
Original: Handling "Right to be Forgotten" in GDPR and CCPA using Delta Live Tables (DLT)
翻訳: junichi.maruyama
ここ数十年でデータ量は爆発的に増加し、各国政府は個人データに対する個人の保護と権利を強化するための規制を設けています。General Data Protection Regulation(GDPR)とカリフォルニア州消費者プライバシー法(CCPA)は、企業が遵守しなければならない最も厳しいプライバシーとデータセキュリティの法律の1つです。他のデータ管理およびデータガバナンスの要件の中でも、これらの規制は、顧客について収集した個人を特定できる情報(PII)を、顧客の明確な要求に応じて永久的かつ完全に削除することを企業に求めています。この手続きは、「忘れられる権利」とも呼ばれ、指定された期間内(例えば、1暦月以内)に実行されなければならない。このシナリオは難しいタスクのように聞こえるかもしれませんが、前回のブログでも紹介したDelta Lakeを利用することで十分に対応できます。この記事では、Delta Live Tables (DLT)を使用して、データレイクハウスで「忘れられる権利」の要件を処理するさまざまな方法を紹介します。デルタテーブルはデータをテーブルに格納する方法ですが、デルタライブテーブルはデルタテーブルを作成し、最新の状態に保つなど、管理する宣言的なフレームワークです。
"忘れられる権利 "を実現するためのアプローチ
「忘れられる権利」を実現する方法はさまざまですが(例:匿名化、仮名化、データマスキング)、最も安全な方法は、やはり完全な抹消です。長年にわたり、不完全または不正に実施された匿名化処理により、個人の再識別が行われた事例がいくつかあります。実際には、再識別のリスクを排除するためには、個人の記録を完全に削除する必要がある場合が多い。そのため、この記事では、匿名化技術を適用する代わりに、ストレージから個人を特定できる情報(PII)を削除することに焦点を当てます。
データレイクハウスでのポイント削除
ACID transactions とdeletion vectorsを使用して大規模なデータレイクで効率的なポイント削除をサポートし提供するDelta Lakeテクノロジーの導入により、消費者のGDPR/CCPAリクエストに対応してPIIデータを見つけ、削除することが容易になりました。ポイント削除を加速するために、Delta Lakeは、Z-orderやbloom filtersによるdata skippingなど、多くの最適化を内蔵し、読み込む必要のあるデータ量を削減します(例:DELETE操作中に使用するフィールドのZ-orderなど)。
"忘れられる権利 "を実現するための課題
組織内のデータランドスケープは大規模になり、機密情報を保存しているシステムが多数存在することがあります。つまり、すべてのソースシステム、Deltaテーブル、クラウドストレージ、および機密データを長期間保存する可能性のあるその他のシステム(ダッシュボード、外部アプリケーションなど)からデータを永久に削除する必要があります。
