
イントロダクション
2023年のめまぐるしい発展の後、多くの企業がビジネスを加速させるために、ますます高性能になる生成AIモデルの採用に躍起になっています。 この推進には、最先端の大規模言語モデルをクエリし、企業の既存の業務の流れに組み込む能力が不可欠です。 これらのプロジェクトの主力は推論APIで、ユーザーがセキュアな環境にあるモデルにリクエストを送り、素早くレスポンスを受け取るための使いやすいインターフェースです。
私たちは、リアルタイムインタラクションの要求に合わせた最先端の推論システムを開発しました。このようなシステムの構築には、革新的なスケジューリング技術から、セキュリティや信頼性を含む新しい考慮事項まで、異なる原則のセットが必要です。このブログポストでは 、前回のブログで学んだことを 推論APIに取り入れることで、私たちの思考プロセスがどのように進化してきたかを説明します。
オンライン推論とユーザー体験にとって重要なこと
パフォーマンスを最大化するために、推論リクエストはNVIDIAのA100およびH100、AMDのMI300、IntelのGaudi、またはAWSのInferentiaのようなAIアクセラレータ上で実行されます。 現在のGPUサーバーのコストと供給の限界により、ユーザーのリクエストは同時に処��理される必要があります。 シンプルな戦略として、バッチ処理を利用することで、複数のリクエストを1つのモデルフォワードパスを通じて同時に実行します。 しかし、本番環境におけるユーザーのワークロードとトラフィックの多様性を考えると、このアプローチには限界があります:
第一に、 ユーザーからのリクエストは様々な特徴があり、通常は同時に到着しません。バッチ処理できるようにリクエストが来るのを待つ戦略には、大きな待ち時間のペナルティが伴います。バッチ内のリクエストは、最新のリクエストが到着するまで生成を開始できず、最初のトークンまでの時間が急増します。バッチ内のリクエストの入力と出力の長さが異なる場合、これもGPUの利用を最適化しないことにつながります。ユーザーAは長いストーリーを生成するようリクエストを送信し、ユーザーBは単純な「はい」か「いいえ」の質問をしたとします。ユーザーBのリクエストは素早く処理できますが、同じバッチにあるため、ユーザーBのリクエストが完了するまで待つ必要があります。この2つの問題の解決策は、反復レベルで生成を分割する連続バッチ戦略を利用することです。
