
本日、Databricksが開発したオープンで汎用的なLLM、DBRXをご紹介します。 DBRXは、さまざまな標準ベンチマークにおいて、確立されたオープンLLMの新たな最先端を打ち立てました。 さらに、これまでクローズドモデルのAPIに限られていた機能を、オープンコミュニティや独自のLLMを構築する企業に提供します。私たちの測定によると、GPT-3.5を上回り、Gemini 1.0 Proに引けを取りません。 汎用LLMとしての強みに加え、CodeLaMA-70Bのようなプログラミングに特化したモデルを凌ぐ、特に優れたコードモデルです。
この最先端の品質は、訓練と推論の性能の著しい向上とともにもたらされます。 DBRXは、そのきめ細かなMoE(Mixture-of-Experts; 専門家混合)アーキテクチャにより、オープンモデルの中で最先端の効率性を実現しています。 推論はLLaMA2-70Bの2倍速く、DBRXはGrok-1の約40%のサイズです。 Mosaic AI Model Serving上でホストされた場合、DBRXは最大150トークン/秒/ユーザーでテキストを生成できます。 MoEのトレーニングは、同じ最終的なモデル品質で密なモデルをトレーニングするよりも、FLOP効率が約2倍高いことがお分かりいただけると思います。 エンドツーエンドでは、DBRXの全体的なレシピ(事前学習データ、モデルアーキテクチャ、最適化戦略を含む)は、4倍近い少ない計算量で、前世代のMPTモデルの品質に匹敵します。
ベースモデル(DBRX Base)とファインチューンモデル(DBRX Instruct)のウェイトは、オープンライセンスのもと、Hugging Faceで�公開されています。 Databricksのお客様は、DBRXを構築するために使用したのと同じツールとサイエンスを使用して、独自のDBRXクラスのモデルをゼロから事前トレーニングしたり、チェックポイントの上でトレーニングを継続したりすることができます。 DBRXはすでに当社の生成AI搭載製品に統合されており、SQLのようなアプリケーションでは、初期のロールアウトがGPT-3.5 Turboを上回り、GPT-4 Turboの性能に挑戦しています。 また、RAGタスクにおいて、オープンモデルやGPT-3.5 Turboと比べてDBRXはトップクラスのモデルです。
専門家混合モデルのトレーニングは簡単ではありません。 DBRXクラスのモデルを効率的な方法で繰り返し学習させるのに十分な堅牢なパイプラインを構築するためには、科学的かつ性能的なさまざまな課題を克服する必要がありました。 その結果、どのような企業でもワールドクラスのMoE基盤モデルをゼロからトレーニングできる、他に類を見ないトレーニングスタックを手に入れることができました。 私たちは、その能力をお客様と共有し、学んだことをコミュニティと共有することを楽しみにしています。
今すぐHugging FaceからDBRXをダウンロードするか(DBRX Base,DBRX Instruct)、HF SpaceでDBRX Instructを試すか、githubのモデルリポジトリをご覧ください:databricks/dbrx.
DBRXとは何か?