削除がソースで開始された場合、メダリオンアーキテクチャの後続のすべてのレイヤーに伝搬されなければならない。ソースで開始された削除を処理するには、Delta Live Tablesのchange data capture (CDC)が便利です。しかし、Delta Live Tablesはパイプライン内のデルタテーブルを管理し、現在はChange Data Feedをサポートしていないため、CDCのアプローチは、テーブルのバージョン間の行レベルの変更を追跡するために、すべてのレイヤーでエンドツーエンドで使用することはできません。次のセクションで紹介するように、別の技術的なソリューションが必要です。
Delta Lakeはデフォルトで、削除されたレコードを含むテーブルの履歴を30日間保持し、「time travel」やロールバックに利用できるようにしています。しかし、以前のバージョンのデータを削除しても、データはクラウドストレージに保持されたままです��。そのため、ファイルを永久に削除するためには、Deltaテーブルに対してVACUUMマンドを実行する必要があります。デフォルトでは、タイムトラベル機能を7日間に短縮し(設定可能)、当該データの履歴バージョンもクラウドストレージから削除します。デルタテーブルが更新されてから24時間以内にメンテナンスタスクの一部としてVACUUMコマンドが自動的に実行されるため、この点ではデルタライブテーブルの利用が便利です。
さて、メダリオンアーキテクチャのすべてのレイヤーが規制に準拠するために、「忘れられる権利」の要件を実装し、上記の課題を解決するためのさまざまな方法を検討しましょう。
モダンアナリティクスへのコンパクトガイド

"忘れられる権利 "を実現するための技術的アプローチ
Solution 1 - ブロンズのストリーミングテーブルとその後のマテリアライズドビュー
「忘れられる権利」を扱うための最も簡単な解決策は、DELETEコマンドを実行することで、すべてのテーブルからレコードを直接削除することです。
一般的なメダリオンアーキテクチャでは、ブロンズテーブルへのソースデータの取り込みは、単純な変換を伴うアペンドオンリーです。これは、変換をインクリメンタルに適用し、状態を保持するストリーミングテーブルにぴったりである。また、ストリーミングテーブルは、Silverレイヤーでデータをインクリメンタルに処理するために使用されることもあります。しかし、ストリーミングテーブルはアペンドクエリー(新しい行がソーステーブルに挿入され、変更されないクエリー)しか処理できないことが課題です。その結果、ストリーミングに使用されるソース・テーブルからレコードを削除することはサポートされず、ストリームを壊してしまいます。