次に、 バッチサイズを大きくすると、スループットは向上しますが、レイテンシは遅くなります。 当初、バッチサイズが小さい場合、性能はGPUメモリがコンピュートユニットにデータを供給する速度によって制限されます。より多くのユーザーに対応するためにバッチサイズが大きくなると、ある閾値のバッチサイズを超えると、制限はプロセッサの計算速度に移ります。このようなシナリオでは、サーバ��ーのスループット(1秒あたりに処理されるリクエスト数)とリクエストのレイテンシ(1つのリクエストが完了するまでの時間)を区別することが重要 です。バッチサイズを大きくすると、全体的なスループットが向上することが多いのですが、 バッチサイズが十分に大きい場合は、レイテンシが大きくなる可能性があります。開発者はサーバーの総合的なパフォーマンスを測定するためにスループットをモニターしますが、ユーザー体験は主に待ち時間によって左右されます。図1はバッチサイズの増加に伴う典型的なスループットのレイテンシ曲線を示しています。 このプロットからいくつかの興味深いことがわかります:
1) あるポイントまで、トラフィックが2倍増加するとスループットは2倍増加しますが、レイテンシは2倍増加しません。
2) 与えられたレイテンシで達成できる最大スループットを見つけることができます。例えば、1000msという予算の中で達成できる最大スループットは1秒あたり11500出力トークンです。
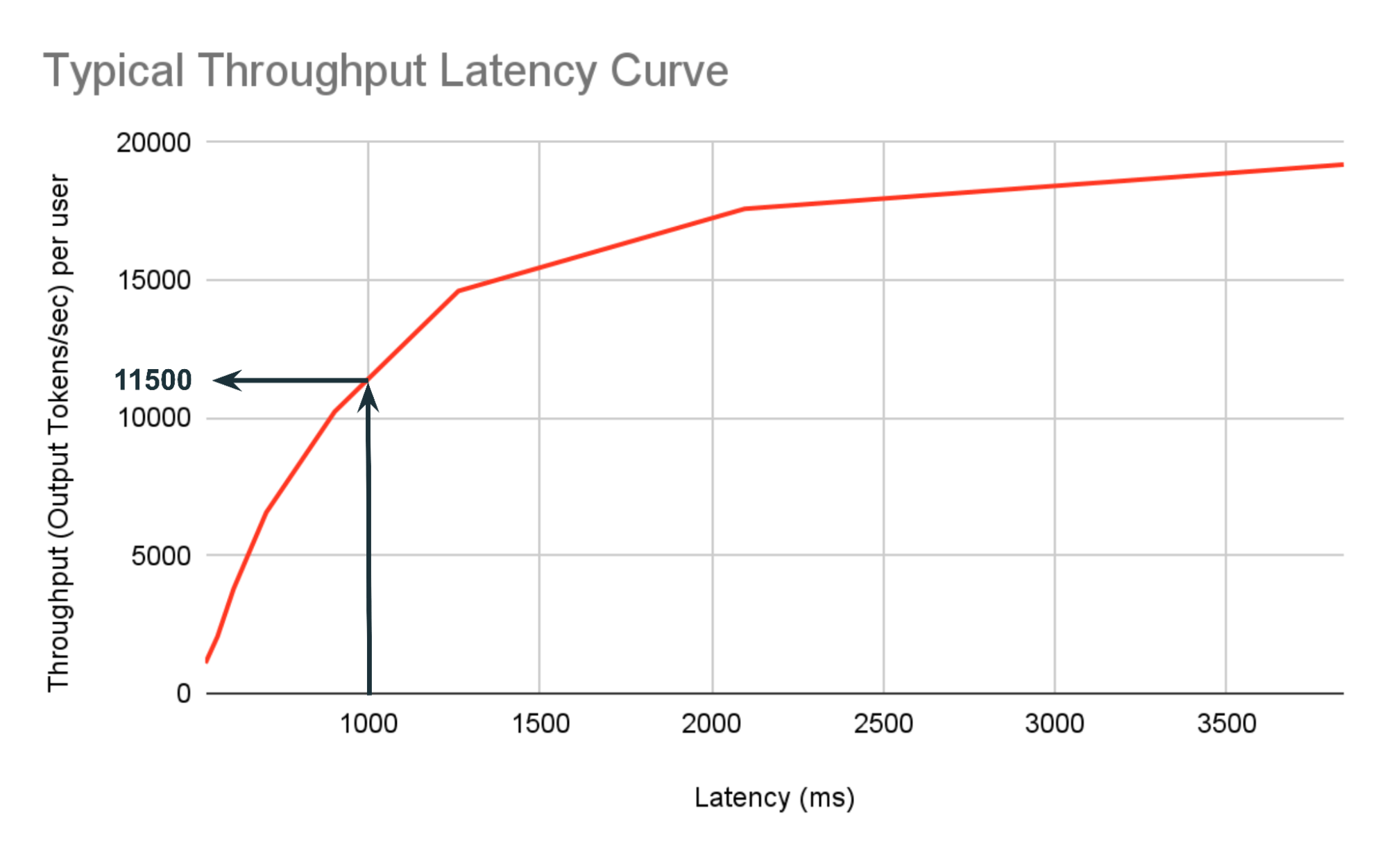
この現象はさらに、低いバッチサイズのベンチマークでは、ユーザーがリアルタイムの高トラフィック環境で期待するものを適切にシミュレートできないことが多いことを意味します。 文献にある多くの最適化技法は、メモリ帯域幅の制約が大きい低バッチサイズに対して最適化を試みますが、本番サービス環境では適していません。 GPUの供給には限りがあり、高価です。低いバッチサイズで実行すれば高速になるかもしれませんが、GPUを十分に活用できず、運用コストが上がります。
第三に、 ユーザーは長いコンテキスト長をサポートしたいと考えています。プロプライエタリなモデルの最近のトレンドは、より長いコンテキスト長(例えば、20万コンテキスト長のClaude 3や100万トークンのGemini 1.5 Pro)であり、オープンなモデルもすぐに追いつくでしょう。例えば、Mixtral-8x7bはすでに32,000トークンまでのコンテキスト長をサポートしています。これにより、首尾一貫した長文テキストの生成から、より長いドキュメントを対象とした検索補強型生成パイプラインの実現まで、多くの新しいアプリケーションが可能になりました。長いコンテキストは、メモリを大量に消費するKVキャッシュを生成するため、サービングに大きな課題をもたらします。長いコンテキストのメモリ管理は困難になります:KVキャッシュはより多くの領域を占め(Mixtralではバッチサイズ4で合計17GB)、これらのキャッシュはリクエストの途中で退避させることができないため、最大バッチサイズが制限されます。さらに、長いプロンプトはサーバに大きな計算負荷を与えます。サーバは各リクエストにより多くの計算を割り当てなければならなくなります。
