LoRAによる効率的なファインチューニンガイド

翻訳:Junichi Maruyama. - Original Blog Link
ニューラルネットワークベースの技術や大規模言語モデル(LLM)研究の急速な進歩に伴い、企業は価値生成のための大規模言語モデルを活用した AI アプリケーションにますます関心を寄せている。これらの企業は、分類、要約、シーケンス間タスク、制御されたテキスト生成など、テキスト関連の課題に対処するために、生成および非生成の両方で、さまざまな機械学習アプローチを採用している。組織はサードパーティのAPIを選択することもできるが、独自のデータでモデルを微調整することで、ドメイン固有の適切な結果を提供し、安全な方法でさまざまな環境に展開可能な、費用対効果の高い独立したソリューションを可能にする。
ファインチューニングの戦略を選択する際には、効率的なリソース利用と費用対効果を確保することが重要です。このブログでは、このようなパラメータ効率的な手法の中で、間違いなく最も一般的で効果的なバリエーションであるLoRA(Low Rank Adaptation)について、特にQLoRA(LoRAのさらに効率的なバリエーション)に重点を置いて説明します。ここでのアプローチは、オープンな大規模言語モデルを使用し、商品名とカテゴリを入力すると架空の商品説明が生成されるようにファインチューニングすることです。この演習のために選ばれたモデルはOpenLLaMA-3b-v2で、寛容なライセンス(Apache 2.0)を持つオープンな大規模言語モデルであり、選ばれたデータセットは Red Dot Design Award Product Descriptionsで、どちらもHuggingFace Hubから提供されたリンクからダウンロードできます。
Fine-Tuning, LoRA and QLoRA
言語モデルの分野では、特定のデータに対して特定のタスクを実行するために、既存の言語モデルをファインチューニングすることが一般的である。これには、必要に応じてタスクに特化したヘッドを追加し、学習プロセス中にバックプロパゲーションによってニューラルネットワークの重みを更新することが��含まれる。このファインチューニングプロセスとゼロからのトレーニングの区別に注意することが重要である。後者のシナリオでは、大規模言語モデルの重みはランダムに初期化されるが、ファインチューニングでは、重みは事前トレーニング段階ですでにある程度最適化されている。どの重みを最適化または更新し、どの重みを凍結しておくかの決定は、選択した手法に依存する。
完全なファインチューニングでは、ニューラルネットワークの全レイヤーを最適化またはトレーニングする。このアプローチは一般的に最良の結果をもたらすが、最もリソースを消費し、時間もかかる。
幸いなことに、効果的であることが証明されているファインチューニングのためのパラメータ効率の良いアプローチが存在する。このようなアプローチのほとんどは性能が低いのですが、Low Rank Adaptation(LoRA)はこの傾向に逆らい、場合によっては完全なファインチューニングを上回ることさえあります。
LoRA は改良されたファインチューニング手法であり、事前学習された大規模言語モデルの重み行列を構成するすべての重みをファインチューニングする代わりに、この大規模行列を近似する2つの小さな行列をファインチューニングする。これらの行列がLoRAアダプターを構成する。このファインチューニングされたアダプタが事前学習済みモデルにロードされ、推論に使用される。
QLoRA は、大規模言語モデルのファインチューニングにおいて、4 ビット量子化を用いることで、LoRA と同様のパフォーマンスを維持しつつ、GPU メモリの節約を実現します。この方法を調査し、必要に応じて2つの方法を比較し、最短の学習時間で最適なパフォーマンスを達成するためのQLoRAハイパーパラメータの最適な組み合わせを見つけ出すことが、ここでの焦点となります。
