機密データを保護するために、HabuとDatabricksはどのように連携しているか
Habu’s data clean room technology works seamlessly with Databricks infrastructure to enable privacy-preserving access to data across teams and partners.

Original : How Habu Integrates With Databricks to Protect Sensitive Data
翻訳:saki.kitaoka
先日、Databricksとの提携を発表(announce)し、すべてのLakehouseにマルチクラウドデータクリーンルームコラボレーション機能を提供することを発表しました。Databricksとの統合は、Databricks's Lakehouse technology とHabuのクリーンルームオーケストレーションプラットフォームの長所を組み合わせ、クラウドやデータプラットフォーム間でのコラボレーションを可能にし、コラボレーションによるデータサイエンス作業のアウトプットをビジネス関係者に提供するものです。このブログポストでは、以下の質問に答えることで、HabuとDatabricksがどのようにこれを実現しているかを説明します:
- データクリーンルームとは何ですか?
- Databricksの既存のデータクリーンルーム機能は何ですか?
- HabuとDatabricksはどのように連携するのですか?
さっそく始めましょう!
データクリーンルームとは何ですか?
データクリーンルームは、セキュリティや消費者のプライバシーを侵害したり、MLモデルのIPを公開したりする心配がなく、企業がデータやモデルを安全に共有できるようにする閉じた環境です。Habuが提供するクリーンルームを含む多くのクリーンルームは、安全なデータインフラ上にローコードまたはノーコードのソフトウェアソリューションを提供し、データへのアクセスやパートナーとのコラボレーションの可能性を大幅に広げます。また、クリーンルームには、データへのアクセスや監査に関するベストプラクティスのガバナンスコントロールや、データサイエンスのタスクを実行する際に個人の消費者のプライバシーを保護するために使用されるプライバシー強化技術も組み込まれています。
データクリーンルームは、ここ数年で規制やプライバシーへの懸念が高まったため、小売、メディア、ヘルスケア�、金融サービスなどの業界で広く採用されるようになりました。MLエンジニアリングやAI駆動型研究などの追加分野において、質の高い同意済みデータへのアクセスの必要性が高まるにつれ、データライフサイクルの全段階においてプライバシーを保護したデータ連携を可能にするクリーンルームの採用がますます重要になると考えられます。
Databricks、クリーンルームへ向けて動き出す
このようなニーズの高まりを受け、Databricksは昨年、Databricksの顧客にすでに馴染みのあるツールを使って、他の関係者に複製や配布をせずにデータのビューを提供するDelta Sharing プロトコルを発表しました。データのプロビジョニング後、パートナーはDatabricksがサポートするあらゆる言語で任意のワークロードを実行することができ、データ所有者は Unity Catalog.を使用した設定によりデータに対する完全なガバナンスコントロールを維持します。
Delta Sharingは、Databricksにおける安全なデータ共有への第一歩となりました。Databricksのネイティブ機能とHabuの最先端データクリーンルーム技術を組み合わせることで、Databricksの顧客は、データの内容を明らかにすることなく、データへのアクセスを共有することができるようになりました。Habuのクリーンルーム設定、分析結果のダッシュボード機能、およびアクティベーションパートナーとの統合に対するローコードアプローチにより、お客様はデータクリーンルームのユースケースセットおよびパートナーシップの可能性を拡�大することができます。
Habu + Databricks: どのように機能するか
HabuとDatabricksの統合により、ユーザーはDatabricksやHabuの機能を深く理解する必要がなくなり、目的のデータコラボレーションビジネスの成果を得ることができるようになります。Databricksの既存のセキュリティプリミティブと、Habuの直感的なClを活用しました。
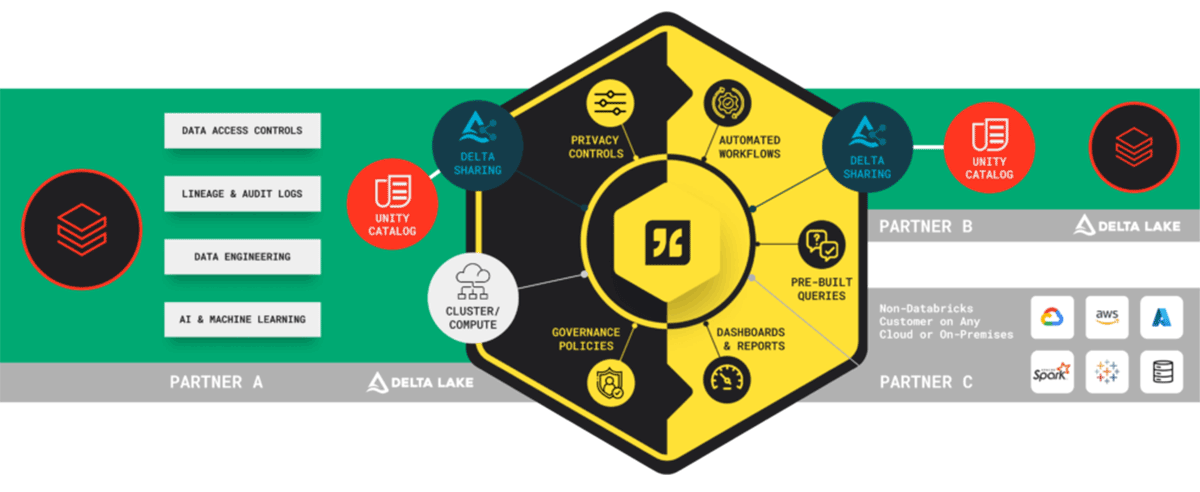
- エージェントのインストール: Databricks管理者はHabuエージェントをインストールし、HabuとDatabricksを組み合わせたクリーンルーム設定アクティビティのオーケストレーターとして機能します。このエージェントはHabuからのコマンドを聞き、あなたやパートナーがHabu UI内でクリーンルームにデータをプロビジョニングするアクションを起こしたときに、指定されたタスクを実行します。
- クリーンルームのコンフィギュレーション: Habu UI内で、あなたのチームはあなたがディクテーションできるデータクリーンルームを設定します:
- アクセス: どのパートナーユーザーがクリーンルームにアクセスできるか
