サンタクロースもAIフィーバー
北極株式会社はいかにしてDatabricksでデータ+AIを取り入れたか?

公開日: December 15, 2023
によって アレックス・ミラー、クナル・マーワー、ミカイラ・ガーフィンケル、アビナッシュ・スーリヤラッチ による投稿
サンタクロースは北極株式会社のCEOとして、世界で最も複雑なサプライチェーン、製造、物流業務を監督しています。
毎年、サンタと最高執行責任者(COO)であるサンタ夫人、そして妖精さんのチームは、世界中の子どもたちから届く何百万通もの手紙を読み、「いたずらっ子リスト」や「いい子リスト」と照らし合わせ、彼らが欲しいプレゼントを登録し、そして何百万ものプレゼントを作り、たった一晩ですべてを届けなければなりません。サンタとそのクルーはこれらを簡単に行なっているように見せていますが、運営上は悪夢のような作業であり、依然として大部分が手作業で行われています。そのため、他の多くのビジネスリーダーと同様、サンタもAIがどのように役立つかを知りたがっていました。そこで彼はDatabricksに助けを求めました。
Foundation Model APIなどのDatabricksツールと、合成データ生成や名前付きエンティティ認識などのテクニックを使って、サンタに宛てた子供たちの手紙を分析し、それぞれの子供が欲しいプレゼントを引き出すモデルを作成しました。
以降のセクションでは、Databricksのデータインテリジェンスプラットフォームを使用して、 これまで数週間かかっていた作業を数分で達成できるAIモデルを作成した方法を紹介します。この青写真は、パーソナライズされたコミュニケーションやカスタマーサポートの改善など、あらゆる企業がAIを活用するために実践できるものです。
合成データとは何か、なぜ重要なのか
合成データとは、現実世界のデータを模倣するように設計された人工的に生成されたデータのことです。そして、AIの将来において大きな役割を果たすでしょう。実際、ガートナーによれば、2024年までに全トレーニングデータの60%が合成データになるとのことです。
AIは膨大な量のデータを必要といます。例えば、既存の商用大規模言語モデル(LLM)を微調整したり、独自の言語モデルを開発したいとしましょう。他の組織は、財務記録や医療記録のような、必要な機密情報やドメイン固有の情報を入手できないかもしれません。どの企業もデータセットに十分な多様性を持たせたいと考えています。だからこそ、合成データはますます不可欠になります。
合成データには、安価かつ非常に整理されているという大きな利点があります。この2つの特徴は、現実世界のデータセットでは見つけるのが困難です。また、ハッカーによる攻撃が増えている顧客データへの依存を減らすことができるため、より安全性を高�めることができます。さらに、合成データはより多様で、企業が独自に設定したデータのギャップを埋めるのに役立ち、最終的なAIモデルをより正確で信頼性の高いものにするのに役立ちます。
しかし、いくつかの制限があります。実世界の情報には、合成データでは再現が難しい一方で、モデルのパフォーマンスには不可欠なニュアンスが存在することがよくあります。シミュレーションでは完璧に運転する自動運転車が、実際の人間のドライバーの前ではミスを犯すようなものです。
どうやったのか?
Databricksで最近提供が開始されたFoundation Models APIを利用し、MetaのLlama2 70BモデルにMosaicML推論を加えて、過去20年間に北米で最も人気のあった子供の名前と、2023年に5歳から15歳の子供に最も人気のあったギフトテーマを生成してもらいました。(後者については、家庭の装飾品や旅行関連のアイテムを避けるなど、異常な応答を制御するために、クエリの周りにいくつかのパラメータを設定する必要がありました - これは一般的に プロンプトエンジニアリングと呼ばれています) 。
次に、Llama2からの文字列出力をPythonでフォーマットし、子供の名前とプレゼント・カテゴリの1つをランダムにペアリングするDeltaテーブルを作成しました。これで、サンタへの手紙の作成に必要な合成入力データができました。最初は、Pandasデータフレームを使って、Llama2に連続的に問い合わせを行い、これらの手紙を作成しました。しかし、この処理には1時間以上かかりました。Databricksのデータインテリジェンスプラットフォームを使うと、1000通の手紙を5分もかからずに作成できました。その理由として、Apache Spark™を使用することで、基礎となるモデルに複数の名前と対応するギフト・カテゴリーを同時に入力できたからです。
次に、子供たちがリストアップしたかもしれない特定のアイテムなど、妖精さんたちが適切なプレゼントを作るのに役立つ情報を各文字から引き出したいと考えました。 名前固有表現認識(NER)と呼ばれる処理を使って、1000文字すべてをスキャンし、「スケートボード」や「コーディング・キット」といった単語を引き出しました。自然言語処理の一分野であるNERは、日付、物、人名などの特定のパラメータに基づいて情報を引き出す処理です。NERは、ユーザーコメントや製品説明のような大量のテキストを要約する際に、膨大な時間を節約するのに役立ちます。
北極株式会社では、Llama2を使って、手紙から引き出したい具体的な特徴、つまり、人の名前や場所、日付、各子供がリクエストした具体的なプレゼント/製品を特定しました。以下はNERを使った手紙の例です。

その情報はDeltaテーブルに保存され、北極株式会社の従業員は、子供たちがクリスマスプレゼントに何を欲しがっているかを素早く把握することができました。また、Lakeviewダッシュボードを使用する ことで、全体的なプレゼントのリクエストの上位や各カテゴリーの上位など、サンタの情報をまとめたレポートを簡単に作成できました。