LoRAはHugging Face Parameter Efficient Fine-Tuning (PEFT)ライブラリに実装されており、使い勝手が良く、bitsandbytesとPEFTを併用することでQLoRAを活用できます。HuggingFace Transformer Reinforcement Learning (TRL)ライブラリは、LoRAのためにシームレスに統合された教師ありファインチューニングのための便利なトレーナーを提供します。これら3つのライブラリは、選択された事前学習済みモデルをファインチューニングするために必要なツールを提供し、必要な属性を示す指示があれば、首尾一貫した�説得力のある製品説明を生成します。
教師ありファインチューニングのためのデータ準備
QLoRA による指示追従モデルのファインチューニングの有効性を調べるには、データを教師ありファインチューニングに適した形式に変換することが不可欠である。教師ありファインチューニングとは、要するに、与えられたプロンプトを条件としてテキストを生成するように、事前に訓練されたモデルをさらに訓練することである。これは、一貫した方法でフォーマットされたプロンプトとレスポンスのペアを持つデータセット上でモデルをファインチューニングするという点で教師ありである。
Hugging Faceハブから選択したデータセットからの観察例は以下のようになる:
|
product |
category |
description |
text |
|
"Biamp Rack Products" |
"Digital Audio Processors" |
""高い認知価値、統一された美しさ、実用的な拡張性-これはBiampのブランド・ランゲージによって見事に達成されている..."" |
"" 製品名 Biamp Rack Products; Product Category: デジタル・オーディオ・プロセッサー; 製品概要: "高い認知価値、統一された美しさ、実用的な拡張性-これはBiampのブランド言語によって見事に達成されています。""
|
このデータセットは有用であるが、上記のような方法で命令フォローの言語モデルをファインチューニングするには、このデータセットはうまくフォーマットされていない。
以下のコードでは、Hugging Faceハブからデータセットをメモリにロードし、必要なフィールドを一貫した書式のプロンプトを表す文字列に変換し、その直後にレスポンス(つまり説明)を挿入している。このフォーマットは大規模言語モデル研究界では「Alpacaフォーマット」として知られている。MetaのオリジナルLlaMAモデルをファインチューニングするために使われたフォーマットであり、Alpacaモデルは(商用利用はライセンスされていないが)広く配布された最初の命令追従型大規模言語モデルの一つである。
得られたプロンプトは、教師ありのファインチューニングを行うために、Alpaca 形式のデータセットにロードされる。それぞれのプロンプトは以下のような形式を持つ。
迅速な実験を可能にするため、各微調整は、このデータの5000の観測サブセットに対して行われる。
ファインチューニングの前にモデルの性能をテストする
ファインチューニングを行う前に、それを行わずにモデルがどのように動作するかをチェックし、訓練済みモデルの性能の基準値を得ることをお勧めします。
モデルは以下のように8ビットでロードすることができます model card on Hugging Face.
この出力は、我々が望むものとはまったく違います
結果の最初の部分は実際に満足のいくものだが、残りの部分はもっととりとめのない混乱だ。
同様に、前述のように「Alpacaフォーマット」の入力テキストでモデルをプロンプトした場合、出力は同様に最適でないと予想される:
そして案の定、そうなった:
モデルは訓練されたことを実行し、次に最も可能性の高いトークンを予測する。この文脈での教師あり微調整のポイントは、制御可能な方法で望ましいテキストを生成することである。この後の実験では、QLoRAは重みが凍結された4ビットでロードされたモデルを活用するが、出力品質を調べる推論プロセスは、一貫性を保つために、上記のようにモデルが8ビットでロードされた時点で行われることに注意されたい。
回転するノブ
PEFTを使用してLoRAまたはQLoRAでモデルを学習する場合(前述のように、両者の主な違いは、後者では、ファインチューニングプロセスの間、事前に学習されたモデルは4ビットで凍結されることに注意)、低ランク適応プロセスのハイパーパラメータは、以下のようにLoRAコンフィグで定義することができます:
