SnowflakeでUnityカタログテーブルを読み取るには!?たった4ステップ!
Unity Catalogは現在、Snowflake、Dremio、Starburst、EMRなどと連携して、データとAIを統合するお手伝いをします!

Summary
Unity CatalogのIceberg REST APIにSnowflakeから接続し、単一のソースデータファイルをIcebergとして読み込む方法を学びましょう。
Databricksは、オープンデータレイクハウスアーキテクチャを先駆けて開発し、フォーマットの相互運用性の最前線に立ってきました。私たちは、より多くのプラットフォームがレイクハウスアーキテクチャを採用し、相互運用可能なフォーマットと標準を採用し始めることを楽しみにしています。相互運用性は、顧客が分析やAIツールの選択によってデータの単一コピーを使用することで、高価なデータの複製を減らすことを可能にします。特に、私たちの顧客にとって一般的なパターンは、Databricksの最高クラスのETL価格/パフォーマンスを上流データに使用し、それをBIや分析ツール、例えばSnowflakeからアクセスすることです。
Unity Catalogは、データとAI資産のための統一されたオープンガバナンスソリューションです。Unity Catalogの主要な特徴は、Iceberg REST Catalog APIの実装です。これにより、メタデータの場所を手動で更新することなく、Iceberg準拠のリーダーを簡単に使用することができます。
このブログ投稿では、Iceberg RESTカタログがなぜ有用であるか、そしてSnowflakeでUnity Catalogテーブルを読み込む例を通じて説明します。
注:この機能は、すべてのクラウドプロバイダーで利用可能です。以下の手順はAWS S3に特化したものですが、Azure Data Lake Storage (ADLS)やGoogle Cloud Storage (GCS)などの他のオブジェクトストレージプラットフォームを使用することも可能です。
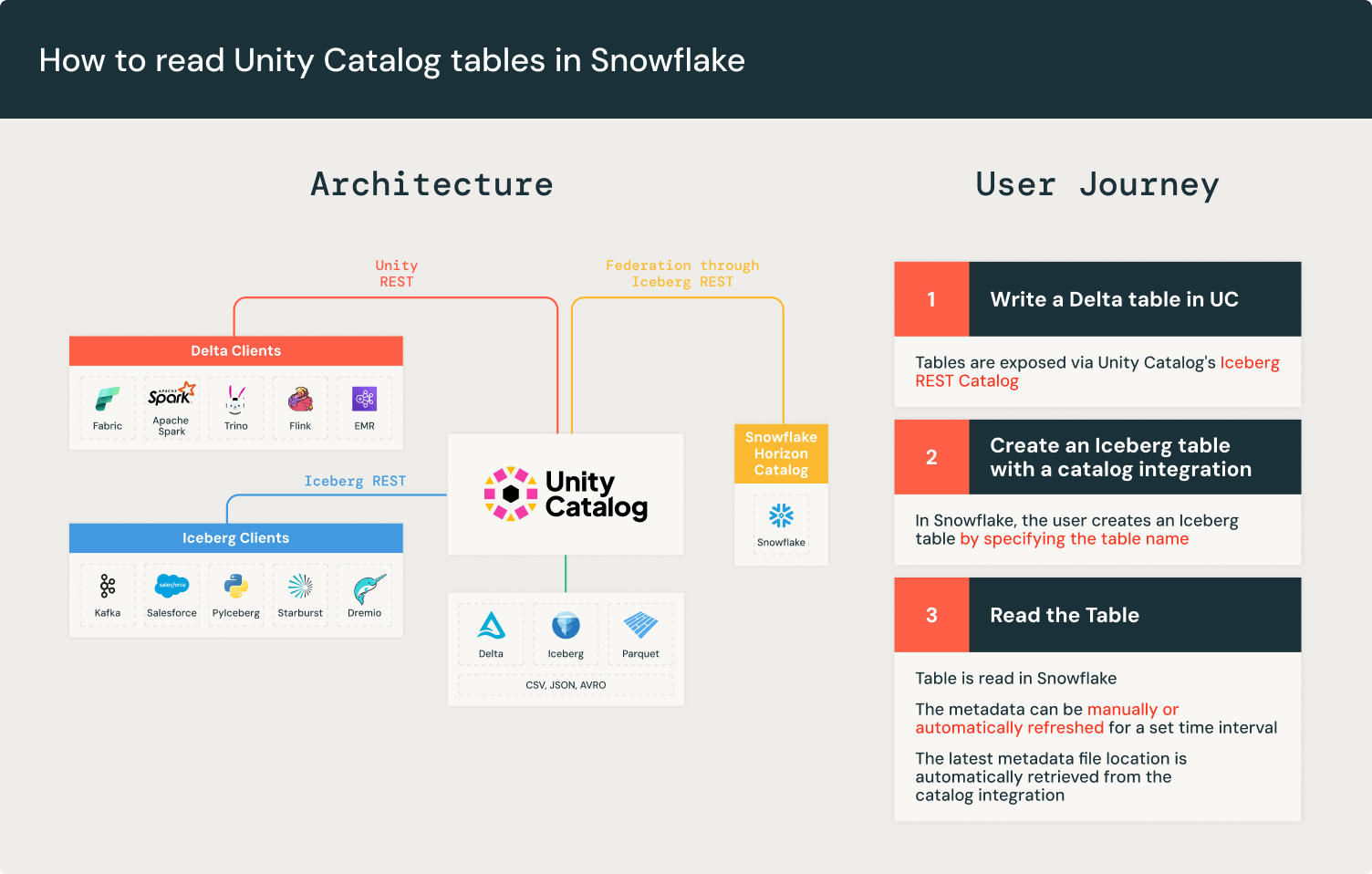
Iceberg REST APIカタログ統合
Apache Iceberg™は、各テーブルの変更ごとに新しいメタデータファイルを作成することで、原子性と一貫性を維持します。これにより、不完全な書き込みが既存のメタデータファイルを破損することはありません。Icebergカタログは、新しいメタデータを書き込みごとに追跡します。しかし、すべてのエンジンがすべてのIcebergカタログに接続できるわけではなく、顧客は新しいメタデータファイルの位置を手動で追跡する必要があります。
Icebergは、Iceberg RESTカタログAPIを使用してエンジンとカタログ間の相互運用性を解決します。Iceberg RESTカタログは、標準化されたオープンAPI仕様であり、Icebergカタログの統一されたインターフェースで、クライアントからカタログの実装を分離します。
Unity Catalogは、Universal Format(UniForm)の2023年のローンチ以来、Iceberg REST Catalog APIを実装しています。Unity Catalogは最新のテーブルメタデータを公開し、Apache Spark™、Apache Trino、SnowflakeなどのIceberg REST Catalogと互換性のある任意のIcebergクライアントとの相互運用性を保証します。Unity CatalogのIceberg REST Catalogエンドポイントは、ガバナンスとDelta Lakeテーブル機能を拡張し、Change Data Feedのような機能を提供します。
SnowflakeのREST APIカタログ統合を使用すると、Unity CatalogのIceberg REST APIに接続して最新のメタデータファイルの場所を取得できます。つまり、Unity Catalogを使用すると、Snowflakeでテーブルを直接読み取ることができます。