第四に、本番ワークロードをサポートするために、ユーザは大量のリクエストを送信したいと思うでしょう。特定のチャッ��トベースのアプリケーションやデータ処理アプリケーションは、毎秒多くのクエリを送信するため、さらなる制御が必要となります。 リソースへの公平なアクセスを保証するためには 、特定のユーザのワークロードがキューを支配しないようにすることが重要です。そのための解決策がレート制限ですが、これを低く設定しすぎてユーザーの要求に応えられないようなことがあってはなりません。
オンラインパフォーマンスの指標
任意の時点で任意の数のユーザーが推論APIをヒットすることができ、彼らはすべて一貫して低いレイテンシと高い可用性を期待しています。 反応の待ち時間は2つの要因に影響されます:
- 待ち行列の遅延とプリフィル時間(つまり、すべての入力トークンを処理する時間)で、どちらも最初のトークンまでの時間(TTFT)に寄与します。
- 出力トークンあたりの時間(TPOT)で測定されるデコード速度。
インタラクティブなアプリケーションの場合、ユーザーは推論サーバーから出力がストリーミングされることを好みます。 これらのメトリクスはストリーミングパフォーマンスを表し、ユーザーが最初のトークンを待つ時間と2つの出力トークンの間の平均的な待ち時間を示します。
すべてのユーザーに一貫した体験を保証するためには、従来のサービングシステムと同様に、応答時間の分布を監視することが重要です。 これらの各メトリクスについて、実際の使用パターンをシミュレートする高トラフィック環境でp90とp95の統計値を監視します。詳細は以下のベンチマークのセクションを参照してください。
企業ワークロードの最適化戦略
私たちの推論サービスは、パフォーマンス、信頼性、スケーラビリティに優れています。 このセクションでは、私たちがプロダクションで使用しているテクニックとデザインの選択について詳しく説明します。
スケジュール設定
1つのリクエストに何万ものトークンが含まれるような高トラフィック環境では、LLM推論はメモリ管理に大きな課題をもたらします。 本番環境で実行時メモリ不足エラー(OOM)が発生しないように、GPUメモリに複数のリクエストの状態(KVキャッシュなど)を維持することは慎重に行わなければなりません。 このような場合に、リクエスト間の公平性を保ちつつ、高いパフォーマンスを維持するために使用するテクニックがいくつかあります。
サーバはリクエストを受け取り、非同期にリクエストプールにプッシュします。 そしてリクエストスケジューラは、次のフォワードパスでどのリクエストを走らせるかを決定します。 どのリクエストを実行できるかを決定するために、スケジューラは、現在キューイングされているリクエストのプロパティに加えて、現在実行中のリクエストの現在のGPUメモリ使用率を調べます。
