Databricks Lakehouseでクレジットデータプラットフォームを構築する方法
金融包摂に向けた障壁の打破

公開日: July 5, 2023
によって Nuwan Ganganath、Boris Banushev、Ricardo Portilla による投稿
翻訳:Junichi Maruyama. - Original Blog Link
dbdemos.aiのデモをご覧になり、ビジネスのためのクレジットデータプラットフォームを構築してください。
はじめに
世界銀行の金融包摂に関する報告によると、なんと17億人もの成人が銀行口座を持たないとされている。銀行口座を持たない個人の多くは、伝統的な金融機関から融資を受けることが難しく、法外な金利で融資を行うインフォーマルな金融業者に頼ることになる。このグループには通常、若い世代、発展途上国の低所得者、農村部の住民が含まれ、その多くは金融サービスへのアクセスを得るために移動している。
銀行口座を持たない人々に関して言えば、モバイル・バンキングは通常、伝統的な銀行業務が弱いと思われている地域の消費者ニーズを満たすために参入してきました。世界中のスマートフォンのユーザー数は、過去5年間一貫して毎年最低5%ずつ増加しており、融資にとって新たな有望な機会をもたらしています。金融機関は、機械学習やその他の高度な分析を活用して顧客の信用力を評価し、プラットフォームを通じて徐々にクレジットヒストリーを構築することで、この機会を活用する必要があります。
金融包摂と伝統的な考え方の拡大の精神に基づき、このブログは、銀行、フィンテック、ノンバンクが、より良い金融サービスを待ち望み、熱望している低空飛行の果実市場に参入する方法についてのガイドであり、再利用可能な公開レイクハウスのデモの役割を果たします。
信用を拡大する - 良いことをすることと良いことをすることは互いに排他的ではない
デロイトが金融包摂に関する報告書の中で指摘しているように、「良いことをすることと良いことをすることは互いに排他的なものではない」。このコンセプトをよりよく理解するために、いくつかの用語を定義してみよう。
与信判断とは、個人の信用力を評価し、ローンやクレジットの返済能力を判断するプロセスである。これは融資業界にとって不可欠なものであり、データ収集、データ処理、データ分析、損失見積もりなど様々な段階が含まれる。伝統的に、与信判断は、銀行口座を持たない人々が最もよく購入するタイプの短期ローンであっても、長いプロセスを要する。さらに、このプロセスは、過去に信用履歴のある個人や長期ローンを組んでいる個人に大きく偏っている。BNPL(buy-now-pay-later) サービス、住宅購入のためのデジタル・マーケット、ノンバンクの信用供与の出現により、与信判断の世界舞台は完全に変貌した。
AIによる与信判断が進歩し続ける中、銀行業界と決済業界では、Databricks Lakehouseの設計に対する顧客の要求が急増しています。このデザインは、与信判断プロセスに全体的かつ効率的なソリューションを提供する与信データプラットフォームを提供します。このプラットフォームは、データ統合、監査、AIを活用した意思決定、説明可能性を可能にし、データ分析のための単一の真実のソースを提供します。与信データ・プラットフォームには、膨大な量のデータを分析し、借り手の信用力についてより正確な予測を提供できる機械学習モデルが含まれており、与信判断プロセスのスピードと精度を向上させる。クレジット・データ・プラットフォームは、金融サービスを提供��しようとしているフィンテック、銀行、またはノンバンクが、情報に基づいた与信判断を行い、債務不履行のリスクを低減し、顧客により良い金利と条件を提供するのに役立つ。テクノロジー・ソリューションについて掘り下げる前に、金融機関が今日の市場でサービスを提供するのに苦労している分野を取り上げる。
Part I - Why Change?