DBRXはトランスフォーマーベースのデコーダのみの大規模言語モデル(LLM)で、ネクストトークン予測を使用して学習されました。 MoE(Mixture-of-Experts)アーキテクチャを採用し、総パラメータは132Bで、そのうち36Bのパラメータが任意の入力に対してアクティブになります。 DBRXは、12Tのテキストとコードデータのトークンで事前に訓練されました。 MixtralやGrok-1のような他のオープンMoEモデルと比較すると、DBRXはきめ細かく、つまりより多くの小規模なエキスパートを使用します。 DBRXは16人のエキスパートを持ち、4人を選びますが、MixtralとGrok-1は8人のエキスパートを持ち、2人を選びます。これにより65倍の専門家の組み合わせが可能になり、モデルの品質が向上することがわかりました。 DBRXは回転位置エンコーディング(RoPE)、ゲート線形ユニット(GLU)、グループ化クエリーアテンション(GQA)を使用します。 tiktokenリポジトリで提供されているGPT-4トークナイザを使用しています。 これらの選択は、徹底的な評価とスケーリング実験に基づいて行いました。
DBRXは入念にキュレーションされた12Tトークンのデータで事前学習され、コンテキストの最大長は32kトークンでした。 このデータは、MPTモデルの事前学習に使用したデータよりも、トークン対トークンで少なくとも2倍優れていると推定されます。 この新しいデータセットは、データ処理のためのApache Spark™ とDatabricksノートブック、データ管理とガバナンスのためのUnity Catalog、実験追跡のためのMLflowを含むDatabricksツール一式を使用して開発されました。 事前学習にはカリキュラム学習を使い、学習中にデータの組み合わせを変更することで、モデルの質が大幅に向上することがわかりました。
主要オープンモデルとのベンチマーク比較における品質
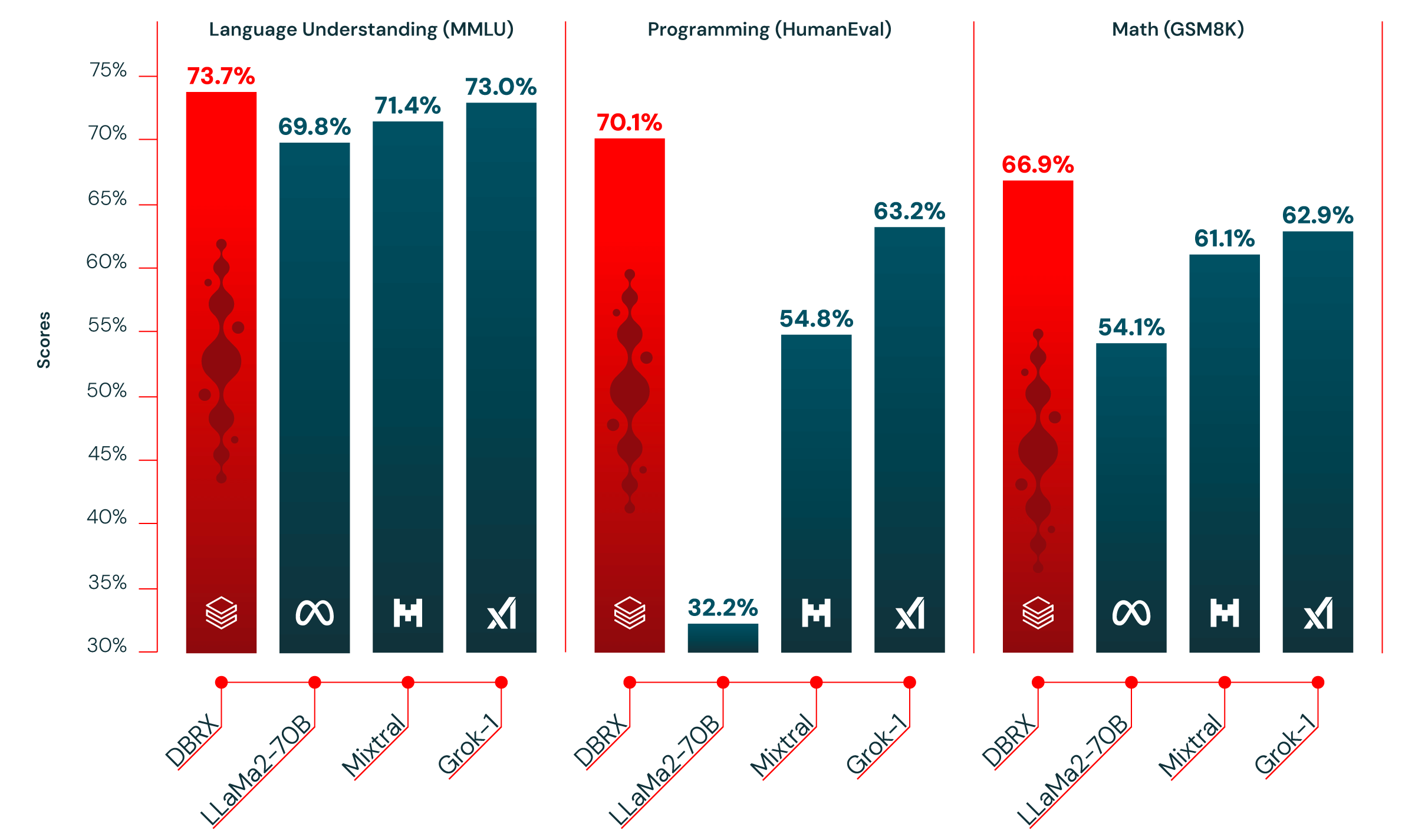
表1は、DBRX Instructと主要な確立されたオープンモデルの品質を示しています。 DBRX Instructは、複合ベンチマーク、プログラミングおよび数学ベンチマーク、MMLUの主要モデルです。 標準的なベンチマークでは、すべてのチャットやインストラクションのファインチューンモデルを上回っています。
複合ベンチマーク:Hugging Face Open LLM Leaderboard(ARC-Challenge、HellaSwag、MMLU、TruthfulQA、WinoGrande、GSM8kの平均)とDatabricks Model Gauntlet(世界知識、常識的推論、言語理解、読解、記号的問題解決、プログラミングの6つのカテゴリにまたがる30以上のタスク群)の2つの複合ベンチマークでDBRX Instructと主要モデルを評価しました。
私たちが評価したモデルの中で、DBRX Instructは2つの複合ベンチマークで最高得点を記録しました:Hugging Face Open LLM Leaderboard(74.5% vs. 72.7%)。 とDatabricks Gauntlet(66.8% vs. 次点のMixtral Instructは60.7%)。
プロ��グラミングと数学:DBRX Instructは特にプログラミングと数学が得意です。 HumanEval(70.1% vs. Grok-1:63.2%、Mixtral Instruct:54.8%、最もパフォーマンスの高いLLaMA2-70B variant:32.2%)およびGSM8k(66.9% vs. Grok-1:62.9%、Mixtral Instruct:61.1%、最もパフォーマンスの高いLLaMA2-70B variant:54.1%)で評価した他のオープンモデルよりも高いスコアです。 DBRXは、Grok-1が2.4倍のパラメータを持つにもかかわらず、これらのベンチマークで次に優れたモデルであるGrok-1を上回っています。 HumanEvalでは、DBRX Instructは、DBRX Instructが汎用的に使用されるように設計されているにもかかわらず、明示的にプログラミングのために構築されたモデルであるCodeLLaMA-70B Instructを上回っています(CodeLLaMAブログでMetaが報告したHumanEvalでの70.1% vs. 67.8%)。
