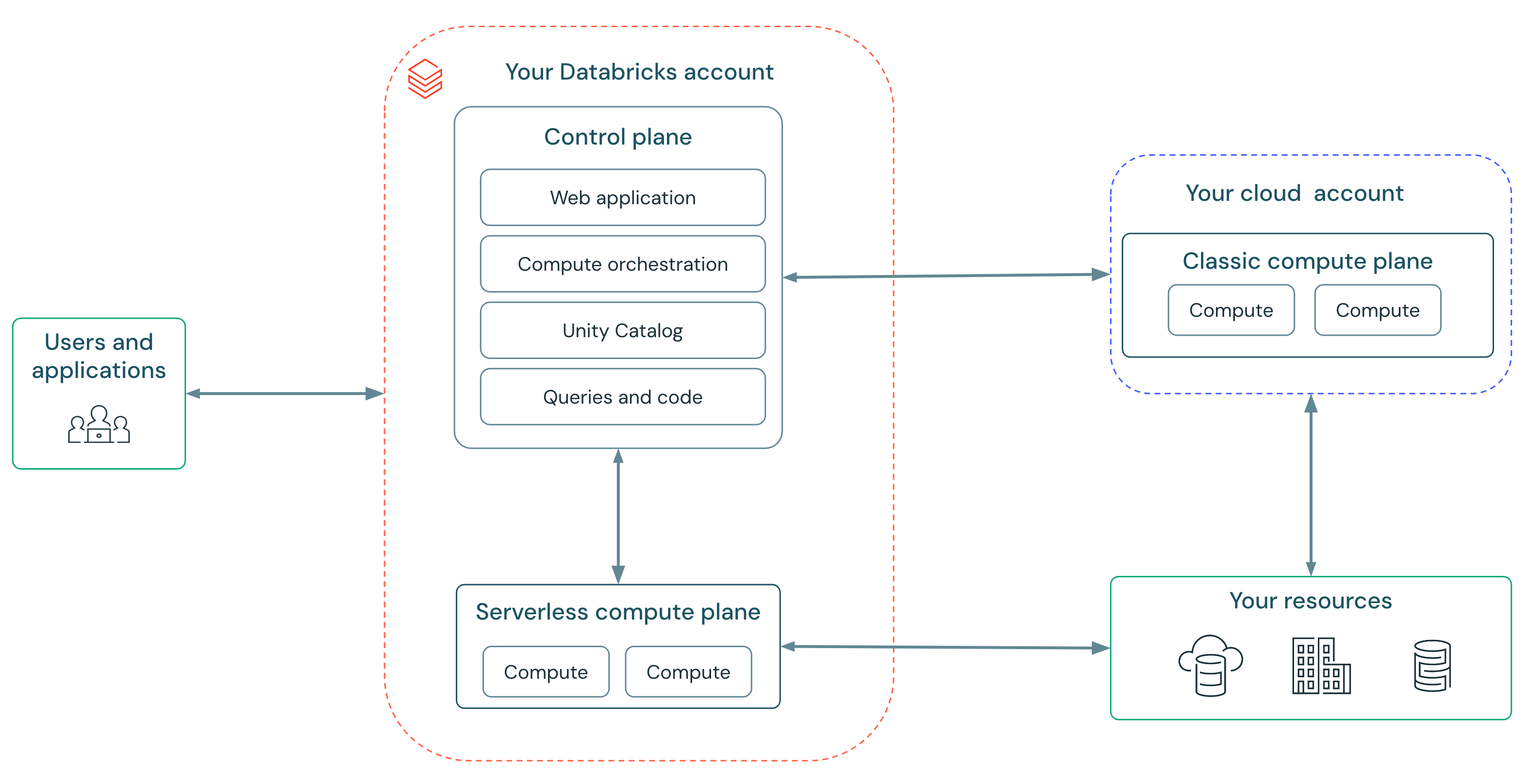
サー�バーレス コンピューティングにより、高速、シンプル、信頼性の高いサービスを提供できます。
- 高速: クラスターを待つ必要はもうありません。コンピューティングは数分ではなく数秒で起動します。 Databricks はインスタンスの「ウォーム プール」を運用しており、いつでもコンピューティングの準備が整っています。
- シンプル: インスタンスタイプの選択、クラスタスケーリングパラメータの設定、Spark 設定の調整は不要です。サーバーレスには、新しい自動スケーラーが含まれており、従来のコンピューティングの自動スケーラーよりもスマートでワークロードのニーズに迅速に対応します。これにより、インフラ専門家の手助けなしにすべてのユーザーがワークロードを実行できるようになります。Databricks はワークロードを自動的に更新し、最新の Spark バージョンに安全にアップグレードします。これにより、常に最新のパフォーマンスとセキュリティの恩恵を受けることができます。
- 信頼性: Databricksのサーバーレス コンピューティングは、自動インスタンス タイプ フェイル オーバーと可用性不足を緩和する「ウォーム プール」を備え、クラウドの障害から顧客を保護します。
「ワーカーの種類を選択する必要がなく、ワークフローを開発から本番に移動するのは非常に簡単です。 スタートアップ時間の大幅な改善と、DataOps の設定とメンテナンスの削減により、生産性と効率が大幅に向上します。」 — Gal Doron 氏、AnyClip 社のデータ責任者
サーバーレス コンピューティングの料金
サーバーレスコンピューティングの弾力的な請求モデルを導入することを嬉しく思います。コンピューティングがワークロードに割り当てられた時間にのみ課金され、インスタンスの取得や設定にかかる時間には課金されません。
インテリジェントなサーバーレス自動スケーラーは、ワークスペースが常に適切な容量を確保できるようにします。たとえば、ユーザーがノートブックでコマンドを実行する際に需要に応じて対応します。この自動スケーラーは、ニーズに応じてワークスペースの容量を段階的にスケールアップおよびスケールダウンします。リソースが賢明に管理されるよう、インテリジェント自動スケーラーが不要と予測した場合には、数分後にプロビジョニングされた容量を削減します。
