
大規模言語モデル(LLM)は、プロンプト技術を最適化することで効果的な人間とAIの対話に注目を集めています。「プロンプトエンジニアリング」は、大規模言語モデルの出力を最適化するための成長中の方法論であり、検索拡張生成(RAG)などの技術を通じて、関連情報を活用した大規模言語モデルの応答生成を強化します。
スタンフォードNLPグループが開発したDSPyは、「プロンプトではなくプログラミングで基盤モデルを構築する」ためのフレームワークとして登場しました。現在、DSPyはDatabricksの開発者エンドポイントとの統合をサポートしており、Model ServingやVector Searchが可能です。
複合AIのエンジニアリング
これらのプロンプト技術は、AI開発者がLLM、リトリーバルモデル(RM)、その他のコンポーネン�トを組み込んで複合AIシステムを開発する際に、大規模言語モデルを活用した複雑な「プロンプトパイプライン」へのシフトを示しています。
プロンプトではなくプログラミング: DSPy
DSPyは、下流タスクのメトリクスに向けて、LLMコールと他の計算ツールを組み合わせることで、AI駆動システムのパフォーマンスを最適化します。従来の「プロンプトエンジニアリング」とは異なり、DSPyはユーザーが定義した自然言語シグネチャを完全な指示と少数のショット例に変換することで、プロンプトのチューニングを自動化します。PyTorchのエンドツーエンドのパイプライン最適化を模倣し、DSPyはユーザーがレイヤーごとにAIシステムを定義および構成しながら、望ましい目標に向けて最適化することを可能にします。
DSPyのプログラムには2つの主要なメソッドがあります:
初期化 (Initialization)
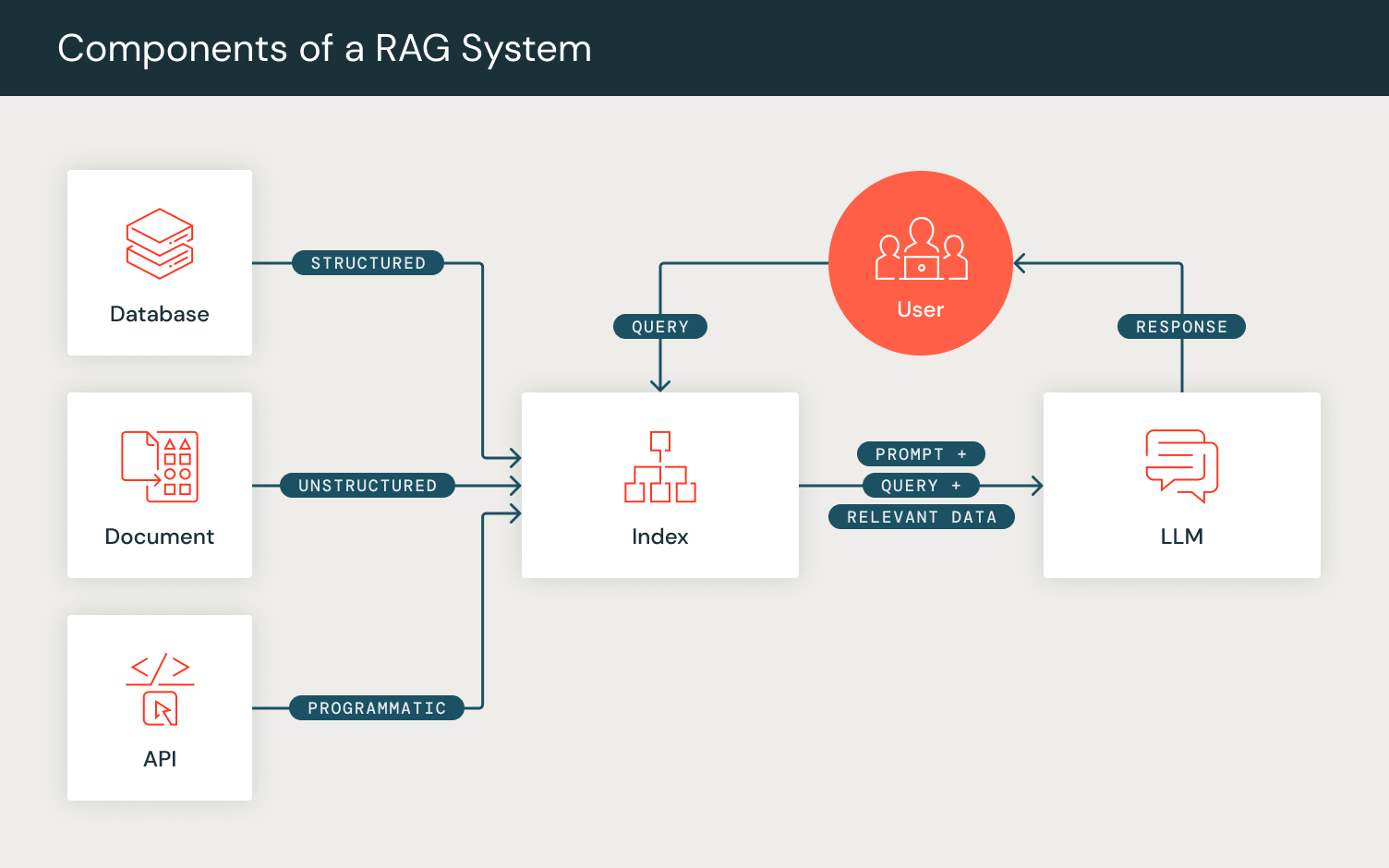
ユーザーは、プロンプトパイプラインのコンポーネントをDSPyレイヤーとして定義できます。例えば、RAG(Retrieval-Augmented Generation)の手順を考慮し、大規模言語モデルを活用するために、検索レイヤーと生成レイヤーを定義します。
- 検索レイヤー
dspy.Retrieveを定義し、ユーザーが設定したリトリーバルモデル(RM)を使�用して、入力された検索クエリに対して関連するパッセージやドキュメントを取得します。 - 次に、生成レイヤーを初期化します。このために
dspy.Predictモジュールを使用し、内部的に生成のためのプロンプトを準備します。この生成レイヤーを設定するために、RAGタスクを自然言語シグネチャ形式で定義し、一連の入力フィールド(「コンテキスト、クエリ」)と期待される出力フィールド(「回答」)を指定します。このモジュールは、定義された形式に一致するようにプロンプトを内部でフォーマットし、ユーザーが設定した言語モデル(LM)からの生成結果を返します。
フォワード (Forward)
PyTorchのフォワードパスに似て、DSPyプログラムのフォワード関数はユーザーがプロンプトパイプラインのロジックを構成することを可能にします。初期化したレイヤーを使用して、クエリに対して一連のパッセージを取得し、これらのパッセージをコンテキストとしてクエリと一緒に使用して回答を生成し、期待される出力をDSPyの辞書オブジェクトに出力します。
DSPyプログラムとDBRXの生成を使用したRAGの実例
この例では、正しい答えを導き出すために複数のステップが必要な質問を含むHotPotQAデータセットからサンプル質問を使用します。
まず、DSPyでLMとRMを設定しましょう。 DSPyには様々な言語と検索モデルの統合機能があり、ユーザーはこれらのパラメータを設定することで、DSPyで定義されたプログラムがこれらの設定を通して実行されるようにすることができます。
