
このブログ投稿では 、Fine-Grained RLHFについて説明 します。Fine-Grained RLHFは、密度と多様性という2つの異なる方法できめ細かい報酬関数から学習とトレーニングを可能にするフレームワークです。 密度とは、全てのセグメント(例えば文章)が生成された後に報酬を提供することで達成されます。�多様性は、異なるフィードバックタイプ(例えば、事実誤認、無関係、情報の不完全性)に関連する複数の報酬モデルを組み込むことによって達成されます。
粒度の細かい報酬とは?
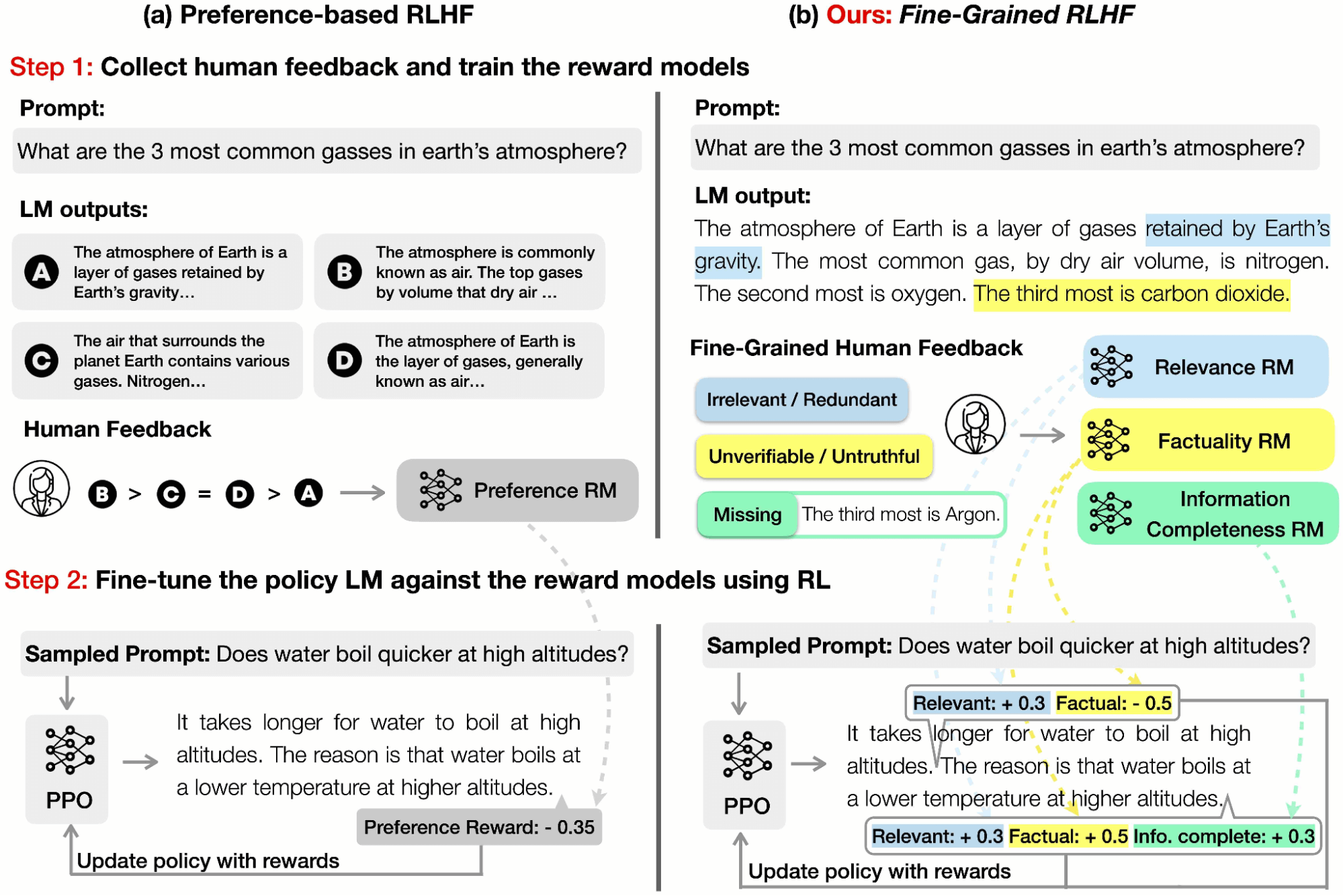
RLHFにおけるこれまでの研究は、 言語モデル(LM)出力の全体的な品質に関する人間の嗜好を収集することに重点を置いてきました。 しかし、このような全体的なフィードバックは限られた情報しか提供しません。 NeurIPS 2023で発表した論文では、人間のフィードバック(例えば、どのサブセンテンスが無関係か、どのセンテンスが真実でないか、どのセンテンスが有害か)を明示的な学習信号として導入しました。
RLHFの報酬関数とは、テキストを受け取り、そのテキストがどれだけ「良い」かを示すスコアを出力するモデルのことです。 上の図に見られるように、従来�、全体論的選好に基づくRLHFでは、「良い」の定義に特別なニュアンスや多様性はなく、テキスト全体に対して単一の報酬が与えられます。
対照的に、私たちの報酬は2つの面できめ細かいものです:
(a) 密度:OpenAIの「ステップバイステッププロセスの報酬」に似ています。 私たちは、このアプローチが全体的なフィードバックよりも情報量が多く、強化学習(RL)に効果的であることを発見しました。