したがって、SilverテーブルとGoldテーブルは、Materialized Viewsを使用して実体化し、Bronzeレイヤーからレコードが削除されるたびに完全な再計算を行う必要があります。Enzyme最適化(解決策2参照)またはskipChangeCommitsオプションを使用して、既存のレコードを削除または変更するトランジションを無視することにより、完全な再計算を回避することができます(解決策3参照)
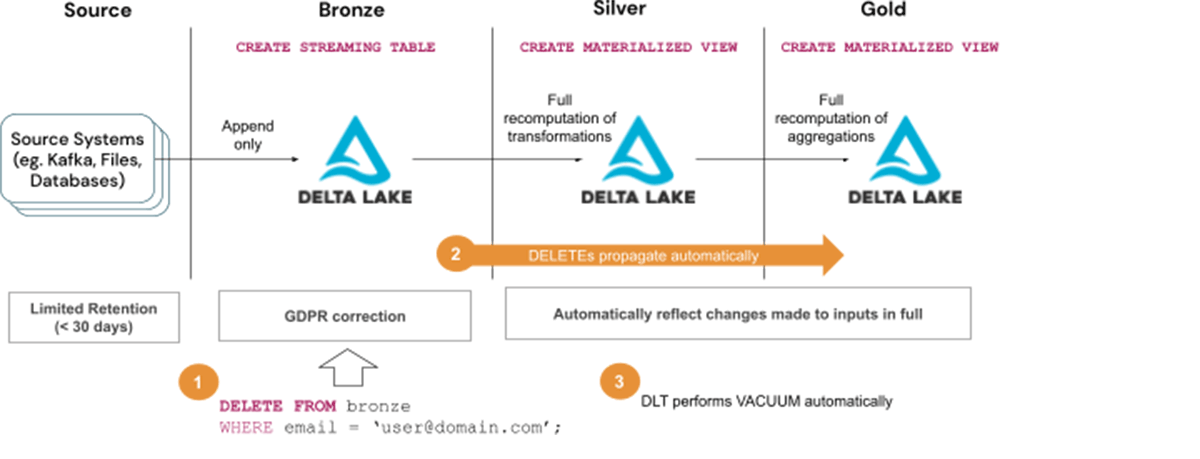
ソリューション1でGDPR/CCPAリクエストに対応するためのステップ:
- Bronzeテーブルからユーザー情報を削除する
- 削除が後続のレイヤー(SilverとGoldのテーブル)に伝搬するのを待つ
- DLTのメンテナンスタスクの一環として、バキュームが自動的に実行されるのを待つ
次のような場合に、ソリューション1の使用を検討する:
- 使用されるクエリのタイプがEnzyme最適化でサポートされていない。サポートされている場合は解決策2を使用します。
- テーブルの完全な再計算を許容する。
上記の解決策の主な欠点は、マテリアライズド・ビューが結果を完全に再計算しなければならないことです。これは、コストや待ち時間の制約から望ましいことではありません。では、DLTの Enzyme 最適化を使ってこれを改善する方法を見てみましょう。
Solution 2 - ブロンズのストリーミングテーブルとEnzymeを使ったマテリアライズドビュー
Enzyme 最適化(プライベートプレビュー中)は、Streaming Tablesを使用することなく、Materialized Viewsへの変更を自動的かつ増分的に計算することにより、DLTパイプラインの待ち時間を改善する。つまり、ブロンズテーブルで実行された削除は、パイプラインを壊すことなく、後続のレイヤーにインクリメンタルに伝搬されます。Enzymeを有効にしたDLTパイプラインは、結果を具体化するために必要なMaterialize Viewの行のみを更新するため、インフラストラクチャのコストを大幅に削減することができます。
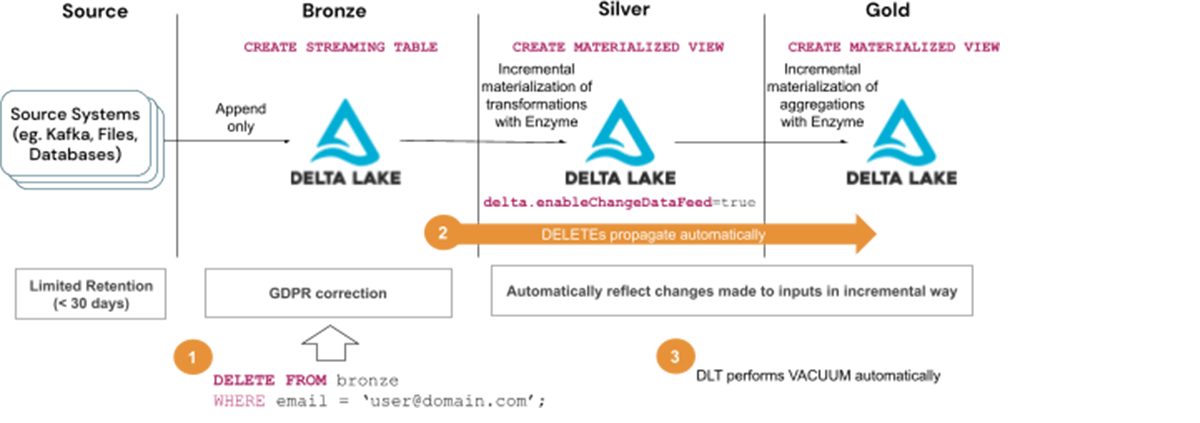
ソリューション2によるGDPR/CCPA要請への対応ステップ:
- Bronzeテーブルからユーザー情報を削除する
- 削除が後続のレイヤー(SilverとGoldのテーブル)に伝搬するのを待つ。
- DLTのメンテナンスタスクの一部として、Vacuumが自動的に実行されるのを待つ。
以下のような場合に、ソリューション2の使用を検討する:
- 使用されるクエリのタイプはEnzyme最適化*でサポートされている。
- テーブルの完全な再計算は、コストとレイテンシーの要件から許容されない。
*DLT Enzyme 最適化については、本稿執筆時点では、いくつかのシナリオをサポートするプライベートプレビュー版となっています。どのような種類のクエリをインクリメンタルに計算できるかは、時間の経過とともに拡大する予定です。詳細については、Databricksの担当者にお問い合わせください。.