それでは、定義したDSPy RAGプログラムを宣言し、入力として質問を渡してみましょう。
検索ステップでは 、クエリーはself.retrieve レイヤーに渡され 、上位3つの関連する文章を出力します:
これらの検索された文章を、クエリと一緒にdspy.Predictモジュールの self.generate_answerに渡す ことで、自然言語シグネチャの入力フィールド "context, query "にマッチさせることができます。これは内部的にいくつかの基本的なフォーマットとフレーズを適用し、LMをプロンプトエンジニアリングすることなく、正確なタスク記述でモデルを指示することができます。
フォーマットが宣言されると、入力フィールド "context "と "query "が入力され、最終的なプロンプトがDBRXに送信されます:
DBRXはAnswer:フィールドに入力される�答えを生成し、呼び出しによってこのプロンプト生成を観察できます:
これは、LMから生成された最後のプロンプトを、生成された答え「Steve Yzerman」と共に出力します!
DSPyは 、ファインチューニング、 文脈内学習、 情報抽出、 自己洗練 など、さまざまな言語モデルのタスクで広く使用 されています。 この自動化されたアプローチは、、 マルチホップRAGのような自然言語タスクやGSM8Kのような数学ベンチマークにおいて、GPT-3.5では最大46%、Llama2-13b-chatでは65%も、人間が書いたデモンストレーションによる標準的な数発プロンプトを凌駕 します。
Databricks上のDSPy
DSPyは、Databricks の開発者エンドポイントとの統合をサポートするようになりました。 Model Serving および Vector Searchとの統合をサポートしました。 SDKの下で、dspy.を通して、Databricks-hostedOpenAIDatabricks基礎モデルAPIを構成することができます 。 これにより、Databricks-hostedモデル上でエンドツーエンドのDSPy パイプラインを評価できるようになります。現在、Model Serving エンドポイント上のモデルをサポートしています:チャット(DBRX Instruct、Mixtral-8x7B Instruct、Llama 2 70B Chat)、補完(MPT 7B Instruct)、埋め込み(BGE Large (En))モデル。
チャットモデル
補完モデル(Completion Models)
埋め込みモデル
レトリーバーモデル/ベクトル検索
さらに、ユーザは Databricks Vector Searchを使用してレトリーバ・モデルを構成 できます。Vector Search インデックスとエンドポイントを作成した後、dspy.DatabricksRM.RM を使用して対応する RM パラメータを指定することができます:
ユーザーは、LM と RM を対応する Databricks エンドポイントに設定し、DSPy プログラムを実行することで、この設定をグローバルに行うことができます。
この統合により、ユーザーはDatabricksのエンドポイントを使用して、RAGのようなエンドツーエンドのDSPyアプリケーションを構築および評価できます!
公式のDSPyGitHubリポジトリ、 ドキュメント 、 Discordをチェックして、生成AIタスクをDatabricksで多用途なDSPyパイプラインに変換する方法について詳しく学びましょう!