Databricksによる建築製品業界の異常検知のための機械学習の活用

序章
異常検知は多様な業界で重要な役割を持ち、特に製造業での異常検知応用が注目されています。本ブログでは異常検知の実例をDatabricksで紹介します。 シミュレーションされたプロセスサブシステムの健全性監視を中心としたケーススタディを探求します。 さらに、主成分分析(PCA)のような次元削減手法を掘り下げ、そのようなシステムを本番環境に導入した場合の実際の影響を検証します。 実際の例を分析することで、Databricksをツールとして活用し、このアプローチをどのようにスケールアップして、広範なセンサーデータから価値ある洞察を抽出できるかを実証します。
LPビルディングソ��リューションズ(LP)は、建築業界を形成してきた50年以上の実績を持つ木材製品製造会社です。 北米と南米で事業を展開するLP社は、耐湿性、耐火性、耐シロアリ性を備えた建築製品ソリューションを製造しています。 LP社では、環境・衛生・安全(EHS)データとともに、ペタバイト級の過去のプロセスデータが長年にわたって収集されてきました。 このような大量の履歴データは、オンプレミスのSQLサーバー、データ履歴データベース、統計プロセス制御ソフトウェア、企業資産管理ソリューションなど、さまざまなシステムに保存・管理されてきました。 原材料の取り扱いから完成品の包装に至るまで、すべての工場の生産工程でミリ秒単位でセンサーデータが収集されています。 データチームは、さまざまなデータにわたって能動的な分析ソリューションを構築することで、全社的な意思決定者に業務プロセスに関する情報を提供し、予知保全を実施し、情報に基づいたデータ主導の意思決定を行うための洞察を得る能力を備えています。
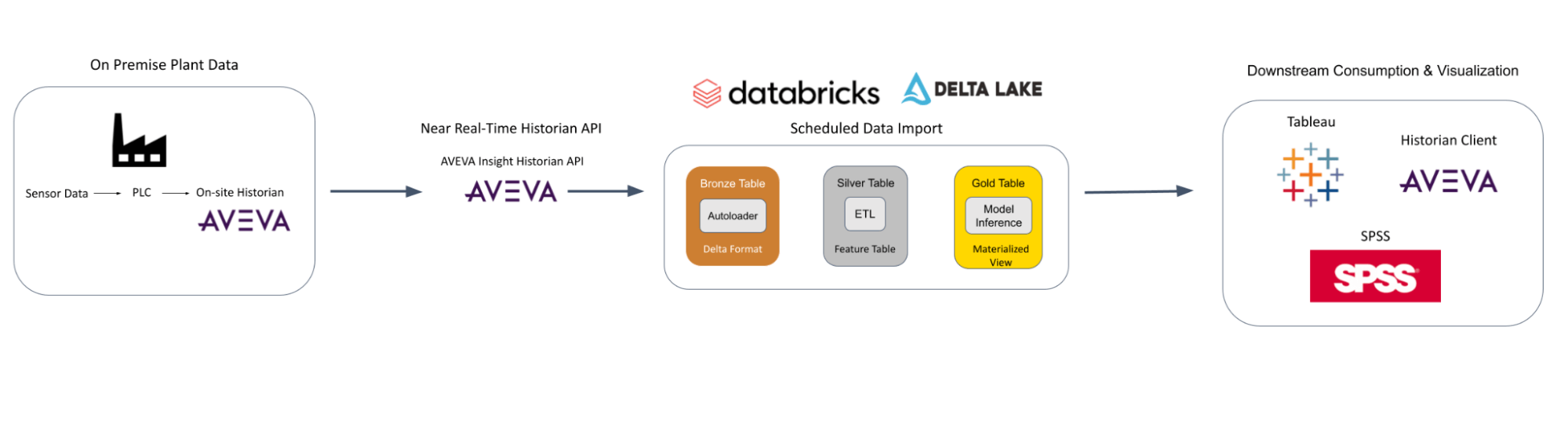
