Databricks 上の大規模言語モデルで放射線科のワークフローを自動化

放射線学は、X 線、コンピュート断層撮影 (CT)、磁気共鳴画像 (MRI)、核医学、陽電子放出断層撮影 (PET)、超音波などの医療用画像診断手順を通じて病気を診断し治療する重要な要素です。 典型的な放射線科ワークフローには、特にプロトコル作成プロセスを中心に手作業のステップが含まれます。 大規模言語モデル (LLM) を使用すると、このような管理上の負担の一部を自動化できます。
現在の状況: 放射線科ワークフロー
さらに詳しく調べるために、典型的な放射線科のワークフローについて詳しく見てみましょう。 最初に、患者は最近の脳震盪の影響が長引くと報告し、医療機関を受診することがあります。 医療提供者は、患者のメモを電子��カルテ(EHR)にまとめ、CTスキャンなどの画像検査を依頼します。 その後、放射線科医が臨床記録を確認し、「造影剤付き脳のCT」などの適切なプロトコルラベルを注文に割り当てます。 このラベルは、画像技術者が注文を実行する際の指針となり、検査とその後の結果の確認につながります。
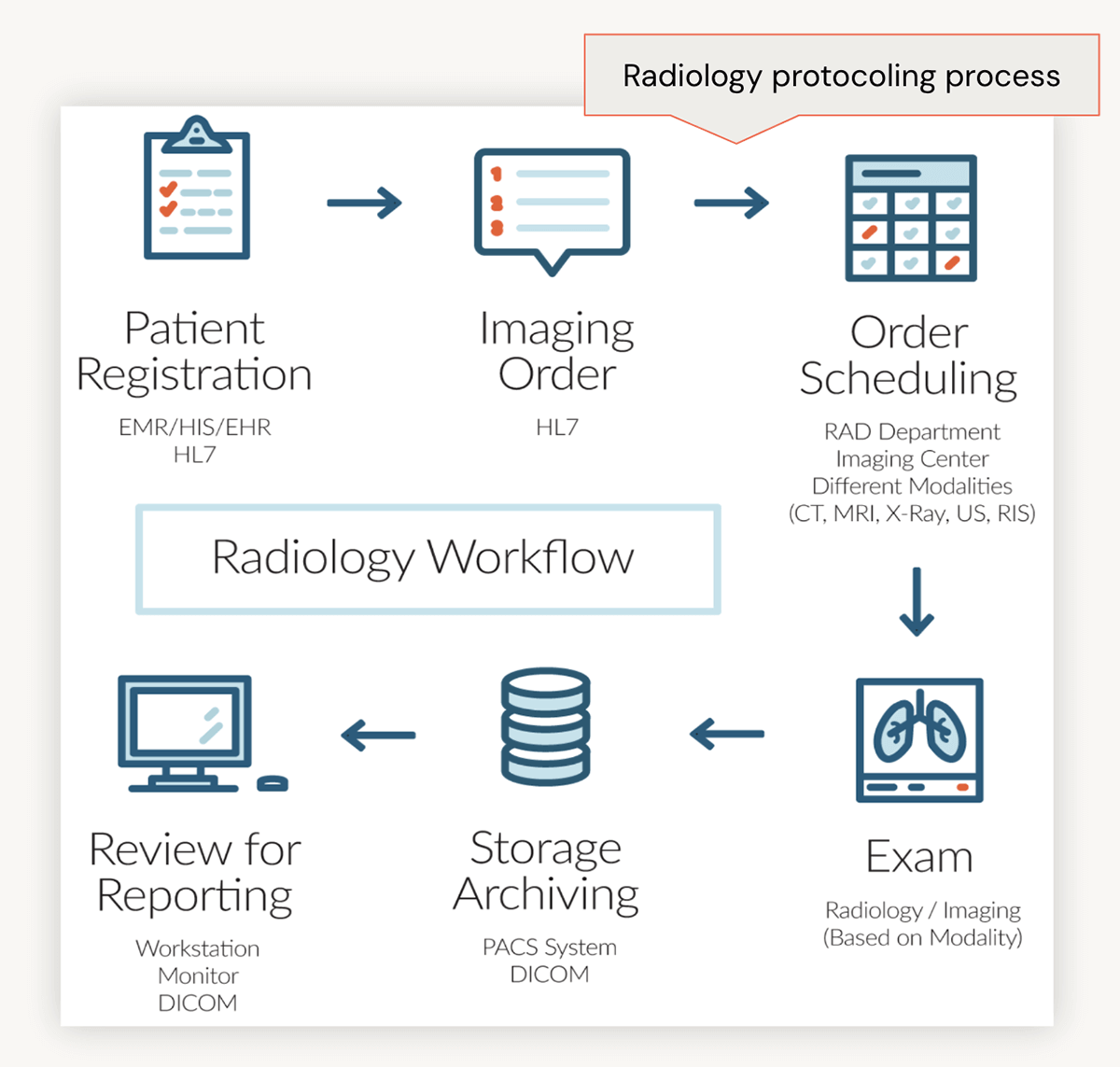
放射線科ワークフローにおける管理負担の特定
では、プロトコルラベルを割り当てる手動プロセスが重要なのはなぜですか? 主な理由は2つあります。
まず、人為的ミスに内在する不正確さを軽減するためです。 私たちの目的は、放射線科医に取って代わることではなく、放射線科医の意思決定プロセスを強化し、一貫性を高め、エラーを減らすことです。
第二に、放射線科医は、最も高給の医療専門家の一人であり、ラベルの割り当てに年間約3.5〜6.2%(1,2)、 年間約17,000〜30,000ドルに相当する時間を費やしています。 このプロセスを最適化することで、放射線科医はより影響力のあるタスクに努力を向けることができます。
大規模言語モデル (LLM) による手動�タスクの解決
この課題にどのように対処したのでしょうか? 最初に、ChatGPT を使用して、プロバイダーのメモと対応するプロトコル ラベルを模倣した合成データセットを生成しました。 法的制約により顧客による使用は推奨されませんが、この概念実証を効果的にサポートします。
そこで、ファインチューニングの基礎LLMとして Meditron-7b を選択しました。 PubMed の記事に基づいてトレーニングされたオープンソース である MeditronLLM は 、ヘルスケアやライフ サイエンスのアプリケーションに適しており、ファインチューニングによってさらに改善することができます。Meditron のような基盤モデルは広範囲にわたるため、私たちのユースケースでは具体的な内容が求められます。 ファインチューニングは、放射線プロトコルに関する当社の特殊な要件に合わせてモデルをカスタマイズします。