注: 現時点では、SnowflakeのIceberg RESTカタログのサポートはパブリックプレビュー中です。Unity CatalogのIceberg REST APIは一般利用可能です。
SnowflakeでRESTカタログ統合を作成するには4つのステップがあります:
- DatabricksのDelta LakeテーブルでUniFormを有効にし、Icebergのメタデータを生成します
- SnowflakeでUnity Catalogをカタログとして登録します
- SnowflakeでS3バケットを登録して、ソースデータを認識させます
- SnowflakeでIcebergテーブルを作成して、データをクエリすることができます
次のステップ
Databricksから始めて、Unity Catalogで管理されたテーブルを確認し、Icebergとして読み取れることを確認します。次に、残りのステップを完了するためにSnowflakeに移動します。
開始する前に、必要ないくつかのコンポーネントがあります:
- Unity Catalogを持つDatabricksアカウント(これは新しいワークスペースではデフォルトで有効化されています)
- AWS S3バケットとIAM権限
- DatabricksインスタンスとS3にアクセスできるSnowflakeアカウント
Unity Catalogの名前空間はカタログ名.スキーマ名.テーブル名の形式に従います。以下の例では、私たちのDatabricksテーブルに対してuc_catalog_name.uc_schema_name.uc_table_nameを使用します。
ステップ1: DatabricksのDeltaテーブルでUniFormを有効にする
Databricksでは、Delta LakeテーブルでUniFormを有効にすることができます。デフォルトでは、新しいテーブルはUnity Catalogによって管理されます。完全な指示はUniFormのドキュメンテーションにありますが、以下にも含まれています。
新しいテーブルの場合、ワークスペースでテーブル作成時にUniFormを有効にすることができます:
既存のテーブルがある場合、ALTER TABLEコマンドを使用してこれを行うことができます:
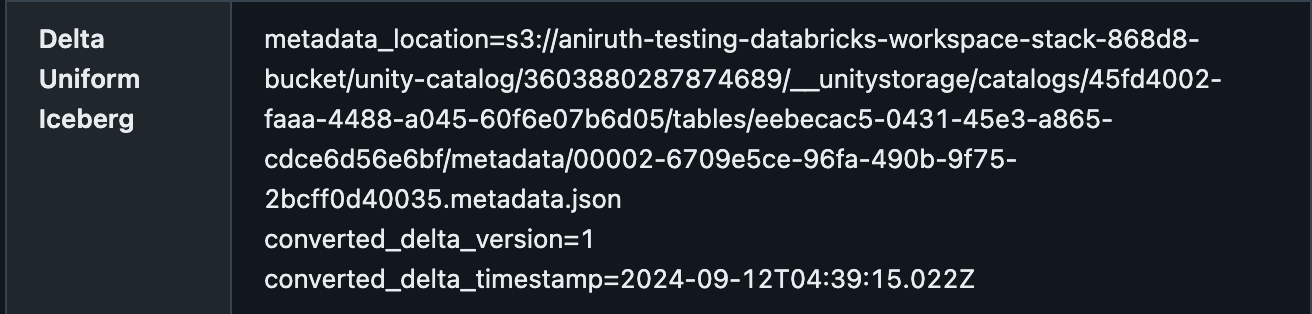
カタログエクスプローラの詳細タブで、メタデータの位置を確認することで、DeltaテーブルがUniFormを有効にしていることを確認できます。以下のようになるはずです:
ステップ2:SnowflakeにUnity Catalogを登録する
Databricks内でまだ作業中の場合、サービスプリンシパルを作成し、ワークスペースの管理設定から対応するシークレットとクライアントIDを生成します。サービスプリンシパルの代わりに、デバッグやテスト目的で個人トークンで認証することもできますが、開発と本番のワークロードではサービスプリンシパルの使用を推奨します。このステップから、あなたの<deployment-name>とOAuthの値<client-id>と<secret>が必要になります。これにより、Snowflakeでの統合を認証することができます。
これでSnowflakeアカウントに切り替えます。
注: DatabricksとSnowflakeの間には、混乱を招く可能性のあるいくつかの命名の違いがあります:
- Databricksの“catalog”は、Snowflake Icebergカタログ統合設定の“warehouse”です。
- Databricksの「スキーマ」は、Snowflake Icebergカタログ統合における「catalog_namespace」です。
以下の例では、CATALOG_NAMESPACEの値がUnity Catalogテーブルのuc_schema_nameであることがわかります。