LP社の最大の事例の1つは、何千ものセンサー時系列データを使った異常検知です。Databricksで膨大なデータを効率的に処理し、工場全体で異常検知を実装しました。 Apache Spark on Databricksを使用することで、大量のデータを大規模に取り込み、準備することができます。 これらのデータを工場データ分析、データサイエンス、高度な予測分析用に準備するためには、LPのような企業がオンプレミスのデータウェアハウスソリューション単独よりも高速かつ確実にセンサー情報を処理する必要があります。
アーキテクチャ
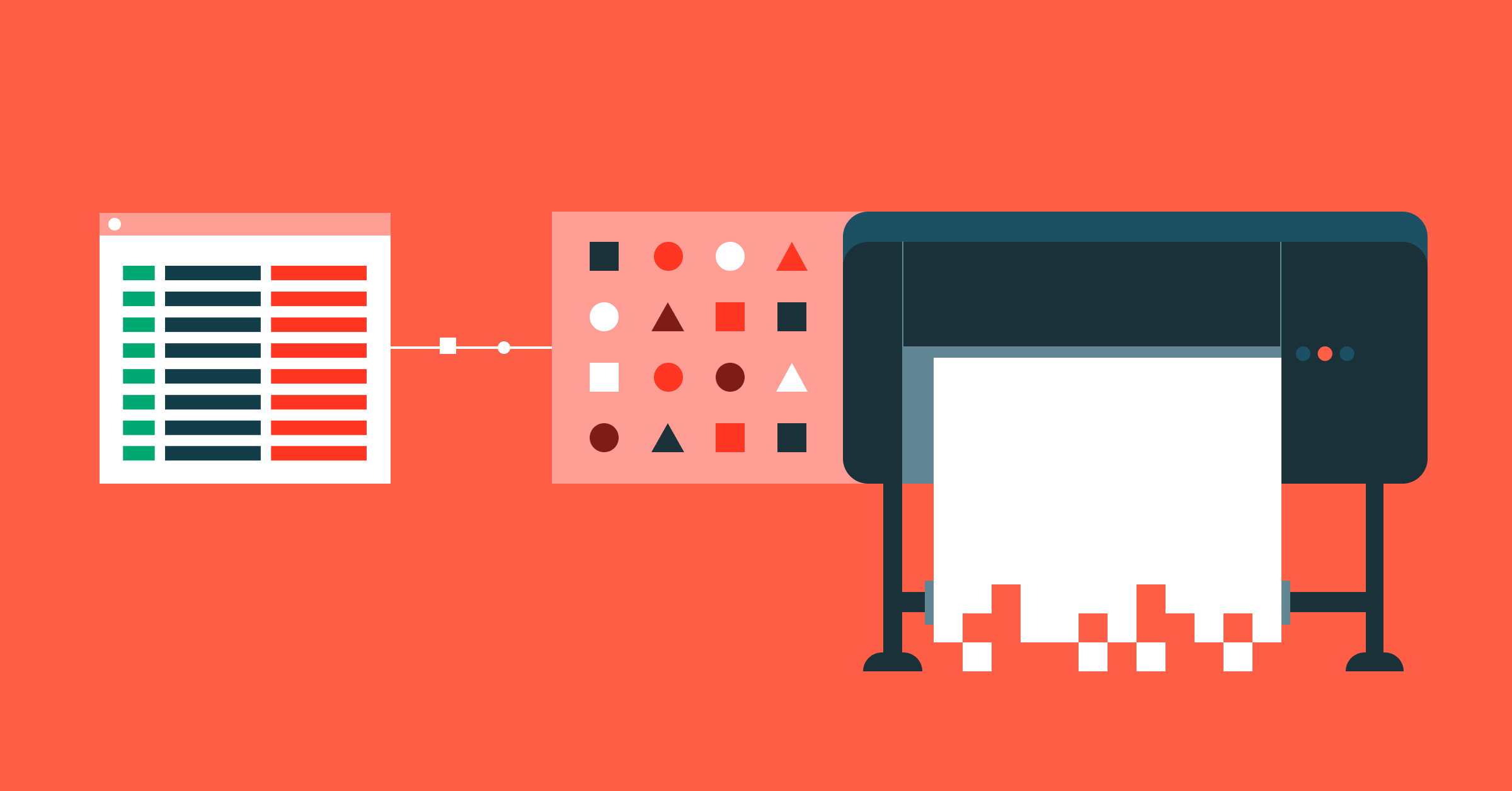
シミュレーションされたプロセスをモデル化するML
一例として、特殊製品の工程における上流の小さな異常が、下流の複数のシステムでより大きな異常へと拡大するシナリオを考えてみましょう。 さらに、下流システムにおけるこのような大きな異常が製品品質に影響を及ぼし、主要な性能属性が許容範囲を下回るとします。 工場レベルの専門家から得た工程に関する予備知識を、周囲環境の変化やこの製品の過去の稼働状況とともに使用することで、異常の性質、発生場所、下流の生産への影響を予測することができます。

第一に、時系列センサーデータの次元削減アプローチにより、オペレーターが見逃していたかもしれない機器の関係を特定することができます。 次元削減は、毎日機器に触れているオペレーターにとって直感的な機器間の関係を検証するためのガイドとして役立ちます。 ここでの主な目標は、相関する時系列のオーバーヘッドの数を減らし、代わりに比較的独立した関連性のある時間ベースの関係にすることです。 理想的には、許容可能な製品SKUとオペレーション・ウィンドウができるだけ多様なプロセス・データから始めるべきです。 これらの要素によって、実行可能な許容範囲が決まります。
プロット
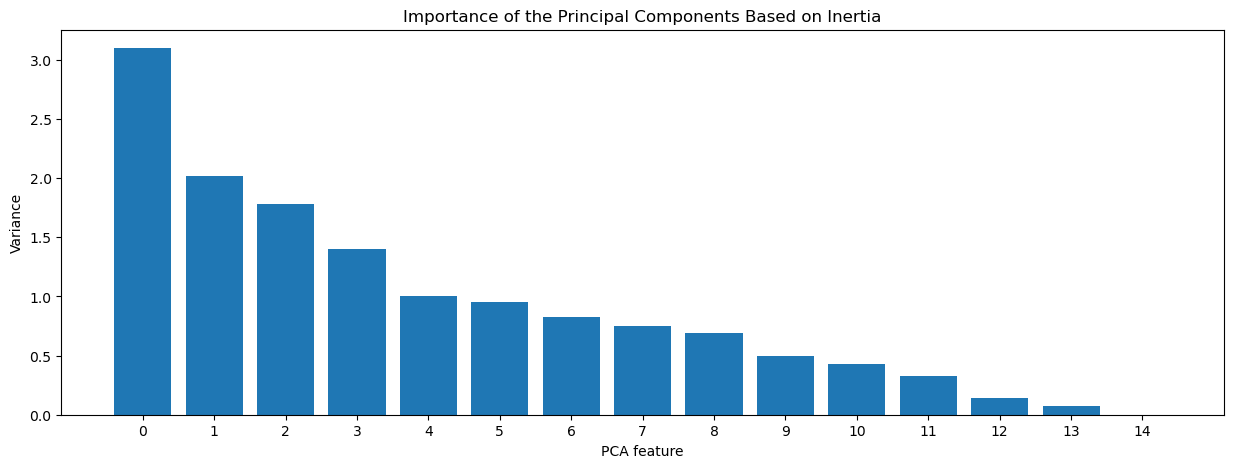
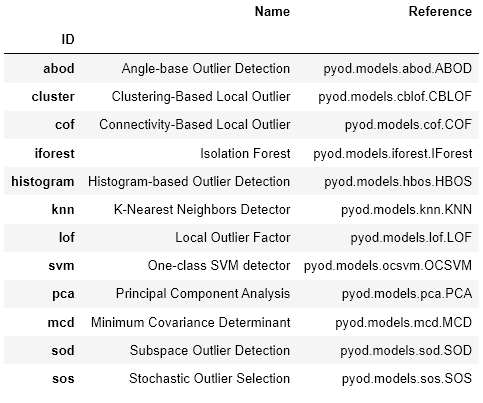
