データとAIにおけるオペレーティングモデルと実践
チームと役割

翻訳:Ryo Hasegawa. - Original Blog Link
このBlogシリーズのパート1 では、Databricksがどのように企業のデータとAIから価値を引き出すプロセスを開発、管理、運用を可能にするかについて説明しました。今回は、チーム構成、チームダイナミクス、責任について焦点を当てます。ターゲット・オペレーティング・モデル(TOM)を成功させるためには、組織内のさまざまな部署やチームが協力し合う必要があります。
Databricksに入社する前、私はコンサルティングに携わり、クラウドネイティブからオープンソースまで、様々な業界や様々なテクノロジースタックを使ってAIプロジェクトに携わってきました��。基礎となるテクノロジーは異なりますが、これらのアプリケーションの開発と実行に関わる役割はほぼ同じでした。チーム内の1人が、作業の規模や複雑さに応じて複数の役割を担うことができることも事実です。
エンジニアリング、データサイエンス、アナリストのような異なるチームや異なる役割を持つ人々が、同じツールを使い、同じ技術言語を使い、各々のプロダクトの統合を促進するプラットフォームを持つことは、データ資産利益率(RODA)を向上させるために不可欠でです。
AIにおける運用モデルを実践するための適切なチームを立ち上げるには、以下の要素を考慮することが重要です:
- データ基盤の成熟度: データがサイロ化したままになっていないか、オープンではないプロプライエタリの独自フォーマットにとどまっていないか、統一された方法でアクセスするのが難しいかどうかが、データエンジニアリングの作業量やデータプラットフォームの専門知識の必要性に大きく影響します。
- インフラとプラットフォームの管理: 保守が必要か、「as-a-service」サービスを活用する必要があるかは、チーム全体の構成に大きく影響する。さらに、データプラットフォームが複数のサービスやコンポーネントで構成されているとします。その場合、データとユーザーを管理・保護し、すべてのパーツを連携させ続けるという管理負担は、特にエンタープライズ規模では圧倒的なものになる可能性がある。
- MLOps:AIを最大限に活用するには、それを応用してビジネスにインパクトを与える必要があります。適切なMLエンジ�ニアリングの専門知識や、パッケージ化、テスト、デプロイ、モニタリングのためのツールを持たずに、データサイエンスチームを雇用することは、非常に無駄が多いものです。効果的なエンドツーエンドのAIアプリケーションを実行するには、いくつかのステップが必要であり、運用モデルは、ユースケースの特定から開発、デプロイメント、そして(おそらく最も重要な)活用に至るまで、関係する役割やモデル・ライフサイクル管理の実行方法に反映されるべきです。
これら3つの属性が、開発チームの一部の役割やあなたの中心的な役割になり得ます。時間の経過とともに、ある役割は、あなたの組織の成熟度やプラットフォームの決定に基づいて変化する可能性があるということです。
データとAIに関するアプリケーションの開発は非常に反復的なプロセスであるため、それらのプロセスの中でチームが緊密に連携し、連携時の摩擦を減らすことが非常に重要です。下図は、運用モデルのエンドツーエンドの流れと、さまざまなチームの役割と責任を示しています。
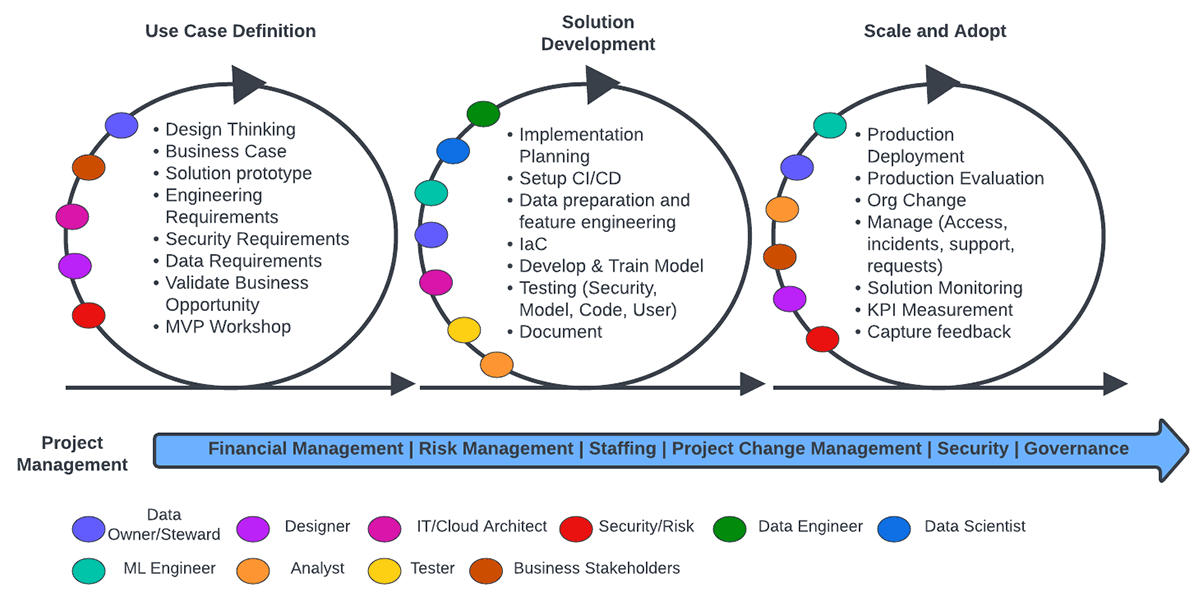