SilverテーブルとGoldテーブルの完全な再計算が必要なソリューション1と比較して、Enzyme最適化を使用することで、インフラストラクチャのコストを削減し、処理待ち時間を短縮することができます。しかし、実行するクエリのタイプがまだEnzymeでサポートされていない場合は、この後のソリューションがより適切かもしれません。
Solution 3 - ブロンズ&シルバーのストリーミングテーブルとその後のマテリアライズド・ビュー
前述したように、ストリーミングに使用されているソーステーブルに対して削除を実行すると、ストリームが壊れます。そのため、SilverテーブルにStreaming Tablesを使用すると、GDPR/CCPAシナリオの処理に問題がある可能性�があります。PIIデータの削除要求がBronzeテーブル上で実行されるたびに、ストリームが壊れてしまうのです。この問題を解決するために、以下に示すような2つの代替アプローチを使用することができます。
Solution 3 (a) - フルリフレッシュ機能の活用
DLTフレームワークは、フルリフレッシュ(選択)機能を提供し、全テーブルまたは選択したテーブルの完全再計算によってストリームを修復することができます。これは、「忘れられる権利」によって、個人情報は要求から1ヶ月以内にのみ削除されなければならず、即時には削除されないことが規定されているため有用です。つまり、完全な再計算を1ヶ月に1回に減らすことができるのです。さらに、Bronzeテーブルでpipeline.reset.allow = falseを設定し、インクリメンタル処理を継続させることで、Bronzeレイヤーのフル再計算を完全に回避することができます。
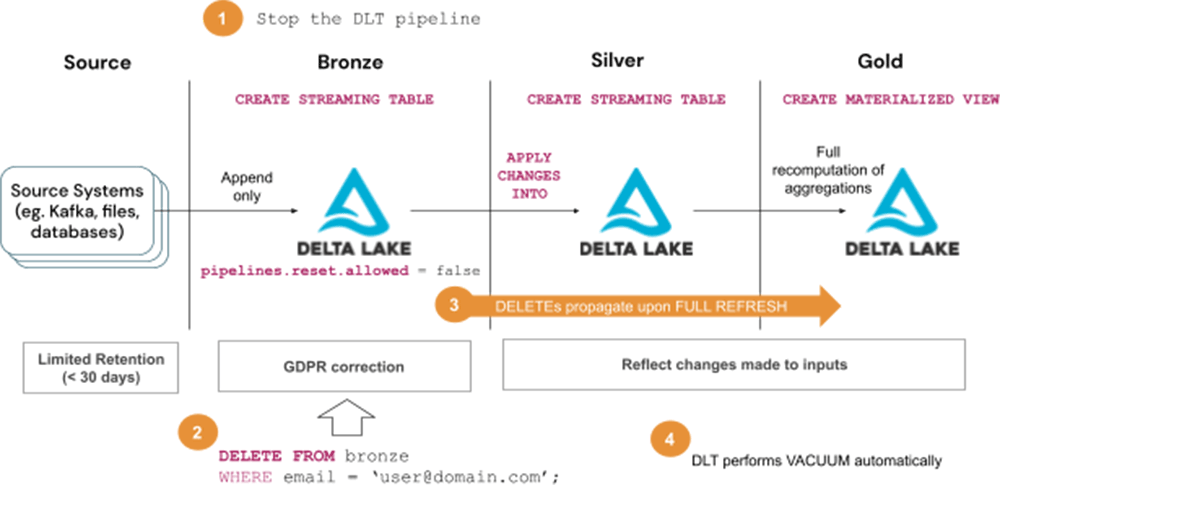
ソリューション3(a)によるGDPR/CCPAリクエストへの対応手順~月1回程度の実行:
- DLTパイプラインの停止
- Bronzeテーブルからユーザー情報を削除する
- パイプラインをフルリフレッシュ(選択)モードで開始し、削除が後続のレイヤー(Silver、Goldテーブル)に伝搬するのを待つ。
- DLT のメンテナンスタスクの一部として、Vacuum が自動的に実行されるのを待ちます。
以下の状況の時に、解決策3(a)を検討をする。:
- 使用されているクエリのタイプはEnzyme最適化ではサポートされていない。サポートされている場合は解決策2を使用する。