これらのハイパーパラメータのうち2つ、rとtarget_modulesは経験的に適応品質に大きく影響することが示されており、この後のテストの焦点となる。他のハイパーパラメータは、簡単�のため上記の値で一定に保たれている。
r は、大規模言語モデルをファインチューニングの過程で学習された低ランク行列のランクを表す。この値を大きくすると、低ランク適応中に更新する必要のあるパラメータの数が増える。直感的には、rを小さくするほど、より短時間で、より計算量の少ない学習処理が可能になるが、生成されるモデルの品質に影響を与える可能性がある。しかし、rをある値以上に大きくしても、モデル出力の品質が目に見えて向上することはない。rの値が適応(ファインチューニング)の質にどのような影響を与えるかは、まもなく検証される。
LoRAでファインチューニングを行う場合、モデルアーキテクチャの特定のモジュールをターゲットにすることが可能です。適応プロセスは、これらのモジュールをターゲットとし、更新行列を適用する。r "の場合と同様に、LoRA適応の際により多くのモジュールをターゲットにすると、トレーニング時間が長くなり、計算リソースへの要求が大きくなります。したがって、変換器の注目ブロックのみをターゲットにするのが一般的である。しかし、DettmersらのQLoRA paperに示されるように、最近の研究では、すべての線形層をターゲットにする方が、適応の質が向上することが示唆されている。この点についても検討する。
モデルの線形層の名前は、以下のコード・スニペットで簡単にリストに追加できる:
LoRAによるファインチューニング
一般的に大規模な言語モデルを微調整する開発者の経験は、ここ1年ほどで劇的に改善された。Hugging Faceの最新の高レベル抽象化は、TRLライブラリーのSFTTrainerクラスである。QLoRAを実行するために必要なのは以下の通り:
1. モデルをGPUメモリに4ビットでロードする(bitsandbytesはこのプロセスを可能にする)
2. 前述のように LoRA 設定を定義します。
3. Hugging Face Datasetオブジェクトに、事前準備された命令以下のデータの訓練とテストの分割を定義します。
4. トレーニング引数を定義する。これには、エポック数、バッチサイズ、その他のトレーニングハイパーパラメータが含まれます。
5. これらの引数を SFTTrainer のインスタンスに渡します。
これらのステップは、このブログのrepositoryにあるソースファイルに明確に示されている。
実際のトレーニング・ロジックは以下のようにうまく抽象化されている:
DatabricksワークスペースでMLFlowのオートロギングが有効になっている場合(これは強く推奨されます)、すべてのトレーニングパラメータとメトリクスは自動的に追跡され、MLFlowトラッキングサーバでログに記録されます。この機能は、長期間実行されるトレーニングタスクを監視する上で非常に貴重です。言うまでもなく、ファインチューニングプロセスは、GPUをサポートした最新のDatabricks Machineランタイムを使用して作成されたコンピュートクラスタ(この場合、シングルA100 GPUを搭載したシングルノード)を使用して実行されます。
Hyperparameter Combination #1: QLoRA with r=8 and targeting “q_proj”, “v_proj”
QLoRAハイパーパラメータの最初の組み合わせはr=8であり、注目ブロック、すなわち "q_proj "と "v_proj "のみを適応の対象としている。
以下のコード・スニペットは学習可能なパラメータの数を示している:
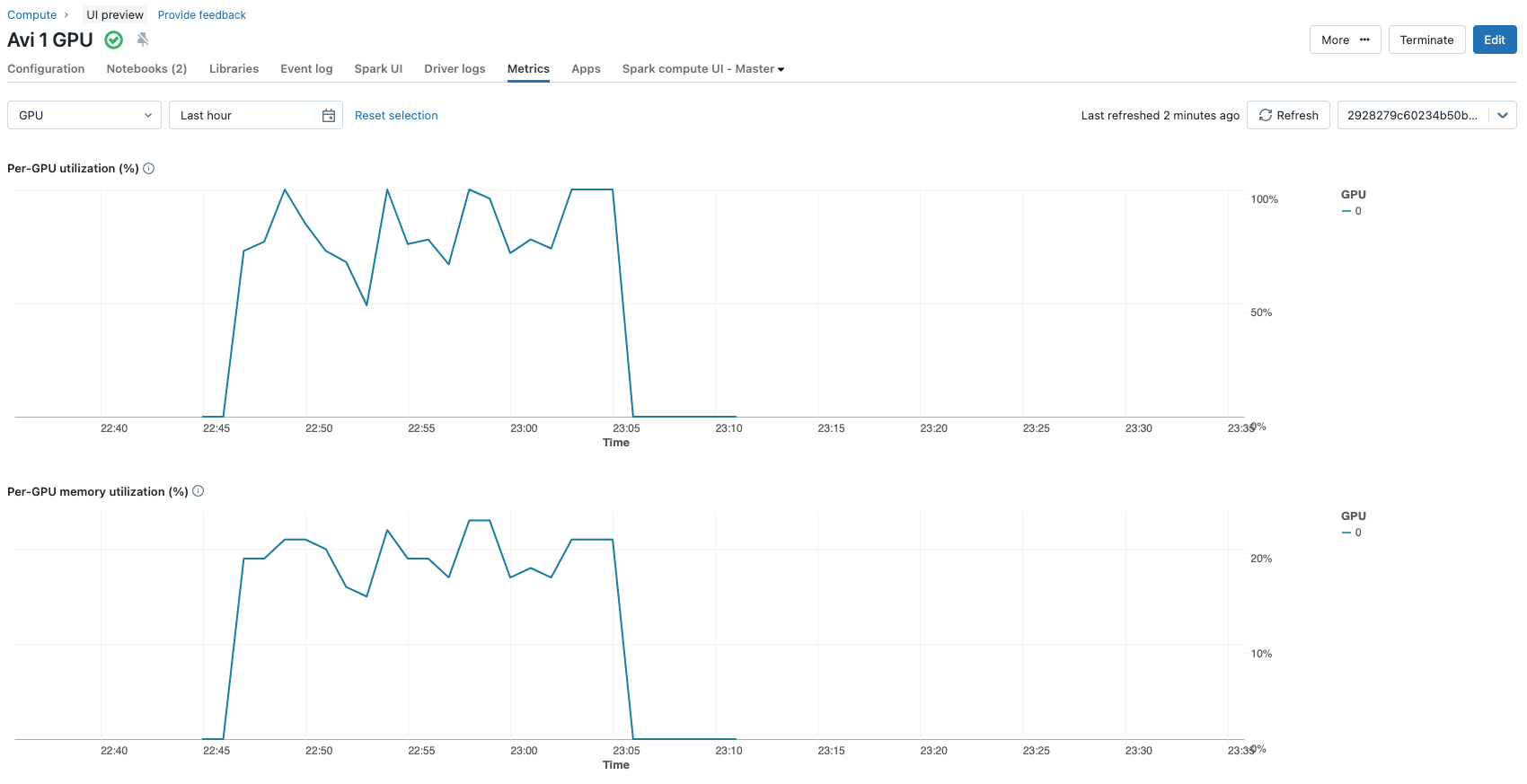
これらの選択により、モデルが構成する全パラメータ約32億個のうち、微調整の過程で更新されたパラメータは2,662,400個(約260万個)になる。これはモデルパラメーターの0.1%未満である。80GBのGPUを搭載した1台のNvidia A100で、3エポックのファインチューニング・プロセス全体を実行しても、およそ12分しかかかりません。GPU 利用メトリッ クは、クラスタ構成のメトリックス・タブで見ることができます。