上記が示すように、プロセスには3つのコア・ステージがあります。これらは、各ループ内とループ間の反復的なエンド・ツー・エンドのオペレーティング・パイプラインの一部となっています。
各ステージは、それぞれの役割を組み合わせることで最大の価値を引き出すことができます。さらに継続的なプロジェクト管理機能があり、それは各チームが、3つのステージを跨いで実行するために適切なリソースと適切なプロセスが利用できることを担保しています。
それでは、それぞれのステージについて見ていこう。
- ユースケースの定義: プロジェクトのユースケースを定義する際には、ビジネス利害関係者と協力して、データと技術的能力をビジネス目標に整合させることが重要です。従って、データ所有者が参加することは、ユースケースの実現可能性を知らせるために重要であり、データプラットフォームがそれをサポートできるかどうかを理解することも重要です。この段階で強調される他の要素は、セキュリティとユーザーエクスペリエンスの両面で、望ましいソリューションの使いやすさを確保することに向けられます。
- ソリューション開発: この段階では、主に技術開発に焦点が当てられます。ここでは、データエンジニアリング、データサイエンス、MLエンジニアリングチームによって推進されるML/AIのコアな開発サイクルが実施され、ソリューションのテスト、検証、パッケージングなど、必要なすべての補助的なステップや要素とともに行われます。この段階はMLOpsのループ内タスクに相当し、実験が主体となる。データオーナーとアーキテクトは、適切なソースとツールを使ってコア開発チームを支援するために、この段階でも重要な役割を果たします。
- スケールと適応: ビジネスの文脈では、ML/AIアプリケーションは、それがビジネスにプラスの影響を与える場合にのみ有益である。この段階での主な目的は、エンドユーザーがアプリケーションのアウトプットを利用し、活用できるようにするための適切なメカニズムとプロセスを開発し、運用することです。また、ビジネスは静的なものではないため、パフォーマンスとKPIの継続的なモニタリング、開発チームとデータチームへのフィードバックループの実装が、この段階での基本となります。
具体的な実装方法は、組織の構造によって異なります。中央集権型からCoE型、連合型まで、様々なアプローチが可能であることは確かですが、役割と責任に関しては、上記のフローで説明した原則が重要であることに変わりはありません。
まとめ
データとAIのプロジェクトとアプリケーション開発には、多様なチームと役割が必要です。さらに、データを中心とした新しい組織パラダイムは、データを重視するために、組織内の新しい役割を効果的にサポートできるAIオペレーティング・モデルの必要性を高めています。
最後に、インフラ、データ、ツールのあらゆる要件を簡素化し、統合するのに役立つ(マルチクラウドの)プラットフォームは、その上で実行されなければならない必要なビジネスプロセスをサポートすると同時に、明確なレポーティング、モニタリング、KPI追跡を容易にする、巨大な資産であることをもう一度強調する価値があります。これにより、多様で部門横断的なチームがより効果的に協力し、本番化までの時間を短縮し、イノベーションを促進することができるのです。
データとAIの運用モデルの原則と設計方法についてもっと知りたい方は、このBlogシリーズのパート1をご覧ください。