多くの同時リクエストは、与えられたリクエストに対して、すべてのキーと 値の表現をキャッシュする必要があるため、メモリを圧迫します。KVキャッシュを効率的に管理することは、オンライン設定における課題です。私たちは vLLMにインスパイアされたPagedAttentionアルゴリズムを利用しています。簡単に言うと、このアルゴリズムは、断片化を減らすことによって、はるかに効率的なメモリ利用を可能にします。その結果、リクエストスケジューラは、アロケータがメモリ不足にならないという制約のもとで、同時に処理されるリクエストの数をスケールアップすることができます。これにより、より高いリクエストスループットを達成することができますが、 適切な待ち時間を維持するために、最大バッチサイズに上限を設けています。
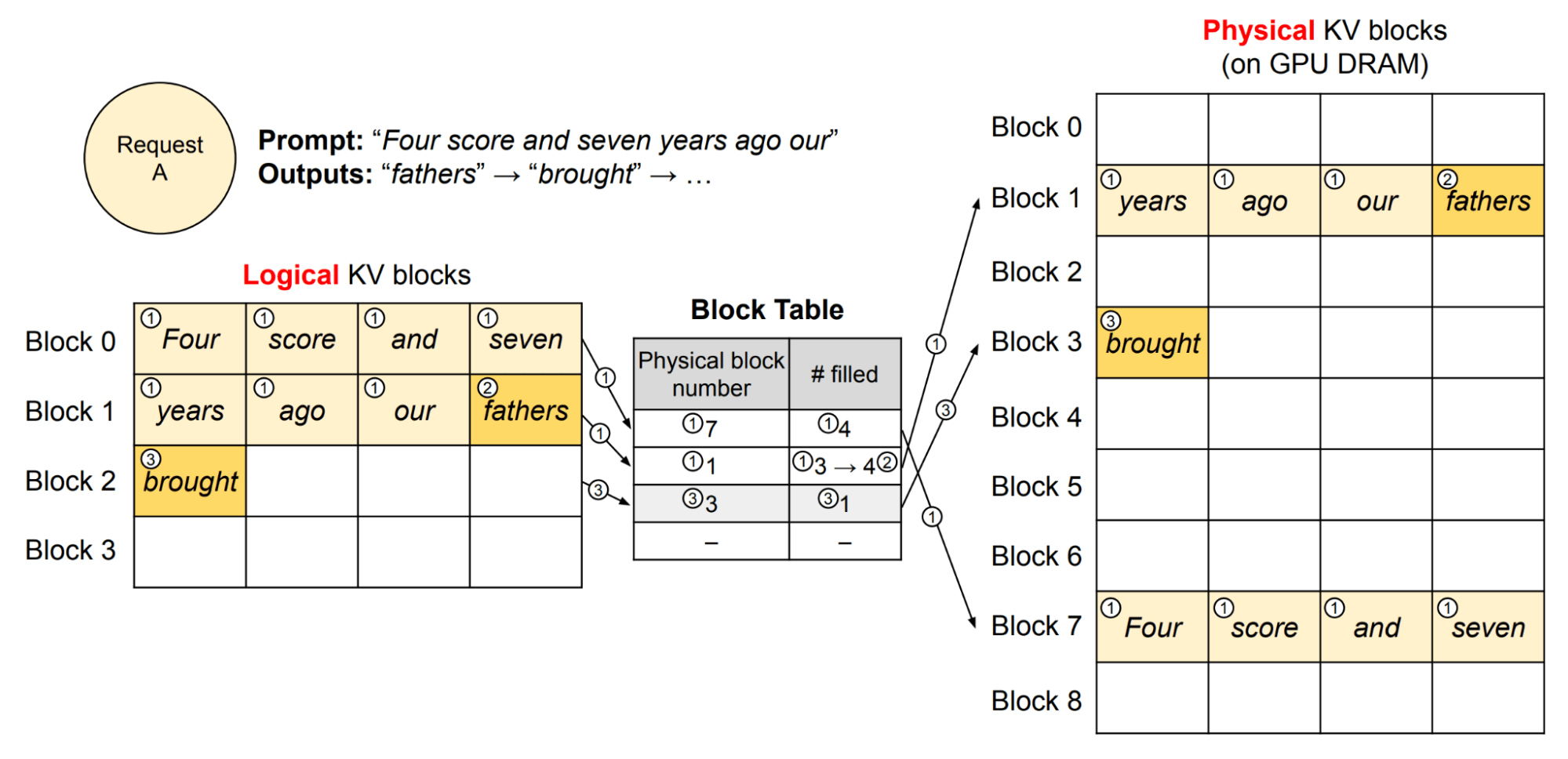
ロードバランサはリクエストを異なるレプリカに均等にルーティングし、 スケジューラはどのリクエストを処理するかを選択します。 この時点で、選択できるスケジューリングアルゴリズムはさまざまで、それぞれにトレードオフがあります。 GPUの使用率を最大にするための1つのオプションは、最大のシーケンス長を持つリクエストを選択し、現在実行中のより短いシーケンスを立ち退かせることです。大きなシーケンス長は、より多くのトークンが並列に処理されるため、テンソルコアのより良い使用率を生み出します。 しかし、これは既存のリクエストに対するレスポンスタイムを低下させ、長いリクエストを不当に優先させることになります。 このような理由から、私たちはリクエストを退去させないポリシーを選択しています。
プリフィルとデコードの重ね合わせ
GPUの計算能力を最大限に活用するには、フォワードパスを実行するときに、できるだけ多くのトークンをまとめてバッチ処理するのが最善です。 これは、多くのトークンが並行して処理されるような長いコンテキストで特に当てはまります。
要求が散発的に入ってくる場合、最初にプレフィルステージのプロンプト処理を行うと、プロンプトの完了を待つアイドル時間が発生するため、デコード速度に支障をきたす可能性があります。 これを回避する戦略として、プリフィルとデコードの段階をオーバーレイして同時進行させる方法があります。 プリフィルとデコードの集約は、同じバッチ内で同時に重ね合わせることができるプリフィルとデコードのトークンの最大数を表す、バッチ化されたトークンの最大数という制約の下で行われます。 この数値は、ワークロードがコンピュートバウンドになり、テンソルコアが飽和するポイントに調整されます。
量子化