DLT のサーバーレス コンピューティングはセットアップも実行も非常に簡単で、マテリアライズド ビューのパフォーマンスが大幅に向上していることがすでに確認されています。 これまでは、生データからシルバーレイヤーへの移行に約 16 分かかっていましたが、サーバーレスに切り替えた後は、わずか 7 分程度で済みます。 時間とコストの節約は計り知れないものになるでしょう」— Aaron Jespen 氏、Jetlinx 社の IT オペレーション ディレクタ��ー
サーバーレス コンピューティングは管理が簡単
サーバーレス コンピューティングには、管理者がコストや予算を管理するためのツールが含まれています。シンプルさが予算超過や驚くような請求を意味してはいけません。
サーバーレス コンピューティングの使用状況やコストに関するデータはシステムテーブルで利用可能です。費用の概要を把握し、特定のワークロードに詳細に掘り下げるための、事前に構築されたダッシュボードを提供しています。
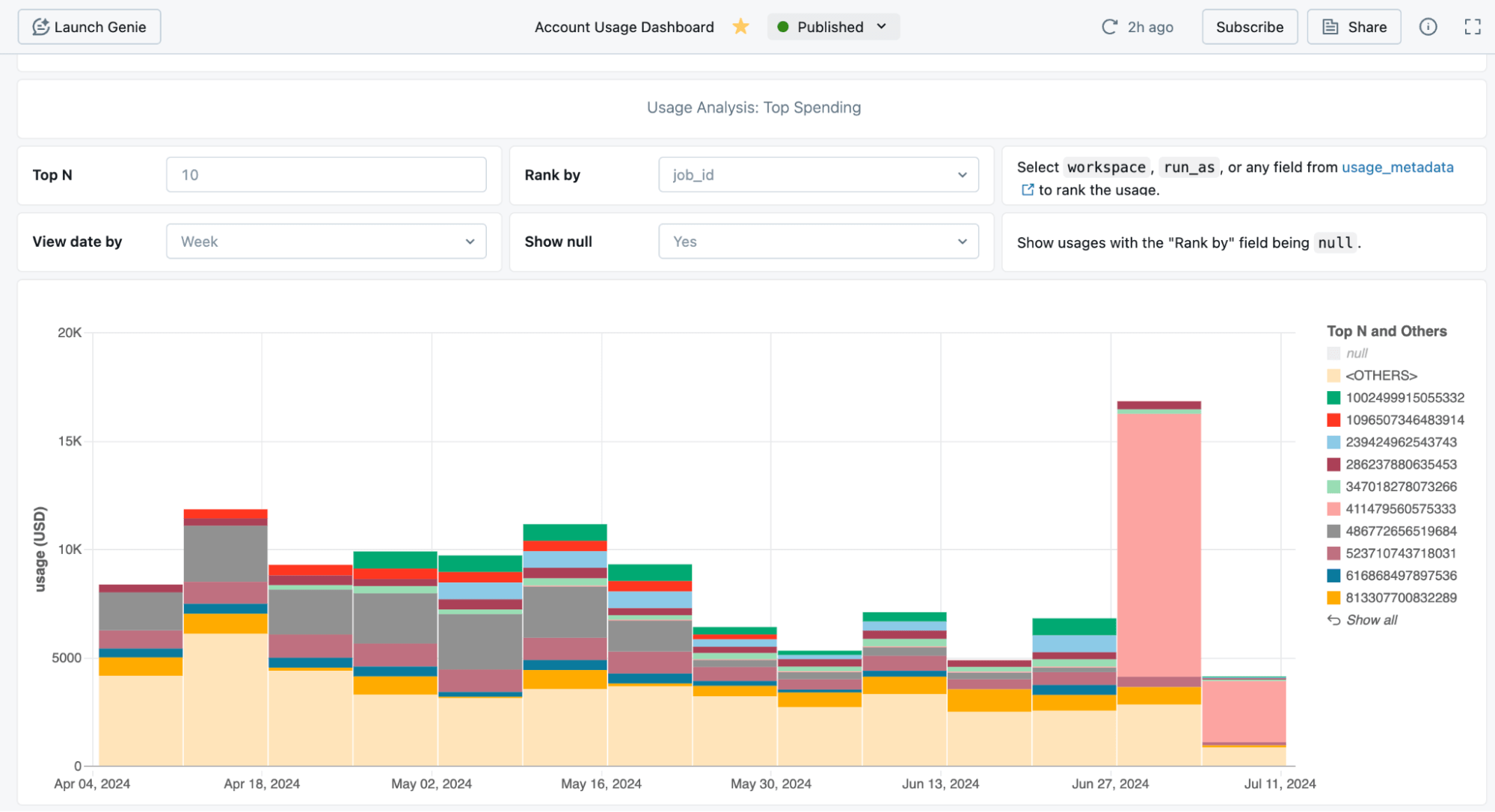
管理者は予算アラート(プレビュー)を使用してコストをグループ化し、アラートを設定できます。 予算を管理するためのフレンドリーな UI があります。
サーバーレス コンピューティングは最新の Spark ワークロード向けに設計されている
内部的には、サーバーレス コンピューティングは Lakeguard によるサンドボックス技術でユーザー コードを分離しますが、これはサーバーレス環境では絶対に必要です。 その結果、一部のワークロードでは、サーバーレスで動作を継続する�ためにコードの変更が必要になります。 サーバーレス コンピューティングでは、データ資産への安全なアクセスのために Unity Catalog が必要なので、Unity Catalog を使用せずにデータにアクセスするワークロードでは変更が必要になる場合があります。
ワークロードがサーバーレス コンピューティングに対応しているかどうかをテストする最も簡単な方法は、まず DBR 14.3 以降で共有アクセス モードを使用してクラシック クラスターで実行することです。
サーバーレス コンピューティングはすぐに利用可能です
私たちは、今後数か月でサーバーレス コンピューティングをさらに改善するために全力を尽くします。
