大規模言語モデル(LLM)を用いた商品レビューの自動分析
規模に応じた顧客フィードバックの追跡

公開日: August 29, 2023
によって アリ・セゼル、ショーン・オーウェン、Sam Steiny、ブライアン・スミス(Bryan Smith) による投稿
Check out our LLM Solution Accelerators for Retail for more details and to download the notebooks.
翻訳:Junichi Maruyama. - Original Blog Link
会話AIはここ数カ月で多くのメディアの注目を集めたが��、大規模言語モデル(LLM)の能力は会話のやり取りをはるかに超えている。クエリ応答、要約、分類、検索など、あまり目立たない機能にこそ、多くの組織が労働力を強化し、顧客体験をレベルアップするための直接的な機会を見出している。
これらのアプリケーションの可能性は驚異的である。ある試算によると、LLM(およびその他の生成AIテクノロジー)は、近い将来、現在従業員の時間の60~70%を占めているタスクに対処できるようになるという。拡張機能によって、背景調査、データ分析、文書作成など、ナレッジ・ワーカーが行うさまざまな作業を完了する時間を半分に短縮できることが、多くの研究で示されている。また、他の研究では、これらのテクノロジーを使用することで、新入社員が完全な生産性を達成するまでの時間を劇的に短縮できることが示されている。
しかし、こうした利点を完全に実現する前に、組織はまず、こうしたモデルが依存する非構造化情報資産の管理を見直し、そのアウトプットに影響��する偏りや正確さの問題を軽減する方法を見つけなければならない。このため、現在、多くの組織が、限定されたスコープで、より良い情報アクセスの機会を提供し、人間の監視が誤った結果に対するチェックの役割を果たすことができる、焦点を絞った内部アプリケーションに力を注いでいる。LLMとそれをサポートするテクノロジーが進化し成熟し続ける間、これらのアプリケーションは、組織内に既に存在する中核的な能力と連携し、実質的かつ直接的な価値を提供する可能性を秘めている。
製品レビューの要約にはブーストが必要だ
LLM採用への、より焦点を絞ったアプローチの可能性を説明するために、多くのオンライン小売組織で行われている、かなり単純で一般的なタスクについて考えてみよう。今日、ほとんどの組織では、そこそこの規模の従業員チームを雇い、ユーザーからのフィードバックを読み込んで、製品の性能向上に役立つような洞察を得たり、顧客満足に関連する問題を特定したりしている。
この仕事は重要だが、セクシーではない。作業員はレビューを読み、メモを取り、次のレビューに移る。回答が必要な個々のレビューにはフラグが立てられ、複数のレビューからのフィードバックの要約が、製品またはカテゴリーマネージャーがレビューするためにまとめられる。
このような作業は、自動化に適している。サイトに寄せられるレビューの量は多いため、この作業のより詳細な部分は、多くの場合、製品の重要性に応じた可変ウィンドウで、限られた製品のサブセットに対して実行されます。より洗練された組織では、問題のあるコンテンツを特定し、レビュアーの注意を喚起するために、コースや不適切な表現を検出するルールや、ユーザーのセンチメントを推定するモデル、または肯定的、否定的、中立的な経験についてレビューを分類するモデルが適用されるかもしれない。しかし、いずれにせよ、問題解決に十分な人員を投入し続けることができず、単調な作業に飽き飽きする傾向があるため、多くのことが見逃されている。
大規模言語モデルによる製品レビュー分析の自動化
しかし、LLMを使えば、規模と一貫性の問題に簡単に対処できる。必要なのは、製品レビューをモデルに持ち込んで尋ねることだけだ:
- これらのレビューで見つかった否定的なフィードバックの上位3点は何ですか?
- 顧客はこの製品のどのような点が一番気に入っているのか?
- 顧客は、要求された金額に対して製品から十分な価値を受け取っていると感じているか?
- 特に否定的なレビューや不適切な表現が使われているレビューはありますか?