MMLU:DBRX Instructは、MMLUのスコアが73.7%に達し、私たちが検討した他のすべてのモデルよりも高くなっています。
| モデル | DBRX Instruct | Mixtral Instruct | Mixtral Base | LLaMA2-70B Chat | LLaMA2-70B Base | Grok-11 |
Open LLM Leaderboad2 (次の6行の平均) | 74.5% | 72.7% | 68.4% | 62.4% | 67.9% | - |
| ARC-challenge 25-shot | 68.9% | 70.1% | 66.4% | 64.6% | 67.3% | - |
| HellaSwag 10-shot | 89.0% | 87.6% | 86.5% | 85.9% | 87.3% | - |
| MMLU 5-shot | 73.7% | 71.4% | 71.9% | 63.9% | 69.8% | 73.0% |
| Truthful QA 0-shot | 66.9% | 65.0% | 46.8% | 52.8% | 44.9% | - |
| WinoGrande 5-shot | 81.8% | 81.1% | 81.7% | 80.5% | 83.7% | - |
| GSM8k CoT 5-shot maj@1 3 | 66.9% | 61.1% | 57.6% | 26.7% | 54.1% | 62.9%(8-shot) |
Gauntlet v0.34 (平均30以上の多様なタスク) | 66.8% | 60.7% | 56.8% | 52.8% | 56.4% | - |
HumanEval5 0-Shot, pass@1。 (プログラミング) | 70.1% | 54.8% | 40.2% | 32.2% | 31.0% | 63.2% |
表1. DBRX Instructと主要オープンモデルの品質。 数字の収集方法については脚注を参照。 太字と下線は最高得点。
主要クローズドモデルとのベンチマーク比較における品質
表2は、DBRX Instructと主要なクローズドモデルの品質を示しています。 各モデル作成者が報告したスコアによると、DBRX InstructはGPT-3.5(GPT-4論文に記載)を上回り、Gemini 1.0 ProやMistral Mediumに引けを取りません。
私たちが検討したほぼすべてのベンチマークにおいて、DBRX InstructはGPT-3.5を上回るか、最悪でもGPT-3.5に匹敵します。 DBRX Instructは、MMLUで測定される一般知識でGPT-3.5を上回ります(73.7% vs. 70.0%)。 常識的推論は、HellaSwag(89.0% vs. 85.5%)およびWinoGrande(81.8% vs. 81.6%)で測定されました。 DBRX Instructは、HumanEval(70.1% vs. 48.1%)とGSM8k(72.8%対57.1%)によって測定されたように、プログラミングと数学的推論に特に優れています。
