データインテリジェンスとAIトレンド:トップ製品、RAGなどの最新情報
データと AI 戦略のためのプレイブック

Translation Review by saki.kitaoka
生成AI(GenAI)の熱気は冷める兆しを見せていません。強力なGenAI戦略を実行するためのプレッシャーと興奮が高まる中、データリーダーや実務者は、最適なプラットフォーム、ツール、ユースケースを探しています。
現実の世界ではどのように進行しているのでしょうか?私たちは、業界全�体でAIへの取り組みを理解するために、10,000人のグローバル顧客からのデータを活用して「2024 State of Data + AI」を発表しました。このレポートでは、データ駆動型企業に関連する幅広いテーマをカバーしていますが、GenAIの旅における明確なトレンドが浮かび上がってきました。
今回の調査で明らかになった主なポイント:
トップ10のデータおよびAI製品:GenAIスタックの形成
新しい技術が登場すると、開発者はどのツールが最適かを見極めるために多くの異なるツールを試します。
私たちのトップ10データおよびAI製品は、 Data Intelligence Platformで最も広く採用されている統合ツールを紹介しています。データ統合からモデル開発まで、このリストは、企業が新しいGenAIの優先事項をサポートするためにどのようにスタックに投資しているかを示しています。
Hugging Faceのトランスフォーマーモデルが第2位に急上昇
わずか12か月で、Hugging Faceは4位から2位にランクアップしました。多くの企業が、このオープンソースプラットフォームのトランスフォーマーモデルを企業データと組み合わせて使用し、基礎モデルを構築およびファインチューニングしています。
LangChainが統合から数か月でトッププロダクトに
LangChainは、独自のLLMを操作および構築するためのオープンソースツールチェーンで、統合から1年未満で4位に上昇しました。企業が最新のLLMアプリケーションを構�築し、トランスフォーマー関連の専門的なPythonライブラリを使用してモデルをトレーニングする際に、LangChainはプロンプトインターフェースや他のシステムとの統合を開発するための支援を行います。
Enterprise GenAIはLLMのカスタマイズが重要
