SIEM検知ルールの進化:シンプルから洗練への旅

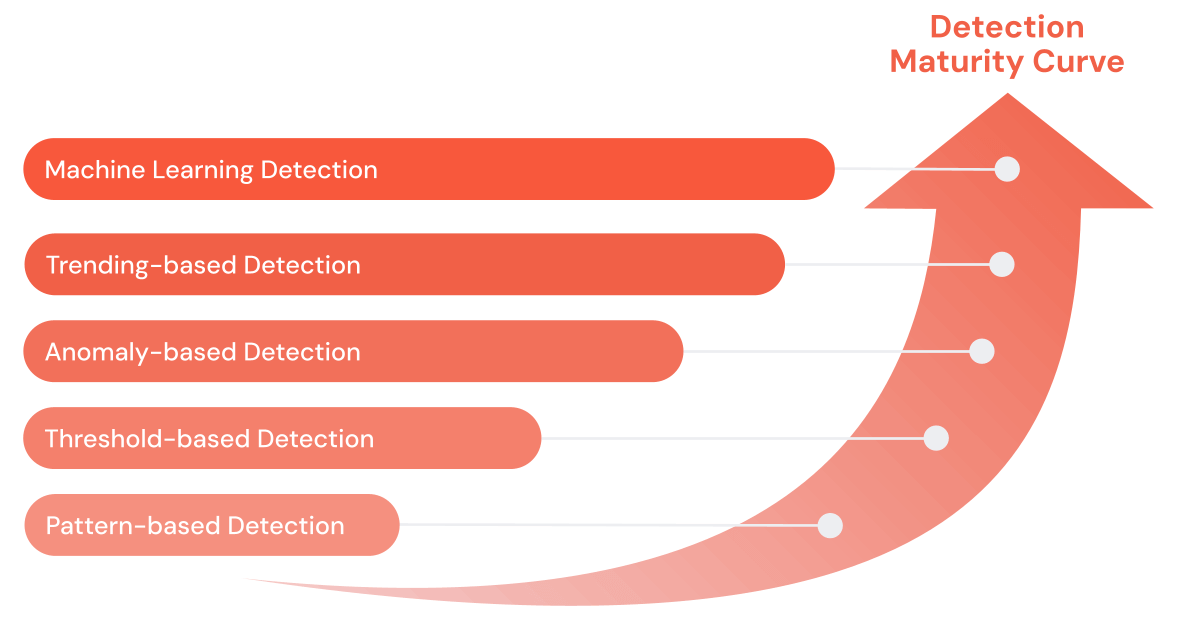
サイバー脅威とそれに対抗するツールはより洗練されたものになっています。 SIEMは20年以上の歴史があり、その間に大きく進化してきました。 当初はパターンマッチングと閾値ベースのルールに依存していたSIEMは、より高度なサイバー脅威に対処するために分析能力を向上させました。 「検知成熟度曲線」と呼ばれるこの進化は、セキュリティ運用が単純な警告システムから脅威の予測分析が可能な高度なメカニズムへと移行したことを示しています。 このような進歩にもかかわらず、最新のSIEMは、大規模なデータセットや長期的な傾向分析、機械学習による検出のためのスケーリングという課題に直面しており、複雑化する脅威要因の検出と対応に対する組織の能力が問われています。
そこでDatabricksがサイバーセキュリティチームを支援します。 Apache Spark™、MLflow、およびDeltaテーブルを搭載したDatabricksの統合アナリティクスは、企業の最新のビッグデータと機械学習のニーズを満たすために、コスト効率よく拡張できます。
このブログ記事では、基本的なパターンマッチングから高度なテクニックへと移行する、進化するセキュリティ検出ルールを構築する旅について説明します。 各ステップの詳細を説明し、Databricks Data Intelligence Platformを使用して、月間100テラバイトを超えるイベントログと4ペタバイトを超える履歴データに対してこれらの検出を実行し、スピードとコストの世界記録を更新した方法を紹介します。
序章
私たちの主な目的は、検知成熟度曲線に記載されている検知パターンを解明し、その価値、利点、限界を探ることです。 そのために、このブログのソースと、あなたのサイバー分析プログラムに使える繰り返し可能なPySparkコードを含むヘルパーライブラリをGitHubリポジトリに作成しました。 このガイドの例は、Git リポジトリが生成するサンプルログに基づいています。