DBRX Instructは、Gemini 1.0 ProやMistral Mediumに引けを取りません。 DBRX Instructのスコアは、Inflection Corrected MTBench、MMLU、HellaSwag、HumanEvalではGemini 1.0 Proよりも高く、GSM8kではGemini 1.0 Proの方が優れています。 DBRX InstructとMistral MediumのスコアはHellaSwagではほぼ同じですが、Mistral MediumはWinograndeとMMLUでより強く、DBRX InstructはHumanEval、GSM8k、Inflection Corrected MTBenchでより強くなっています。
| モデル | DBRX Instruct | GPT-3.57 | GPT-48 | Claude 3 Haiku | Claude3 Sonnet | Claude 3 Opus | Gemini 1.0 Pro | Gemini 1.5 Pro | Mistral Medium | Mistral Large |
| MT Bench(変曲補正済み, n=5) | 8.39 ± 0.08 | - | - | 8.41 ± 0.04 | 8.54 ± 0.09 | 9.03 ± 0.06 | 8.23 ± 0.08 | - | 8.05 ± 0.12 | 8.90 ± 0.06 |
| MMLU 5-shot | 73.7% | 70.0% | 86.4% | 75.2% | 79.0% | 86.8% | 71.8% | 81.9% | 75.3% | 81.2% |
| HellaSwag 10-shot | 89.0% | 85.5% | 95.3% | 85.9% | 89.0% | 95.4% | 84.7% | 92.5% | 88.0% | 89.2% |
| HumanEval 0-shot pass@1 (プログラミング) | 70.1% temp=0, N=1 | 48.1% | 67.0% | 75.9% | 73.0% | 84.9% | 67.7% | 71.9% | 38.4% | 45.1% |
| GSM8k CoT maj@1 | 72.8%(5ショット) | 57.1%(5ショット) | 92.0%(5ショット) | 88.9% | 92.3% | 95.0% | 86.5% (maj1@32) | 91.7%(11ショット) | 66.7%(5ショット) | 81.0%(5ショット) |
| WinoGrande 5-shot | 81.8% | 81.6% | 87.5% | - | - | - | - | - | 88.0% | 86.7% |
表2.DBRX Instructと主要クローズドモデルの品質。 Inflection Corrected MTBench(モデルのエンドポイントで独自に測定)以外の数値は、各モデルの作成者がそれぞれのホワイトペーパーで報告している通りです。 詳細は脚注を参照。
ロングコンテキストタスクの品質とRAG
DBRX Instructは、最大32Kトークンコンテキストウィンドウで学習されました。 表3は、ロングコンテキストベンチマーク(Lost in the Middle論文のKV-Pairsと、タスクをより長いシーケンス長に拡張したHotPotQAの修正版であるHotpotQAXL)において、Mixtral InstructとGPT-3.5 TurboおよびGPT-4 Turbo APIの最新バージョンとの性能を比較したものです。 GPT-4 Turboは、一般的にこれらのタスクで最高のモデルです。 しかし、1つの例外を除いて、DBRX Instructは、すべてのコンテキスト長とシーケンスのすべての部分でGPT-3.5 Turboよりも優れた性能を発揮します。 DBRX InstructとMixtral Instructの全体的なパフォーマンスはほぼ同じです。
| モデル | DBRX Instruct | Mixtral Instruct | GPT-3.5 Turbo(API) | GPT-4 Turbo(API) |
| 文脈の冒頭3番目の答え | 45.1% | 41.3% | 37.3%* | 49.3% |
| 文脈の真ん中3分の1の答え | 45.3% | 42.7% | 37.3%* | 49.0% |