コスト効率を確保するため、私たちは Efficient ファインチューニング (PEFT) を実装しました。 このアプローチでは、ファインチューニング プロセス中に 引数 のサブセットを凍結し、引数 の一部のみを最適化します。 ディメンション マトリックスを分解することで、パフォーマンスを維持しながら計算要件を大幅に削減します。 たとえば、10,000 行 x 20,000 列の次元を持つ事前トレーニング済みの重みを表す行列 (W) を考えてみましょう。従来のファインチューニングでは、更新のために合計 2 億の行列が生成されます。 PEFTでは、内次元ハイパーパラメータを使用して、この行列を2つの小さな行列に分解します。 たとえば、W 行列を行列 A (10,000 行 x 8 列) と行列 B (8 行 x 20,000 列) に分解すると、240,000 個の行列のみを更新する必要があります。 これにより、更新を必要とするビルドの数が約 99% 削減されます。
QLoRA(Quantized Lower Rank Adaption)は、PEFT戦略の一環として導入しました。 QLoRAは、高精度コンピューティングと低精度ストレージアプローチを統合した4ビットトランスです。 これにより、高い性能と精度レベルを維持しながら、モデルをコンパクトに保ちます。
QLoRAは、高品質のパフォーマンスを維持しながらメモリ使用量を削減することを目的とした3つの革新的なコンセプト、4ビットノーマルフロート、ダブル量子化、およびページオプティマイザを導入しています。
- 4 ビットの通常浮動小数点数: この新しいデータ型により、ニューラルネットワークのサブセットの凍結が容易になり、 メンバ Efficient ファインチューニング (PEFT) が 16 ビットの精度に匹敵するパフォーマンス レベルを達成できるようになります。 凍結された 4 ビットの事前トレーニング済み言語および学習モデル ( LLM ) を介して勾配を LoRA に逆伝播することにより、ファインチューニング プロセス中に提供されたランク 引数 (r) に基づいて重み行列が分解されます。 r の値が小さいほど、更新行列が小さくなり、トレーニング可能な行列の数が少なくなります。
- 二重量子化: このプロセスでは、モデルの重みを低いビット深度にマッピングして、メモリと計算要件を削減します。 たとえば、16ビットのNFから始めて、8ビットに量子化した後、4ビットに量子化することがで��きます。 この方法を2回適用すると、平均して1インチあたり約0.37ビットの大幅なメモリ節約となり、65Bモデルの場合は約3GBに相当します(4)。
- ページ オプティマイザー: メイン メモリとセカンダリ ストレージ間のデータ転送を管理する "ポケットベル" の概念を利用して、ページ オプティマイザーは、メモリ内のモデルの重みとバイアスの配置を最適化します。 この最適化により、特にシーケンス長が拡張されたミニバッチの処理中に必要な時間とリソースが最小限に抑えられます。 ページ オプティマイザーは、勾配チェックポイントに関連するメモリ スパイクを防止することで、従来は単一のマシン上での大規模モデルのファインチューニングを妨げていたメモリ不足エラーを軽減します。