学習プロセスの最後に、以下のようにアダプターの重みを事前学習モデルにロードすることで、ファインチューニングされたモデルが得られる:
このモデルは、他のモデルと同じように推論に使うことができる。
定性的評価
プロンプトとレスポンスのペアの例を以下に挙げる
プロンプト(アルパカ形式でモデルに渡される:)
次の製品の詳細な説明を作成します: カテゴリに属するCorelogic Smooth Mouse: 光学式マウス
Response:
Prompt:
次の製品の詳細な説明を作成します: カテゴリに属するHoover Lightspeed: コードレス掃除機
Response:
このモデルは明らかに、より一貫性のある記述を生成するために適応されている。しかし、光学式マウスに関する最初のプロンプトに対する回答は非常に短く、次のフレーズ「掃除機にはダストコンテナが装備されており、ダストコンテナから空にすることができます」は論理的に欠陥がある。
ハイパーパラメータの組み合わせ#2: r=16のQLoRAで、すべての線形レイヤーを対象とする
確かにここは改善できる。適応中に学習される低ランク行列のランクを16に増やす、つまりrの値を2倍の16にして、他はすべて同じにすることを検討する価値がある。これにより、学習可能なパラメーターの数は2倍の5,324,800(~530万)になる。
定性的評価
しかし、同じプロンプトでもアウトプットの質は変わらない。
Prompt:
次の製品の詳細な説明を作成します: カテゴリに属するCorelogic Smooth Mouse: 光学式マウス
Response:
Prompt:
次の製品の詳細な説明を作成します: カテゴリに属するHoover Lightspeed: コードレス掃除機
Response:
同じように、詳細の欠如や、詳細が利用可能な場合の詳細の論理的欠陥が持続する。このファインチューニングされたモデルを実際のシナリオで商品説明の生成に使用する場合、このような出力は受け入れられません。
ハイパーパラメータの組み合わせ#3: QLoRA、r=8、すべての線形層をターゲットとする
rを2倍にしても出力品質が知覚できるほど向上するようには見えないことから、もう1つの重要なつまみを変更する価値がある。ここではLoRAのハイパーパラメータはr=8で、target_layersは'q_proj','k_proj','v_proj','o_proj','gate_proj','down_proj','up_proj'と'lm_head'である。これにより、更新されるパラメータ数は12,994,560に増加し、トレーニング時間はおよそ15.5分に増加する。
定性的評価
モデルに同じプロンプトを出すと、次のようになる:
Prompt:
次の製品の詳細な説明を作成します: カテゴリに属するCorelogic Smooth Mouse: 光学式マウス
Response:
Prompt:
次の製品の詳細な説明を作成します: カテゴリに属するHoover Lightspeed: コードレス掃除機
Response:
今では、架空の光学式マウスに関するある程度長い首尾一貫した説明を見ることができるし、掃除機の説明にも論理的な欠陥はない。製品の説明は論理的であるだけでなく、適切である。念のために言っておくと、これらの比較的質の高い結果は、一貫した方法でフォーマットされたこのようなプロンプトと説明のペアの合計5000のデータセットで、モデルの重みの1%未満を微調整することによって得られたものである。
ハイパーパラメーターの組み合わせ#4:LoRA、r=8、全リニア・トランスレイヤーをターゲットとする
また、事前学習されたモデルを4ビットではなく8ビットでフリーズさせた場合、モデルからの出力の質が向上するかどうかを調べる価値がある。言い換えれば、QLoRA の代わりに LoRA を使用して、ファインチューニングプロセスを再現する。ここで、LoRAのハイパーパラメータは、新たに発見された最適な構成、すなわちr=8で、適応プロセス中にすべての線形変換層をターゲットとする、以前と同じに保たれる。
定性的評価
記事中で使用された2つのプロンプトの結果は以下の通り:
Prompt:
次の製品の詳細な説明を作成します: カテゴリに属するCorelogic Smooth Mouse: 光学式マウス