- GCP サポート: GCP 上のサーバーレス コンピューティングのプライベート プレビューを開始しています。パブリック プレビューと GA の発表をお待ちください。
- プライベート ネットワーキングおよびエグレス制御: プライベート ネットワーク内のリソースに接続し、サーバーレス コンピューティング リソースがパブリック インターネット上でアクセスできるものを制御します。
- 強制可能な属性付け: すべてのノートブック、ワークフロー、および DLT パイプラインが適切にタグ付けされ�ていることを確認し、特定のコスト センター(例えばチャージバック用)にコストを割り当てることができるようにします。
- 環境設定: 管理者は、プライベート リポジトリ、特定の Python およびライブラリ バージョン、環境変数にアクセスして、ワークスペースの基本環境を設定できます。
- コストとパフォーマンス: サーバーレス コンピューティングは現在、高速起動、スケーリング、およびパフォーマンスのために最適化されています。 ユーザーは近い将来、低コストなどの他の目標も設定できるようになります。
- Scala サポート: ユーザーはサーバーレス コンピューティングで Scala ワークロードを実行できるようになります。スムーズにサーバーレスに移行できるように、現在の Scala ワークロードを共有アクセスモードのクラシック コンピューティングに移行して準備してください。
今すぐサーバーレス コンピューティングを使い始めるには:
- AWS または Azure のアカウントでサーバーレス コンピュートを有効にします。
- ワークスペースで Unity Catalog の使用が有効になっており、 AWS または Azure でサポートされているリージョンにあることを確認してください。
- 既存の PySpark ワークロードについては、共有アクセス モードおよび DBR 14.3 以降と互換性があることを確認します。
- ノートブック、ワークフロー、 Delta Live Tables の特定の手順に従ってください。
- Databricks Connect を使用すると、任意のサードパーティ システムからサーバーレス コンピュートを使用できます。 たとえば、IDE からローカルに開発する場合や、アプリケーションを Python でネイティブに統合する場合などです。