| 文脈の最後の3分の1の答え | 48.0% | 44.4% | 37.0%* | 50.9% |
| 2Kコンテキスト | 59.1% | 64.6% | 36.3% | 69.3% |
| 4K コンテキスト | 65.1% | 59.9% | 35.9% | 63.5% |
| 8K コンテキスト | 59.5% | 55.3% | 45.0% | 61.5% |
| 16K コンテキスト | 27.0% | 20.1% | 31.7% | 26.0% |
| 32K コンテキスト | 19.9% | 14.0% | - | 28.5% |
表3. KV-PairsおよびHotpotQAXLベンチマークにおける各モデルの平均性能。 太字は最高得点。 下線はGPT-4 Turbo以外の最高得点。 GPT-3.5 Turboは最大16Kのコンテキスト長をサポートしているため、32Kでは評価できませんでした。*GPT-3.5 Turboのシーケンスの開始、中間、終了の平均は、16Kまでのコンテキストのみを含みます。
モデルのコンテキストを活用する最も一般的な方法の1つは、検索拡張生成(RAG)です。 RAGでは、プロンプトに関連するコンテンツがデータベースから検索され、プロンプトと一緒に表示されます。 表4は、埋め込みモデルbge-large-en-v1.5を使用してWikipedia記事のコーパスから検索されたトップ10の文章をモデルにも提供した場合の、2つのRAGベンチマーク(Natural QuestionsとHotPotQA)におけるDBRXの品質を示しています。 DBRX Instructは、Mixtral InstructやLLaMA2-70B ChatのようなオープンモデルやGPT-3.5 Turboの現行バージョンと競争��力があります。
| モデル | DBRX Instruct | Mixtral Instruct | LLaMa2-70B Chat | GPT3.5 Turbo(API) | GPT 4 Turbo(API) |
| 自然な質問 | 60.0% | 59.1% | 56.5% | 57.7% | 63.9% |
| HotPotQA | 55.0% | 54.2% | 54.7% | 53.0% | 62.9% |
表4. bge-large-en-v1.5を使用してWikipediaコーパスから検索された上位10行を各モデルに与えた場合のモデルの性能。 精度は、モデルの答えの範囲内で一致するかどうかで測定されます。 太字は最高得点。 下線はGPT-4ターボ以外の最高得点。
トレーニングの効率
モデルの質は、そのモデルがいかに効率的に訓練され、使用されるかという文脈の中に置かれなければなりません。 Databricksでは特にそうです。DBRXのようなモデルを構築し、お客様が独自の基礎モデルをトレーニングするプロセスを確立しています。
専門家混合モデルをトレーニングすることで、トレーニングの計算効率が大幅に向上することがわかりました(表5)。 たとえば、DBRX MoE-B(総パラメータ23.5B、アクティブパラメータ6.6B)と呼ばれるDBRXファミリーの小型モデルのトレーニングでは、Databricks LLM Gauntletで45.5%のスコアに到達するのに必要なFLOP数は、LLaMA2-13Bが43.8%に到達するのに必要なFLOP数の1.7倍でした。 また、DBRX MoE-BはLLaMA2-13Bの半分のアクティブパラメータを含んでいます。
総合的に見ると、私たちのエンドツーエンドのLLM事前学習パイプラインは、この10ヶ月で計算効率が4倍近く向上しました。 2023年5月5日、1Tトークンで学習させた7BパラメータモデルであるMPT-7Bをリリースし、Databricks LLMガントレットスコア30.9%を達成しました。 DBRX MoE-A(総パラメータ7.7B、アクティブパラメータ2.2B)と呼ばれるDBRXファミリーのメンバーは、3.7倍のFLOP数で30.5%のDatabricks Gauntletスコアを達成しました。 この効率性は、MoEアーキテクチャの使用、ネットワークのその他のアーキテクチャの変更、より優れた最適化戦略、より優れたトークン化、そして非常に重要なことですが、より優れた事前学習データなど、多くの改良の結果です。