Response:
Prompt:
次の製品の詳細な説明を作成します: カテゴリに属するHoover Lightspeed: コードレス掃除機
Response:
繰り返しになるが、出力テキストの品質にはそれほど大きな改善は見られない。
主な考察
上記の一連の試行と、QLoRAを紹介する優れた出版物に詳述されているさらなる証拠に基づき、r(適応中に�更新される行列のランク)の値は、ある点を超えると適応の質を向上させないことが推論できる。最大の改善は、LoRAやQLoRAを詳述した技術文献で一般的に文書化されているように、適応プロセスにおいて、注目ブロックだけでなく、すべての線形層をターゲットにすることで観察される。上記で実施された試行やその他の経験的証拠から、QLoRAはLoRAと比較して、生成されるテキストの品質が目に見えて低下することはない。
LoRA アダプタの展開におけるさらなる考慮事項
アダプターの使い方を最適化し、この手法の限界を理解することが重要です。ファインチューニングによって得られるLoRAアダプターのサイズは通常数メガバイトですが、事前に訓練されたベースモデルはメモリ上でもディスク上でも数ギガバイトになります。推論中、アダプタと事前学習された大規模言語モデルの両方をロードする必要があるため、必要なメモリは同程度のままです。
さらに、事前に訓練されたLLMとアダプターの重みがマージされていない場合、推論のレイテンシがわずかに増加します。幸いなことに、PEFTライブラリを使えば、重みとアダプターをマージする処理は、ここに示すように1行のコードで行うことができます:
下図は、アダプタのファインチューニングからモデルのデプロイまでのプロセスの概要を示しています。

アダプタ・パターンには大きな利点がありますが、アダプタのマージは普遍的な解決策ではありません。アダプタパターンの利点の1つは、タスク固有のアダプタを持つ1つの大きな事前学習済みモデルをデプロイできることです。これにより、事前訓練されたモデルを異なるタスクのバックボーンとして利用することで、効率的な推論が可能になります。しかし、重みのマージはこのアプローチを不可能にします。重みをマージするかどうかは、特定のユースケースと許容できる推論レイテンシーに依存する。それにもかかわらず、LoRA/ QLoRAはパラメータを効率的にファインチューニングするための非常に効果的な手法であり続け、広く使用されている。
まとめ
低ランク適応は強力なファインチューニング技法であり、適切な構成で使用すれば素晴らしい結果をもたらす。ランクの正しい値と、適応時にターゲットとするニューラルネットワークアーキテクチャの層を選択することで、ファインチューニングされたモデルからの出力の品質が決まる可能性がある。QLoRAは、適応の質を保ちながら、さらなるメモリの節約をもたらす。ファインチューニングを行う場合でも、適応されたモデルが正しい方法で展開されるようにするために、工学的に考慮すべき重要な点がいくつかある。
要約すると、OpenLLaMA-3b-v2を1つのA100で5000のオブザベーションを3エポックでファインチューニングしたときに、試行したLoRAパラメータの異なる組み合わせ、テキスト品質出力、更新されたパラメータ数を示す簡潔な表を以下に示します。
|
r |
target_modules |
Base model weights |
Quality of output |
Number of parameters updated (in millions) |
|
8 |
Attention blocks |
4 |
low |
2.662 |
|
16 |
Attention blocks |
4 |
low |
5.324 |
|
8 |
All linear layers |
4 |
high |
12.995 |
|
8 |
All linear layers |
8 |
high |
12.995 |
Databricksで試してみよう!このブログに関連する GitHub repositoryを Databricks Repo にクローンして始めましょう。Databricks上でモデルをファインチューニングするための、より詳細な文書化された例が利用可能です here.