銀行業務における課題
信用データ・プラットフォームの導入は、銀行やその他の金融機関にとって重要な課題となり得る。以下の理由を考えてみよう。
課題その1:既存データの不足
優れたクレジット・モデリングとは、大規模なデータ・キュレーションの実践である。
多くの銀行口座を持たない個人は、伝統的な金融機関から融資を受けることが難しく、法外な金利で融資を行うインフォーマルな金融業者に頼ることになる。銀行口座を持たない顧客の与信判断は、従来のクレジットヒストリーや信用力の評価に使用できる財務記録がない場合があるため、困難な場合がある。さらに、与信判断のデータは異なるソースや互換性のないフォーマットで保存されていることが多く、データ・ユーザーが完全に統合して貴重な洞察を引き出すことが困難である。この結果、データはデータ・エンジニアや科学者だけが利用でき、マーケティングや財務チーム、コールセンター・エージェント、銀行の窓口係などのエンド・ユーザーは利用できない。
課題その2 - セキュリティとガバナンス
制限のないデータは、ガバナンスのない運営を意味しない。
銀行やその他の金融機関は、クレジット・データ・プラットフォームを構築する際に大きな課題に直面する。プラットフォームが安全で、規制要件に準拠し、機密性の高い顧客データを確実に保護しなければならない。これらの目標を達成するには、データのプライバシー、アクセス制御、品質、コンプライアンスなど、セキュリティとガバナンスに関連するさまざまな課題に対処する必要があります。しかし、データガバナンスと企業のセキュリティ管理は、データエコシステムの複雑さ、脅威の進化、内部リスク、リソースの制約などのために、困難な場合があります。データを効果的に管理し保護するために、組織はこれらの課題に根本から取り組む必要があります。
課題その3 - 説明可能性と公平性
「データインサイト」を実用的なものにする
説明可能性と公平性は、消費者を差別から守り、公平な結果を保証する偏りのない理解しやすい決定を促進するため、与信判断において不可欠である。公正さと説明可能性の欠如は、クレジット制度に対する信頼を損ない、消費者のクレジット申込意欲を減退させる可能性がある。しかし、与信判断の公平性を評価し、結果を説明することは、いくつかの要因により困難な場合がある。これには、クレジットスコアリングモデルの複雑さ、潜在的なデータの偏り、人間のバイアスの可能性などが含まれる。
与信判断ソリューション
