Databricksがエージェント評価の組み込みLLM判断に大幅な改善を発表
公開日: 2024年9月5日
によって Max Marion、アルナヴ・シンヴィ、Samraj Moorjani、アヴェシュ・シン、マイケル・カービン 、 Alkis Polyzotis による投稿
エージェント評価における改良された回答正確性判断機能
エージェント評価は、Databricksの顧客がGenAIアプリケーションの品質を定義し、測定し、改善する方法を理解するのを可能にします。顧客データを扱う業界特有の文脈でのGenAIアプリケーションのML出力の品質を測定することは、新たな複雑さの次元を持っています:入力は複雑なオープンエンドの質問を含むことがあり、出力は文字列マッチングメトリクスを使用して参照回答と簡単に比較できない長い形式の回答になることがあります。
エージェント評価は、2つの補完的なメカニズムでこの問題を解決します。最初の一つは、組み込みのレビューUIで、人間の専門家がアプリケーションの異なるバージョンとチャットして生成されたレスポンスにフィードバックを提供することができます。二つ目は、組み込みのLLMジャッジのスイートで、自動的なフィードバックを提供し、評価プロセスを大量のテストケースにスケールアップすることができます。組み込みのLLMジャッジは、生成された回答が参照回答に対して意味的に正しいか、生成された回答がRAGエージェントの取得したコンテキストに基づいているか、またはコンテキストが正しい回答を生成するのに十分であるかどうか、などを理解することができます。私たちの使命の一部は、これらのジャッジの効果を継続的に改善し、エージェント評価の顧客がより高度なユースケースを処理し、アプリケーションの品質を向上させるための生産性を向上させることです。
このミッションに沿って、エージェント評価の改善された回答の正確さを判断する機能のローンチを発表することを嬉しく思います。回答の正確さは、入力され��た質問への生成された回答が参照回答とどのように比較するかを評価し、エージェントアプリケーションの品質を測定するための重要な基準を提供します。改善されたジャッジは特に顧客代表のユースケースにおいて、いくつかの基準に比べて大幅な改善を提供します。
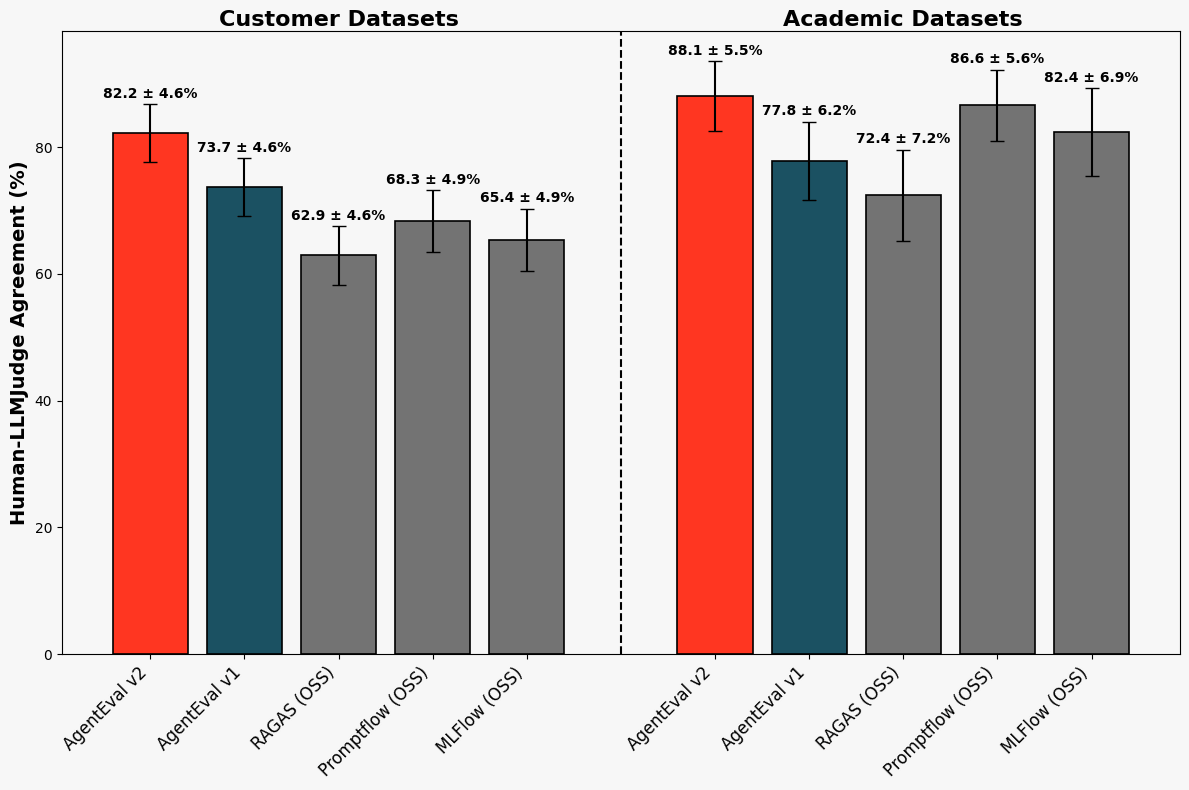
図1. 新しい回答の正確さ:ジャッジと人間の評価者との一致:各バーは、ベンチマークデータセットで測定された回答の正確さについて、ジャッジと人間のラベラーとの間の一致の割合を示しています。AgentEval v2は、顧客データセットで大幅な改善を達成してローンチした新しいジャッジを表しています。

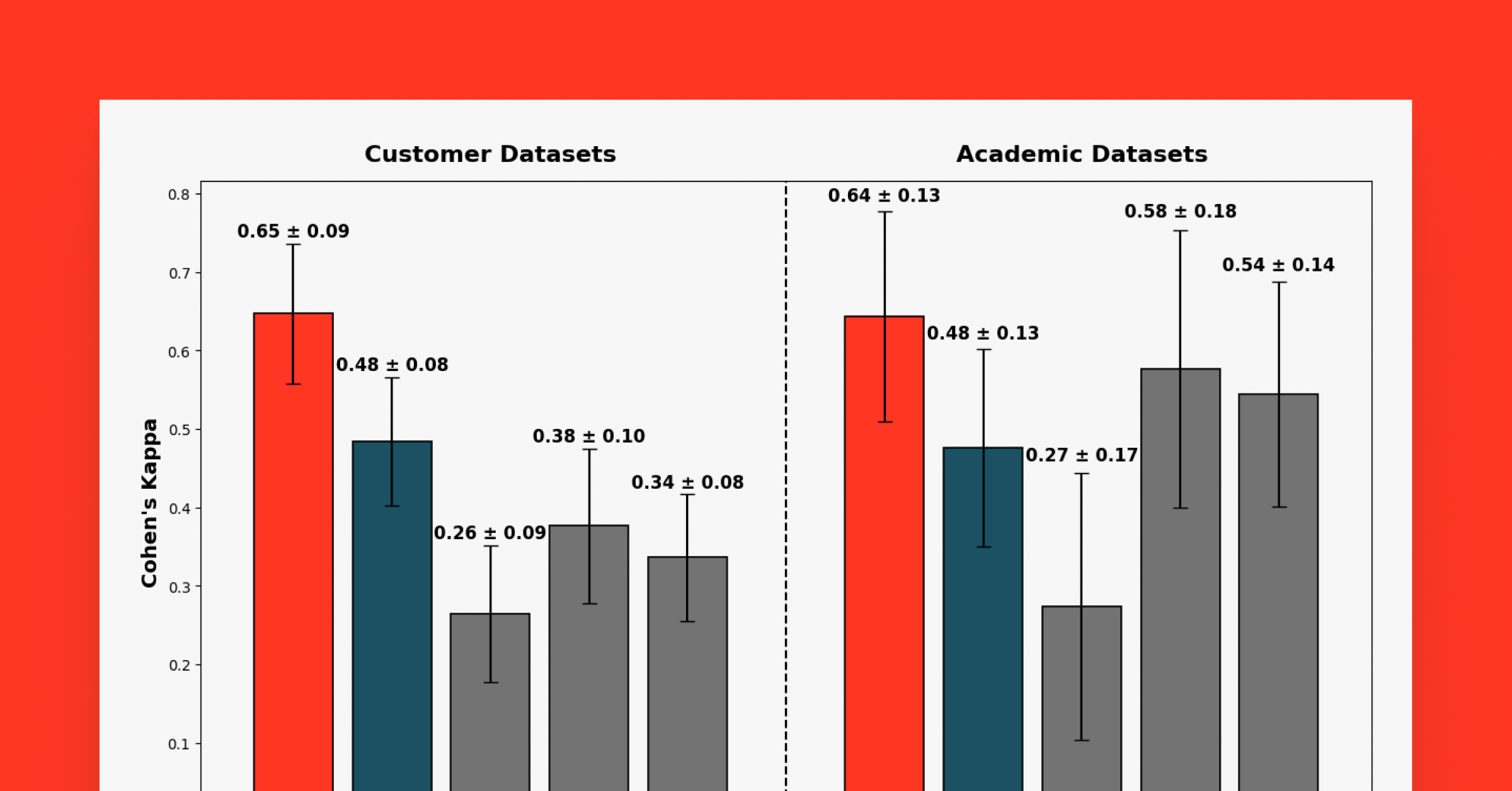
図2. 回答の正確さを判断するジャッジと人間の評価者との間の注釈者間信頼性(コーエンのカッパ): 各バーは、ジャッジと人間のラベラーとの間の回答の正確さについてのコーエンのカッパの値を示しており、これは私たちのベンチマークデータセットで測定されました。値が1に近いほど、ジャッジと人間の評価者との間の一致が偶然によるものではないことを示します。 AgentEval v2は、私たちが新たに導入したジャッ�ジを表しています。