1. パターンベースのルール
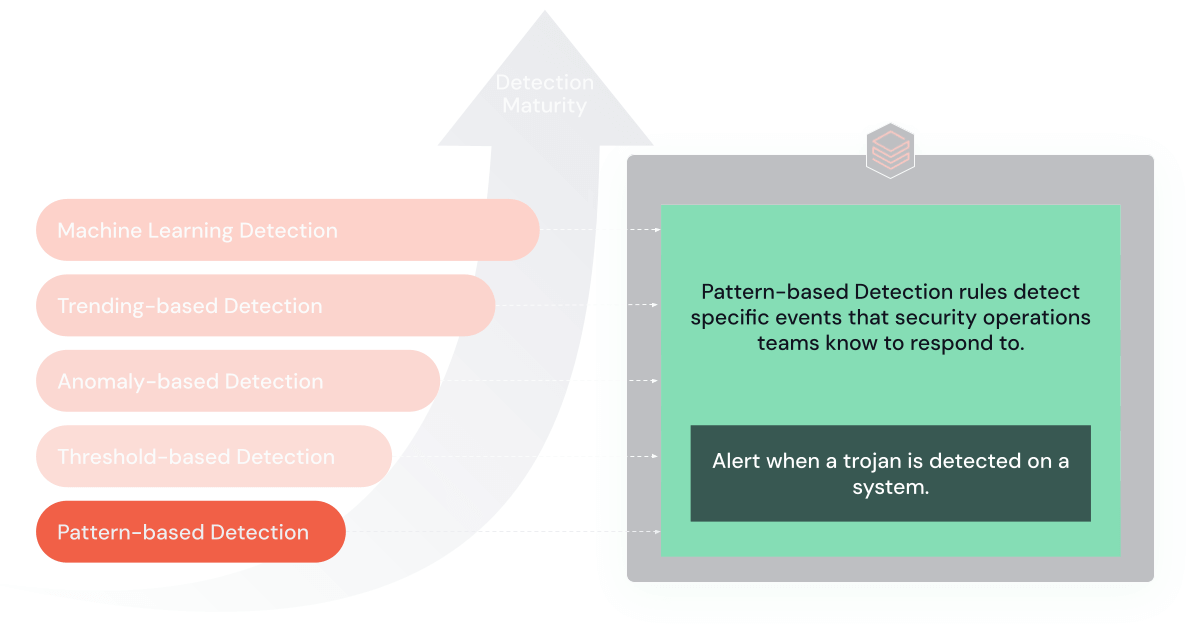
パターンベースのルールは、SIEMの検出の最も単純な形態であり、データ内の特定のパターンやシグネチャを認識したときにアラートをトリガーします。
目的と利点:これらのルールはSIEMの検知の基礎となるもので、シンプルさと特異性を提供します。 既知の脅威を迅速に特定し、対応する上で非常に効果的です。
制限事項:主な欠点は、新しい未知の脅威に適応する能力が限られているため、高度なサイバー攻撃に対して効果が低いことです。
使用時期:これらのルールは、サイバーセキュリティプログラムの初期段階にある組織や、主に十分に文書化された脅威に直面している組織に最適です。
例えば、以下のSQLパターンベースのルールは、特定のマルウェアのシグネチャを検索します:
コード1: virus_categoryが'trojan'の場合のパターン・ベースのSQLコマンドの例。
2. 閾値ベースのルール
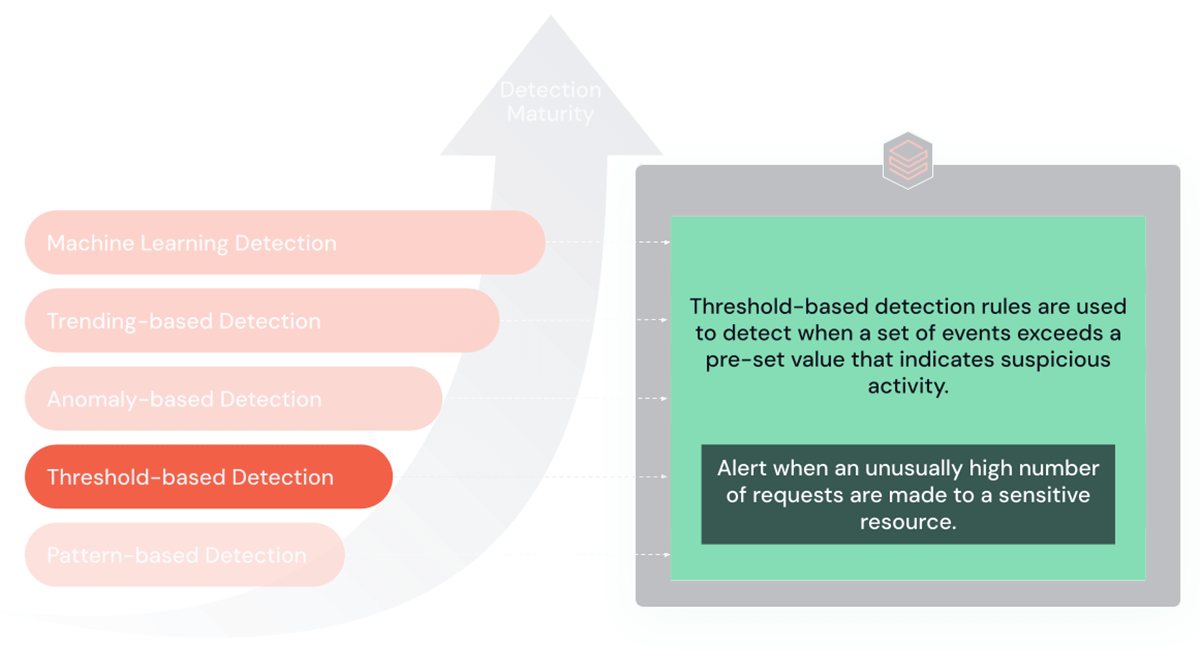
閾値ベースのルールは、イベントが事前に定義されたリミットまたは閾値を超えた場合にアラートをトリガーするように設計されています。 ブルートフォース攻撃やサービス拒否(DoS)攻撃のようなシナリオでは特に効果的です。
目的と利点:これらのルールの主な長所は、異常に高いネットワーク・トラフィックや異常な数のログイン試行など、通常のアクティビティからの著しい逸脱を検出する能力にあります。 そのため、大規模で目立つ攻撃を特定するのに非常に有効です。
制限事項:ただし、この閾値をすぐに超えないような、ゆっくりと進行する攻撃に対しては効果が薄れます。 また、静的な閾値が低すぎると偽陽性が発生し、高すぎると偽陰性が発生します。
使用時期:これらのルールは、ベースラインのアクティビティレベルが確立され、明確な閾値設定が可能な環境で最も効果的です。 これには、ネットワーク・トラフィックの監視やログイン試行の追跡などのシナリオが含まれます。