このブログでは、Databricks Lakehouseを通じて適切なデータ基盤を設定することで、前述の課題に対処し、より優れたクレジット・モデルを構築して、銀行口座を持たない顧客へのサービス提供、クレジット・リスクとエクスポージャーの評価、Buy-now-Pay-Laterなどの�斬新な商品の導入など、企業のビジネス目標を達成できることを示します。

優れた与信モデルには、銀行顧客の消費習慣、過去の延滞の可能性、収入源など、可能な限り多くの角度から銀行顧客を描写する多種多様なデータが必要です。信用調査機関のデータ、顧客情報、リアルタイムの取引データ、パートナー・データ(従来の銀行情報を補強するために使用する通信データ)など、最新の与信判断プラットフォームを構築するために必要なさまざまな金融データ・ソースを図の左側に報告しています。すべてのデータ・ソースは、ファイル形式、取り込み速度、ボリューム、ソース・プラットフォームが全く異なることは容易に理解できる。
データ統合
様々な課題を解決するために、私たちはデータ統一から始めます。つまり、あらゆるデータソースを単一の真実のソースに取り込む能力です。
- 信頼性、保守性、テスト可能なデータ処理パイプラインを構築するための宣言型フレームワークである Delta Live Tables を使用することで、これら全てのデータソースを単一のパイプライン、保存場所、ファイルフォーマットである Delta Lake に取り込むことを合理化することができます。時間移動、スキーマの強制と検出、ストリーミングとバッチデータのマージ機能などの機能により、デルタレイクは最新のデータプラットフォームの基礎となる信頼性とパフォーマンスを提供します。すべてのデータは今日の世界ではストリーミングであり、ほぼリアルタイムのインジェストはテーブルステークスです。Delta Live Tablesは、インフラストラクチャのプロビジョニングの「方法」ではなく、「何を」に集中するためのシンプルなインターフェイスを提供します。
- データの統一は、全てのデータが同じ場所に同じフォーマットで存在するため、ガバナンスとセキュリティが簡素化されることも意味します。クレジットスコアリングには、多くの個人識別情報(PII)を含むソースが必要です。Unity Catalogとして知られるDatabricksのガバナンス・ソリューションによって、データの使いやすさや消費可能性を損なうことなく、最高レベルのセキュリティを簡単に実現することができます。Unity Catalogでは、構造化されていないデータであっても、ストリームデータであっても、データの形式に関係なく、シンプルなSQLステートメントを使用して、きめ細かなテーブルアクセスコントロール(ACL)を簡単に適用することができます。
データの決断
