Mosaic AI Vector Searchのハイブリッド検索の一般提供を開始
Mosaic AI Vector Searchにおけるハイブリッド検索の一般提供開始を発表することを嬉しく思います。ハイブリッド検索は、事前に訓練された埋め込みモデルの強みとキーワード検索の柔軟性を組み合わせた強力な機能です。このブログ投稿では、ハイブリッド検索がなぜ重要で、どのように機能し、どのようにして検索結果を改善するためにそれを使用できるかを説明します。
ハイブリッド検索の理由は何ですか?
事前学習済みの埋め込みモデルは、非構造化データを表現する強力な方法であり、意味を圧縮し、簡単に検索可能な形式で捉えます。しかし、それは外部データを使用して訓練されており、あなたのデータについての明確な知識はありません。ハイブリッド検索は、ベクトル検索インデックスの上に学習したキーワード検索インデックスを追加します。キーワード検索インデックスはあなたのデータで訓練されており、そのため、あなたの検索状況に重要な名前、製品キー、その他の識別子について��の知識を持っています。
ハイブリッド検索を選ぶタイミング
ハイブリッド検索は、公開されている埋め込みモデルのトレーニングデータセットに存在しない、あなたのデータセットにおける重要なキーワードがある場合に、より良いパフォーマンスを発揮することができます。例えば、特定の製品コードや正確に一致させたい他の用語に質問が参照している場合、ハイブリッド検索がより良い選択となるかもしれません。どちらのオプションがあなたの問題セットに最適かを見るために、両方を試すことをお勧めします。
Mosaic AI Vector Searchでのハイブリッド検索の使用
ハイブリッド検索を始めるのは簡単です。すべてのインデックスは、追加の設定なしでハイブリッド検索にアクセスできるようになりました。
キーワードインデックスは、コーパス内のすべてのテキストフィールドで訓練されているため、テキストチャンクとすべてのテキストメタデータフィールドの両方に自動的にアクセスできます。
完全に管理されたDelta同期インデックスでは、類似性検索クエリに`query_type='hybrid'`を追加するだけで済みます。これは、モデルサービングエンドポイントが接続された直接ベクトルアクセスインデックスでも機能します。
自己管理のDelta Syncインデックスとモデルサービングエンドポイントが接続されていないDirect Vector Accessインデックスでは、`query_vector`と`query_text`の両方が指定されていることを確認する必要があります。