(b)多様性:異なるタイプのフィードバック(事実の不正確さ、無関係性、情報の不完全性など)を捉えるために、複数の報酬モデルを採用しました。 興味深いことに、これらの報酬モデルは互いに補完しあい、また競合しあっています。 報酬モデルの重みを調整することで、異なるタイプのフィードバック間のバランスを制御し、特定のニーズに応じてタスクごとにLMを調整することができます。 例えば、短く簡潔な出力を好むユーザーもいれば、長く詳細な回答を求めるユーザーもいるでしょう。
人間のアノテーターから逸話的に得られたフィードバックは、全体的な嗜好を使用するよりも、データをきめ細かくラベリングする方が簡単だということでした。 その理由は、判断が何世代にもわたって行われるのではなく、局所的に行われるからでしょう。 これにより、人間のアノテーターの認知的負荷が軽減され、よりクリーンで、アノテーター間の一致度が高い嗜好データが得られます。 言い換えれば、全体的な嗜好よりも、きめ細かいフィードバックの方が、単価あたりの質の高いデータが得られる可能性が高いということです。
私たちは、この方法の有効性を検証するた�めに、2つの主要なタスクのケーススタディを実施しました。
タスク 1:解毒
解毒(detoxification)のタスクは、モデル生成における毒性(toxicity)を減らすことを目的としています。 毒性測定にはPerspective APIを使用しました。 0(毒性なし)から1(毒性あり)の間の毒性値を返します。
私たちは2種類の報酬を比較しました:

(a) (非)毒性に対する全体的報酬:1-Perspective(y)を報酬として使用。
(b)(非)毒性に対する文レベルの(細かい)報酬:モデルが完全なシーケンスを生成する代わりに、各センテンスを生成した後にAPIに問い合わせます。 生成された各文に対して、-Δ(Perspective(y))を文の報酬として使用します(つまり 現在の文の生成から毒性がどれだけ変化したか)。
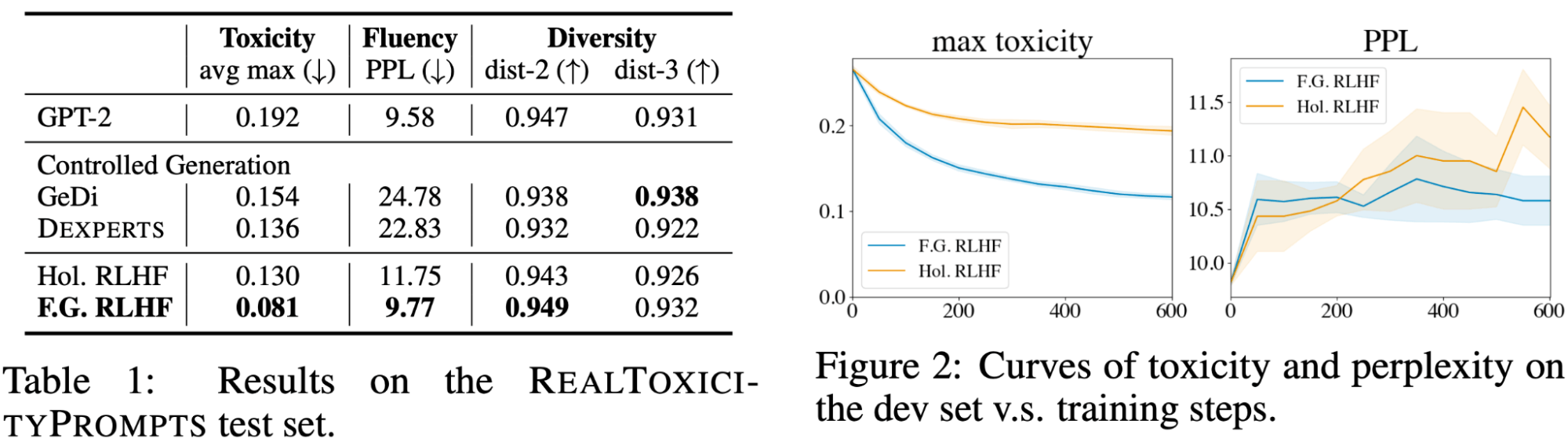