単独では、より良い事前学習データがモデルの品質に大きな影響を与えました。 DBRXの事前学習データを使って、1Tトークンの7Bモデル(DBRX Dense-A)を学習しました。 MPT-7Bが30.9%だったのに対し、Databricks Gauntletでは39.0%に達しました。 この新しい事前学習データは、MPT-7Bの学習に使用されたデータよりも、トークン対トークンで少なくとも2倍優れていると推定されます。 言い換えれば、同じモデル品質に到達するためには、半分の数のトークンが必要であると推定されます。 DBRX Dense-AはDatabricks GauntletでMPT-7Bを上回り、32.1%に達しました。 データ品質が向上したことに加え、トークン効率に大きく貢献したのは、語彙が多く、特にトークン効率が高いとされるGPT-4トークナイザーかもしれません。 データ品質の向上に関するこれらの教訓は、お客様がご自身のデータで基礎モデルをトレーニングするために使用するプラクティスやツールに直接反映されます。
| モデル | 合計 | アクティブパラメータ | ガントレ��ットのスコア | 相対FLOP数 |
| DBRX MoE-A | 7.7B | 2.2B | 30.5% | 1x |
| MPT-7B(1Tトークン) | - | 6.7B | 30.9% | 3.7x |
| DBRX Dense-A(1Tトークン) | - | 6.7B | 39.0% | 3.7x |
| DBRX Dense-A(500Bトークン) | - | 6.7B | 32.1% | 1.85x |
| DBRX MoE-B | 23.5B | 6.6B | 45.5% | 1x |
| LLaMA2-13B | - | 13.0B | 43.8% | 1.7x |
表5. DBRX MoEアーキテクチャとエンドツーエンドトレーニングパイプラインのトレーニング効率を検証するために使用した複数のテスト記事の詳細
推論効率
図2は、NVIDIA TensorRT-LLMを使用し、最適化されたサービングインフラストラクチャと16ビット精度でDBRXと同様のモデルをサービングした場合のエンドツーエンドの推論効率を示しています。 このベンチマークは、複数のユーザーが同時に同じ推論サーバーにアクセスするなど、実際の使用状況をできるだけ忠実に反映することを目指しています。 1秒間に1人の新規ユーザーを生成し、各ユーザーリクエストには約2000トークンプロンプトが含まれ、各レスポンスには256トークンが含まれます。
一般的に、MoEモデルは、その総パラメータ数から想像されるよりも推論が高速です。 これは、各入力に使用するパラメータが比較的少ないためです。 この点ではDBRXも例外ではありません。 DBRXの推論スループットは、132Bの非MoEモデルより2~3倍高くなります。
推論の効率とモデルの質は、一般的に相反するものです。一般的に、より大きなモデルの方が質は高くなりますが、より小さなモデルの方が推��論の効率は高くなります。 MoEアーキテクチャを使用することで、密なモデルが一般的に達成するよりも、モデルの品質と推論効率のトレードオフを改善することができます。 例えば、DBRXはLLaMA2-70Bよりも高品質で、アクティブパラメーターの数が約半分であるため、DBRXの推論スループットは最大2倍高速です(図2)。 Mixtralは、MoEモデルによって達成された改善されたパレートフロンティアのもう一つのポイントです。DBRXよりも小さく、品質という点では劣りますが、推論スループットは高くなります。 Databricks基盤モデルAPIのユーザーは、8ビット量子化で最適化されたモデルサービングプラットフォーム上で、DBRXで毎秒最大150トークンを期待できます。