適切なデータ基盤が整えば、データデシジョニングに移行し、「データインサイト」と呼ばれる隠れたパターンや相関関係を見つけることができる:
- 効果的なチーム間コラボレーションは、金融サービス業界においてデータプロダクトの構�築を成功させるために非常に重要です。MLFlow'のグラスボックスAutoML機能は、Databricks Feature Storeの発見可能性と系統性、Databricks Notebooksに統合されたGUIベースのデータプロファイリングとダッシュボード機能によって強化され、自動化された実験、モデル選択、ハイパーパラメータのチューニングを通じて、非常に迅速にベースラインモデルを作成することができます。
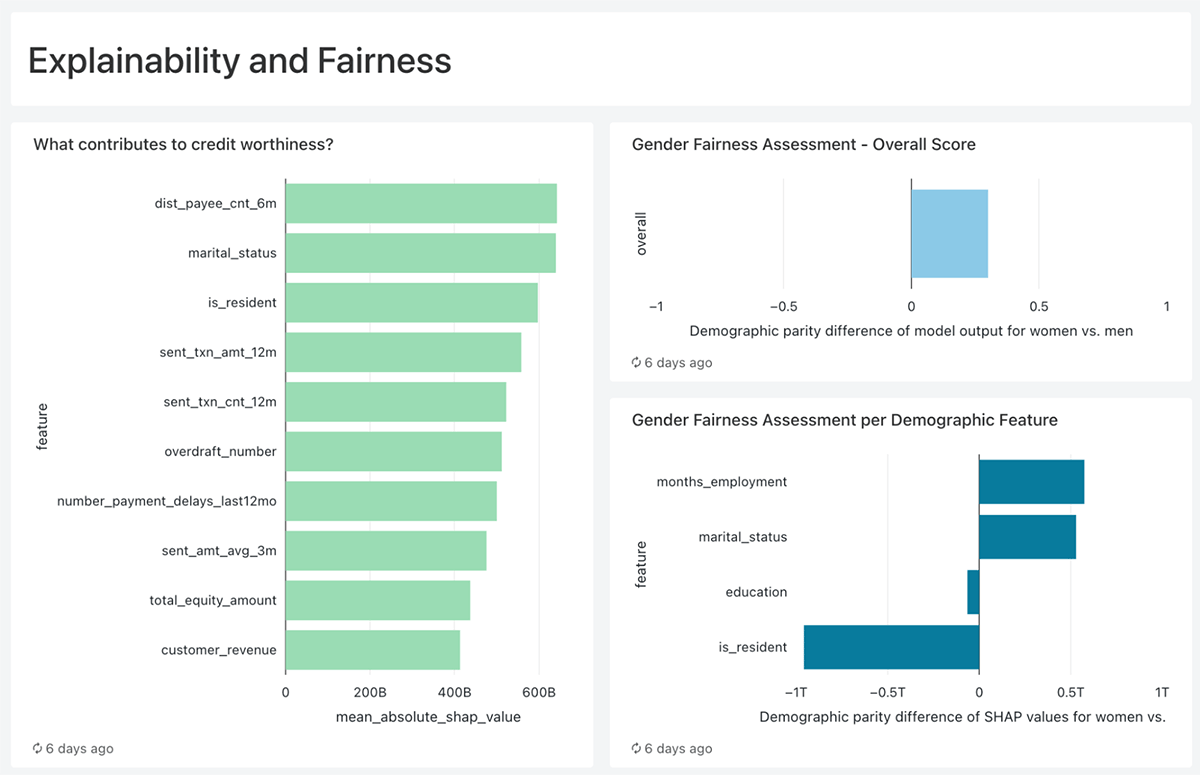
- 既に述べたように、データ洞察と機械学習予測が説明可能で、公正で、実行可能でなければ、ノートブックにとどまる可能性が非常に高い。このデモでは、SHAP (SHapley Additive exPlanations)を使用して、「何が信用度に寄与するのか」や「特定の顧客がデフォルトになる理由」などの詳細を提供することで、統計をビジネス・プロセスに結びつけ、クレジット・エージェントやマーケティング・チームが一人一人に対応しやすくしています。
データの民主化
今日、データにアクセスし、利用できるのは、データサイエンティストやデータエンジニアといったデータチームだけである。しかし、データ・チームは、与信判断のようなユースケースのエンド・ユーザーではない。それは、与信担当者が申込書を評価したり、コールセンターの担当者が顧客とコミュニケー�ションをとったり、マーケティング・チームが銀行口座を持たない顧客にアップセルするための販促資料を作成したりすることである。しかし、これらのペルソナは、データにもダッシュボードにも機械学習による予測にもアクセスできないことが多い。昔は、データ・チームは要求されたデータをcsvファイルやpdfファイルにエクスポートし、メールでビジネス・ユーザーに送っていた。このやり方は、安全でもスケーラブルでもシンプルでもない。
Unity CatalogとDatabricksのデータウェアハウス・ソリューションであるDatabricks SQLにより、金融サービス組織は、BIビジュアライゼーションやDelta Sharingなどの機能を通じて、データと洞察を「民主化」し、データ・ユーザーだけでなく組織内のすべての人がデータにアクセスできるようになります。
金融サービス向けDatabricks Lakehouse