表1は、文レベルのきめ細かい報酬を持つ我々のFine-Grained RLHFが、同程度の多様性を維持しながら、すべての手法の中で最も低い毒性と複雑さを実現したことを示しています。 図2は、より密度の高い細かい報酬からの学習は、全体的な報酬よりもサンプル効率が高いことを示しています。 1つの説明として、きめ細かい報酬は有害なコンテンツがある�場所に配置されるため、テキスト全体に対するスカラー報酬と比較して、より強い学習シグナルとなります。
タスク2:長文問題の解答
私たちは QA-Feedbackという長文質問応答のデータセットを収集しました。QA-Feedbackは、曖昧な事実に基づいた質問に答えることに焦点を当てたデータセットであるASQAに基づいています。
きめ細かい人間のフィードバックには3つのタイプがあり、それぞれにきめ細かい報酬モデルをトレーニングしました:
1:無関係、繰り返し、支離滅裂(rel.) 報酬モデルはサブセンテンスの密度レベルを持ち、各サブセンテンスのスコアを返します。 そのサブセンテンスが無関係、繰り返し、または支離滅裂である場合、報酬は-1され、そうでない場合、報酬は+1されます。
2:不正確な、あるいは検証不可能な事実(fact.) 報酬モデルは文の密度レベルを持ち、各文に対してスコアを返します。 もしその文章に事実誤認があれば、報酬は-1され、そうでなければ報酬は+1されます。
3:不完全な情報(comp.) 常習モデルでは、回答が完全で、問題に関連する参照パッセージのすべての情報を網羅しているかどうかをチェックします。 この報酬モデルでは、回答全体に対して1つの報酬が与えられます。
きめ細かな人間評価
我々のFine-Grained RLHFを以下のベースラインと比較しました:
SFT: RLHF実験の初期ポリシーとして使用される教師ありファインチューニングモデル(1K学習例で学習)。