最後に、妖精さんたちがデータセットから知見を簡単に抽出できるようにしたいと考えました。Text-to-SQLエンジンを使うことで、北極株式会社のエンジニアは、SQLジョブを実行するのに必要な構文を得るために、自然言語クエリを取得できるようになりました。例えば、サンタはエミリーとガブリエルという名前の女の子にどんなプレゼントを贈るのか知りたがっているかもしれないとして、妖精さんたちはそのリクエストをエンジンに入力するだけで、答えを得るために実行する必要のあるSQL文が返ってきます。
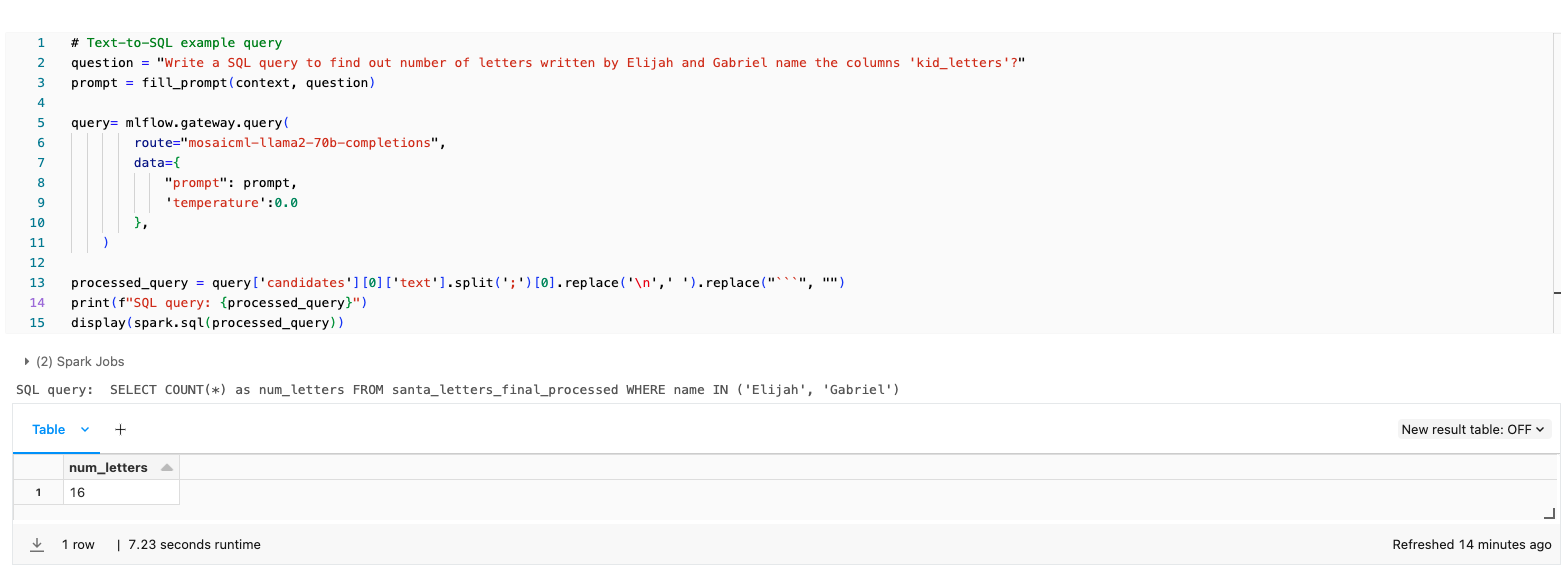
私たちは何を学んだのか?
上記のことを達成する方法はたくさんありました。しかし私たちは、サンタがこれらのAIを企業全体に拡大することを熱望していることを知っていました。そしてそれは、北極を越えて広く採用される準備をしなければならないことを意味していました。 下の地図は、米国の州ごとに最も人気のあるギフト・カテゴリーをまとめたものです(生成されたすべての文字に、異なる米国の州をランダムに割り当てて��います)。

Llama2やMPT-7Bのような基盤モデルは重要ですが、拡張するのが難しく、コストがかかります。Databricksのデータインテリジェンスプラットフォームを使用することで、より簡単に、より速く、より安く行うことができるようになりました。例えば、大規模なデータセットの場合、数週間またはそれ以上かかる可能性のあるプロセスである、基盤モデルにワークロードを1つずつ送信する代わりに、Sparkを使用して数分で終了する一括ジョブを実行することができました。AIを企業全体に拡大しようとする場合、このような利便性とスピードは必須です。
Databricksマーケットプレイス内の基盤モデルを介して商用モデルとのインターフェイスをDatabricksのようなプラットフォームに依存することは、北極株式会社のような企業がデータをレイクハウスから移動する必要がないことを意味します。社内のエンジニアが複雑なデータパイプラインの構築や管理から解放されるだけでなく、企業はデータの安全性を確保し、個々のユーザーに至るまでアクセスを管理することができます。
例えば、合成データではなく実際の顧客データを使って手紙を作成したとしましょう。そのためには、より厳格なセキュリティ管理と、消費者情報の保存と使用に関するあらゆる規制を考慮したガバナンスの枠組みが必要となります。
この演習の応用例は?
私たちは、北極株式会社が他の多くの企業とは大きく異なる組織であることを理解しています。 しかし、この演習は、ほとんどすべての企業が恩恵を受けることができる幅広い応用が可能です。
例えば、マーケティングチームは、顧客一人ひとりにパーソナライズされたホリデー・グリーティングカードを作成したいと思うかもしれません。その企業は、売上上位の見込み客にお歳暮を贈りたいかもしれません。あるいは、連休明けの返品サイクルをより正確に把握したい小売業者が、何千件もの顧客サービスコールから知見を引き出そうと躍起になっているのかもしれません。これらのユースケースはすべて、北極株式会社で使ったのと同じアプローチに依存しています。
この ブログで使用したサンプルコードです。 Databricksが生成AIの学習と構築にどのように役立つかについては、オンデマンドWebセミナーをご覧ください:生成AIで業界を破壊する