私たちは 最近のブログ記事で、 モデルの重みとKVキャッシュを低精度(int8またはfp8)に量子化することで、同じレイテンシでスループットが大幅に向上し、モデルの品質への影響が無視できることを示しました。 この研究とテストにより、私たちは将来のサービスアップデートで、基礎モデルの��量子化されたデプロイメントを提供することを楽しみにしています。
スピード: ユーザーあたりのレイテンシはほぼ同じで、スループットが2.2倍向上 しました。 量子化により、同じレイテンシの予算を維持しながら、同じハードウェアに収まる最大バッチサイズを2倍にすることができます。同じバッチサイズであれば、H100のfp16と比較して、fp8ではトークン生成時間が25~30%短縮されています。
品質:品質への影響を測定するため、量子化モデル(Llama-70B)をmosaicML Gauntlet評価スイートでテストしました。34の多様なベンチマーク(MMLU、BigBench、Arc、HellaSwagを含む)において、品質への影響はごくわずかでした。この結果は近日中に本番環境に出荷され、遅延を維持しながら高いバッチサイズでサービスを提供したり、低いバッチサイズ領域で遅延を低減したりすることが可能になります。 詳しくはこちらのブログをご覧ください 。
基盤モデルAPI:Databricksのサービスアプローチ
企業ユーザーは、固定されたレイテンシ予算でスループットを最大化することに関心があることがわかりました。その結果、ユーザが最低限達成したいTTFTとTPOTを固定することで、あるレイテンシの目標を保証したいと考えることがよくあります(これがP90とP95の統計です)。サポート可能な最大トラフィックによってこのレイテンシが許容できないほど高くなる場合は、レプリカの数を増やすことを検討します。様々なユースケースをサポートするために、Databricksサービングは基盤モデルAPI (FMAPIs) をサポートしています。 基盤モデルAPIは、トークンごとの支払い(Pay-per-token)とプロビジョニングされたスループットの2つのモードで提供されます。エンタープライズ ユーザーのレイテンシ要件を満たすスループットのしきい値を保証するDatabricksのプロビジョニングされたスループットに移行する前に、トークンごとの支払いを使用していた顧客は数多くいました。この原則は、ユーザーに可能な限り最高のエクスペリエンスを提供するエンタープライズ推論製品を設計する際の主な推進力となっています。
トークンごとの支払いでは、ハードウェアを最も効率的に使用するために、待ち時間の制約下で高いスループットを提供するように最適化します。 上述の設定に基づき、あるレイテンシ閾値までは、メモリバウンド最適化よりもコンピュートバウンド最適化を重視します。 高バッチサイズでベンチマークを最適化して公開することで、高トラフィックでリアルタイムに動作するシステムでユーザーが目にするレイテンシーをより適切にシミュレートできます。
