レイクハウスAIがリアルタイム計算でモデルの精度を向上させる方法

機械学習モデルの予測精度は、学習と推論の両方に用いられるデータの品質をそのまま反映します。 通常、特徴量(モデルへの入力データ)は事前に計算して保存し、推論時にストアから取得してモデルへ入力する。 モデルの性能は、特徴計算に使用するデータの鮮度と直接相関することが多いため、これらの特徴を事前に計算できない場合に課題が生じる。 オンデマンド・フィーチャー・コンピュテーションを発表することで、このようなフィーチャー・クラスのサービスを簡素化することができる。
レコメンデーション、セキュリティシステム、不正検知などのユースケースでは、これらのモデルのスコアリング時にオンデマンドで機能を計算する必要がある。 代表的なシナリオの例は、次のとおりである。
- 特徴量の入力データがモデル提供時にしか得�られない場合。 例えば、
distance_from_restaurantは、モバイル機器によって決定されたユーザーの最後の既知の位置を必要とする。 - ある機能の価値が、それが使われる文脈によって変化する状況。
デバイスの種類がデスクトップと モバイルでは、エンゲージメントの指標の解釈が大きく異なる。 - 機能を事前に計算し、保存し、リフレッシュすることがコスト的に困難な場合。 動画ストリーミングサービスは、数百万人のユーザーと数万本の映画を持っている可能性があり、
avg_rating_of_similar_moviesのような機能を事前に計算することは法外である。
これらのユースケースをサポートするためには、推論時に特徴を計算する必要がある。 しかし、モデル学習のための特徴計算は、通常、Apache Spark(™)のようなコスト効率が高く、スループットが最適化されたフレームワークを使用して実行される。 リアルタイム採点にこれらの機能が必要な場合、これは2つの大きな問題を引き起こす:
- 人的労力、遅延、トレーニング/サービングの偏り:このアーキテクチャでは、JavaやC++のようなサーバーサイドでレイテンシを最適化した言語で特徴計算を書き換える必要があることがあまりにも多い。 この場合、2つの異なる言語で特徴量が作成されるため、トレーニング・サービス・スキューの可能性が生じるだけでなく、機械学習エンジニアはオフラインとオンラインのシステム間で特徴量計算ロジックを維持・同期する必要がある。
- モデルの機能を計算し、提供するためのアーキテクチャの複雑さ。 このようなフィーチャーエン��ジニアリングパイプラインシステムは、サービスを提供するモデルと連動して展開され、更新される必要がある。 新しいモデルのバージョンがデプロイされると、新しい機能定義が必要になる。 このようなアーキテクチャはまた、不必要な配備の遅れをもたらす。 機械学習エンジニアは、レート制限、リソース制約、ネットワーク帯域幅に直面するのを避けるために、新しい特徴計算パイプラインとエンドポイントが本番のシステムから独立していることを確認する必要がある。
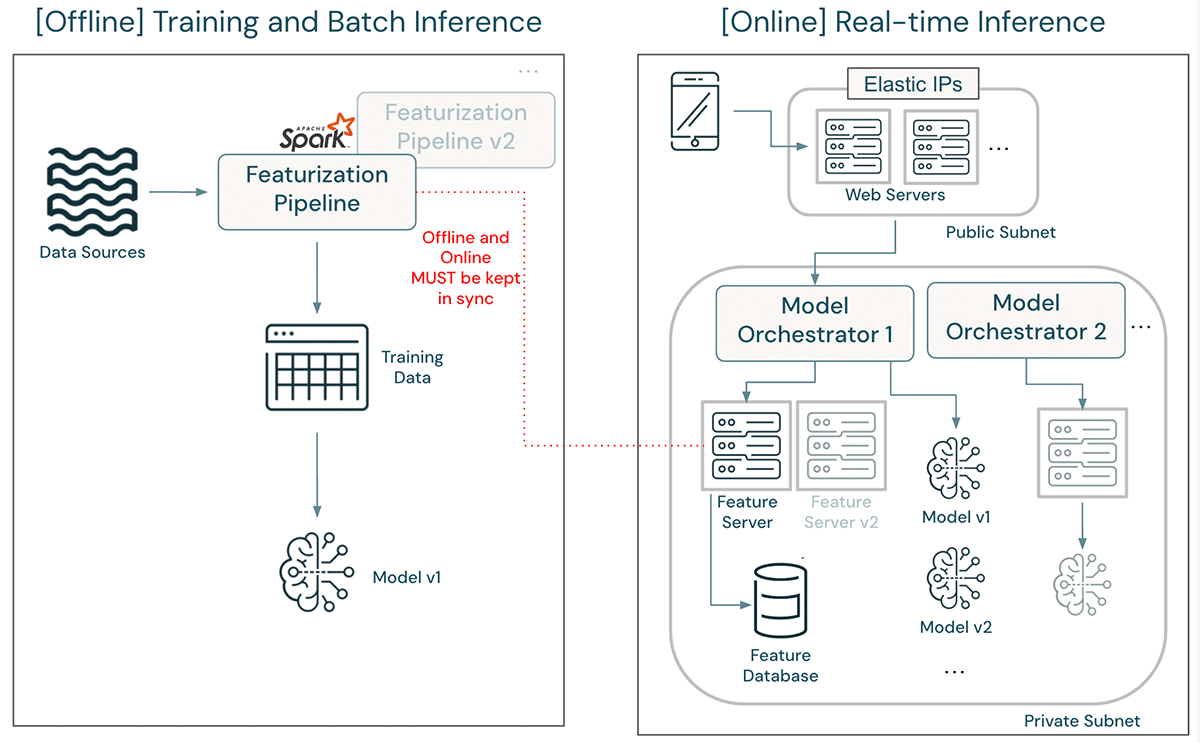
