Databricksが実現するデータとAIの運用モデルとは:Part 1
Overview

Original Blog : How Databricks enables your operating model for Data and AI: Part 1
翻訳: junichi.maruyama
"今、(AIの)ボトルネックは、テクノロジーではなく、マネジメント、実装、ビジネスイマジネーションにあります。" -Erik Brynjolfsson
データとAIは、ここ数年、ほとんどの組織にとって戦略的な必須事項として浮上しています。大企業も中小企業も、データおよびAIの専門家を多数採用し、データプラットフォームのアップグレードと進化に多大な投資を行ってきました。
これまでのところ、投資のほとんどは、デ�ータとAIを活用し、進化し続けるデータ環境の規模と複雑性に伴って出現した技術的課題を解決するために必要なテクノロジーと技術スキルに焦点を当てています。Databricksでは、レイクハウスパラダイムを発明したり、Delta Sharingでより簡単な共有とコラボレーションを可能にしたり、MLFlowでエンドツーエンドのMLOps機能を提供したりと、そうした課題に正面から向き合い解決することで知られています。
しかし、テクノロジーだけですべての問題を解決することはできませんし、どんなに優れたテクノロジーでも、適切に使用されなければ、期待を裏切ることになるのは間違いありません。これは、最近AIで見られる傾向です。Databricksでは、データとAIの有効活用を目指す企業が成功するためには、それを開発するための適切な技術、アルゴリズム、スキルを持つことと同様に、適切なオペレーションモデル、プロセスを持ち、最適な働き方を実現することが不可欠であると認識しています。
このシリーズの第1部では、DatabricksプラットフォームがAIのためのモダンなオペレーティング・モデルをどのようにサポートするかという一般的な概要に焦点を当て、以降のパートでは、それがチームや組織にとって何を意味するのかについて詳しく掘り下げていきます。それを踏まえて、DatabricksがAIのための運用モデルをどのようにサポートするのかを掘り下げていきましょう:
- オープンなコラボレーション: チーム内およびチーム間で明確なコミュ��ニケーションラインを確立できることは、AIの成功の基本です。現在、データエンジニア、データサイエンティスト、アナリストは、それぞれ別のテクノロジースタックで仕事をしており、チーム間のコラボレーションは最小限か、せいぜい緊張した状態です。
Databricksは、これらのペルソナがクロススキル、ハンドシェイクの削減、ステージの収束のために一緒に働くことができ、技術的負債を大幅に削減できる統一された環境を作ることに努めています。
組織レベルでは、最近注目を集めているデータメッシュのようなコンセプトは、多くの組織が置かれているサイロ化された現状では、ほとんど実現不可能です。Deltaのようなオープンデータ形式や、Delta Sharingのようなオープン共有プロトコルは、データフォワードを目指す組織や、有用なデータ製品を開発するチームの力を高めるために、ゲームチェンジャーとなります。なぜなら、これらのプロトコルは、データを標準化された方法で扱い、アクセスし、組織内外の両方で安全に共有・使用することを可能にするからです。
Databricksは、データプロバイダ、データ&AIプロフェッショナル、データコンシューマーを結びつけるために必要なプロセスを簡単に実装できるプラットフォームを提供します。

-
ガバナンスとマネジメント: どのような運用モデルでも、その成功は、説明責任、トレーサビリティ、透明性にかかっています。ビジネスとデータの状況がますます複雑になる中、テーブル、ファイル、AIモデル、ダッシュボードなど、すべてのデータ成果物の使用とアクセスを保護し最適化するプロセスを導入することが不可欠です。
Databricks Lakehouse Platformは、Unity Catalogを通じて、統一されたガバナンスモデルを実現する手段を提供します。Unity Catalogでは、データアーティファクトにきめ細かい権限を付与し、ユーザーをグループ化して一元的に管理することが可能です。どのようなデータやリソースにアクセスできるのか、チームやユーザーを簡単に管理できることは、持続可能な運営モデルやコスト管理のために重要なことなのです。