DBRXの構築方法
DBRXは、3.2Tbps Infinibandで接続された3072台のNVIDIA H100で学習されました。 事前トレーニング、事後トレーニング、評価、レッドチーム、改良など、DBRX構築の主なプロセスは3カ月にわたって行われました。 数ヶ月にわたる科学、データセットの研究、スケーリング実験の継続であり、MPTプロジェクトやDollyプロジェクトを含むDatabricksのLLM開発の数年間は言うまでもありません。
DBRXを構築するために、Databricksの顧客が利用できるのと同じツール群を活用しました。 Unity Catalogを使用してトレーニングデータを管理・統制しました。 私たちは、新たに入手したLilac AIを使って、このデータを探索しました。 Apache Spark™ と Databricks ノートブックを使用して、このデータを処理し、クリーニングしました。 DBRXのトレーニングには、オープンソースのトレーニングライブラリを最適化したものを使用しました:MegaBlocks、LLM Foundry、Composer、Streamingです。 私たちは、Mosaic AI Trainingサービスを使って、何千ものGPUにまたがる大規模なモデルのトレーニングとファインチューニングを管理しました。 結果はMLflowを使って記録しました。 私たちはMosaic AIモデルサービングと推論テーブルを通じて、品質と安全性向上のための人間のフィードバックを集めました。 Databricks Playgroundを使用して、手動でモデルの実験を行いました。 Databricksのツールは、それぞれの目的に対して最高品質のものであり、それらがすべて統一された製品体験の一部であるという事実から、私たちは恩恵を受けることができました。
DatabricksでDBRXを始めましょう
DBRXをすぐに使い始めたい場合、Databricks Mosaic AI 基盤モデルAPIを使えば簡単です。従量課金ですぐに始められ、AI Playgroundのチャットインターフェイスからモデルをクエリできます。本番アプリケーションには、プロビジョニングされたスループットオプションを提供し、パフォーマンス保証、きめ細かいモデルのサポート、追加のセキュリティとコンプライアンスを提供します。DBRXをプライベートホストするには、Databricks Marketplaceからモデルをダウンロードし、Model Servingでモデルをデプロイします。
結論
Databricksでは、すべての企業が生成AIの新興世界においてデータとその運命をコントロールする能力を持つべきだと考えています。 DBRXは私たちの次世代生成AI製品の中心的な柱であり、DBRXの機能とそれを構築するために私たちが使用したツールを活用することで、私たちの顧客を待っているエキサイティングな旅を楽しみにしています。 この1年間で、私たちはお客様とともに何千ものLLMを訓練してきました。 DBRXは、内部的な機能から顧客の野心的なユースケースまで、幅広い用途のためにDatabricksで構築されている強力で効率的なモデルの一例に過ぎません。
どのような新しいモデルでもそうですが、DBRXの旅は始まりに過ぎず、最高の仕事はDBRXを構築する人々、つまり企業やオープンコミュニティによってなされるでしょう。 また、これはDBRXに関する私たちの仕事のほんの始まりに過ぎません。
コントリビューション
DBRXの開発は、以前MPTモデルファミリーを構築したMosaicチームが中心となり、Databricks社内の数十人のエンジニア、弁護士、調達・財務スペシャリスト、プログラムマネージャー、マーケティング担当者、デザイナー、その他の貢献者と協力して行われました。 この数カ月間、辛抱強く支えてくれた同僚、友人、家族、そして地域社会に感謝しています。