Snowflakeでは、Iceberg RESTカタログのカタログ統合を作成します。そのプロセスに従って��、以下のようにカタログ統合を作成します:
REST API Catalog Integrationにより、時間ベースの自動更新が可能になります。自動更新を使用すると、Snowflakeはカタログ統合で定義された時間間隔でUnity Catalogから最新のメタデータロケーションをポーリングします。ただし、自動更新は手動更新と互換性がなく、テーブル更新後に時間間隔まで待つ必要があります。カタログ統合で設定されたREFRESH_INTERVAL_SECONDSパラメータは、この統合で作成されたすべてのSnowflake Icebergテーブルに適用されます。テーブルごとにカスタマイズすることはできません。
ステップ3:SnowflakeにS3バケットを登録します
Snowflakeでは、Amazon S3の外部ボリュームを設定します。これには、AWSでIAMロールを作成し、そのロールの信頼ポリシーを設定し、その後、ロールのARNを使用してSnowflakeで外部ボリュームを作成する作業が含まれます。
このステップでは、Unity Catalogが指向している同じS3バケットを使用します。
ステップ4:SnowflakeでApache Iceberg™テーブルを作成します
Snowflakeでは、Icebergテーブルを作成します先に作成したカタログ統合と外部ボリュームを使用してDelta Lakeテーブルに接続します。SnowflakeのIcebergテーブルの名前は自由に選ぶことができ、DatabricksのDelta Lakeテーブルと一致する必要はありません。
注: SnowflakeのCATALOG_TABLE_NAMEの正しいマッピングは、Databricksのテーブル名です。例えば、これはuc_table_nameです。カタログやスキーマはこのステップで指定する必要はありません。これらはすでにカタログ統合で指定されています。
オプションとして、自動更新を有効にすることができます。カタログ統合の時間間隔を追加してAUTO_REFRESH = TRUEコマンドを実行します。自動更新が有効になっている場合、手動更新は無効になることに注意してください。
これで、SnowflakeでDelta Lakeテーブルを正常に読み取ることができました。
完了: 接続のテスト
Databricksで、新しい行を挿入してDeltaテーブルのデータを更新します。
以前に自動更新を有効にした場合、テーブルは指定した時間間隔で自動的に更新されます。有効にしていない場合は、ALTER ICEBERG TABLE <snowflake_table_name> REFRESHを実行して手動で更新できます。
注:以前に自動更新を有効にした場合、手動で更新コマンドを実行することはできず、テーブルを更新するためには自動更新間隔が完了するのを待つ必要があります。
動画デモ
ビデオチュートリアルが必要な場合、このビデオでは、これらのステップを組み合わせてSnowflakeでUniFormを使用してDeltaテーブルを読み込む方法を示しています。
レイクハウスアーキテクチャへの継続的なサポートに感謝しています。顧客はもはやデータを複製する必要がなく、コストと複雑さが削減されます。このアーキテクチャは、顧客が適切なツールを適切なワークロードに選択することを可能にします。
オープンなレイクハウスの鍵は、Delta LakeやIcebergのようなオープンな形式でデータを保存することです。独自のフォーマットは顧客をエンジンに閉じ込めますが、オープンフォーマットは柔軟性と移植性を提供します。プラットフォームに関係なく、顧客が常に自分のデータを所有することを我々は推奨します。これが相互運用性への第一歩です。今後数ヶ月間で、Unity Catalogを使用してオープンデータレイクハウスをより簡単に管理する機能を続けて開発します。