- データ: パートナーに提供されるデータセット
- 質問: パートナーがどのデータ要素に対して実行できるクエリやモデルか
- 出力制御: 提供された質問の出力に関するプライバシーコントロール、および出力を使用できるユースケース(例:分析、マーケティングターゲットなど)
- これらの要素を設定すると、Habuエージェントを介してデータクリーンルームコラボレーターワークスペース内のタスクがトリガーされます。これらのタスクはDatabricksのプリミティブと相互作用してクリーンルームをセットアップし、すべてのアクセス、データ、および質問の設定がDatabricksインスタンスにミラーリングされ、含まれるパートナーのデータインフラと互換性があることを保証します。
- 質問の実行: クリーンルーム内では、すべての関係者がデータ、モデル、コードを各分析ユースケースまたは質問に明示的にレビューして承認することができます。承認されると、これらの質問はオンデマンドまたはスケジュールで実行することができるようになります。質問は、SQLまたはPython/PySparkで直接Habuで作成することも、ノートブックを接続して作成することも可能です。
クリーンルームで使用できる質問には3つのタイプがあります:
- 分析的な質問: この質問は、レポートやダッシュボードなどのインサイトに使用するための集計結果を返します。
- リスト質問: これらの質問は、ユーザー識別子や製品SKUなどの識別子のリストを返し、下流の分析、データ強化、チャネル活性化で使用されます。
- CleanML:これらの質問は、データまたはコード/IPへの直接アクセスを提供することなく、機械学習モデルのトレーニングや推論に使用することができます。
質問の実行時点で、Habuは各質問の実行ごとにユニークなユーザーを作成します��。このユーザーは、単にクエリを実行するマシンであり、指定された質問のための承認されたデータビューに基づいたデータへのアクセスが制限されています。結果は合意した目的地に書き込まれ、成功した実行後にユーザーは廃止されます。
あなたは疑問に思うかもしれませんが、Habuはどのようにして私のデータをリスクにさらすことなくこれらすべてのタスクを実行するのでしょうか?既存のセキュリティ対策に加えて、Databricksパターンの統合のすべての側面をカバーするために、3つの追加のセキュリティ層を実装しています。
- エージェント:エージェントをインストールすると、Habuはデルタシェアを作成・整理して、Habuワークスペース内でデータのビューへの安全なアクセスを提供できるようになります。このエージェントは、あなたの指示で動くマシンとして働き、Habuの個々のユーザーはエージェントのアクションを制御する能力がありません。また、そのアクションは完全に監査可能です。
- 顧客:Habuの統合が有効化された際に、顧客または組織ごとにサービスプリンシパルを作成するために、Databricksのサービスプリンシパルの概念を活用します。サービスプリンシパルは、事前に設定されたアクセス制御に従って自動化されたタスクやジョブを実行するために作成されたアイデンティティと考えることができます。このサービスプリンシパルは、あなたとHabuの間でデルタシェアを作成するために利用されます。顧客レベルでサービスプリンシパルを実装することで、Habuが他の顧客やHabuユーザーからの指示に基づいてあなたのアカウントでアクションを実行できないように保証します。
- 質問:最後に、パートナー関係を完全に保護するために、クリーンルーム内で作成された各質問に対して質問実行時にサービスプリンシパルを適用します。これは、個々のユーザーがクリーンルームに提供されたデータへのアクセスを持つことはないということを意味します。代わりに、質問が実行されるとき(そしてそれが実行されるときだけ)、質問を実行する権限を持つ新しいサービスプリンシパルユーザーが作成されます。実行が終了すると、サービスプリンシパルは廃止されます。
まとめ
Databricksとの統合ソリューションには多くの利点があります。Delta Sharingは、Lakehouseからの大量のデータを迅速かつ安全に共有することを可能にします。さらに、クリーンルーム内のメダリオンアーキテクチャからデータを共有する能力は新たな洞察を開きます。最後に、Pythonや他のコードをコンテナ化されたパッケージで実行する能力は、顧客がプライベートデータ上でMLを訓練し、大規模言語モデル(LLM)を検証することを可能にします。
Databricksに固有のこれらすべてのセキュリティメカニズム、およびHabuに組み込まれたセキュリティとガバナンスのワークフローは、あなたが協力関係に関与するデータワークフローの詳細だけでなく、最も戦略的なパートナーとのデータパートナーシップから生じるビジネス成果にも焦点を当てることができるように保証します。
HabuとDatabricksのパートナーシップについて詳しく知りたい方は、5月17日に予定されている共同ウェビナー「クリーンルームを活用したセキュアなデータコラボレーションの力を解放する」に今すぐ登録してください(register now)。または、Habuの代表者と連絡を取ってデモを体験し、HabuとDatabricksの力を自分で体感してみてください。(connect with a Habu representative)