私たちのパイプラインは完全にDatabricks上で実行され、構造化されたフローに従います。つまりHugging Faceからベース Meditron モデルをDatabricksに取得し、合成データセットをUnity Catalog (UC) Volumes にインポートし、 Databricksで PEFT QLoRA を使用してファインチューニング プロセスを実行しました。
モデルの重み、チェックポイント、トークナイザーを UC ボリュームに保存し、MLflow を使用してモデルをログに記録し、UC に登録しました。 最後に、バッチ予測による推論に PySpark を利用しました。 意味的類似性は評価メトリクスとして機能し、評価プロセスにおけるコンテキストを考慮し、テキスト生成および要約タスク全体にわたる汎用性を確保します。
Databricks 内でこのパイプラインを実行する利点は、包括的なワークフロー機能と、すべてのレイヤーにわたる統合ガバナンスにあ�ります。 たとえば、医師が作成した機密性の高い患者メモへのアクセスを制限し、許可された担当者のみが閲覧できるようにすることができます。 同様に、モデル出力の使用を制御し、放射線科医などの関連する医療専門家のみがアクセスできるようにすることができます。
さらに、このセットアップで使用されるすべての機能が一般に利用可能であり、HIPPA 規制への準拠が保証されていることも注目に値します。
私たちは、このパイプラインがヘルスケアやライフサイエンスのさまざまなファインチューニング シナリオでメモリ使用量を最適化するための貴重な資産であることをお客様にご理解いただけると信じています。
次に放射線科医が医師のメモを確認し、複雑な病歴や診断を詳述したときを想像してみてください。診断:処置後、生検後、アピキサバンの肝裂傷への懸念」-当社のシステムは、「CT脳」ではなく「CT腹部W造影剤」などの適切なプロトコルラベルの正確な割り当てを保証します。 この精度により、診断効率と患者ケアを大幅に向上させることができます。
この Databricks ソリューション アクセラレータを使用して、LLM ユース ケースを開始してください。
参照
(1) Dhanoa D, Dhesi TS, Burton KR, Nicolaou S, Liang T.放射線科医の進化する役割:バンクーバーのワークロード使用率評価研究。 アメリカ放射線学会誌。 2013年10月1日;10(10):764–9.
(2) Schemmel A, Lee M, Hanley T, Pooler BD, Kennedy T, Field A, 他 放射線科ワークフローの混乱要因: 詳細な分析。 アメリカ放射線学会誌。 2016年10月1日;13(10):1210–4.
(3) https://www.doximity.com/reports/physician-compensation-report/2020
(4)デットマーズ、ティム、アルティドーロ・パニョーニ、アリ・ホルツマン、ルーク・ゼットルモイヤー。 「Qlora:量子化LLMの効率的なfinetuning」 神経情報処理システムの進歩 36 (2024)。
(5) https://magazine.sebastianraschka.com/p/lora-and-dora-from-scratch



{kind=link}