コストの観点からは、長期的にGPUをあまり活用せず、低いバッチサイズで実行するのは手頃ではありません。 可用性の観点からは、私たちのシステムが可能な限り多くの需要に対応し、毎回レプリカを増やすのは現実的ではないため、スケーリングを継続できるように、GPUあたりのスループットをユーザーができるだけ多く得られるようにすることも重要です。 したがって、企業顧客の負荷と、これらの企業顧客のそれぞれが高いスループットを求めていることを考えると、ユーザーリクエストは、効率的に多くのリクエストを同時に処理できるシステムに多重化されなければなりません。
セキュリティ、信頼性、可用性
私たちは、お客様のAIワークロードが確実に保護され、信頼されるよう配慮しています。 このセクションでは、トークンごとの支払いの基盤モデルのエンドポイントに組み込まれたセキュリティと信頼性の機能の一部を紹介します。
セキュリティ:各ワークスペースの基盤モデルエンドポイントへの柔軟なアクセス制御を提供します。管理者は、エンドポイントのレート制限を調整して、組織内のユーザーから許可されるトラフィック量を制御できます。エンドポイントの作成者は、配備されたエンドポイントにアクセスできるユーザーを制御できます。各エンドポイントを経由するトラフィックも顧客のクラウド内に完全に格納されるため、信頼できる環境からデータが流出することはありません。各リクエストは認証され、論理的に分離され、暗号化されます。また 、悪用や危害の防止、検出、軽減以外の目的で顧客データが保存されたり、アクセスされたりしないようにします。保存される場合、顧客データは最大30日間保持され、顧客のワークスペースと同じリージョンに保存されます。プロビジョニングされたスループットは、AWSとAzureにおいてHIPAAに準拠しており、近日中に準拠レベルが追加される予定です。
信頼性: 私たちは、お客様が私たちのエンドポイントから最高のパフォーマンスを得られるように、基盤�モデルAPIに頻繁に新しいリリースを行います。私たちのサービスが信頼できるものであることを保証するために、私たちのエンジニアリングチームは、リリースごとに実行される回帰テストのスイートを設計し、私たちのデプロイパイプラインは、ダウンタイムなしでアップデートがロールアウトされることを保証するために構築されています。これらの回帰テストにより、新しいリリースでモデルの品質が低下することはなく、アップデートのたびに一貫したパフォーマンス目標を維持することができます。私たちのデプロイパイプラインは、リグレッションをできるだけ早く検出できるように、複数段階の健全性を介した方法でアップデートをロールアウトするように開発されています。各デプロイは、複数のノードに分散されたレプリカ上で実行され、ノードの障害に直面してもアップタイムを保証します。さらに、本番稼動中のエンドポイントでエラーが検出されないことを確実にするため、監視ツール群も構築しています。エラー率やリクエストの待ち時間などの指標により、エンドポイントがフル稼働していることを確認できます。