Mosaic AIの研究チームとエンジニアリングチームの積極的な協力の結果として改善されたジャッジは、エージェント評価のすべての顧客に自動的に利用可能です。新しいジャッジの品質改善と、一般的なLLMジャッジの効果評価方法について学びましょう。また、私たちのデモノートブックでエージェント評価をテストドライブすることもできます。
どのように?事実だけ、事実だけ
回答の正確さを判断するジャッジは、3つのフィールドを入力として受け取ります:質問、この質問に対するアプリケーションによって生成された回答、そして参照回答。ジャッジは、生成された回答が参照回答と比較して十分であるかどうかを示す二値結果("Yes"/"No")を出力し、その推論を説明する根拠を提供します。これにより、開発者はエージェントの品質(評価セット全体での"Yes"の判断の割合として)を測定するとともに、個々の判断の背後にある推論を理解することができます。
顧客代表のユースケースと私たちのベースラインシステムの研究に基づいて、多くの既存のLLMジャッジの効果の主な制限は、"類似性"という柔らかい概念を使用する評価基準に依存しており、その解釈に大幅な曖昧さを許していることがわかりました。具体的には、これらのジャッジは短い回答を持つ典型的な学術データセットに対しては効果的かもしれませんが、回答がしばしば長くてオープンエンドの顧客代表のユースケースでは問題を提起することがあります。対照的に、私たちの新しいLLMジャッジは、生成された応答の事実と主張のより狭く定義されたレベルで推論します。
顧客-代表者の使用事例. コミュニティ内のLLMジャッジの評価は、よくテストされた学術的な質問応答データセット、例えば NQ と HotPotQAに基づいています。これらのデータセットの顕著な特徴は、以下のような短く、事実に基づいた抽出的な回答を持つ質問があることです:

例1:学術ベンチマークからの質問と参照回答:質問は通常具体的で、単一の短い事実に基づいた回答があります。
これらのデータセットはよく作られ、よく研究されていますが、多くのものは最近のLLMの革新以前に開発され、顧客のユースケース、つまり、複数部分の回答や異なる複数の受け入れ可能な回答があるオープンエンドの質問を代表するものではありません。例をいくつかご紹介します。

例2: 顧客-代表者の使用事例からの質問と参照/生成された回答: 質問はオープンエンドであり、回答はいくつかの部分から成ることがあります。また、複数の受け入れ可能な回答があるかもしれません。
ルーブリックの曖昧さ. LLMの判断は通常、ルーブリックに基づいたアプローチを採用しますが、広範に適用可能なルーブリックを設計することは課題です。特に、このような汎用的なルーブリックはしばしば曖昧な表現を導入し、その解釈を曖昧にします。例えば、以下のルーブリックはPromptFlowとMLFlowのLLM判断を駆動します:

OSS PromptFlowの回答正確性のためのプロンプト

OSS MLFlowの回答正確性プロンプト
