
Databricksでは、大規模AIモデルのための最も効率的で高性能なトレーニングツールの構築に尽力しています。最近リリースされたDBRXでは、トレーニングと推論の効率を大幅に向上させるMixture-of-Experts(MoE)モデルの力を強調しました。本日、DBRXのトレーニングに使用されたオープンソースライブラリであるMegaBlocksが公式のDatabricksプロジェクトになることを発表します。また、オープンソースのトレーニングスタックであるLLMFoundryへのMegaBlocks統合もリリースします。これらのオープンソースリリースに加え、スケールで最高のパフォーマンスを得る準備ができたお客様に対して、最適化された内部バ�ージョンのオンボーディングも開始します。
Mixture of Experts(MoE)モデルとは?
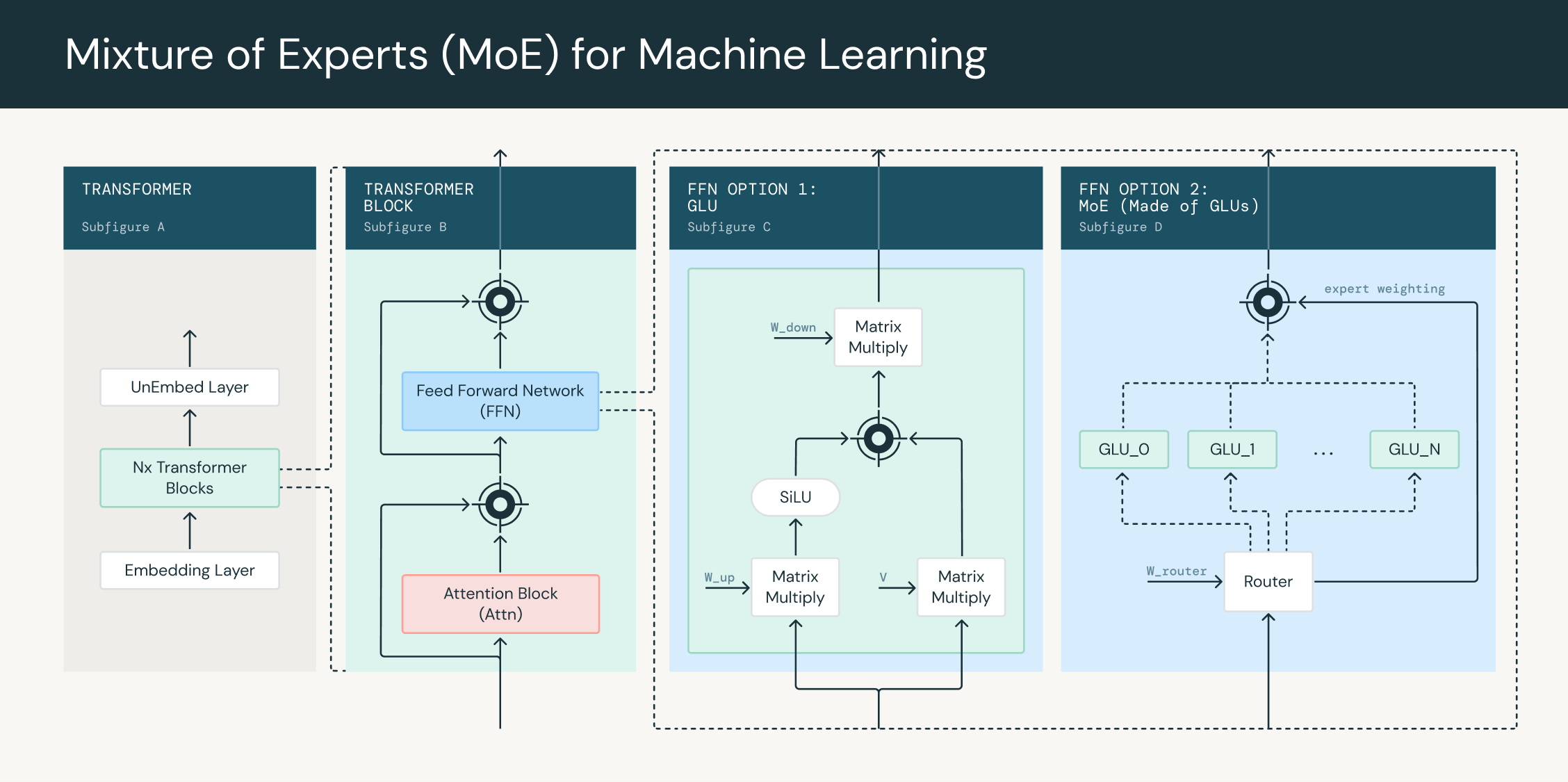
Mixture of Experts(MoE)モデルは、複数の専門ネットワーク、または「エキスパート」の出力を組み合わせて予測を行う機械学習モデルです。各エキスパートは入力空間の特定の領域に特化しており、ゲーティングネットワークが与えられた入力に対してエキスパートの出力をどのように組み合わせるかを決定します。
トランスフォーマーネットワークの文脈では、各フィードフォワードブロックをMoE層に置き換えることができます。この層は、それぞれ独自のパラメータセットを持つ複数のエキスパートネットワークと、各入力トークンのエキスパートの出力をどのように重み付けするかを決定するゲーティングネットワークで構成されています。ゲーティングネットワークは通常、各トークンを入力として取り込み、重みのセットを出力する線形層のフィードフォワードネットワークです。トークン割り当てアルゴリズムはこれらの重みを使用して、どのトークンがどのエキスパートにルーティングされるかを選択します。トレーニング中、ゲーティングネットワークは入力をエキスパートに割り当てる方法を学習し、モデルが専門化し、そのパフォーマンスを向上させることができます。
MoE層は、各トークンを処理するために使用される操作数を増やすことなく、トランスフォーマーネットワークのパラメータ数を増やすために使用できます。これは、ゲーティングネットワークがトークンを全エキスパートセットの一部 F < 1 に送るためです。MoEネットワークはNパラメータのネットワークですが、N * Fパラ��メータのネットワークと同じ計算しか必要ありません。例えば、DBRXは132Bパラメータモデルですが、36Bパラメータモデルと同じ計算量しか必要としません。
MegaBlocksの管理を行うには