DBRXを構築するにあたり、私たちはオープンコミュニティとアカデミックコミュニティの巨人の肩の上に立っています。 DBRXをオープンにすることで、私たちはコミュニティに投資し、将来的にさらに素晴らしい技術を一緒に作り上げることを望んでいます。 このことを念頭に、Trevor Galeと彼のMegaBlocksプロジェクト(TrevorのPhDアドバイザーはDatabricks CTOのMatei Zahariaです)、PyTorchチームとFSDPプロジェクト、NVIDIAとTensorRT-LLMプロジェクト、vLLMチームとプロジェクト、EleutherAIと彼らのLLM評価プロジェクト、Lilac AIのDaniel SmilkovとNikhil Thorat、そしてAllen Institute for Artificial Intelligence(AI2)の友人たちの仕事と協力に感謝します。
Databricksについて
DatabricksはデータとAIの会社です。 Comcast、Condé Nast、Grammarly、そしてFortune 500の50%以上を含む世界中の10,000以上の組織が、データ、分析、AIを統合し、民主化するためにDatabricksデータインテリジェンスプラットフォームを利用しています。 Databricksはサンフランシスコに本社を置き、世界中にオフィスを構えています。Lakehouse、Apache Spark™ 、Delta Lake、MLflowのオリジナルクリエイターによって設立されました。 詳細については、LinkedIn、X、FacebookでDatabricksをフォローしてください。
1 xAIが報告した数字。 リリース時にHugging Faceと互換性のあるチェックポイントがなかったため、私たちはGrok-1をベンチマークで評価することができませんでした。
2 DBRXはEleutherAIハーネスを使用して測定しました。 その他の数字は、Hugging Face Open LLM Leaderboadで報告されたものです。
3 DBRXはHugging Face Open LLM Leaderboardで使用されているものと同じ古いコミットでEleutherAIハーネスを使用して測定されました。 その他の数字は、Hugging Face Open LLM Leaderboardで報告されたものです。 なお、EleutherAIハーネスの最新コミットを使用すると、表2で報告されているように、GSM8kでのDBRXの5ショットスコアは72.8%に上昇します。LLaMA2-70B Chatも48.4%に上昇しています。
4 LLM Foundryの Gauntlet v0.3.0を 使用してDatabricksで測定しました。
5 特に断りのない限り、Databricks社による測定値です。
6 この数字はMixtral Arxivの論文より。 この数値は、私たち自身がモデルを評価した際に測定した数値(36.7%)よりも高いため、報告します。
7 スコアはすべてGPT-4論文に記載されているもの。 このバージョンのGPT-3.5は利用できないため、Inflection Corrected MTBenchを収集できませんでした。 GPT-3.5 Turboの現行バージョンは、Inflection Corrected MTBenchで8.58±0.04を記録したのに対し、DBRX Instructは8.39±0.08でした。
8 スコアはすべてGPT-4論文に記載されているもの。 このバージョンのGPT-4は利用できないため、Inflection Corrected MTBenchは収集できませんでした。 現行バージョンのGPT-4 Turboは、Inflection Corrected MTBenchで9.27±0.10を記録したのに対し、DBRX Instructでは8.39±0.08でした。