例えば、次の SQL トレンドベースのルールは、ユーザのログイン試行における統計的に有意な偏差を識別する方法を示しています:
コード2:ウェブサーバーへの接続数が30分で100を超えた場合の閾値ベースのSQLコマンド例
このSQLクエリは、30分間に1つのIPから100を超える接続があった場合にアラートをトリガーします。
3. 統計的異常検知
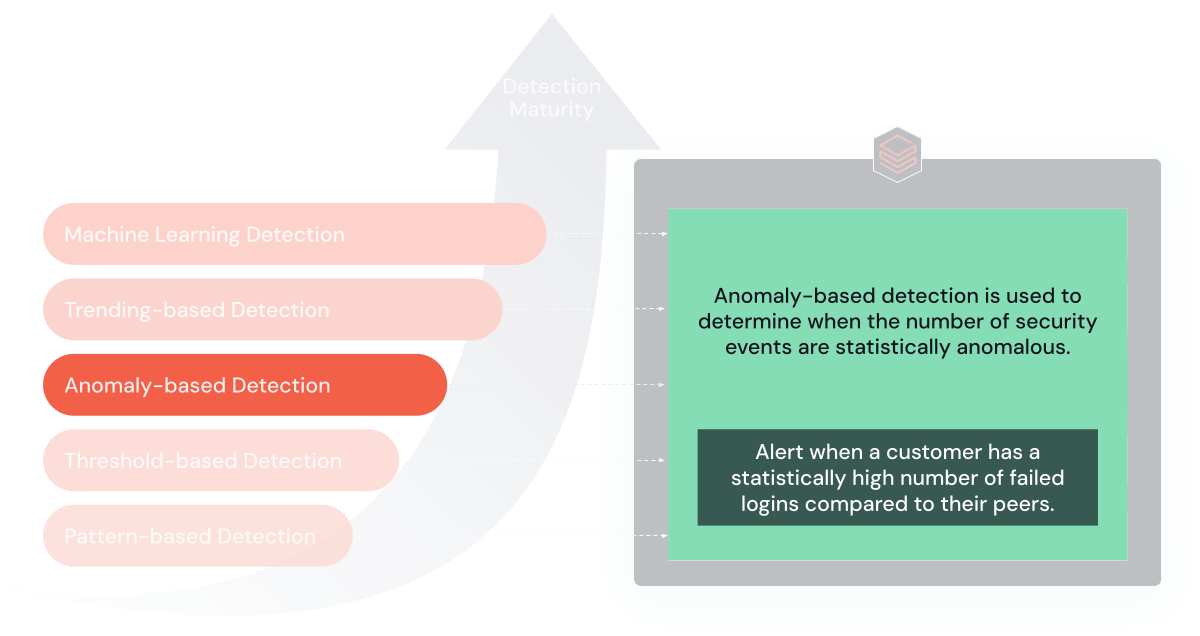
検出機能が成熟すれば、環境内の統計的異常を検出する技術を組み込むことができます。 これらのルールは、過去のデータに基づいて「正常な」行動のモデルを構築し、通常から著しく逸脱した場合に警告を発します。
目的と利点:これらのルールは、「正常な」行動からの逸脱を発見することに優れており、脅威検出へのダイナミックなアプローチを提供します。
制限事項:過去の膨大なデータを必要とし、較正を誤ると偽陽性を生じる可能性があります。 多数のエンティティの追跡には膨大な計算が必要となるため、従来のSIEMでは内部的な限界に達したときにパフォーマンスの問題が発生したり、結果が欠落したりする可能性があります。
使用時期:豊富な履歴データを持つ成熟したサイバーセキュリティ環境に最適です。
例えば、次のSQL異常ベースのルールは、ユーザーのアクティビティがピアグループのアクティビティから統計的に逸脱している場合に検出します:
コード3:login_idのアクティビティが全ユーザより3倍高い場合に識別する、異常ベースの検出SQLコマンドの例。
こ��のクエリは、あるユーザのログイン失敗が同僚のログイン失敗平均の標準偏差の3倍を超えた場合にアラートをトリガします。
4. トレンドベースのルール
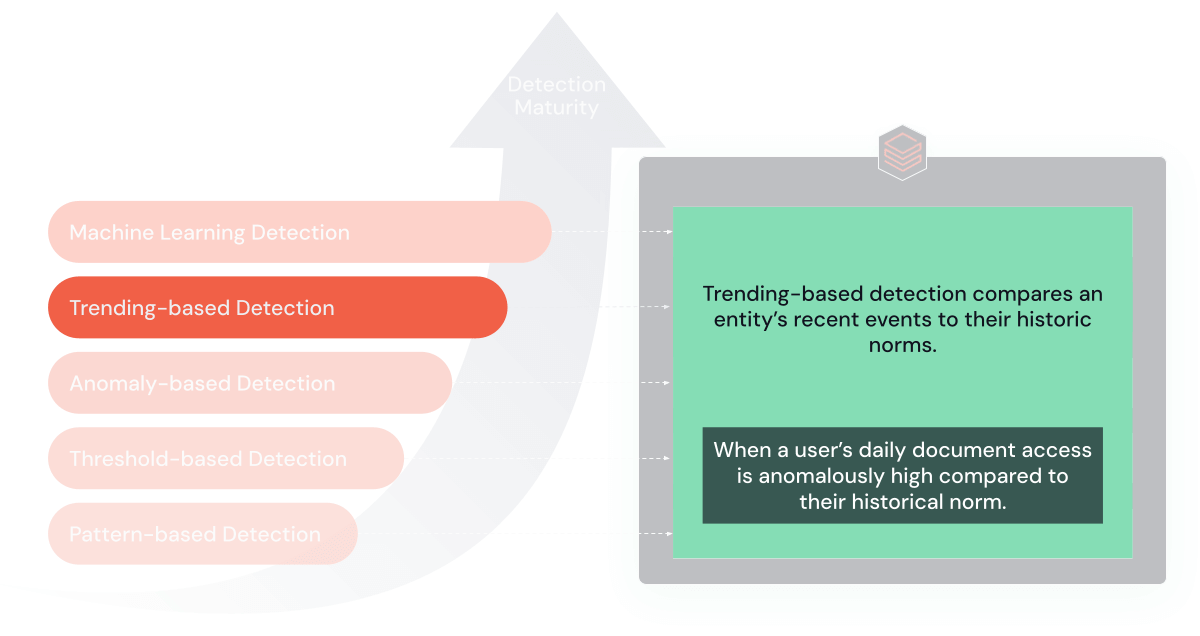
トレンドベースのルールは、時間経過に伴うエンティティの行動の異常または重大な変化を識別するように設計されています。 これらのルールは、個人の過去の規範と現在の活動を比較し、誤検知を効果的に減らします。