これらの時間ベースの関係を異常検知モデルに入力することで、異常な挙動を特定できます。この複合アプローチは異常検知の精度を高め、下流への影響を予防します。 これらの関係における異常を検出することにより、関係パターンの変化は、プロセスの故障、ダウンタイム、または製造装置の一般的な消耗に起因することができます。 この複合的なアプローチでは、次元削減と異常検知技術を組み合わせて、システムレベルおよびプロセスレベルの障害を特定します。 各センサーの異常検知手法に個別に頼るのではなく、サブシステムの全体的な不具合を特定するために、複合的なアプローチを用いれば、さらに強力になります。 関係を特定し、それらの関係内の異常を特定するために組み合わせることができる多くの事前構築パッケージがあります。 これを処理できるビルド済みパッケージの例として、pycaretがあります。
製品が完成する前に、あるいはより深刻な下流の中断につながる前に、潜在的に深刻なプロセスの中断を特定するために、モデルは定期的に実行されるべきです。 可能であれば、すべての異��常は、異常の性質と場所に応じて、品質管理者、サイトの信頼性エンジニア、メンテナンス管理者、または環境管理者のいずれかが調査する必要があります。
AIとデータの可用性は最新の製造能力を提供する鍵ですが、工場現場のオペレーターがそれに基づいて行動できなければ、洞察とプロセスシミュレーションは何の意味も持ちません。 センサーからのデータ収集から、データ主導の洞察、トレンド、アラートへと移行するには、多くの場合、リアルタイムまたはそれに近いタイムスケールでのクリーニング、解析、モデリング、可視化のスキルが必要です。 これにより、工場の意思決定者は、製品の品質に影響が出る前に、予期せぬプロセスの異変に瞬時に対応できるようになります。
製造データサイエンスのためのCI/CDとMLOps
時間が経つと異常検知モデルの精度は低下します。そのためデータドリフト監視と再学習を継続し、異常検知モデルを最新化する必要があります。 これに対処するため、意図的なシステム変更と非意図的な変更に対するチェックとして、データ・ドリフト・モニタリング・システムを実行し続けることができます。 さらに、プロセスの反応に変化をもたらすような意図的な混乱は、モデルがこれまで経験したことのないようなことが起こります。 