データとユーザーの統合、実用的な意思決定、データの民主化という組み合わせが、金融サービス向けDatabricks Lakehouseの基本です。セキュリティとガバナンスを犠牲にすることなく、究極のデータアクセスの民主化を実現します。

ビジネスの成果
与信判断のためのレイクハウスのデモツアーを始めるにあたり、どのような金融機関でも達成できるインパクトをお見せしたい��と思います。データを統合し、分析に利用できるようにすることで、私たちは新規顧客を獲得するビジネス成果を推進しています。
銀行口座を持たない顧客へのアップセルとサービス
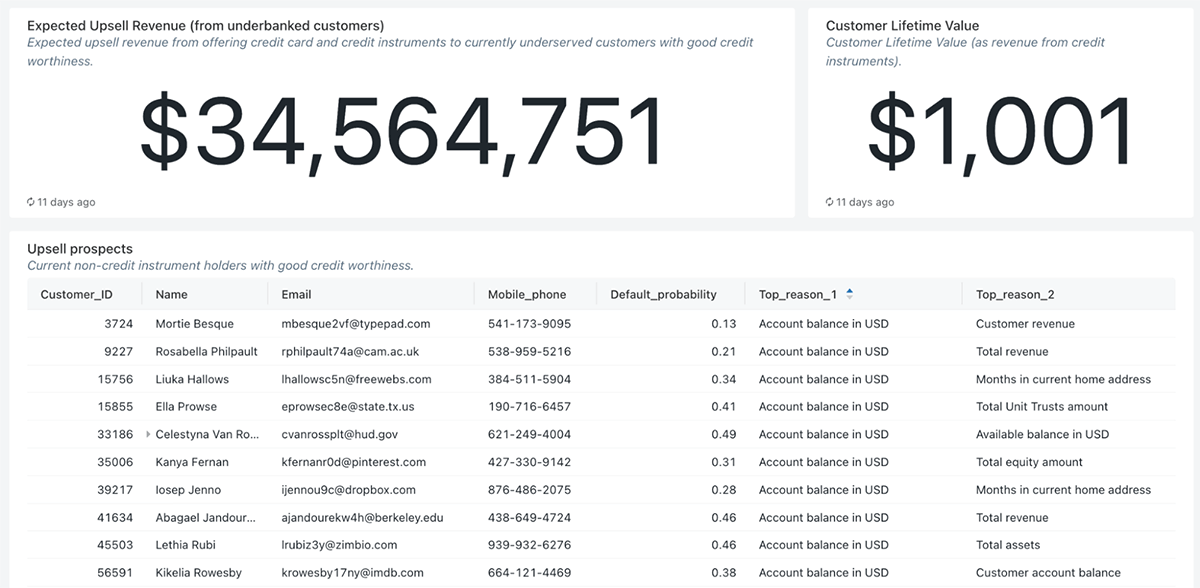
顧客生涯価値モデル(CLV)で強化されたダッシュボード機能を通じて、現在銀行と信用取引を行っていない信用力のある顧客(アンダーバンキング)を特定し、サービスを提供することによる財務的利益を簡単に報告することができます。ダッシュボードは、生データ、機械学習予測、説明可能性情報を組み合わせ、各アンダーバンク顧客のデフォルト確率を特定するだけでなく、各顧客に固有の上位3つの理由も特定し、信用力を評価するクレジットエージェントや顧客とコミュニケーションをとるマーケティングチームにとって非常に実用的なものにしています。最後に、以下に報告するように、信用スコアリング・モデルの公平性を評価し、どの顧客グループにも不利にならないようにする方法も提供しています。
Part II - How to Serve More Clients with the Lakehouse Architecture
プラットフォームの構築
このセクションでは、与信判断デ��モの技術的な実装とアーキテクチャをさらに深く掘り下げ、レイクハウスが金融機関のビジネス目標達成のためのデータ活用をどのように支援しているかを見ていく。
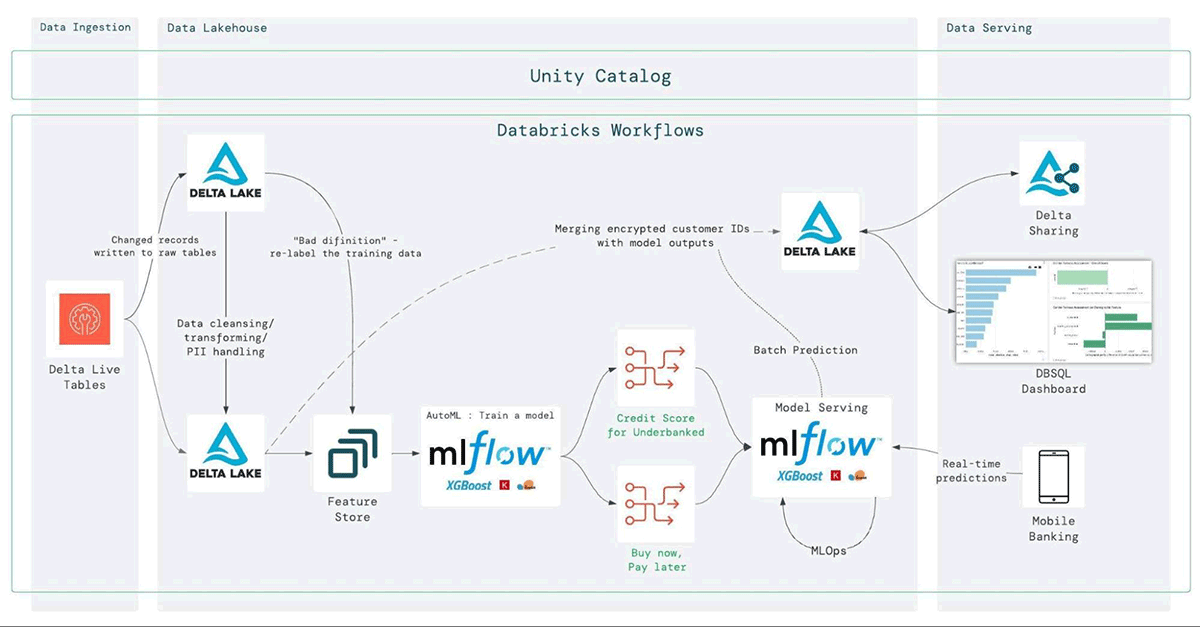
上の図は、与信判断ソリューションの実際のアーキテクチャを示しており、データの統一、ガバナンス、民主化など、前述の目標をどのように達成しているかを示しています。
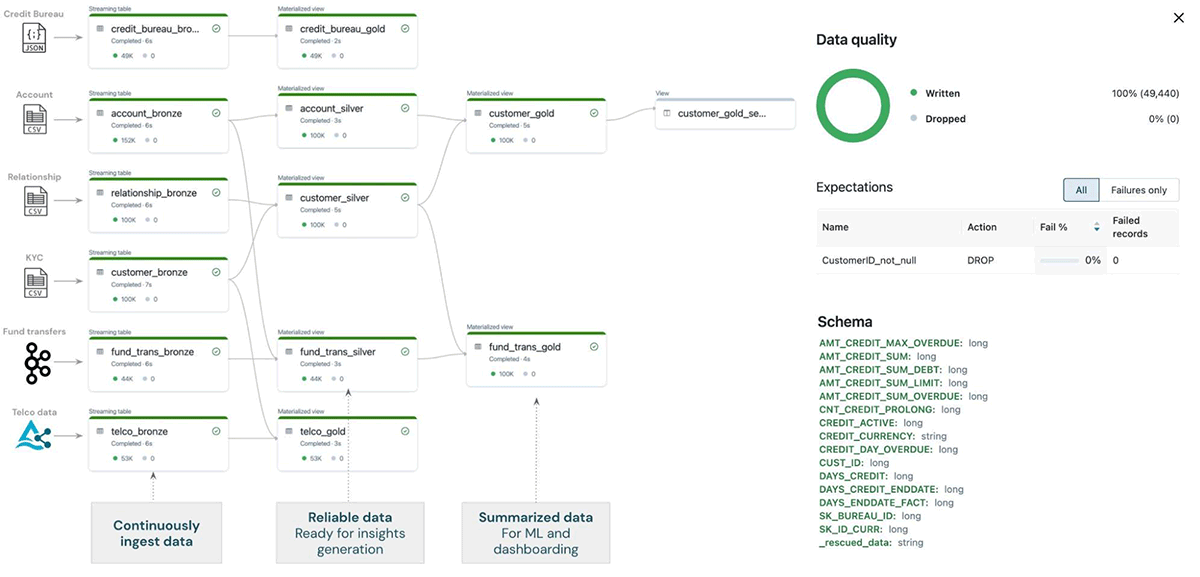
インジェストから始めると、デルタ・ライブ・テーブル(DLT)を使って様々なソース(下図)に接続し、それらを単一の真実のソースにインジェストします。DLTは、自動化されたデータ品質チェックとレポート、オートスケーリング、スキーマ検出、実行スケジューリング、深いモニタリングと観測可能性など、非常に使いやすいデータエンジニアリングツールです。DLTを使用することで、(シルバーレイヤーとゴールドレイヤーに)取り込まれたデータのクリーニングとキュレーションを簡単に行うことができます。