目的と利点:これらのルールは、微妙に進化する脅威を発見することに長けています。 経時的なデータの傾向を分析することで、セキュリティ上の脅威を示す可能性のある行動の変化に関する洞察を提供します。
制限事項:トレンドベースのルールの主な課題の1つは、リソースを大量に消費し、大量のデータを継続的に分析する必要があることです。
使用時期:長期的なデータ監視が現実的で、検知エンジンが拡張可能で、脅威が徐々に発生する可能性がある場合に最も効果的です。 従来のSIEMは、その複雑性からトレンド分析には通常使用されていません。
前のパターンから異常なログイン試行を監視することを考えてみましょう。 ��あるユーザーが同業者グループから逸脱していても、その逸脱はそのユーザーにとって典型的なものかもしれません。 トレンドベースのルールは、特定のホスト名に対するログイン試行失敗が過去のパターンと比較して著しく増加した場合に警告を発するように、または、より重要なこととして、そうでない場合に警告を発しないように展開することができます。
例えば、以下の SQL トレンディングベースのルールは、ユーザのログインが過去の傾向から統計的に有意であることを検出します:
コード4:login_idのアクティビティが同業者より3倍高い場合に識別する異常ベースの検出SQLコマンドの例。
この例では、過去1週間の各ホスト名からのログイン試行失敗の1日平均数と、過去24時間の各ホストからのログイン試行失敗数を計算します。 次に、これら2つの結果セットをホスト名で結合し、過去24時間の試行失敗数が過去90日間の1日平均試行数を超えるホストをフィルタリングします。
5. 機械学習ベースのルール
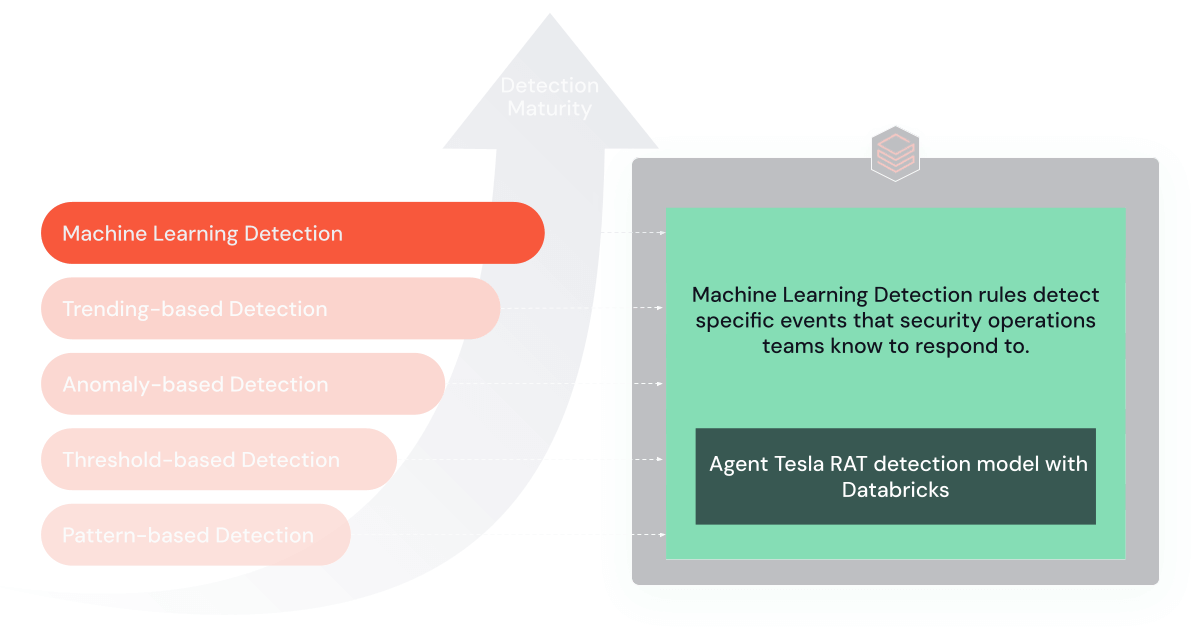