このような混乱には、機器の交換、新しい製品SKU、大規模な機器の修理、原材料の変更などが含まれます。 この2点を念頭に置き、データドリフトモニタを導入し、工場レベルの専門家とプロセスを確認することで、意図的な混乱と非意図的な混乱を識別する必要があります。 検証後、結果を以前のデータセッ�トに組み込んでモデルの再トレーニングを行うことができます。
モデルの開発と管理には、堅牢なクラウド・コンピューティングとデプロイメント・リソースが大いに役立ちます。 プラクティスとしてのMLOpsは、データパイプラインの管理、データシフトへの対応、DevOpsのベストプラクティスによるモデル開発の促進など、組織的なアプローチを提供します。 現在、LP社では、Databricksプラットフォームは、Azure Cloudネイティブ機能およびその他の社内ツールと連携して、リアルタイムおよびほぼリアルタイムの異常予測のMLOps機能に使用されています。 この統合されたアプローチにより、データサイエンスチームはモデル開発プロセスを合理化し、より効率的な生産スケジュールを実現しました。 このアプローチにより、チームはより戦略的なタスクに集中し、モデルの継続的な妥当性と有効性を確保することができます。
まとめ
Databricksプラットフォームのおかげで、ペタバイト級の時系列データを管理しやすい方法で活用できるようになりました。 私たちはDatabricksを使って以下のことを行いました:
- 様々なソースからのデータ取り込みプロセスを合理化し、Delta Lakeを使用して効率的にデータを保存する
- 効率的かつ分散された方法で、MLで使用するためのデータの変換と操作を迅速に行う
- CI/CD MLOpsデプロイのためのMLモデルと自動化されたデータパイプラインを追跡する
これらは、LPとお客様の成功と生産性を向上させる効率的なデータ主導の意思決定に役立っています。
MLOpsの詳細については、The Big Book of MLOpsをご参照ください。また、Databricksを使用した異常検知の技術的な複雑さについては、リンク先のブログをお読みください。