データエンジニアリングチームは、ETLプロセスを合理化するために、もはや様々なツール、言語、プラットフォーム、サービスを必要としない。必要なのはパイソンかSQLだけで、構造化、非構造化、ストリームの形態を問わず、あらゆるデータソースの取り込みと変換を処理できる。このように、DLTはデータアーキテクチャを大幅に簡素化し、必要な時間と労力を削減し、データ品質の問題を最小限に抑え、全体として、データ��チームが組織のデータ目標に向けてより効果的に作業できるよう支援する。
- 次のステップは、データを適切に保護しながら、発見可能かつ消費可能にすることです。レイクハウスは、すべてのユーザーとデータに関するきめ細かなガバナンスを容易に実現します。これまで、データが複数の場所や形式にまたがっていたため、データガバナンスとセキュリティを統一することは困難でした。レイクハウスでは、すべてのデータが1つの場所、1つのフォーマット(非構造化、構造化、ストリームのいずれであっても)で管理されるため、全体的なガバナンスの実現が非常にシンプルになります。
例として、下の図では、SQLステートメントを使用することで、機密データに対して行レベルのマスキングを簡単に実装できることがわかります。このシナリオでは、"データサイエンティスト "グループのユーザーが銀行の顧客の実際のファーストネームを見ることができないようにしたいので、カラムをマスクします。一方、それ以外の人はこれらの名前を見ることができます。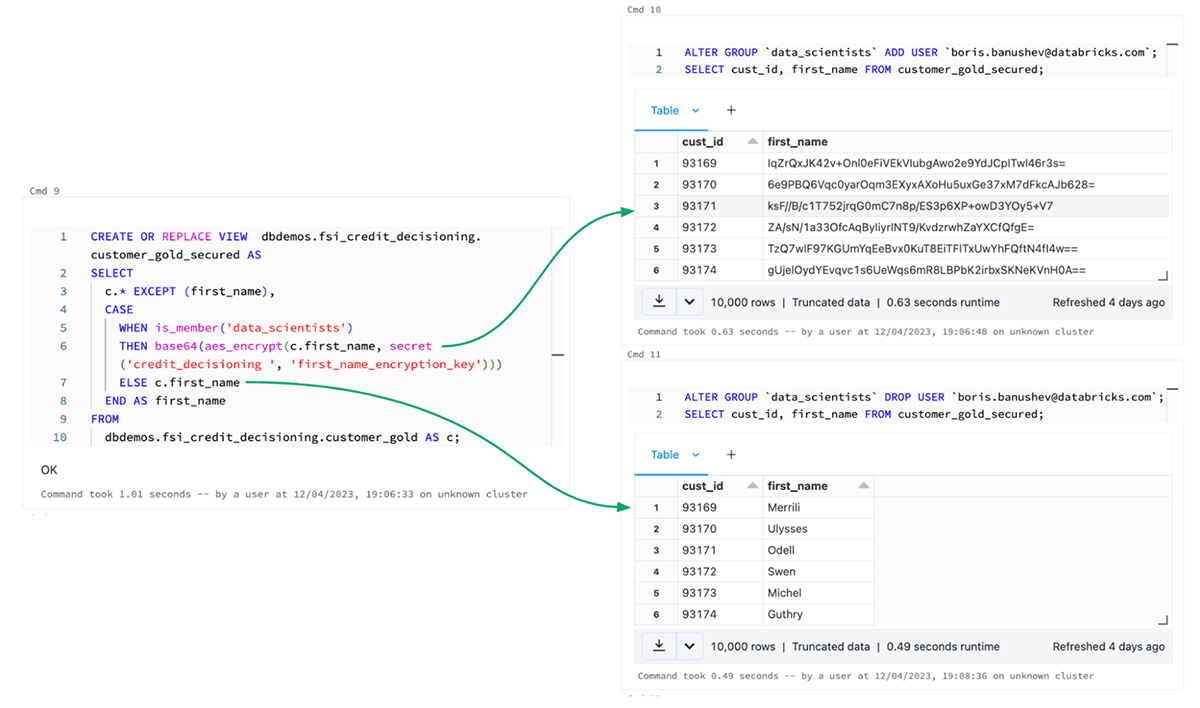
すべての必要なデータが取り込まれ、クリーニングされ、適切に保護され、管理されたので、探索的データ分析(EDA)とフィーチャーエンジニアリングに移ることができます。Databricksフィーチャーストアにフィーチャーを格納し、一元化されたリポジトリでフィーチャーを共有し、フィーチャー値の計算に使用された同じコードがモデルのトレーニングと推論に使用されるようにします。DatabricksフィーチャーストアもDeltaテーブルの上に構築されているため、フィーチャーセットの品質、発見性、ガバナンスを同じレベルで達成することができます。
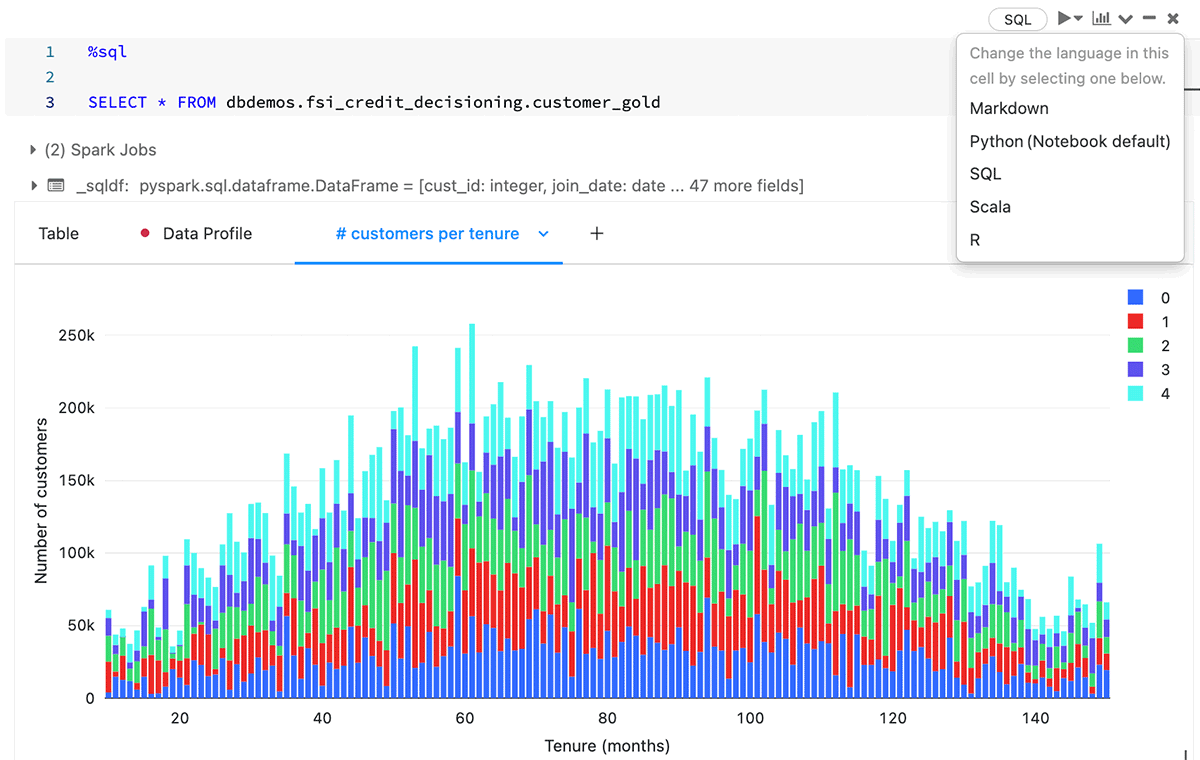