品質の改善
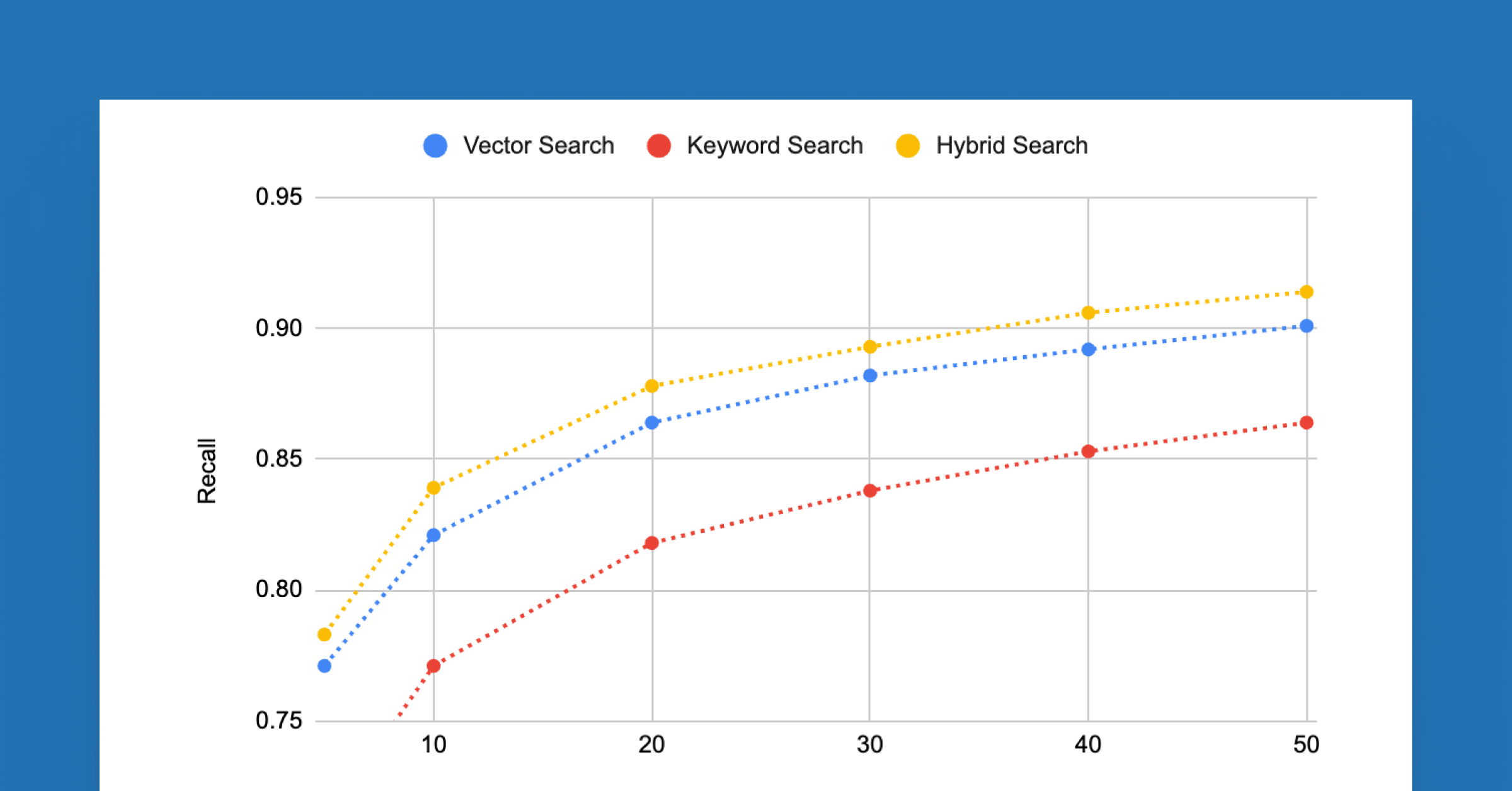
Retrieval-Augmented Generator (RAG)アプリケーションでは、一つの重要な指標はリコール、つまり、入力クエリの答えを含むチャンクを上位`num_results`の取得チャンクの中で何回取得するかの割合です。ハイブリッド検索がリコールを改善し、したがって、ユーザーの質問に答えるためにLLMが処理する必要のあるチャンクの数を減らすことができることがわかります。
ガートナー®: Databricks、クラウドデータベースのリーダー

お客様から見えるデータセットの種類を表現するように設計された内部データセットでは、リコールの大幅な改善が見られます。特に、リコールが0.9に達するために必要なドキュメントの数は、純粋な密検索では50、ハイブリッド検索では40で、これは20%の改善です。これにより、RAGアプリケーションのレイテンシと処理コストが削減されます。
以下に、取得した結果の数のさまざまな値でのリコールをプロットしています。ハイブリッド�検索が、取得結果の数の選択に関して、純粋な密な検索と同じかそれ以上の性能を発揮することがわかります。

使用された方法
私たちのハイブリッド検索の実装は、ランク逆数融合(RRF)に基づいています。ベクトル検索とキーワード検索の結果のRRFです。RRFのパラメータは、ほとんどのデータセットに対して高品質な結果を返すはずの値に調整されています。
スコアは正規化されているため、可能な最高スコアは1.0です。これにより、ベクトル検索者とキーワード検索者の両方が高い価値を持つと考えられるドキュメントを簡単に特定することができます。スコアが1.0に近いということは、両方の検索者がドキュメントを高い関連性を持つと判断したことを意味します。スコアが0.5近くまたはそれ以下の場合、一方または両方のリトリーバーがドキュメントの関連性が低いと考えています。
次のステップ
今日からハイブリッド検索を始めましょう!完全に管理されたデルタ同期(DSYNC)インデックスとモデルサービングエンドポイントが接続された直接ベクトルアクセスインデックスについて:
モデルサービングエンドポイントがない自己管理のDSYNCインデックスと直接ベクトルアクセス��インデックスの場合:
キーワードインデックスは自動的にインデックス内のすべてのテキストフィールドを使用するため、インデックスを構築する際にこれらを提供する必要があります。
詳細については、ハイブリッド検索に関する当社のドキュメンテーションをご覧ください: