データエンジニアのための Databricks Assistant のヒントとコツ
Community Editionに代わり、Free Editionでは無料でより充実した機能をご利用いただけます。ぜひ今日からぜひFree Editionをお試しください。
生成AI革命はチームの働き方を変えつつあり、Databricks Assistantはこれらの進歩を最大限に活用しています。会話型インターフェイスを介してデータをクエリできるため、 Databricksワークスペース内での生産性が向上します。アシスタントはDatabricks用のデータインテリジェンスエンジンであるDatabricksIQを搭載しており 、データのセキュリティを確保し、応答が正確で、企業の詳細に合わせて調整されていることを確認します。Databricks Assistantを使用すると、タスクを自然言語で記述して、開発者のエクスペリエンスを中断することなく、複雑なコードを生成、最適化、またはデバッグできます。
この投稿では、ブログ「Databricks Assistantを最大限に活用するための5つのヒント」を拡張し��、アシスタントが退屈な作業の排除、生産性と没入感の向上、価値実現までの時間の短縮によってデータエンジニアの生活をどのように改善できるかに焦点を当てます。さまざまなデータ実践者のペルソナに焦点を当てた一連の投稿をフォローアップしますので、データサイエンティスト、 SQLアナリストなどに焦点を当てた今後のエントリにご期待ください。
取り込み
データエンジニアとしてDatabricksを使用する場合、多くの場合、 Delta Lakeテーブルへのデータの取り込みが最初のステップになります。アシスタントがデータの読み込みにどのように役立つか、 APIからとクラウド ストレージ内のファイルからの 2 つの例を見てみましょう。それぞれについて、プロンプトと結果を共有します。5つのヒントのブログで述べたように、プロンプトを具体的にすると最良の結果が得られます。これは、この記事で一貫して使用されている手法です。
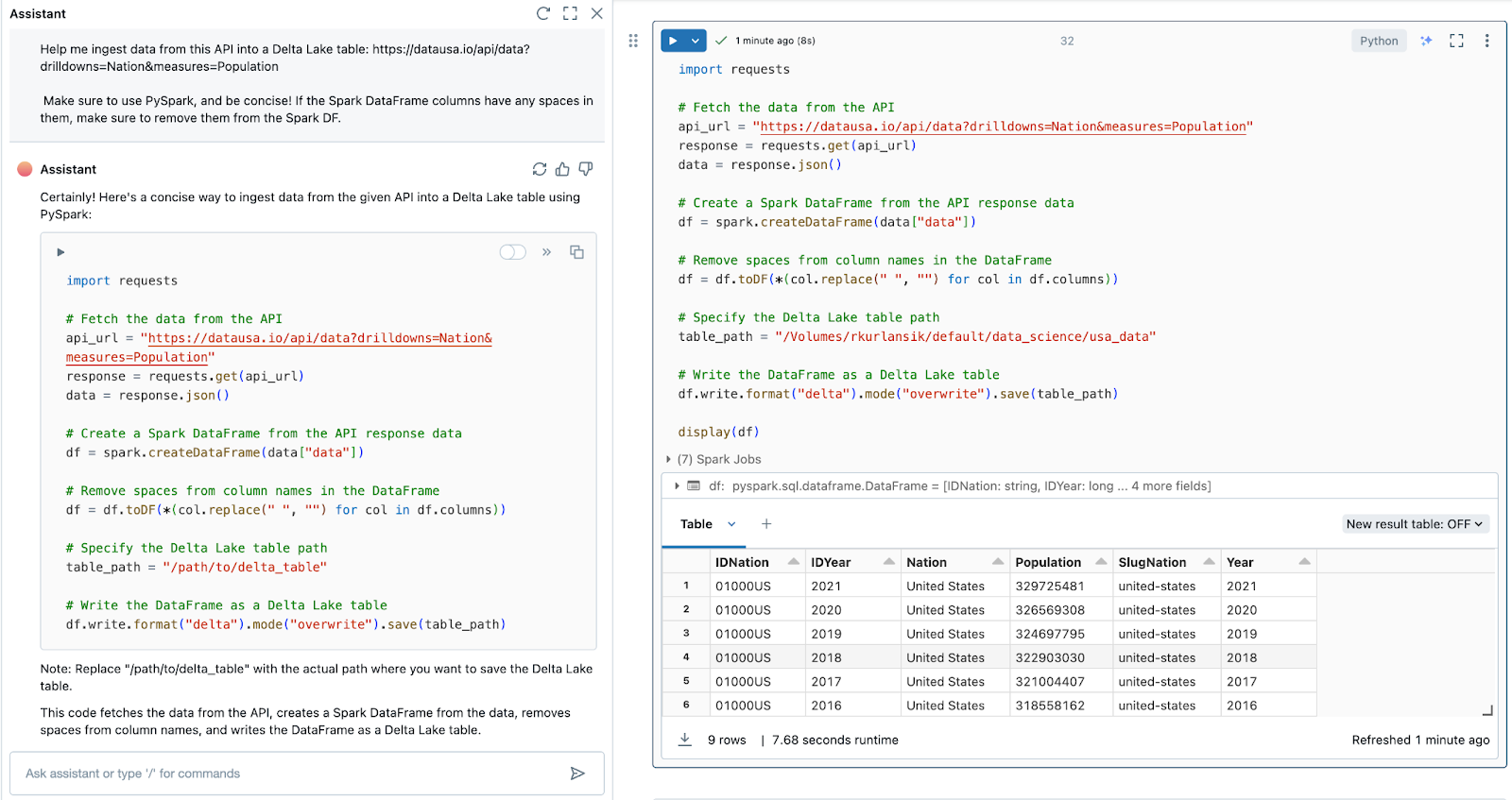
datausa.io APIからデータを取得し、Pythonを使用してDelta Lakeテーブルにロードするには、次のプロンプトを使用しました。
このAPIからDelta Lakeテーブルにデータを取り込むのを手伝ってください:
必ずPySparkを使用し、簡潔に記述してください。 Spark DataFrame列にスペースが含まれている場合は、Spark DFから必ず削除してください。
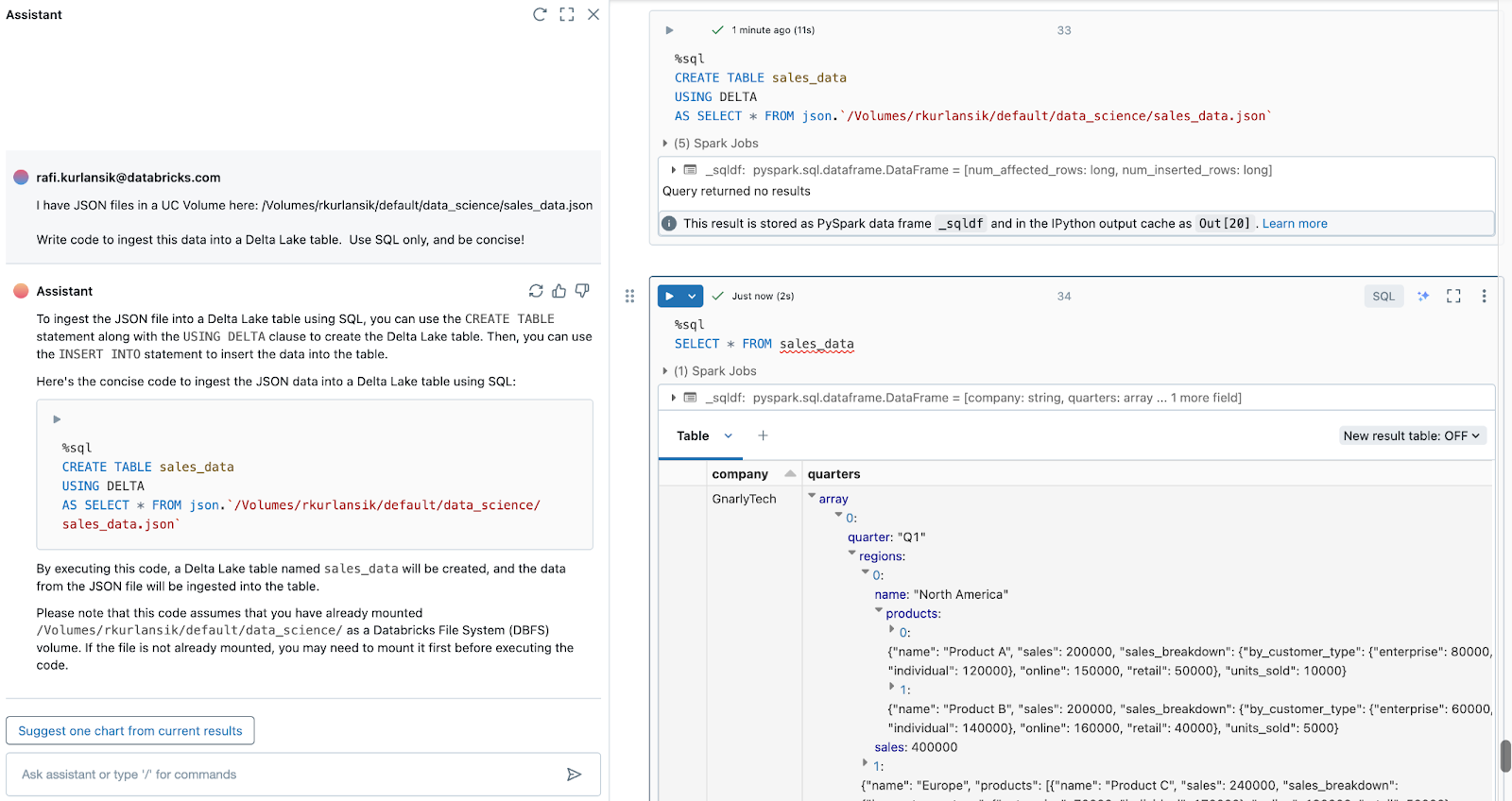
同様のプロンプトを使用して、クラウド ストレージからDelta LakeテーブルにJSONファイルを取り込むことができます。今回はSQLを使用します。
UCボリュームに次のJSONファイルがあります: /Volumes/rkurlansik/default/data_science/sales_data.json
このデータをDelta Lakeテーブルに取り込むコードを記述します。SQLのみを使用し、簡潔に記述してください。
非構造化データから構造化データへの変換
整然としたデータの原則に従うと 、表の任意のセルに適切なデータ型の単一の観測値が含まれている必要があります。複雑な文字列やネストされたデータ構造は、この原則に反することが多く、その結果、データエンジニアリング作業は非構造化データから構造化データを抽出することになります。アシスタントがこのタスクで優れている2つの例、正規表現の使用とネストされたデータ構造の展開について見てみましょう。
正規表現
正規表現は乱雑な文字列から構造化されたデータを抽出する手段ですが、正しい正規表現を見つけるのは時間がかかり、面倒です。 この点で、アシスタントは正規表現に苦労しているすべてのデータエンジニアにとって恩恵となります。
IMDbのTitle列を使用した次の例を考えてみましょう :

この列には、映画のタイトルと公開年の 2 つの異なる観察結果が含まれています。 次のプロンプトを使用して、アシスタントは文字列を複数の列に解析するための適切な正規表現を識別します。
以下はデータセットのタイトル列の例です: 1. ショーシャンクの空に(1994)。 タイトル名は数字と括弧で囲まれ、発売日は括弧で囲まれます。 imdb_raw DataFrameのTitle列からリリース日とタイトル名の両方を抽出する関数を記述します。
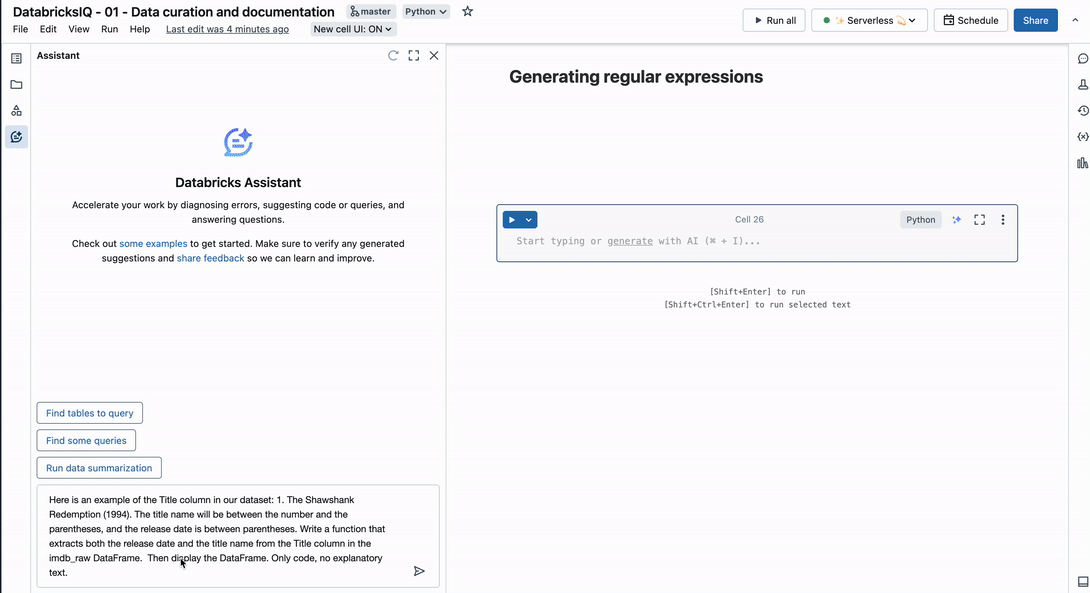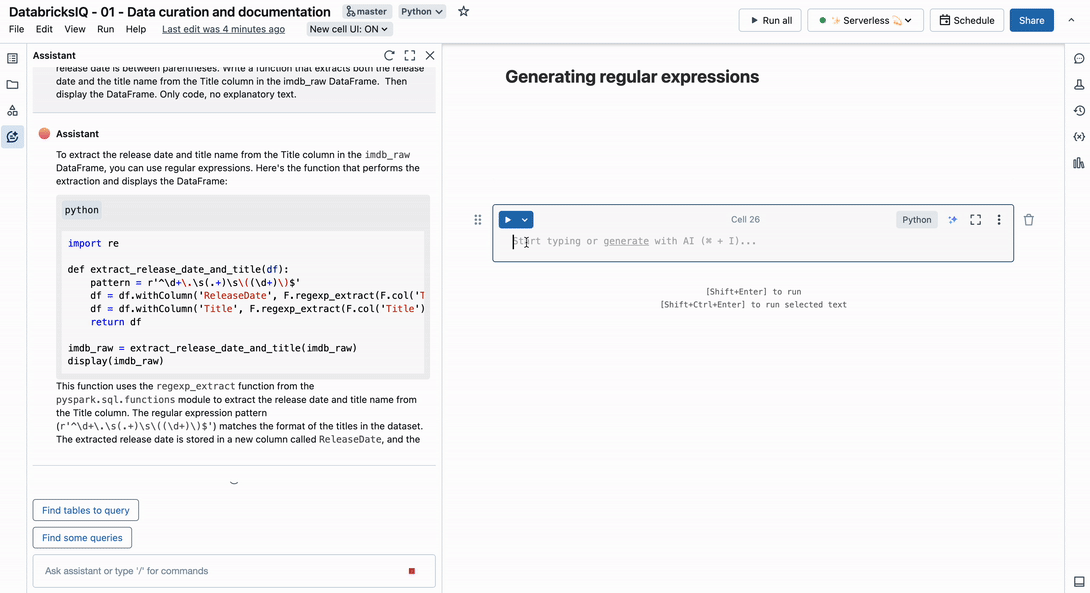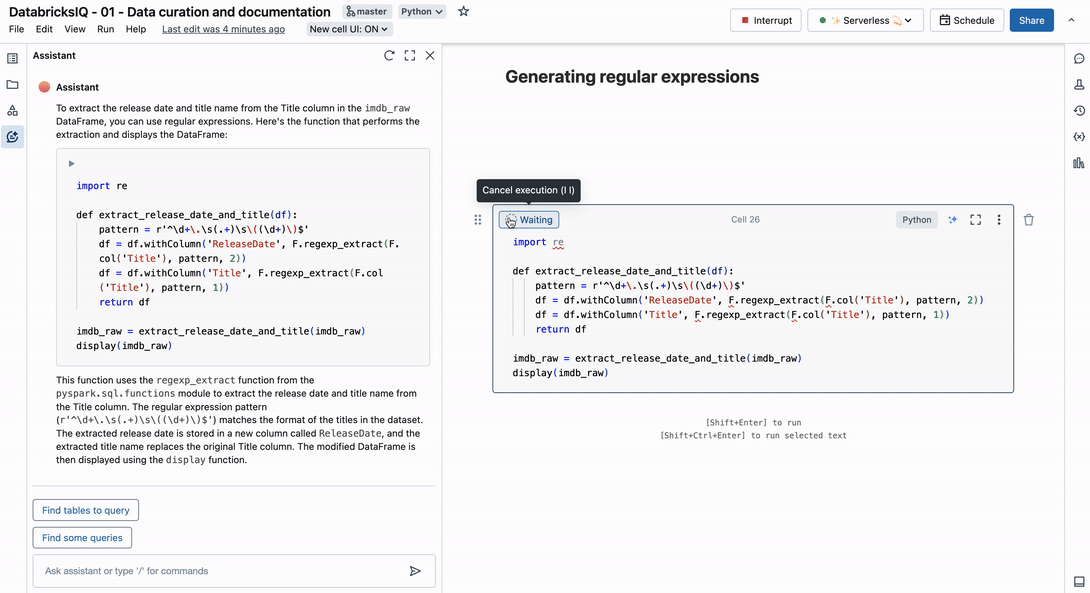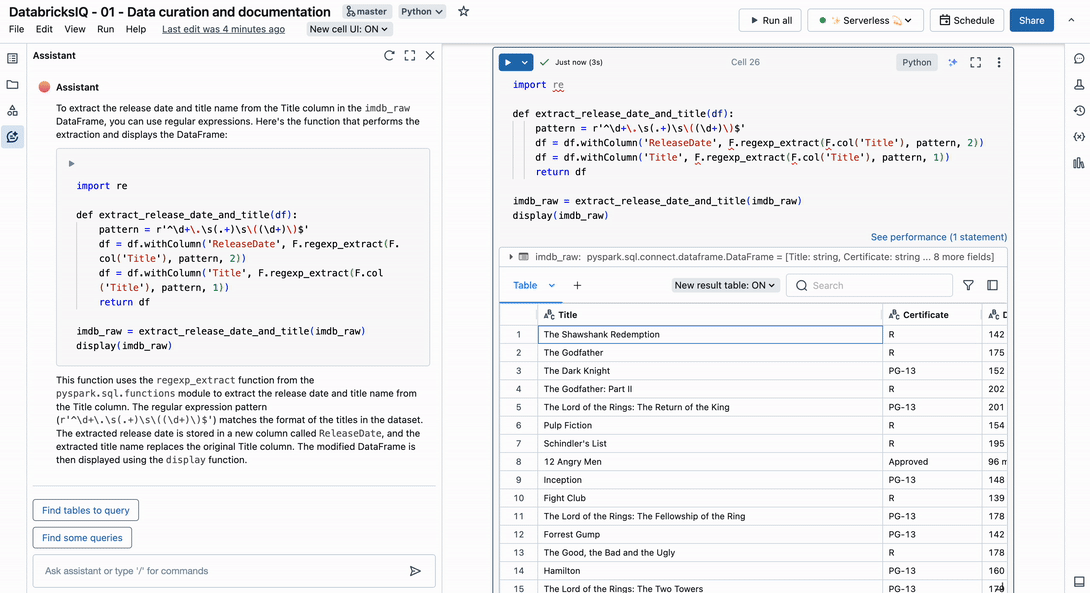
プロンプトに文字列の例を提供すると、アシスタントが正しい結果を見つけるのに役立ちます。機密データを扱っている場合は、同じパターンに従う偽の例を作成することをお勧めします。いずれにしても、これでデータエンジニアリング 作業で心配する問題が1つ減りました。
ネストされた構造体、配列 (JSON、XMLなど)
API、ストレージ内のJSONファイル、またはnoSQLデータベースを介し��てデータを取り込む場合、結果のSpark DataFramesが深くネストされ、正しくフラット化するのが難しくなる可能性があります。 JSON 形式のこの模擬販売データを見てみましょう。
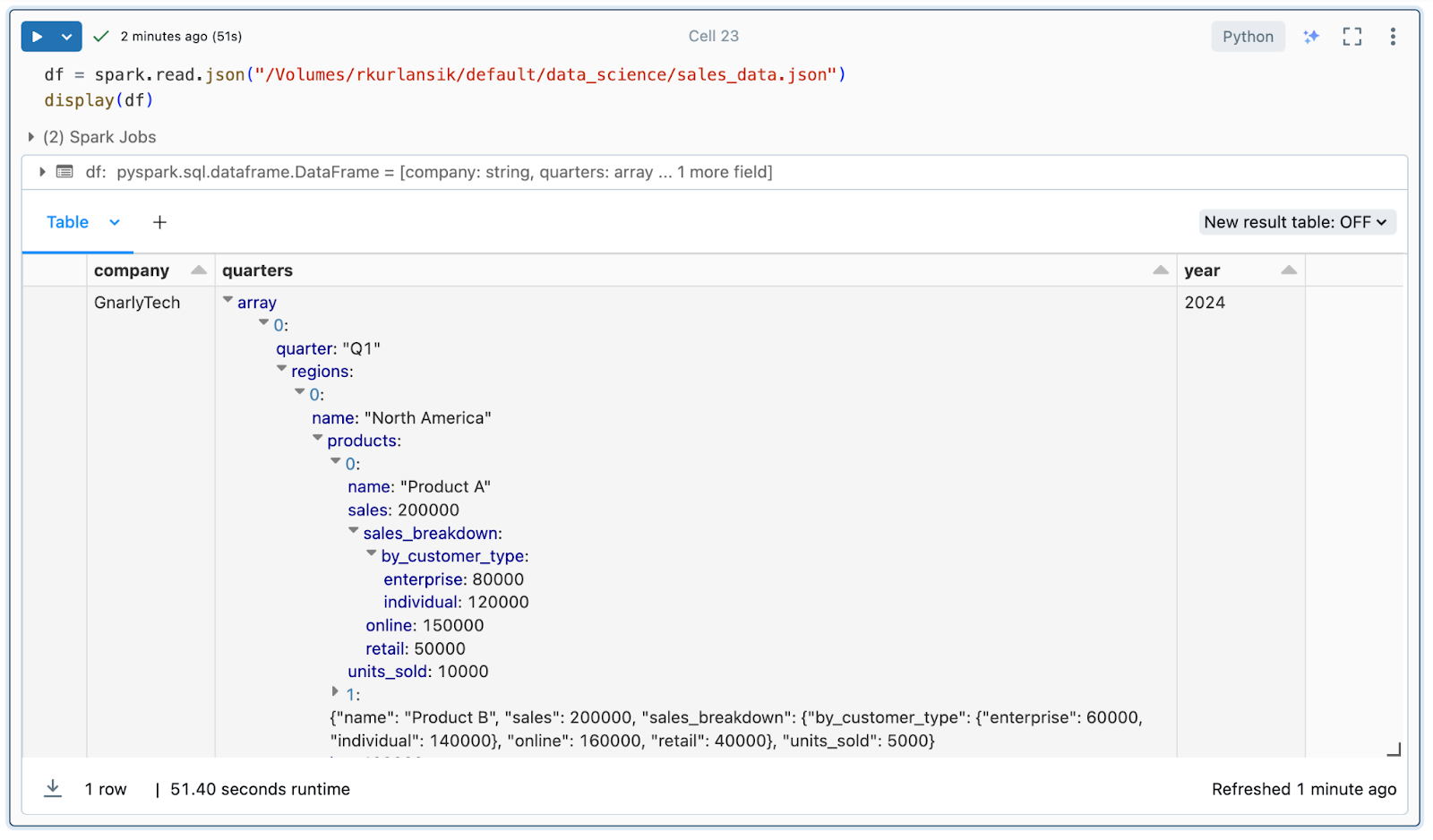
データエンジニアは、ネストされた配列をフラット化し、各製品の収益メトリックを抽出するように求められる場合があります。 通常、このタスクには、データが比較的単純な場合でも、かなりの試行錯誤が必要になります。 ただし、アシスタントは、メモリ内にあるDataFramesのスキーマのコンテキストを認識して、ジョブを完了するためのコードを生成します。 簡単なプロンプトを使用して、探している結果を数秒で取得します。
PySparkコードを記述してdfをフラット化し、各製品と顧客の収益を抽出します。

リファクタリング、デバッグ、最適化
データエンジニアが直面するもう1つのシナリオは、他のチーム メンバー (より経験が浅いメンバーや退職したメンバー) が作成したコードを書き直すことです。このような場合、アシスタントはコンテキストと意図を理解して、適切に記述されていないコードを分析して説明することができます。アシスタントは、より効率的なアルゴリズムを提案したり、読みやすくするためにコードを��リファクタリングしたり、コメントを追加したりすることができます。
文書化と保守性の向上
このPythonコードは、オンライン ショッピング カート内のアイテムの合計コストを計算します。
このコードで条件ブロックを使用すると、読みにくくなり、大規模に非効率的になります。 さらに、何が起こっているのかを説明するコメントはありません。 まず、アシスタントにコードをステップごとに説明してもらうのが良いでしょう。 データエンジニアがコードを理解すると、アシスタントは次のプロンプトを使用してコードを変換し、パフォーマンスと可読性を向上させることができます。
このコードを、よりパフォーマンスが高く、適切にコメントされ、Python関数のドキュメント標準に従ってドキュメント化された方法で書き直します。
以下の生成された例では、コードが適切に文書化されており、 条件ブロックの代わりにジェネレータ式を使用して、大規模なデータセットでのメモリ使用率が向上しています。
エラーの診断
必然的に、データエンジニアはデバッグを行う必要があります。 アシスタントを使用すると、コード内のエラーの原因を特定するために複数のブラウザタブを開いたりコンテキストを切り替えたりする必要がなくなり、集中力を維持できるため生産性が大幅に向上します。アシスタントでこれがどのように機能するかを理解するために��、簡単なPySpark DataFrameを作成し、エラーをトリガーしてみましょう。
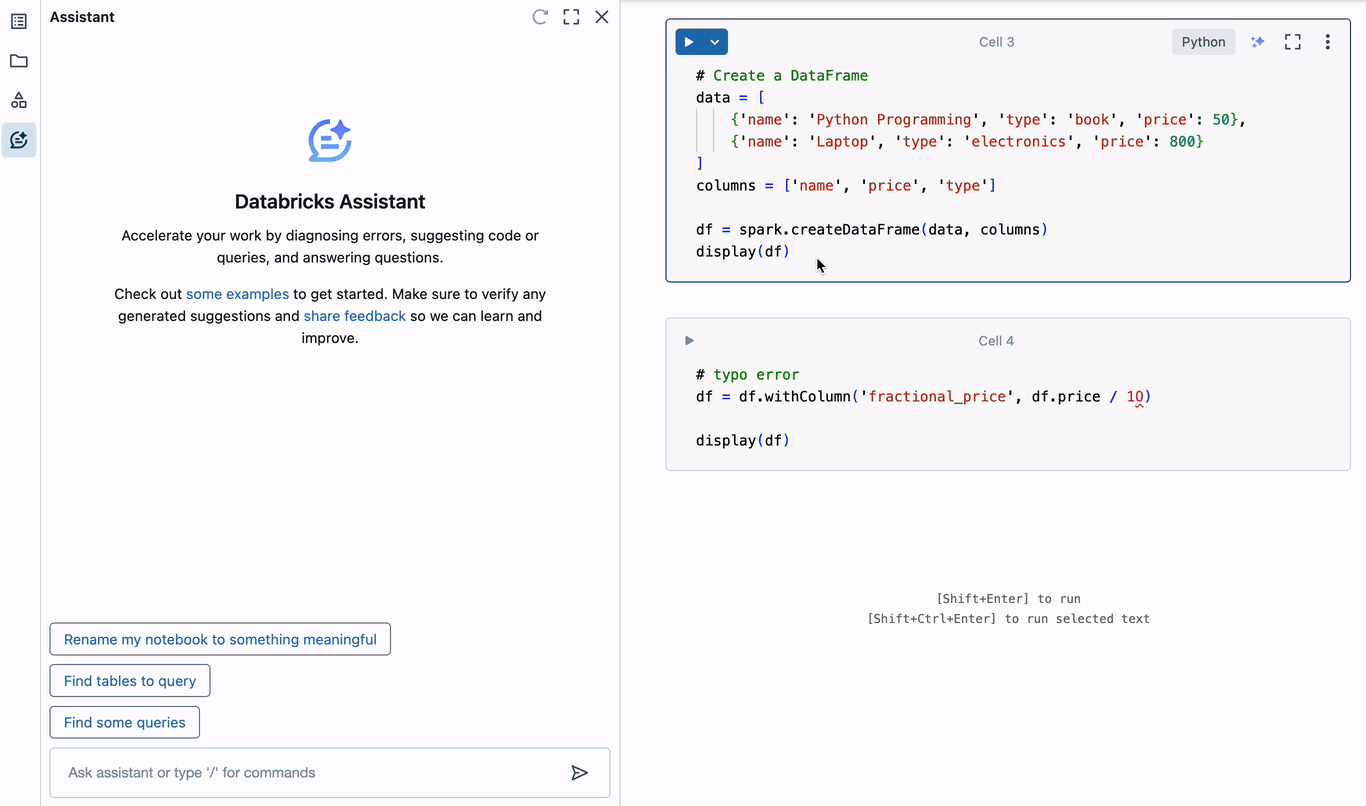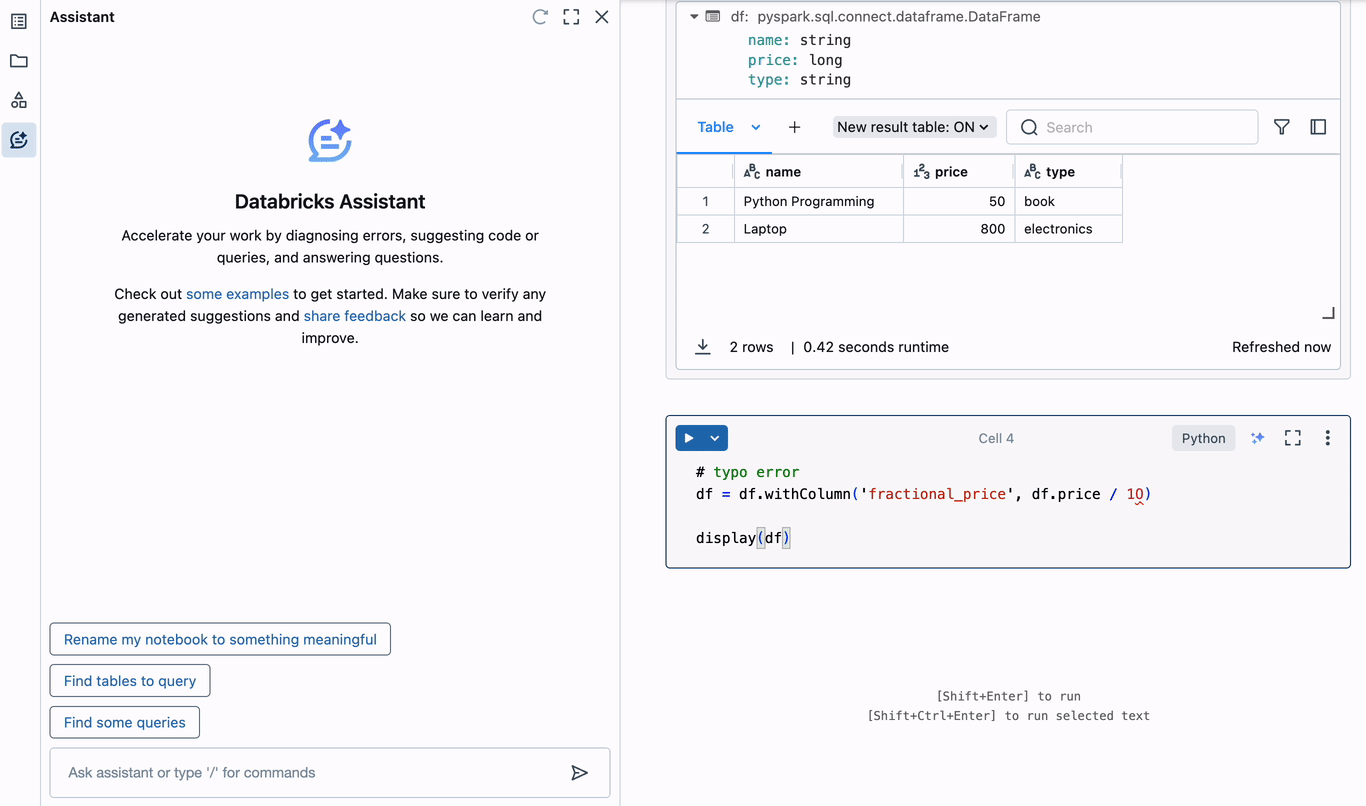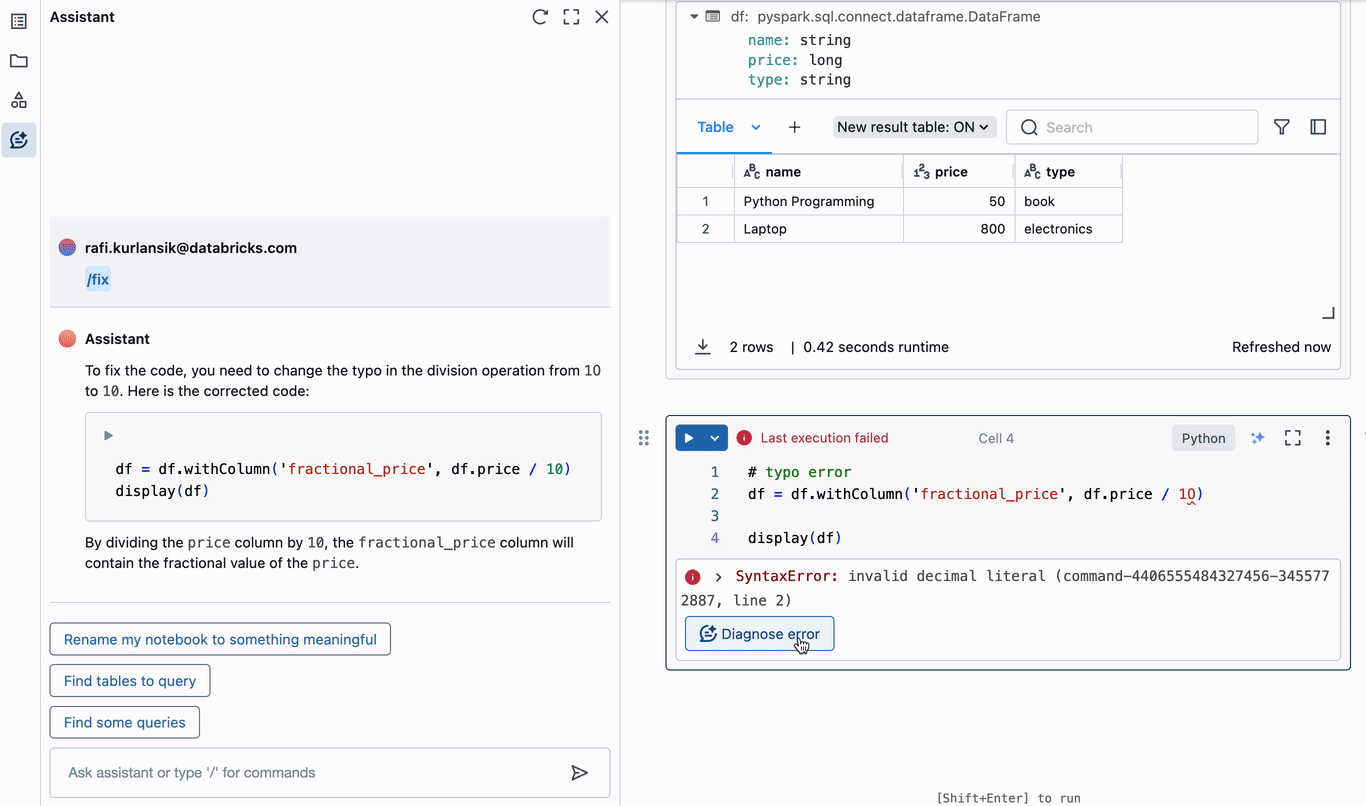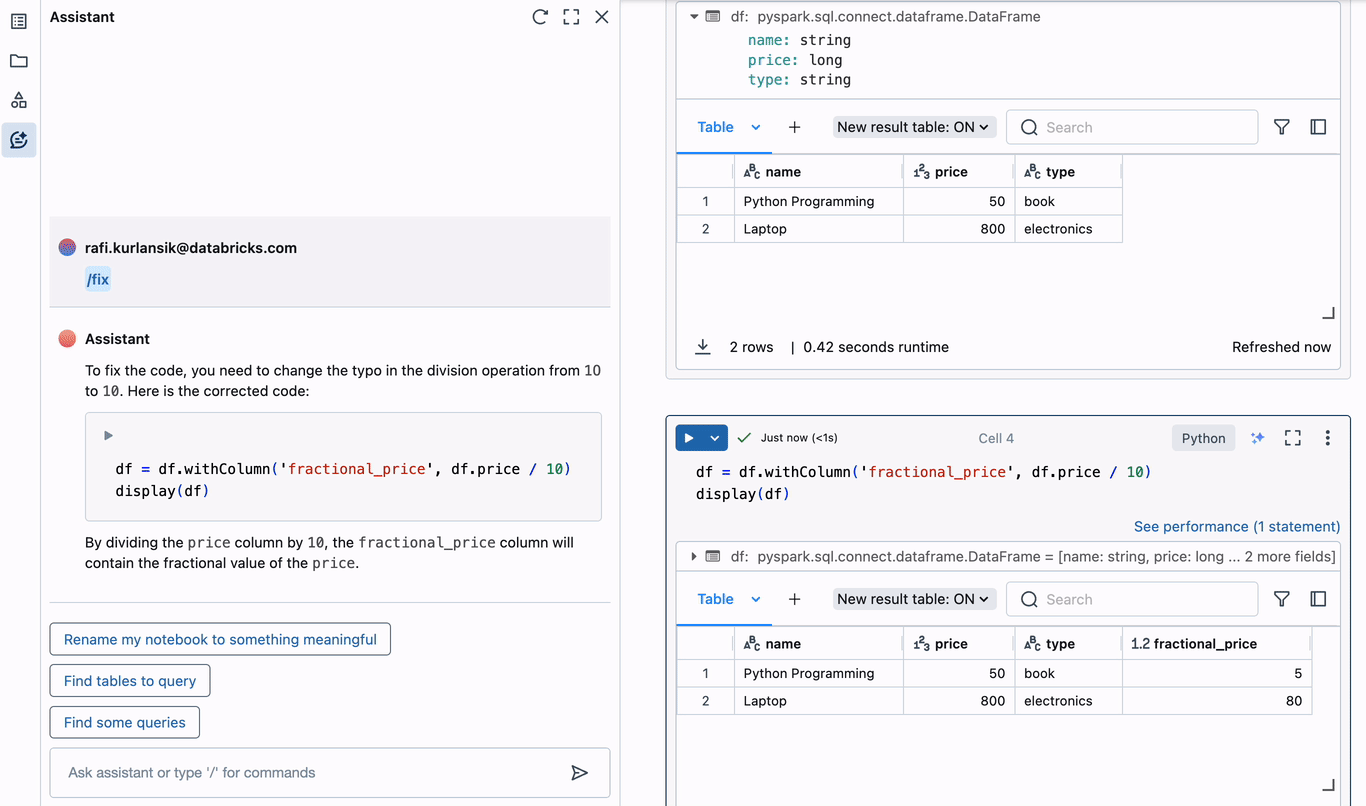
上記の例では、DataFrameに新しい列を追加するときにタイプミスが発生しています。「10」のゼロは実際には文字「O」であり、無効な小数リテラル構文エラーにつながります。アシスタントはすぐにエラーの診断を提案します。タイプミスを正しく識別し、現在のセルのエディターに挿入できる修正コードを提案します。このようにエラーを診断して修正することで、デバッグに費やす時間を何時間も節約できます。
PandasをPySparkにトランスパイルする
Pandasは、Pythonで最も成功したデータ ラングリング ライブラリの1つであり、世界中のデータサイエンティストによって使用されています。 JSON販売データにこだわり、初心者のデータサイエンティストがPandasを使用してデータをフラット化するために最善を尽くした状況を想像してみましょう。 見栄えが悪く、ベストプラクティスに従っていませんが、正しい出力が生成されます。
デフォルトでは、Pandasは単一のマシンでの実行に制限されています。 データエンジニアは、このコードをPySparkに変換するまで、本番運用に組み込んで数十億行のデータで実行すべきではありません。 この変換プロセスには、データエンジニアがコードを理解し、保守可能、テスト可能、か��つパフォーマンスの高い方法でコードを書き直すことが含まれます。 アシスタントは再び数秒でより良い解決策を提案します。
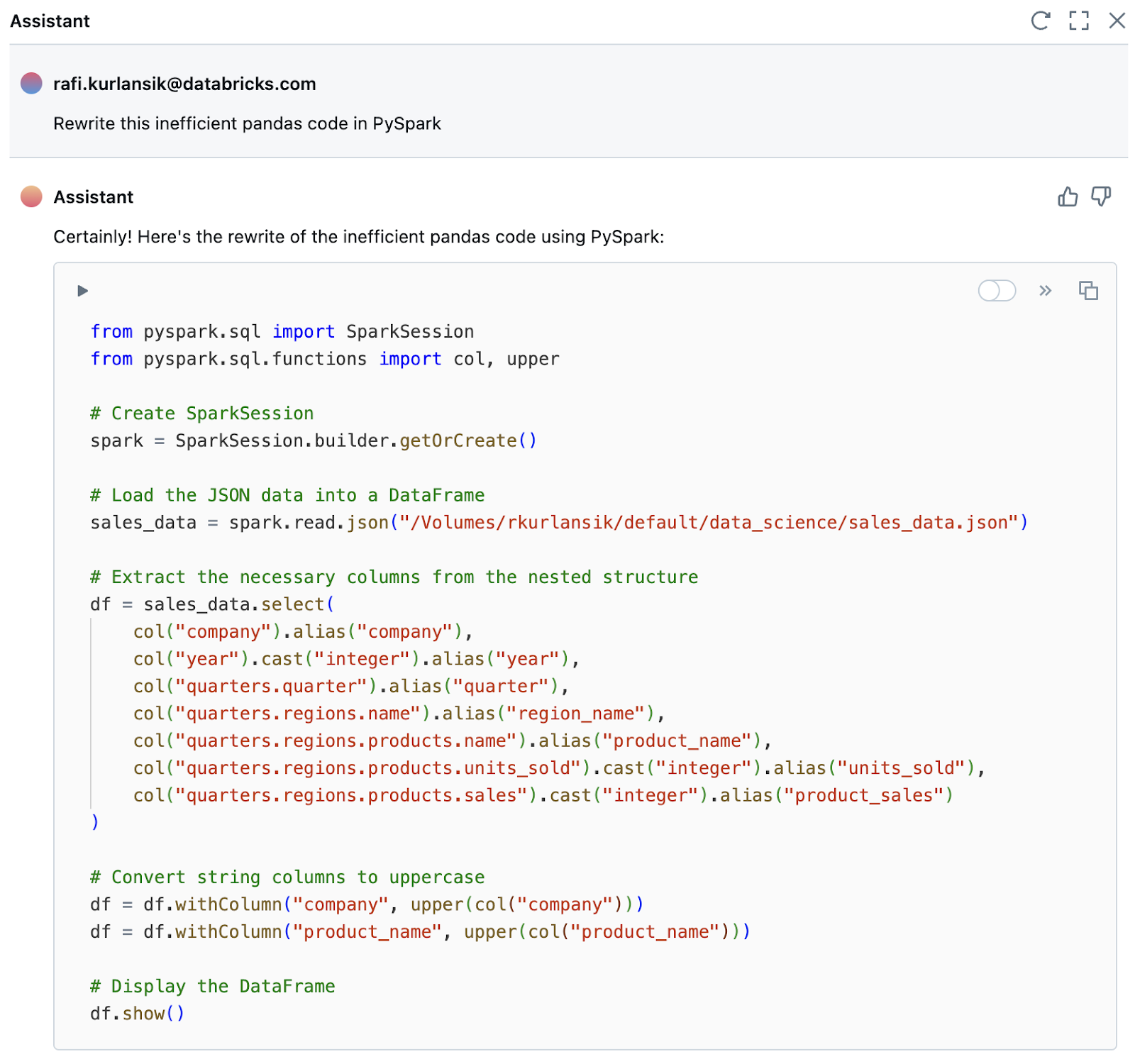
生成されたコードには、Databricksで必須ではないSparkSession作成が含まれていることに注意してください。他のLLMと同様に、アシスタントが間違ったり、幻覚を起こしたりすることがあります。データエンジニアであるあなたは、コードの最終的な作成者であり、次のタスクに進む前に、生成されたコードを確認して理解することが重要です。このような動作に気付いた場合は、それに応じてプロンプトを調整してください。
テストの記述
データエンジニアリングにおける最も重要なステップの 1 つは、 DataFrame変換ロジックが正しいことを確認するためのテストを作成し、パイプラインを通過する破損したデータを潜在的に検出することです。 JSON販売データの例を続けると、アシスタントを使用すると、いずれかの収益列が負であるかどうかを簡単にテストできます。収益列の値がゼロ未満でない限り、この場合のデータと変換が正しいと確信できます。
 次のプロンプトを使用して、アシスタントにテスト�をPySparkのネイティブ テスト機能に組み込むように依頼することで、このロジックを構築できます。
次のプロンプトを使用して、アシスタントにテスト�をPySparkのネイティブ テスト機能に組み込むように依頼することで、このロジックを構築できます。
PySpark .testing.utilsのassertDataFrameEqualを使用してテストを記述し、空のDataFrameの行数が負の収益DataFrameと同じであることを確認します。
アシスタントは、テスト作業をブートストラップするための実用的なコードを提供し、義務付けます。
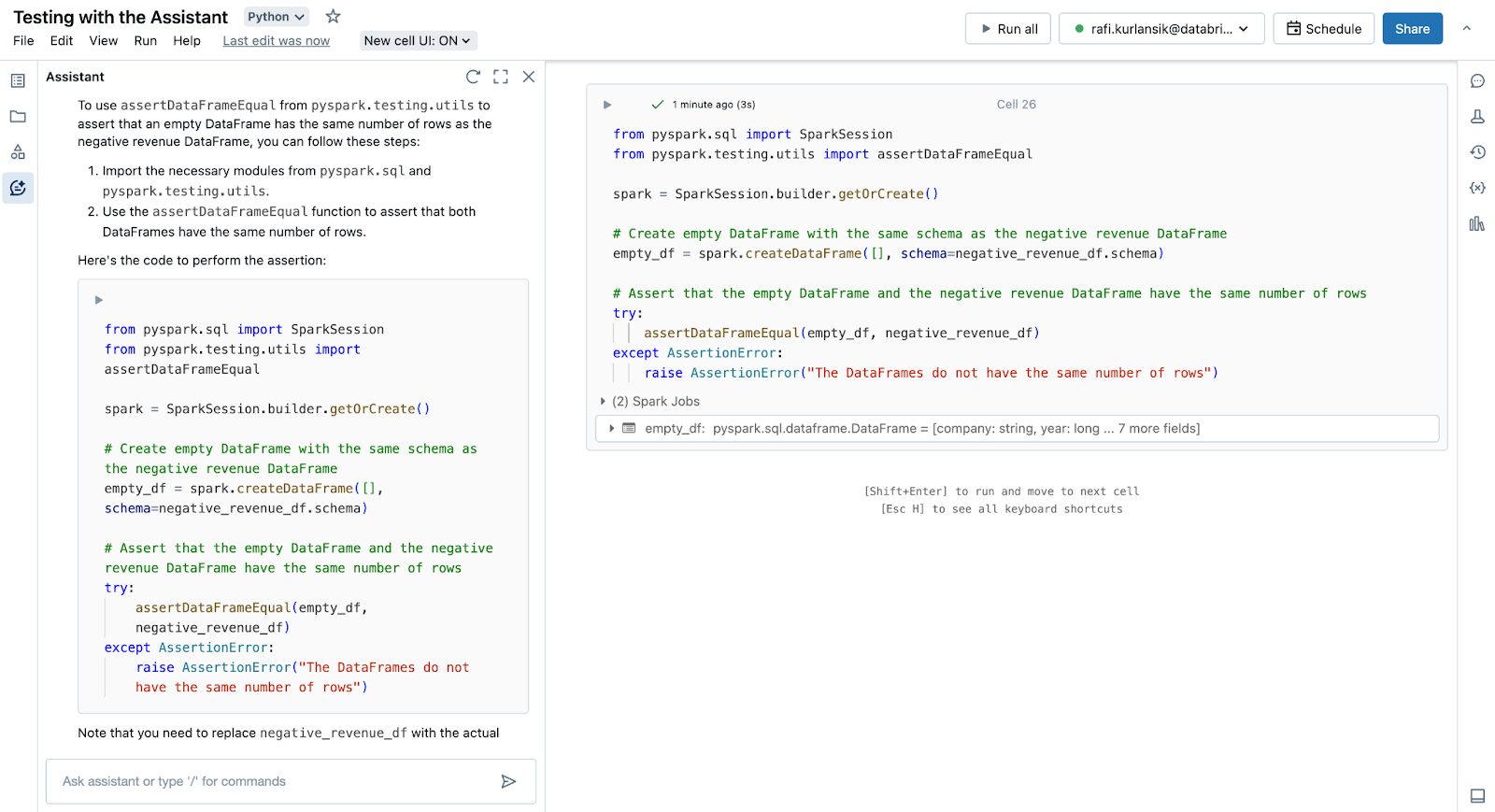
この例は、具体的にし、プロンプトに詳細を追加することで、より良い結果が得られるという事実を強調しています。 詳細を省いてアシスタントにテストを書いてもらうだけでは、結果の質にばらつきが生じます。 私たちが求めているものを具体的かつ明確にする (記述したロジックを基に構築されたPySparkモジュールを使用したテスト) と、アシスタントが私たちの意図を正しく推測できると想定するよりも、一般的にパフォーマンスが向上します。
ヘルプの入手
アシスタントは、コードを改善および理解するための一般的な機能に加えて、Databricksドキュメントとナレッジ ベース全体に関する知識も持っています。 この情報は定期的にインデックス化され、RAGアーキテクチャを介してアシスタントの追加コンテキストとして利用できるようになります。 これにより、ユーザーはDatabricksプラットフォームを離れることなく、製品の機能と構成を検索できます。
たとえば、使用しているDatabricks Runtimeのバージョンのシステム環境の詳細を知りたい場合、アシスタントはDatabricksドキュメント内の適切なページに誘導することができます。
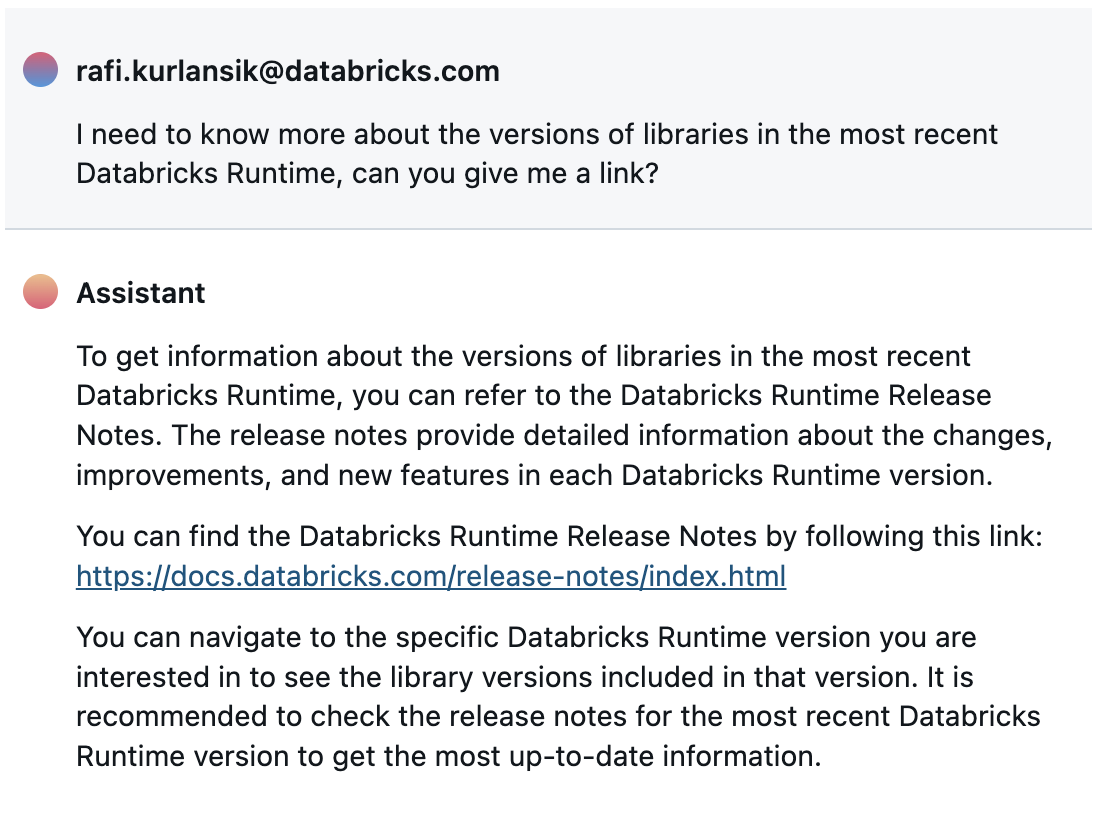
アシスタントは、シンプルで説明的な会話形式の質問に対応し、Databricksの機能の操作や問題の解決におけるユーザー エクスペリエンスを向上させます。サポート チケットの提出をユーザーに案内することもできます。詳細については、発表記事をご覧ください。
まとめ
Databricks Assistant による生成 AI の力により、質の高いデータエンジニアリングへの参入障壁が低くなりました。複雑なデータ構造の操作方法についてサポートを求めている初心者でも、正規表現を書いてもらいたい熟練者でも、アシスタントはあなたの生活の質を向上させます。コードの理解、生成、文書化というコア コンピテンシーにより、あらゆるスキル レベルのデータ エンジニアの生産性が向上します。詳細については、Databricks ドキュメントで今すぐDatabricks Assistant を使い始める方法をご覧ください。また、最近のブログ「Databricks Assistant を最大限に活用するための5�つのヒント」もご覧ください。また、このビデオでDatabricks Assistantの動作を確認することもできます。