Pref.RLHF: 全体的報酬を使用するベースラインRLHFモデル。
SFT-Full: ASQAから提供された人間の手による全トレーニング例の回答を用いてLMを微調整し、このモデルをSFT-Fullと呼びます。各ゴールドレスポンスのアノテーションには15分かかり(ASQAによる)、我々のフィードバックアノテーション(6分)よりもはるかに長い時間がかかります。

人間による評価では、「Fine-Grained RLHF」が「SFT」や「選好型RLHF」をすべてのエラータイプで上回り、「RLHF」(選好型とFine-Grained RLHFの両方)が事実誤認を減らすのに特に効果的であることが示されました。
LM の動作のカスタマイズ

関連性報酬モデルの重みを変更し、他の2つの報酬モデルの重みを固定することで、LM回答の詳細さと長さをカスタマイズすることができました。 図Xでは、それぞれ異なる報酬モデルの組み合わせで訓練された3つのLMの出力を比較しました。
きめ細かい報酬モデルは、互いに補完し合い、競合し合います。
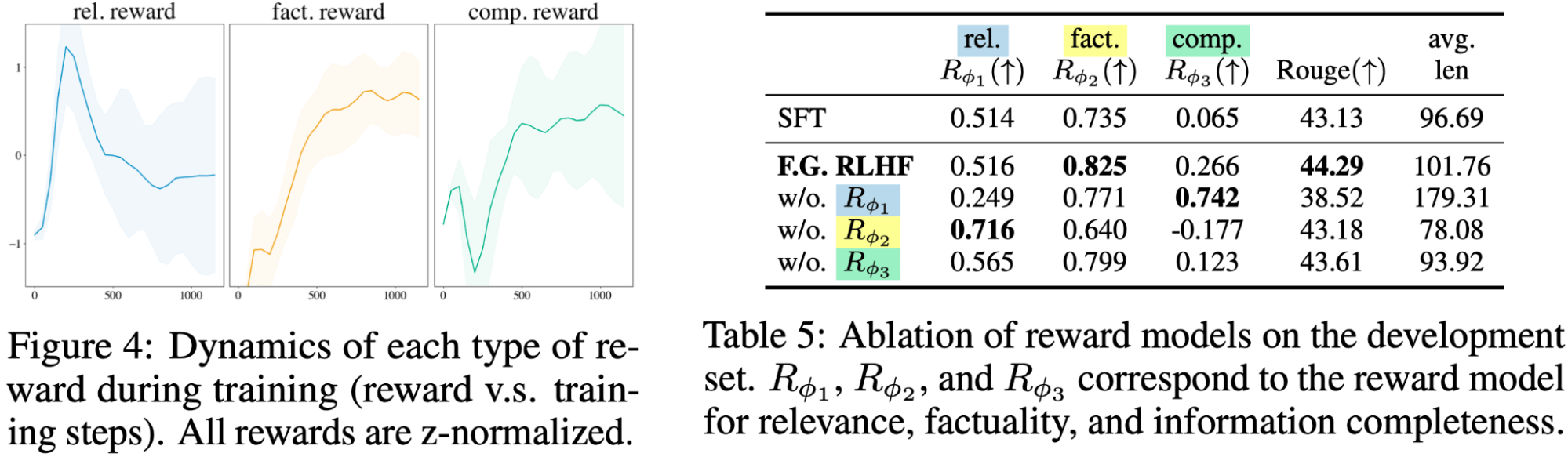
関連性RMはより短く簡潔な回答を好み、情報完全性RMはより長く情報量の多い回答を好みます。 そのため、トレーニング中はこの2つの報酬が互いに競い合い、やがて均衡を保つようになります。 一方、Factuality RMは、回答の事実の正しさを継続的に改善します。 最後に、報酬モデルを1つでも削除すると、パフォーマンスが低下します。
私たちは、きめ細かな報酬の有効性を実証したことで、他の研究者がRLHFの基礎となる基本的な全体的選好から脱却し、RLHFの人間的フィードバック要素の探求にもっと時間を費やすようになることを願っています。私たちの出版物を引用したい場合は、以下を参照してください。