下の図では、Databricks Notebooksで自動化されたダッシュボードを見ることができます。この機能に加えて、自動化されたデータプロファイリング、異なる言語(SQLとpython)で同じNotebookで多くの人が作業できる機能、そして完全なCI/CDのための埋め込みリポジトリ機能により、Lakehouseではチーム間のコラボレーションが非常に高速になっています。フィーチャーエンジニアリングとモデルトレーニングを通じて素早く実験できる能力は、高品質の機械学習モデルを生み出す鍵です。
- フィーチャーが生成されると、Databricks の glass-blox AutoML 機能を使用して、自動化されたモデル選択とハイパーパラメーターのチューニングによってベースライン・モデルを構築できます。MLFlowを使用すると、数百のモデルの比較、数十のメトリクスに基づく評価(下図)、MLOpsのベストプラクティスを使�用したバッチおよびリアルタイムの推論用のモデルの迅速なデプロイ、これらのモデルのデータとコンセプトのドリフトのモニタリング、さらにはA/Bテストのデプロイまで簡単に行うことができます。
- このソリューションのバッチ推論は、銀行口座を持たない顧客の信用度の予測や、現在の債務保有者の債務不履行確率(および債務不履行による損失)の予測に使用されます。リアルタイム推論はBuy now, Pay laterのユースケースで使用され、顧客は金融取引を完了するために必要な金額を持っておらず、銀行は取引が完了するように顧客の信用限度額を一時的に増やすことができるかどうかをリアルタイムで計算したい。
- 次のステップは、Databricks SQLを使用し、すべてのデータと機械学習予測を一緒に可視化することです。すでにブログのビジネス成果のセクションで、Lakehouseで構築されたダッシュボードをいくつか見た。
- 上述したように、与信判断やデフォルト予測のエンドユーザーはデータサイエンティストやエンジニアではなく、ビジネスユーザーであるため、データチームだけでなく、非データチームやビジネスユーザーが必要なデータにアクセスできるようにすることが重要である。しかし後者は、タイムリーかつ構造化された方法でこれらの情報にアクセスできないことが多い。Delta Sharingを通じて、金融機関は、たとえ相手がDatabricksのユーザーでなくて��も、あらゆるデータをあらゆる受信者と安全に共有することができます。
- データインジェスト、ELT、機械学習のトレーニングとデプロイ、データ共有、ダッシュボードを含む単一のデータパイプラインにすべてを生産化するために、私たちはDatabricks Workflowsを使用しています。ワークフローは、Databricksノートブック、DBSQLダッシュボード、DLTパイプライン、pythonファイルなど、様々なデータ資産の堅牢なパイプラインを作成し、統一されたワークフローですべてを連携させることができます。