- Silverテーブルの完全な再計算は、1ヶ月に1回実行でもよい。
Solution 3 (b) - skipChangeCommitsオプションの活用
上記のフルリフレッシュの代わりに、skipChangeCommitsオプションを使用すると、テーブルの完全な再計算を回避することができます。このオプションを有効にすると、ストリーミングはファイル変更操作を完全に無視し、ソースとして使用されているテーブルで変更(DELETEなど)が検出された場合でも失敗しません。この方法の欠点は、変更が下流のテーブルに伝わらないことで、DELETEは後続のレイヤーで個別に実行する必要があります。また、APPLY CHANGES INTO文を使用するクエリでは、skipChangeCommitsオプションはサポートされていないことに注意してください。
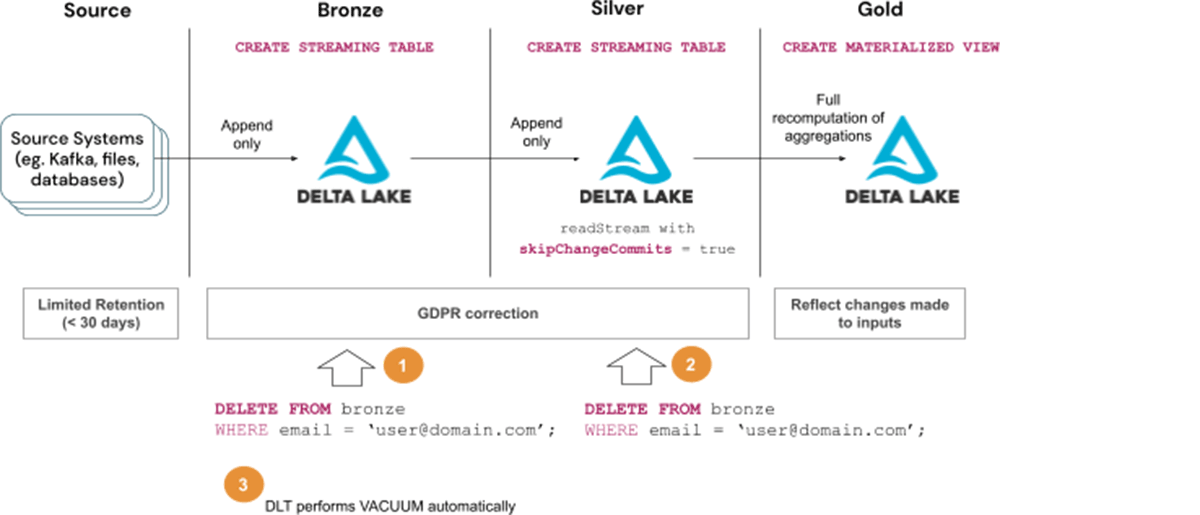
ソリューション3(b)によるGDPR/CCPAリクエストへの対応ステップ:
- Bronzeテーブルからユーザー情報を削除する
- Silverテーブルからユーザー情報を削除し、変更がGoldテーブルに伝搬するのを待つ。
- DLTのメンテナンスタスクの一環として、バキュームが自動的に実行されるのを待つ
以下の場合、解決策3(b)の使用を検討する:
- 使用されているクエリのタイプは、Enzyme最適化ではサポートされていない。サポートされている場合は解決策2を使用してください。
- Silverテーブルの完全な再計算は認められません。
- Silverレイヤーのクエリがアペンドモードで実行されている(つまり、APPLY CHANGES INTOステートメントを使用していない)
解決策3(a)は、テーブルの完全な再計算を避けることができるので、APPLY CHANGES INTO文を使用しない場合は、解決策3(a)を優先して使用する必要があります。
Solution 4 - PIIデータを他のデータから切り離す
すべてのテーブルからレコードを削除するよりも、正規化して別のテーブルに分割した方が効率的な場合があります:
- すべての機密データを含むPIIテーブル(例:customerテーブル)と、surrogate key(例:customer_id)で識別可能な個々のレコード
- 機密データではなく、他のテーブルを介さずに個人を特定する能力を失ったその他のすべてのデータ