これらのルーブリックは、1) 類似性が何を意味するのか、2) 類似性の測定を基礎とする応答の主要な特徴、および3) スコアの範囲に対する類似性の強度を調整する方法について曖昧です。学術データセットの抽出的な回答を超えて大幅に展開された回答については、私たちは(他の人々と共に[1])��、この曖昧さが、人間とLLMがスコアで応答をラベル付けするときに多くの不確定な解釈を引き起こすことがあることを見つけました。
事実についての推論. 私たちのエージェント評価のアプローチは、テキストの一部に含まれる原始的な事実と主張について推論することで長い形式の回答の正確さを評価するためのプロトコルに関する研究コミュニティの結果からインスピレーションを得ています [2, 1, 3] そして、言語モデルの能力を活用してこれを行う [4, 5, 6]. 例えば、上記の例2の参照回答では、4つの暗黙の主張があります:
- DatabricksのMLflowをモデルトラッキングに活用することは効果的な戦略です。
- スケーラビリティのためのマネージドクラスタの使用は効果的な戦略です。
- データパイプラインの最適化は効果的な戦略です。
- Delta Lakeとの統合によるデータバージョニングは効果的な戦略です。
エージェント評価のLLM判断アプローチは、生成された回答が参照回答からの事実と主張を含んでいることを��確認することで、生成された回答の正確さを評価します。検査により、例2の生成された回答は、すべての前述の暗示された主張を含んでいるため、正しい回答です。
全体として、事実の含有を評価することは、生成された回答と参照回答が「類似している」かどうかを判断することよりもはるかに狭く、特定のタスクです。顧客代表的なユースケースでのこれらの代替アプローチに対する私たちの改善は、私たちのアプローチの利点を示しています。
MLOps のビッグブック

評価方法論
私たちは、新しい回答の正確さを判断するために、HotPotQAやNatural Questionsを含む学術データセットのコレクションで評価を行います。また、新しいLLM判断の実用的な利点を強調するために、金融、文書化、HRなどの業界で特定のユースケースをモデル化するお客様から寄贈されたデータセットの内部ベンチマークも使用します。(お気軽にお問い合わせください [email protected]あなたがDatabricksの顧客で、私たちがあなたのユースケースのためにエージェント評価を改善するのを助けたい場合。)
学術データセットと産業データセットのそれぞれにおける(質問、生成された回答、参照回答)の三つ組みについて、我々は複数の人間のラベラーに生成された回答の正確さを評価してもらい、多数決により集約されたラベルを得ています。ただし、多数決が得られない例は除外します。集約されたラベルの品質を評価するために、我々は評価者間の一致度とラベル分布の偏り(偏った分布は偶然による一致をもたらす可能性があります)を調査します。前者はKrippendorfのアルファを通じて量化します。その結果得られた値(学術データセットでは0.698、産業データセットでは0.565)は、評価者間で良好な一致があることを示しています。また、偏りも十分に低い(学術データセットでは72.7%が「はい」/ 23.6%が「いいえ」、産業データセットでは52.4%が「はい」/ 46.6%が「いいえ」)ため、この一致が偶然に起こる可能性は低いと言えます。