最先端の検出ルールは、脅威への適応のために機械学習アルゴリズムを継続的に使用しています。 これらのアルゴリズムは、過去のデータから学習して将来の脅威を予測・検知することができ、より決定論的なルールでは見逃してしまうような攻撃も検知することができます。 機械学習モデルの実装と運用には、データサイエンスと機械学習の専門知識とプラットフォームへの多大な投資が必要です。 Databricksのデータインテリジェンスプラットフォームは、初期モデルの開発、デプロイメント、そして最終的な廃棄段階まで、機械学習のライフサイクル全体を包括的に管理します。
クラスタリング(K-means、階層型クラスタリングなど)や異常検知(Isolation Forests、One-Class SVMなど)といったアルゴリズムを用いて学習された教師なし学習モデルは、これまで知られていなかった新たなサイバー脅威を特定する上で極めて重要です。 これらのモデルは、データの「正常な」行動パターンを学習し、この規範からの逸脱を潜在的な異常または攻撃としてフラグを立てることで機能します。 教師なし学習は、ラベル付けされたデータがまだ存在しない新たな脅威の検出に役立つため、サイバーセキュリティにおいて特に価値があります。
逆に、SOCは教師あり学習モデルを採用し、ラベル付けされたデータに基づいて既知のタイプの攻撃を分類・検出します。 これらのモデルの例としては、ロジスティック回帰、決定木、ランダムフォレスト、サポートベクターマシン(SVM)などがあります。 これらのモデルは、攻撃インスタンスが特定され、ラベル付けされたデータセットを使用して学習され、さまざまなタイプの攻撃に関連するパターンを学習し、その後、新しい未見のデータのラベルを予測することができます。
機械学習については、DatabricksによるDNSアナリティクスを通じてAgentTeslaRATを検出する優れたプロジェクト(Githubはこちら)を参考にします。
ボーナス:リスクベースのアラート