Databricksが提供するリソースポリシー、ユーザー管理、データディスカバリー、アクセスコントロールを促進する機能により、安全でコンプライアンスに優れた組織構造を定義し運用することが可能になり、利用できるリソースを最大限に活用して無駄を最小限に抑え、生産性を向上させます。さらに、Databricksが実現する明確なポリシーとガイドラインのもう一つの利点は、プラットフォーム内で行われるすべてのアクションについて詳細な洞察と監査可能性を提供し、これを監査、品質保証、規��制遵守に利用できるようにすることです。
上記をまとめると、例えばData Meshの例に倣って、データ所有者の役割を効果的に定義し、データ製品の作成と利用を管理・追跡するツールを提供することで、組織への影響を追跡することができるようになります。
Databricksは、データおよびコンピュートリソースのオーナーシップとガバナンスを可能にし、様々なチームや組織構造が安全かつ効果的に働けるように管理を促進します。
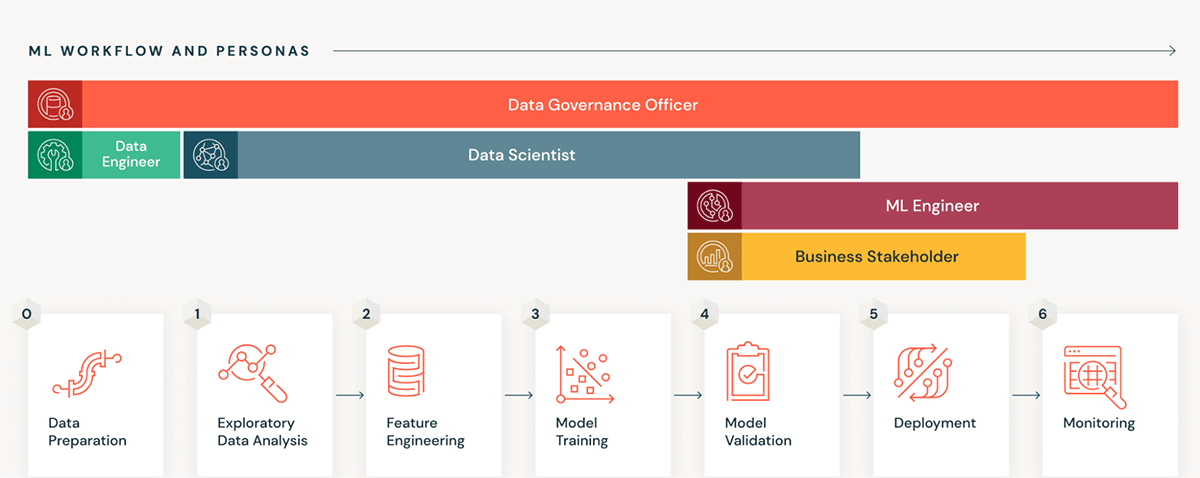
実行し、運用する: AIの運用モデルの最終的な目的は、データからビジネス成果までの価値生成プロセスを合理化することです。AIアプリケーションの開発は高度に反復的なプロセスであり、一般にアジャイルな環境で努力することになります。
Databricksプラットフォームは、探索と革新から実験、追跡、展開まで、機械学習運用のエンドツーエンドのライフサイクルをカバーする環境を提供します。Databricksは、データ中心のAIに焦点を当てたMLOpsフレームワークとツールセットを組織に提供し、チームがそれに従うことで、開発、テスト、提供のための明確な基準を持つことができます。
 実際、追跡と実行というテーマでは、AIの運用モデルの成功の重要な部分は、データとAIの利用を測定可能なビジネス成果に効果的に結びつけることができることであり、DatabricksはそうしたKPIを収集、管理、維持できる基盤を提供する。ビジネスにおけ�るデータの価値を表すKPIの1つが、RODA(Return on Data Assets)です。
実際、追跡と実行というテーマでは、AIの運用モデルの成功の重要な部分は、データとAIの利用を測定可能なビジネス成果に効果的に結びつけることができることであり、DatabricksはそうしたKPIを収集、管理、維持できる基盤を提供する。ビジネスにおけ�るデータの価値を表すKPIの1つが、RODA(Return on Data Assets)です。AIプロジェクトを実行・運営する際には、商業的・予算的に重要な考慮が必要であることを考慮してください。資金調達、チャージバック、コスト配分は、具体的なビジネス成果をもたらす健全なデータおよびAIパイプラインの運用に重要です。Databricksは、ユースケースから本番までの開発サイクルを追跡・定量化し、ワークロードの開発・実行方法に関する標準を確立する能力を組織に提供し、強制、所有、検証、報告することができます。
しかし、AIプロジェクトはモデルがデプロイされたら終わりというわけではなく、モデルは監視、更新、維持される必要があります。ここでもDatabricksは、モデル管理に関する明確なプロセスを構築し、モデルの出力を効果的にビジネス成果に結びつけるために必要なツールと構造をチームに提供し、データをビジネスパフォーマンスの向上につなげる好循環を実現します。
Databricksは、生産へのパスを合理化し、組織がデータとAIの開発とビジネス成果の間の接続を可能にします。
まとめ
組織はさまざまな文脈で運営され、さまざまな形や大きさがあります。規制要件、データとリソースの利用可能性、その他多くの要因が、適切なオペレーティング・モデルを決定する上で役割を果たすでしょう。
そして、より多くのユースケースやユーザーがパイプラインに入り、より多くのモデルが展開され、より多くのビジ�ネスがデータとAIによって強化されるにつれて、組織とともに拡張できるプラットフォームを持つことが重要です。オペレーティング・モデルを支えるサービスは、柔軟であると同時に、セキュリティと説明可能性をプロセスのすべてのステップに浸透させる必要があります。
Databricksは、最先端のデータ処理とAI機能を提供することで、企業が技術的な課題を克服するだけでなく、その上に組織ができる仕組みとプラットフォームを提供します:
- 価値創造へのスピードを上げ、具体的なビジネス・ベネフィットを実現し、追跡する。
- ガバナンスとコラボレーションを実現する。
- オーナーシップを確立し、エンドツーエンドで運用する。
DatabricksがどのようにデータおよびAIで顧客の困難な課題の解決を支援しているかについては、Databricks.comでご確認ください!