MegaBlocksは、Trevor Galeがスパーストレーニングの研究の一環として作成した効率的なMoE実装です。MegaBlocksは、スパース行列乗算を使用して、各エキスパートに異なる数のトークンが割り当てられている場合でも、すべてのエキスパートを並列に計算するというアイデアを導入しました。このプロジェクトは人気が高まり、HuggingFaceのNanotron、EleutherAIのGPT-NeoX、MistralのMixtral 8x7Bのリファレンス実装、そしてもちろん私たちのDBRX実装など、数多くのスタックのコアコンポーネントとなっています。
Databricksは、このプロジェクトの所有権を取得し、それを取り巻くオープンソースコミュニティのために長期的なサポートを提供することを楽しみにしています。Trevorは共同メンテナーとして引き続きプロジェクトに関与し、ロードマップに積極的に参加します。リポジトリはGitHubの新しいホームであるdatabricks/megablocksに移管され、そこでプロジェクトの成長とサポートを続けていきます。当面のロードマップは、プロジェクトを本番品質にアップグレードすることに焦点を当てており、DatabricksのGPUをCI/CDに投入し、定期的なリリースサイクルを確立し、さらにスパース性の研究を可能にする拡張可能な設計を確保することを含んでいます。関与に興味がある方は、issuesページでフィーチャーリクエストをお聞かせください!
LLMFoundry統合のオープンソース化
MegaBlocksはMoE層の実装を提供しますが、完全なトランスフォーマーを実装し、並列化戦略を提供し、スケールで効率的にトレーニングするためには、より大きなフレームワークが必要です。私たちは、MegaBlocksの統合をLLMFoundryにオー��プンソース化することを楽しみにしています。LLMFoundryは、大規模なAIモデル用のオープンソーストレーニングスタックであり、PyTorch FSDPと統合された拡張可能で構成可能なトランスフォーマーの実装を提供し、大規模なMoEトレーニングを可能にします。この統合は、DBRXのトレーニングの中核を成し、130B+パラメータモデルへのスケーリングを可能にしました。
既存のYAMLファイルは簡単に調整してMoE層を含めることができます。
Databricksの最適化されたトレーニング
MegaBlocksに加えて、私たちは何千ものGPUでパフォーマンスを最適化するためのさまざまな手法を構築しました。私たちのプレミアム提供には、カスタムカーネル、8ビットサポート、および線形スケーリングが含まれており、特に大規模モデルにおいて非常に優れたパフォーマンスを達成します。次世代のMoEプラットフォームへの顧客のオンボーディングを開始することに非常に興奮しています。今すぐお問い合わせください!