リスクベースの警告は、検出パターンを補完する強力な戦略です。 リスクベースの警告は、エンティティ(IPアドレス、ユーザーなど)に対する"リスクのある" アクション(ログイン失敗、時間外のアクションなど)を定量化します。 多くの場合、リスクカテゴリー、キルチェーンステージなどの有用なメタデータが含まれており、検知エンジニアはより広範なイベントに基づいてルールを構築することができます。
リスクベースの検知プロセスを構築するには、イベントのリスクスコアリングという余分なステップが必要です。 これは、テーブルの中にリスクスコアの列を新たに追加することで実現できますが、複数のソースからのリスクイベントを組み込んだリスクテーブルを作成するのが一般的です。

リスクベースの検知戦略を採用する組織は、上記の検知パターンを利用することができます。 例えば、あるユーザーが高リスクのスコアを持っているとします。 このような場合、管理者が変更ウィンドウの深夜に定期的にアップグレードを実行している場合にアラートが表示されないように、組織は傾向検出パターンを使用して、これがユーザーに固有であるかどうかを確認できます。
ガートナー®: Databricks、クラウドデータベースのリーダー

反復可能なコード
GitHubリポジトリには、収集、フィルタリング、検出のための標準的なサイバー関数を持つノートブックヘルパーメソッドが含まれています。 Databricksには、このライフサイクルを簡素化するためのプロジェクトもあります。 詳細については、担当のアカウント・マネージャーにお問い合わせください。
まとめ
進化し続けるサイバー脅威の世界では、SIEMの検知を基本的なパターンマッチングから高度な機械学習へとアップグレードすることが不可欠です。 この転換は、複雑なサイバー脅威に効果的に対処するために戦略的に必要なことです。 検知手法の進化により、微妙なセキュリティ・インシデントを発見し対応する能力が高まる一方で、チームに過度の負担をかけることなく、これらの高度な技術を統合することが課題となっています。 最終的な目標は、現在の脅威と将来の課題の両方に効率的かつ機敏に対処できる、弾力的で適応力のあるサイバーセキュリティ・プログラムを開発することです。