ベンチマーク結果
以下のベンチマーク手順を使用して、現実的な本番環境下でシステムをプロファイリングします:
- 高トラフィック: 同時にシステムにアクセスするさまざまな数の同時ユーザーをシミュレートします。これにより、低トラフィック時のパフォーマンスと、リクエストが殺到した場合のパフォーマンスを把握することができます。
- 不規則な間隔で投稿するユーザー: 最初の立ち上げ期�間では、ユーザーは1秒に1人の割合で生成されます。これは、連続的なバッチ機能を行使するために、 ユーザーが同じ規則でリクエストを送らないようにするためのオフセットを生成します。
- 異なるリクエスト特性: 長いプロンプトと短い世代をシミュレートします。これらは実運用で最も一般的なユースケース(RAG、要約など)であることが理由です。プロンプトは、平均入力トークン長と指定された標準偏差でプロンプトの長さをサンプリングすることでランダム化されます。
エンドツーエンドのパフォーマンスメトリクスに加え、プリフィルとデコード固有のメトリクスも表示します。 ベンチマークは、8x H100システム上で16ビット精度で実行されました。 エンドツーエンドのパフォーマンスをベンチマークすることで、システム全体を動かし、他の推論プロバイダーとの比較に役立ちます。 プリフィルとデコードのメトリクスも表示され、ストリーミングパフォーマンスの現実的な感覚を提供します。
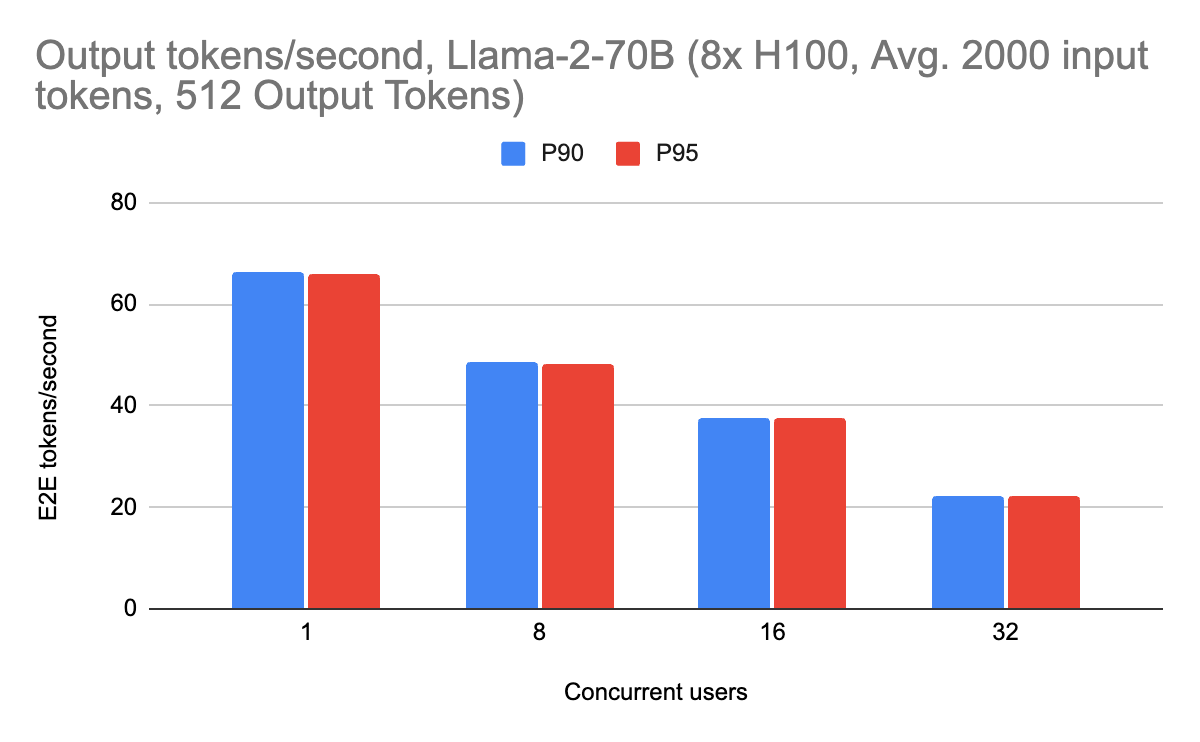
Llama-2-70Bの場合、1ユーザーあたり1秒間に最大69の出力トークンを達成することができ、約700の入力トークン(約2、3段落のテキスト)で1秒間に165のエンドツーエンドトークンを達成することができます。 システム全体をプロファイリングするためにエンドツーエンドの性能をベンチマークし、個々のコンポーネントをベンチマークするためにプリフィルとデコードのメトリクスを分割します。
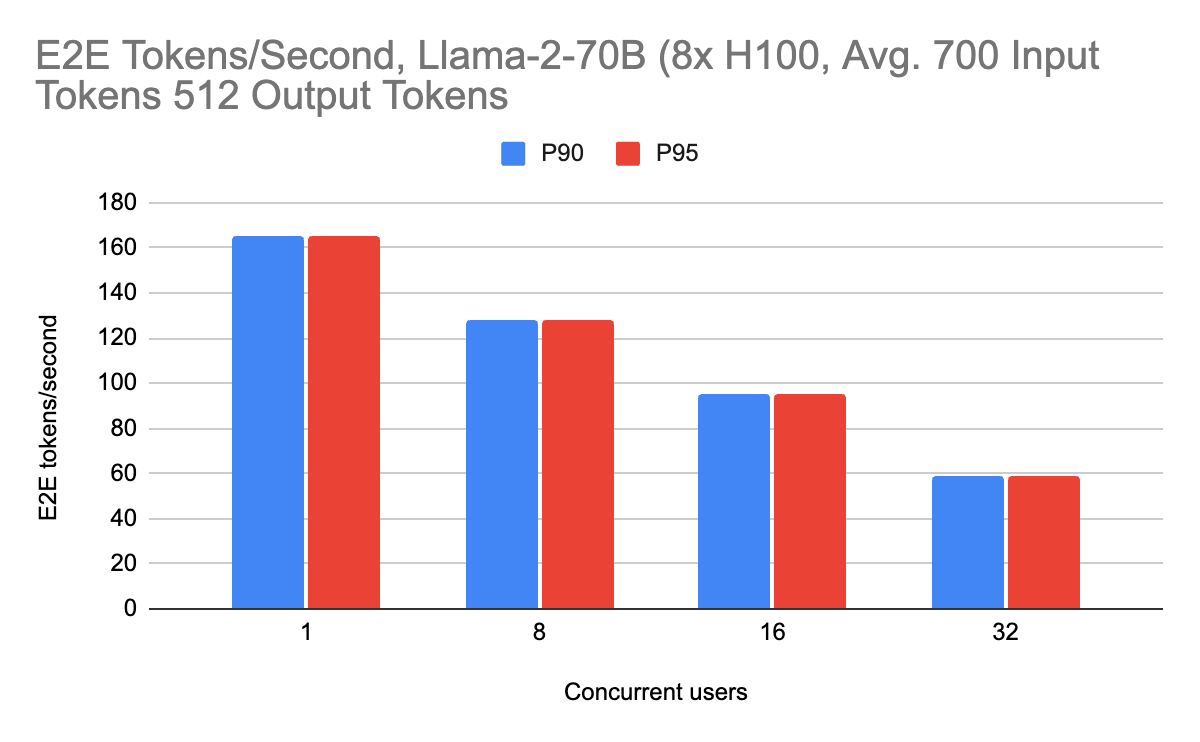
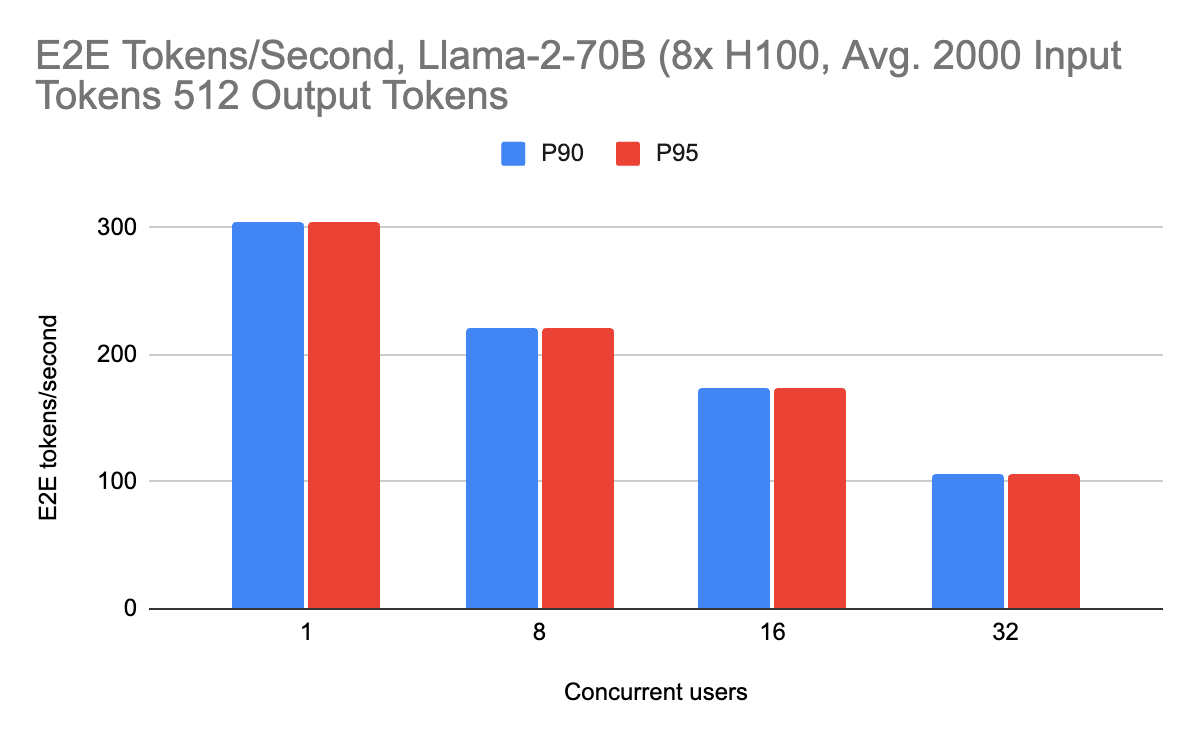
ユーザーが経験するストリーミングパフォーマンスは、ストリーミング出力時の1秒あたりの出力トークン(デコードパフォーマンス)で与えられます。 これらの数字を以下に示します:
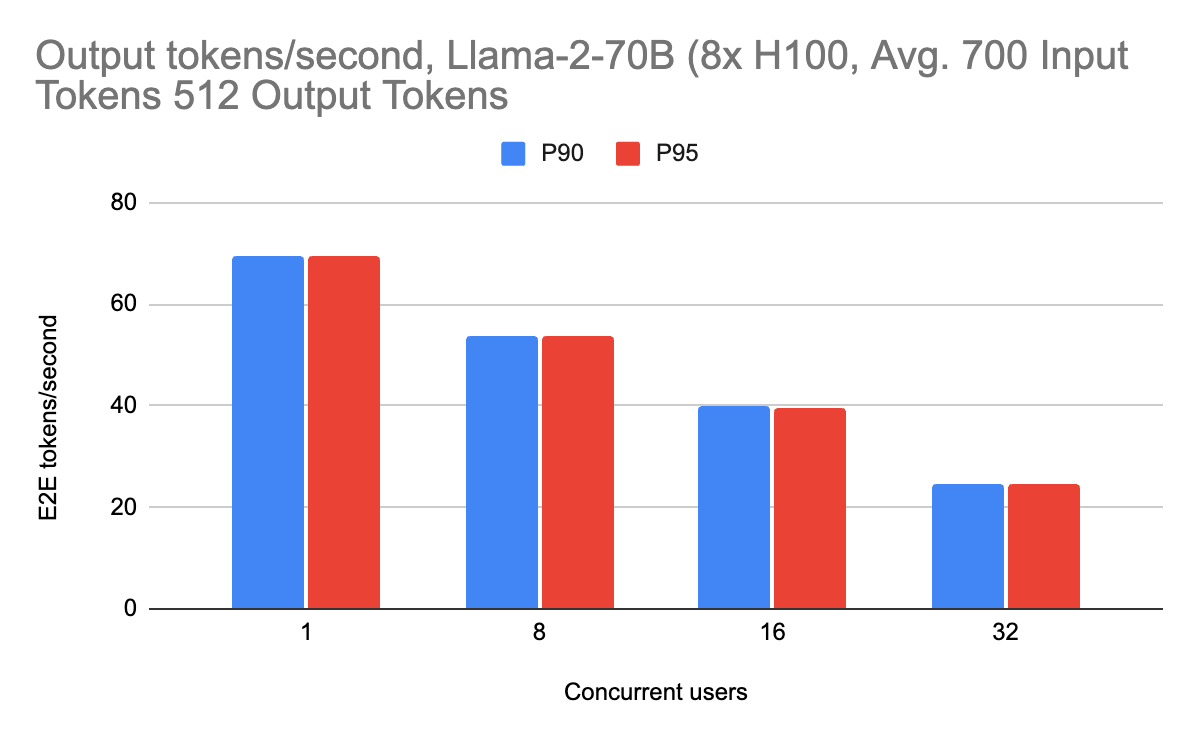
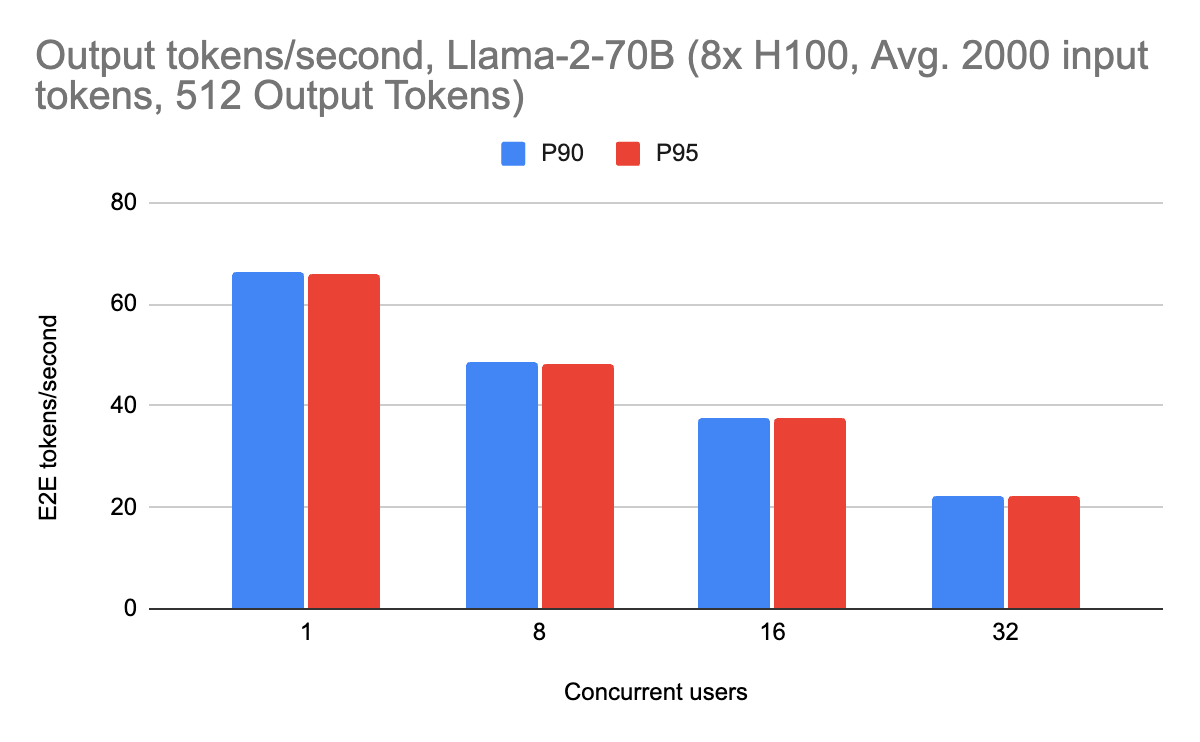