この場合、GDPR/CCPAの要求への対応は、PIIテーブルからレコードを削除するだけと簡単です。残りのテーブルはそのまま残ります。テーブルに格納されている代理キー(図ではcustomer_id)は、個人を特定したりリンクしたりするために使用できないので、データはまだMLや一部の分析に使用することができます。
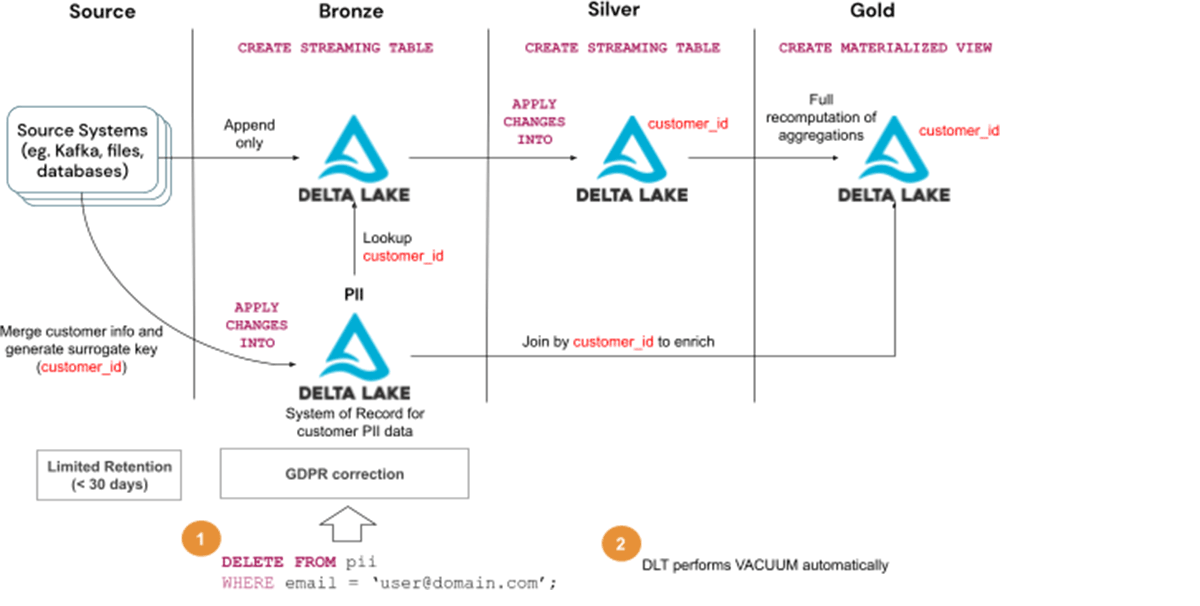
GDPR/CCPAの要請への対応ステップ:
- PIIテーブルからユーザー情報を削除する
- DLTのメンテナンス作業の一環として、Vacuumが自動的に実行されるのを待つ
以下のような場合に、ソリューション4の使用を検討します:
- テーブルの完全な再計算は許されない
- 新しいデータモデルを設計している
- 多くのテーブルを管理し、システム全体を規制に準拠させるためのシンプルな方法が必要である。
- 規制を遵守しつつ、データの大半を再利用したい(例:MLモデルの構築)
このアプローチは、データセットを構造化して、規制の範囲を限定しようとするものです。これは、新しいシ�ステムを設計する際に最適なオプションであり、GDPR/CCPAの要求を処理するための最も優れた全体的なソリューションと言えるでしょう。ただし、PII情報は必要なときに別のテーブルから取得(結合)する必要があるため、プレゼンテーション層が複雑化します。
まとめ
個人を特定できる情報(PII)を処理・保存する企業は、GDPR、CCPAなどの法的規制を遵守する必要があります。この記事では、Delta Live Tables (DLT)を使用して、当該規制の要件である「忘れられる権利」を扱うためのさまざまなアプローチを紹介しました。以下に、どのソリューションが最も適しているかを判断するためのガイドとして、提示されたすべてのソリューションのサマリーをご覧ください。
| Solution | Consider using when |
|---|---|
|
1 - ブロンズ用のストリーミングテーブルとその後のマテリアライズドビュー |
|
|
2 - ブロンズのストリーミングテーブルとEnzymeを使ったマテリアライズドビュー |
|
|
3 (a) フルリフレッシュ - ブロンズとシルバーのストリーミングテーブルとその後のマテリアライズドビュー |
|
|
3 (b) skipChangeCommits - ブロンズ&シルバーのストリーミングテーブルとその後のマテリアライズド・ビュー |
|
|
4 - PIIデータを他のデータから切り離す |
|