私たちは、人間のラベラーに対するLLMジャッジのパフォーマンスを、パーセンテージの一致率とCohenのカッパの2つの主要な指標で測定します。パーセンテージの一致率は、LLMジャッジと人間のラベラーとの間の一致の頻度を測定し、直感的な精度の指標を提供します。Cohenのカッパは、-1から1の範�囲で、LLMジャッジと人間の評価者との間の偶然の一致を捉えます。Cohenのカッパの値が1に近いほど、一致は偶然ではなく、したがってLLMジャッジの非ランダムな精度の強固な信号であることを示します。私たちは、両方の指標について信頼区間を計算します。これは、基礎となるLLMの非決定性を考慮して各ベンチマークを3回実行し、95%の信頼レベルでブートストラップ区間を構築することにより行います。
パフォーマンス結果
上記の図1と2は、私たちの評価の結果を示しています。学術データセットでは、新しいジャッジは88.1 ± 5.5%の一致率とCohenのカッパスコア0.64 ± 0.13を報告し、人間のラベラーとの強い一致を示しました。私たちのLLMジャッジは、業界データセットでも強いパフォーマンスを維持し、82.2 ± 4.6%の一致率とCohenのカッパスコア0.65 ± 0.09を達成し、ランダムでない一致を強調しました。
さらに、私たちは新しいジャッジを既存のAnswerCorrectnessジャッジのベースラインと比較し、私たちの内部ジャッジの前のバージョン(私たちはこれをエージェント評価v1と呼んでいます)から始めました。また、以下のオープンソースのベースラインとも比較しました:RAGAS(セマンティック類似性スコアリング)、OSS PromptFlow(5つ星評価システム)、OSS MLFlow(5点スコアリングシステム)。私たちのジャッジは、学術データセットと顧客��データセットの両方で、ラベラーとLLMジャッジの一致とコーエンのカッパを一貫して最高に達成しました。顧客データセットでは、私たちのジャッジは既存のエージェント評価ジャッジを改善し、次に近いオープンソースのベースラインを一致で13-14%、コーエンのカッパで0.27上回り、学術データセットでは一致で1-2%、コーエンのカッパで0.06のリードを維持しました。
特筆すべきは、これらの基準判断の一部は、ジャッジが実際のデータラベル付きの判断の例を提示されるフューショット設定を使用し、一方、私たちのジャッジはゼロショット設定で評価されました。これは、私たちのジャッジがさらにフューショット学習で最適化され、さらに高いパフォーマンスを達成する可能性を示しています。エージェント評価はすでにこの機能をサポートしており、私たちは積極的に次のバージョンの製品でフューショットの例の選択を改善するために作業しています。
次のステップ
先に述べたように、改善されたジャッジは、エージェント評価のすべての顧客に自動的に有効化されます。私たちはDSPyを使用してジャッジの設計の空間を探索し、その作業を受けて、このジャッジのさらなる改善に積極的に取り組んでいます。