数秒以内に整然とした回答を得ることができるので、プロダクトマネージャーは単に問題を検出するのではなく、問題への対応に集中することができる。
しかし、正確さと偏りの問題についてはどうだろうか?LLMの出力における不正確さとバイアスを特定するための基準は、出力が組織の期待に沿ったものであることをより確実にするためのテクニックと同様に進化しています。承認されたコンテンツを使用してモデルを微調整することは、少なくとも組織が好むコミュニケーション方法に沿ったコンテンツを生成する優先順位をモデルが持っていることを確実にするために、長い道のりを歩むことができます。
これは、今のところこの問題に対する理想的な解決策はない、ということを長々と述べたものだ。しかし、人間主導のプロセスや、より単純化されたモデルやルールベースのアプローチと比較した場合、その結果は、現在経験しているものよりも良くなるか、少なくとも悪くならないことが期待される。また、これらのレビュー・サマリーは内部消費用であるため、誤ったモデルの影響は容易に管理できる。
今日からできる解決策
この作業がどのように実行されるかを正確に示すために、我々は商品レビューを要約するsolution acceleratorを構築した。これは、Sean Owenが以前発表したブログに基づいており、Databricksプラットフォーム上でLLMをチューニングする際の中核的な技術的課題のいくつかを取り上げている。このアクセラレータでは、Amazon Product Reviews Datasetを使用しています。Amazon Product Reviews Datasetには、200万冊の異なる書籍にわたる5,100万件のユーザー生成レビューが含まれています。
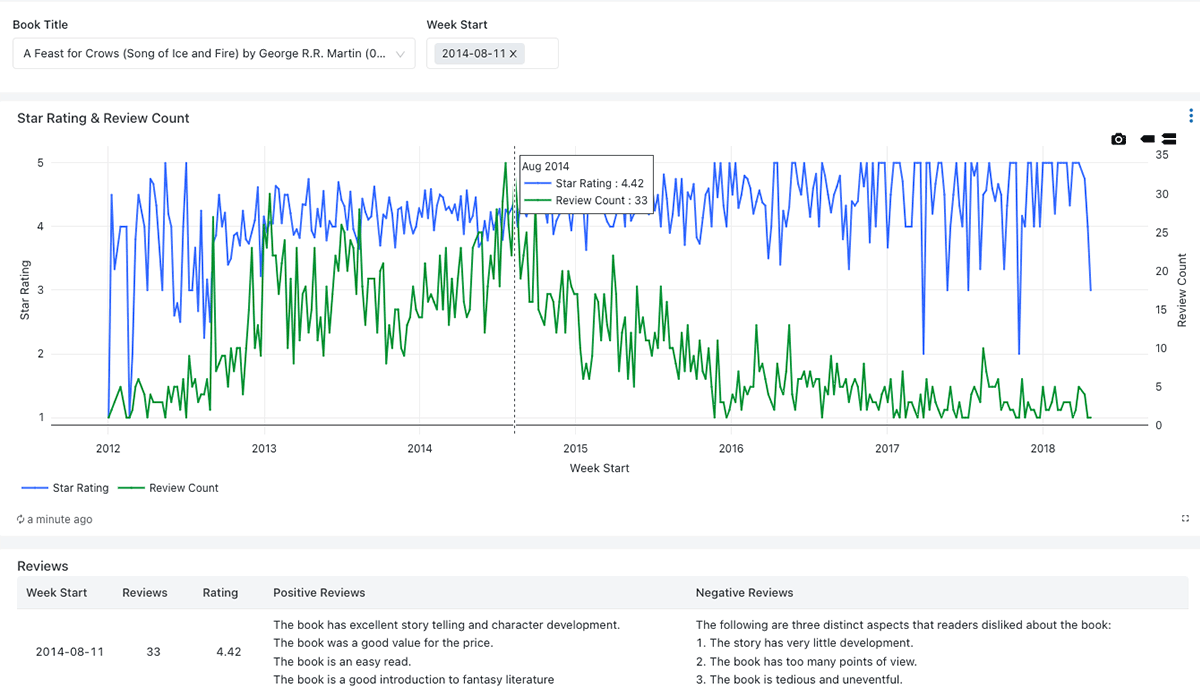
プロダクト・マネージャーのチームが、オンライン・レビューを通じて顧客からのフィードバックを受け取るというシナリオを想像してみよう。これらのレビューは、特定の商品��に関して対処すべき問題を特定し、サイトが将来提供する書籍の方向性を決定するために重要である。テクノロジーを使わなければ、このチームはすべてのフィードバックを読み、実行可能なメモにまとめるのに苦労する。その結果、最も重要な項目だけに注意を向け、散発的にしかフィードバックを処理できない。
しかし、Databricksを使用することで、より幅広い製品からフィードバックを収集し、それらを定期的に要約するパイプラインを構築することができる。好意的な評価を受けた製品は、その書籍の長所を強調する可能性が高く、低評価の製品は短所に焦点を当てる可能性が高いことを認識し、ユーザーから提供された評価に基づいてこれらのレビューを分離し、LLMにレビューの各高レベルカテゴリーから異なる情報セットを抽出させる。
プロダクトマネージャーが受け取ったフィードバックの概要を把握できるように、サマリーメトリクスが提供され、LLMによって生成されたより詳細なサマリーによって裏付けられている(Figure 1)
Databricksはソリューションのすべてのコンポーネントを統合する
上で示したシナリオは、LLMの使用に依存している。数ヶ月前までは、このようなLLMを使用するには特殊な計算インフラへのアクセスが必要でしたが、オープンソースコミュニティの進歩とDatabricksプラットフォームへの投資により、現在ではローカルのDatabricks環境でLLMを実行できるようになりました。
この特別なシナリオでは、データの機密性はこの選択の動機にはなりませんでした。その代わりに、処理するレビューの量がDatabricksを使用するコストに傾き、サードパーティのサービスを使用して同様のソリューションを実装するコストの約3分の1を削減できることがわかりました。
さらに、独自のインフラを導入することで、外部サービスによる制約を気にすることなく、1回のテストで1時間あたり76万件ものレビューに取り組むことができ、より高速な処理のために環境をスケールアップできることがわかりました。ほとんどの組織では、このレベルまでスケールアップする必要はないでしょうが、万が一の場合に備えて環境を用意しておくのは良いことです。
しかし、このソリューションは単なるLLMではない。ソリューション全体を統合するために、私たちはデータ処理ワークフローを開発する必要がありました。統合データプラットフォームであるDatabricksは、データを複製することなく、データエンジニアリングとデータサイエンスの両方の要件に対応する手段を提供してくれます。また、レビューの処理が完了した後は、アナリストが好きなツールを使って出力を照会し、ビジネス上の意思決定を行うことができます。Databricksを通じて、私たちはビジネスのニーズに沿ったソリューションを構築するためのあらゆる機能を利用することができます。