昨年、私たちのデータは、最も人気のあるLLM Pythonライブラリを分析した際、SaaS LLMが2023年の「注目のツール」として示されました。今年のデータは、汎用LLMの使用が続いているものの、前年比の成長が鈍化していることを示しています。
今年の戦略は大きく変わりました。データによると、企業はスタンドアロンの市販LLMを使用するだけでなく、カスタムデータでLLMを強化することに強く焦点を当てています。
企業はSaaS LLMの力を活用したいと考えていますが、同時に精度を向上させ、基礎モデルを自社のニーズに合わせてカスタマイズしたいと考えています。RAGを使用することで、企業は従業員ハンドブックや自社の財務諸表のようなものを利用して、モデルが特定のビジネスに対応した出力を生成できるようにすることができます。そして、これらのカスタマイズされたシステムを構築する需要は非常に高まっています。RAGモデルの重要なコンポーネントであるベクターデータベースの使用は、昨年から377%増加し、Databricks Vector Searchがパブリックプレビューに移行した後は186%増加しました。
エンタープライズAI戦略とオープンLLM
企業が技術スタックを構築する中で、オープンソースがその存在感を示しています。実際、トップ10製品のうち9つはオープンソースであり、私たちの2つの主要なGenAIプレーヤーであるHugging FaceとLangChainも含まれています。
オープンソースLLMは、企業の独自のニーズやユースケースに合わせてカスタマイズできるなど、多くの利点を提供します。私たちは、企業がどのモデルに引き寄せられているのかを理解するために、Meta LlamaとMistralという2つの主要プレーヤーのオープンソースモデルの使用状況を分析しました。
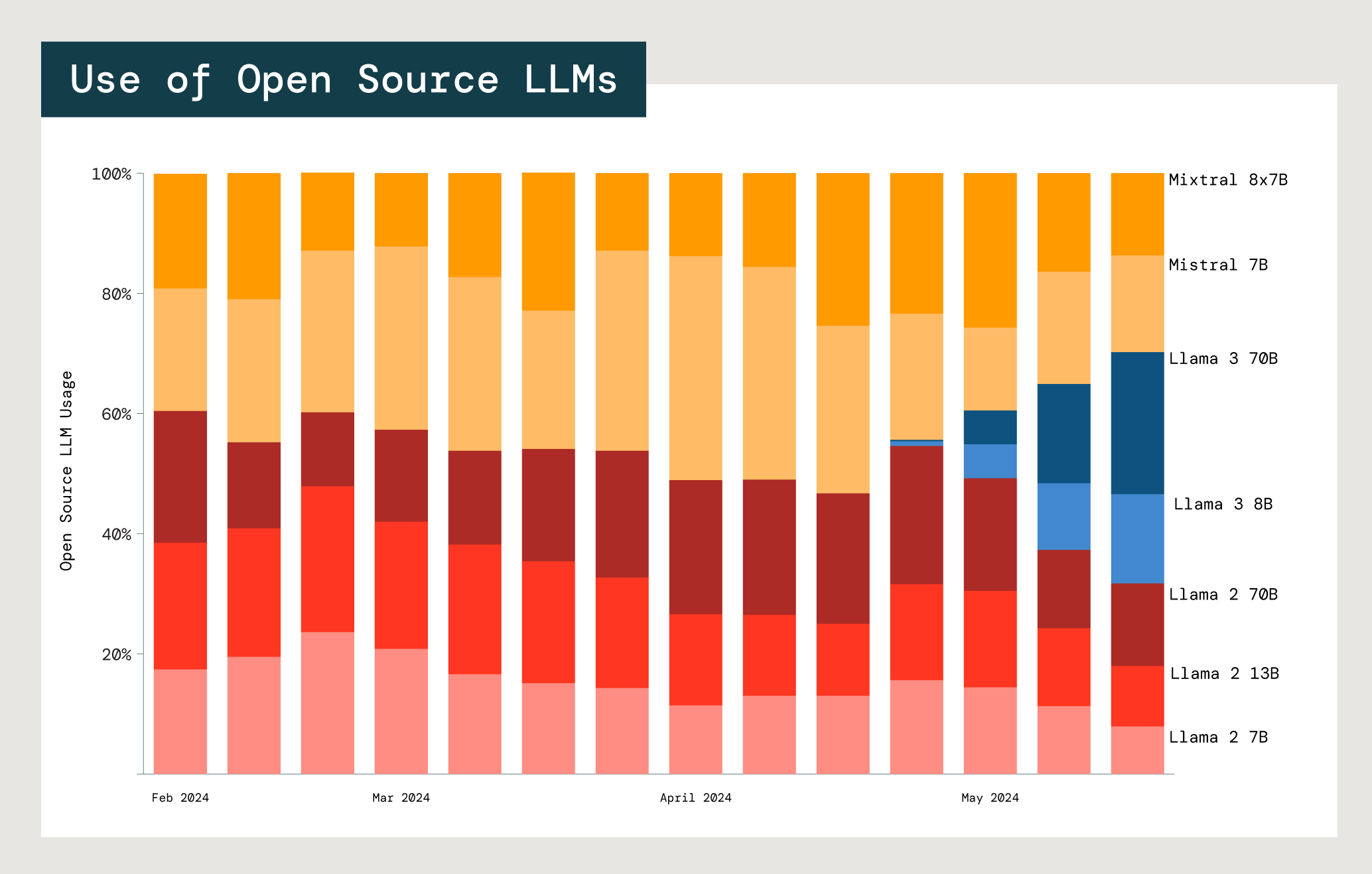
各モデルには、コスト、遅延、パフォーマンスのトレードオフがあります。Meta Llama 2モデル(7Bおよび13B)のうち2つの小さいモデルの使用率は、最大のMeta Llama 2 70Bよりもはるかに高くなっています。
LlamaとMistralのユーザー全体で、77%が13B以下のパラメータを持つモデルを選択しています。これは、企業がコストと遅延を重視していることを示唆しています。
2024年のデータ+AIの現状に関するこれらおよびその他のトレンドをさらに詳しく調べてください。効果的なデータおよびAI戦略のプレイブックとしてお使いください。レポート全文はこちらからダウンロードできます。