- 最後に、Databricks Unity Catalogが自動的に取得する統一されたデータ系統を使ってみましょう(下図)。DLTで取り込まれクリーニングされたデータ、Feature Storeに保存されたFeatureセット、機械学習モデルのトレーニング後にMLFlowで作成されたバッチ予測など、あらゆるデータ資産を同じ系統グラフで見つけることができます。
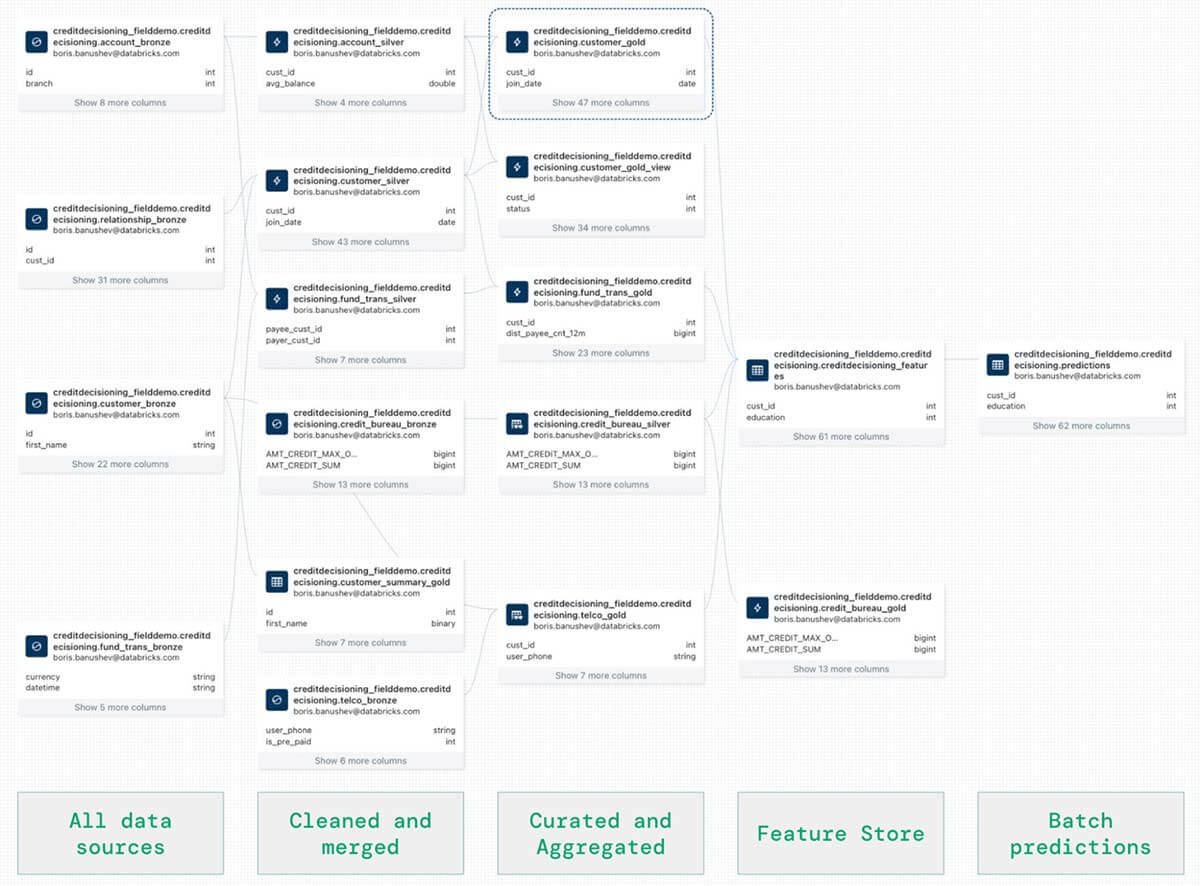
このようなエンド・ツー・エンドのデータ・リネージは、データのコンプライアンス、監査、観察可能性、発見可能性を理解する上で極めて重要である。
これら3つは、完全なデータ・リネージが非常に重要になる、非常に一般的なシナリオである:
- 説明可能性 - 機械学習で使用される特徴を、その特徴を作成した生データにトレースする手段を持つ必要がある、
- ダッシュボードやMLモデルの欠損値を元データにトレースする、
- 特定のデータを見つける - 組織には何百、何千ものデータテーブルやソースがある。特定の情報を含むテーブルやカラムを見つけることは、適切な発見可能性ツールがなければ大変なことです。
結論
過去20年間で、最も顧客が夢中になった発明のいくつかは、より優れた自動化によって支えられていた。iPhoneは、手動によるハードウェアのアップグレードに頼る代わりに、マルチタッチを検出するソフトウェアを導入した。PayPalはピアツーピア・ネットワークを活用することで決済に革命を起こした。そしてGPT-3は、仕事以外の日常生活に浸透した高度なテキスト生成を自動化することで世界を変えた。最終的には、与信判断も同じレベルの革新と自動化の恩恵を受けている。不完全なデータで手作業で融資を承認する代わりに、代替データソースを自動的に取り込み、PIIを管理してTime to Valueを改善し、MLとAIを使って与信判断を自動化することで、どの企業(銀行であれ、そうでない企業であれ)も新しい個人に融資を行うことができるようになった。Databricks Lakehouse上の与信判断フレームワークは、Databricksが提供するソフトウェアによって、この自動化フレームワークのシンプルさを正確に成文化するように設計されている。
クレジット・データ・プラットフォームを構築するには, visit the demo at dbdemos.ai to get started and learn more.