ストリーミング性能は、ピーク時で毎秒約70の出力トークンを達成しました。 また、(RAGワークロードに適した)2000個の入力トークンを含め、さまざまなワークロードで一貫して高い性能を発揮しています。 長いコンテキストのリクエストでも、オーバーレイのためにサーバーが遅くなることはなく、一貫して高いパフォーマンスを示しています。 これは、ユーザーが入力プロンプトの規模を拡大する際に特に重要です。
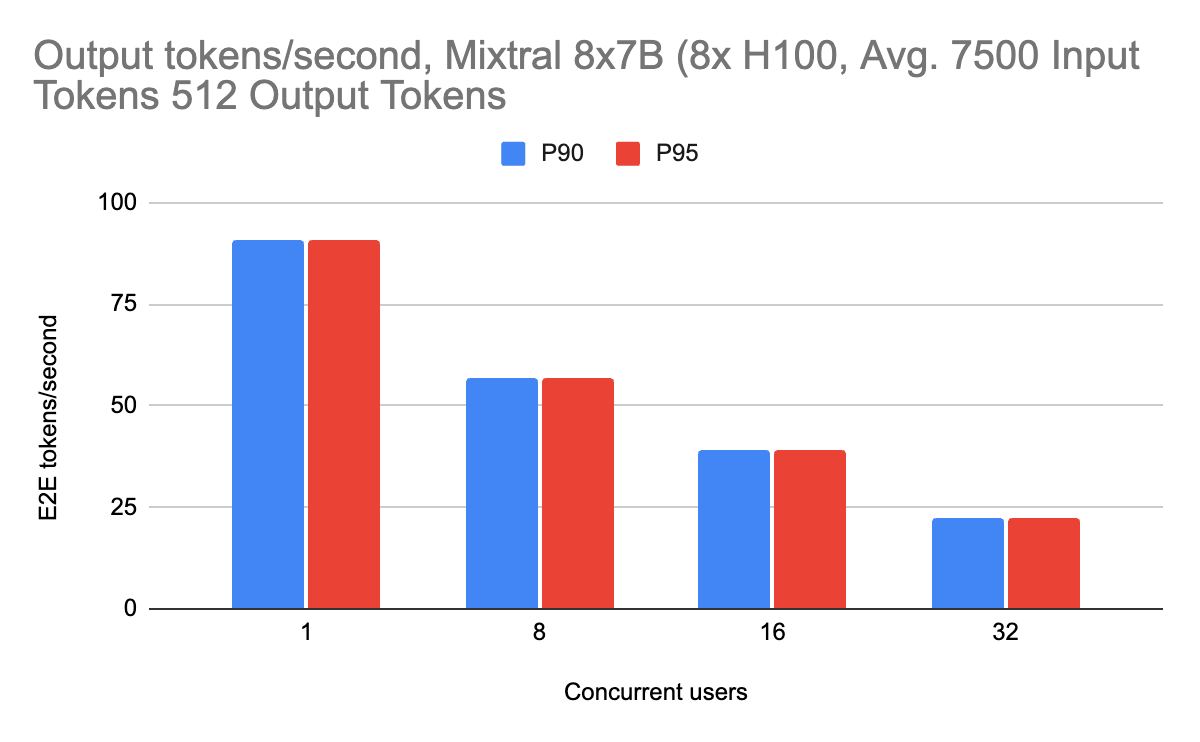
推論性能は、専門家混合モデルでもうまく機能します。 このモデルアーキテクチャは、スパース性を利用することで、推論時間を大幅に増加させることなく、パラメータ数を拡張することができます。 トークンがエキスパート間で適切に負荷分散されていない場合でも、GPU間で均等に仕事が分配されるように、(エキスパート並列処理ではなく)テンソル並列でこれらのモデルを提供することを選択します。 入力トークンの長さは4000と7500の2種類でベンチ�マークを行いました。
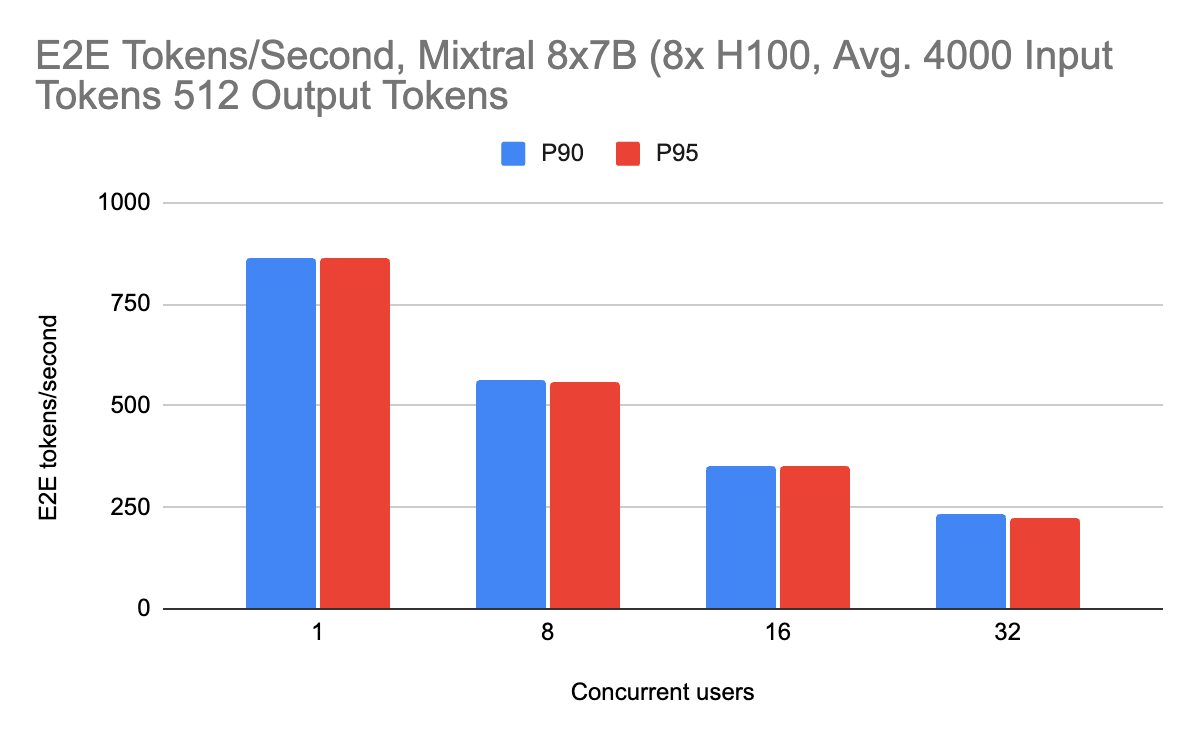
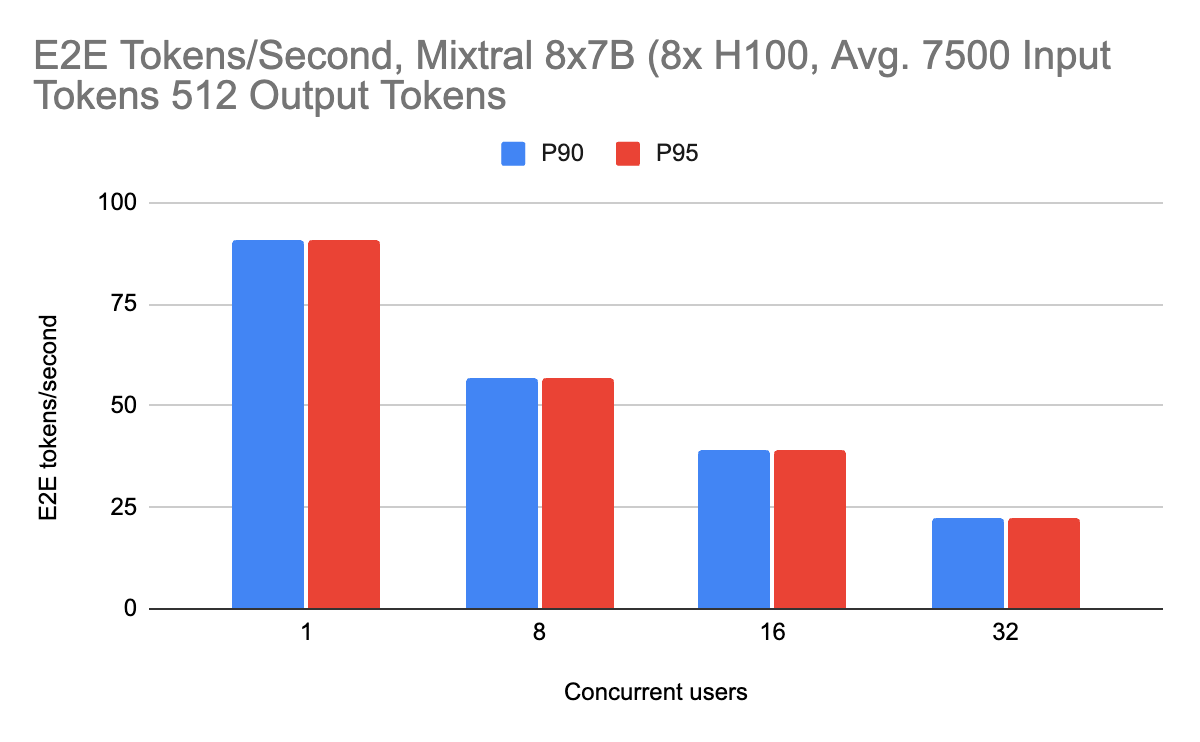
出力長に対するミクスチャーの性能も、入力長が長くなるにつれて、最小限の性能ペナルティでうまくスケールします。
まとめと次への展望
このブログポストでは、オンラインサービングの複雑さを探求し、当社の製品が企業向けLLM推論のトップクラスのソリューションである理由を明確に説明します。 TRT-LLMをバックエンドとして統合したおかげで、推論エンドポイントは目覚ましいスピードアップを遂げました。 現在の基盤モデルのエンドポイントは、以前のAPIに比べて1.5倍から1.7倍の速度で動作しています。 さらに、FP8精度やKV-Cacheの共有など、さらなる進化を間もなく導入し、これらのAPIのさらなる強化をお約束します。
さらに、堅牢なセキュリティ、揺るぎない信頼性、安定した可用性といった、企業のニーズに応える推論ソリューションの組み込み機能を強調できることを誇りに思います。 これらの要素により、当��社の製品は高速で効率的であるだけでなく、企業での使用において安全で信頼できるものとなっています。 今後もLLM推論の分野で革新とリードを続けていきますので、ご期待ください。
もちろん、Databricksの推論サービスを体験していただくのが一番です。Databricksのお客様 であれば、AI Playground (現在パブリックプレビュー中)を使ってすぐに実験を始めることができます。 ログインして、左のナビゲーションバーの機械学習の下にあるPlaygroundの項目を見つけるだけです。まだDatabricksを ご利用でない方は、無料トライアルにご登録ください!