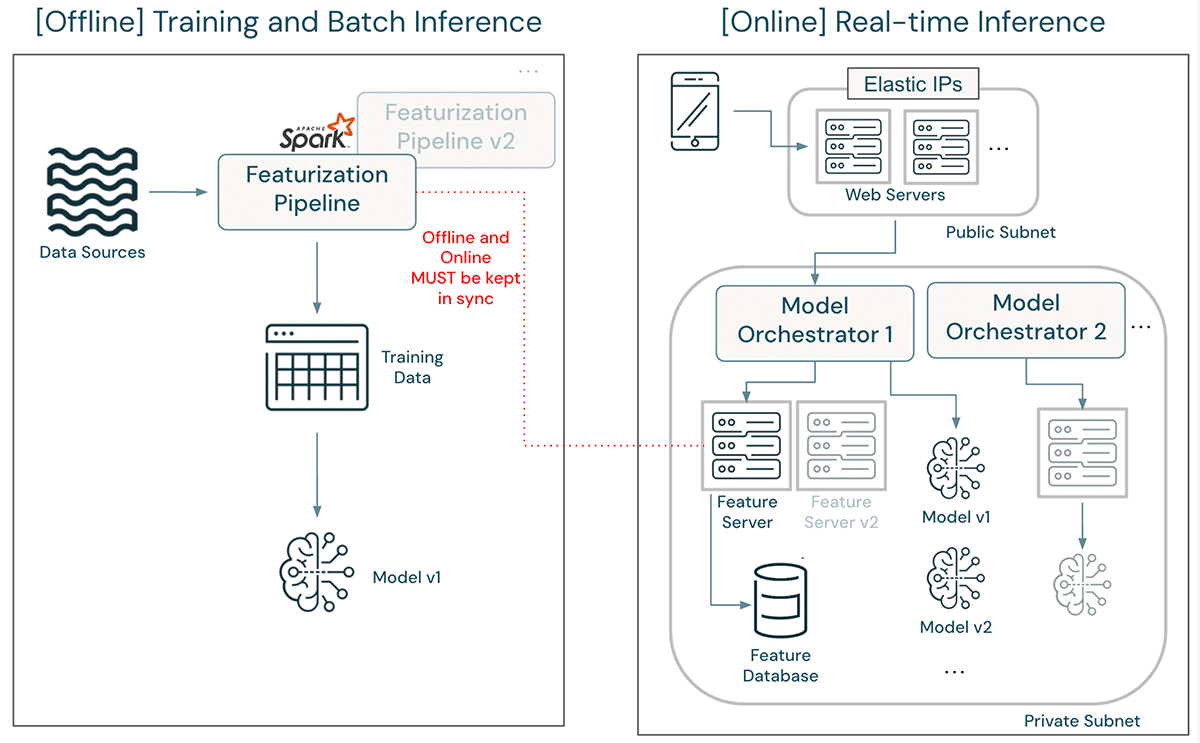
上記のアーキテクチャでは、機能定義の更新は大仕事となる可能性がある。 更新されたフィーチャライゼーション・パイプラインは、古い特徴定義でのトレーニングとバッチ推論をサポートし続けるオリジナルと同時に開発され、デプロイされなければならない。 モデルは、更新された特徴定義を使用して再トレーニングされ、検証されなければならない。 デプロイが許可されると、エンジニアはまずフィーチャー・サーバー内のフィーチャー計算ロジックを書き換え、本番トラフィックに影響を与えないように、独立したフィーチャー・サーバー・バージョンをデプロイしなければならない。 デプロイ後、更新されたモデルのパフォーマンスが開発時と同じであることを確認するために、数多くのテストを実行する必要がある。 モデルオーケストレーターは、新しいモデルにトラフィックを誘導するように更新されなければならない。 最終的に、ある程度の時間が経てば、旧モデルと旧機能のサーバーを撤去することができる。
このアーキテクチャを簡素化し、エンジニアリング速度を向上させ、可用性を高めるために、Databricksはオンデマンド機能計算のサポートを開始する。 この機能はUnity Catalogに直接組み込まれており、モデルの作成と展開のためのエンドツーエンドのユーザージャーニーを簡素化する。
オンデマンド機能により、フィーチャーエンジニアリングパイプラインの複雑さが大幅に軽減されました。 オンデマンド機能により、顧客ごとに異なる複雑な変換を管理する必要がなくなります。 その代わりに、単純にベースとなる特徴のセットから始めて、トレーニングや推論中にオンデマンドでクライアントごとに変換することができます。 本当にオンデマンドの機能によって、次世代のモデルを作る能力が向上した。 - クリス・メシエ、MissionWiredのシニア機械学習エンジニア
機械学習モデルで関数を使う
Unity Catalogのフィーチャーエンジニア�リングにより、データサイエンティストはテーブルから事前にマテリアライズされたフィーチャーを取得し、関数を使用してオンデマンドでフィーチャーを計算することができる。 オンデマンドの計算はPython User-Defined Functions (UDF)として表現され、Unity Catalogのエンティティとして管理される。 関数はSQLで作成され、SQLクエリ、ダッシュボード、ノートブック、そして現在ではリアルタイムモデルのフィーチャーを計算するために、レイクハウス全体で使用することができる。
UCリネージグラフは、モデルのデータと関数への依存関係を記録する。
モデルに関数を使用するには、create_training_setの呼び出しに関数を含める。
この関数はSparkによって実行され、モデルのトレーニングデータを生成する。
また、この関数はネイティブのPythonとpandasを使ってリアルタイムで実行される。 スパークはリアルタイムの経路には関与しないが、トレーニング時に使用されたものと同等の計算が保証される。
簡素化されたアーキテクチャ
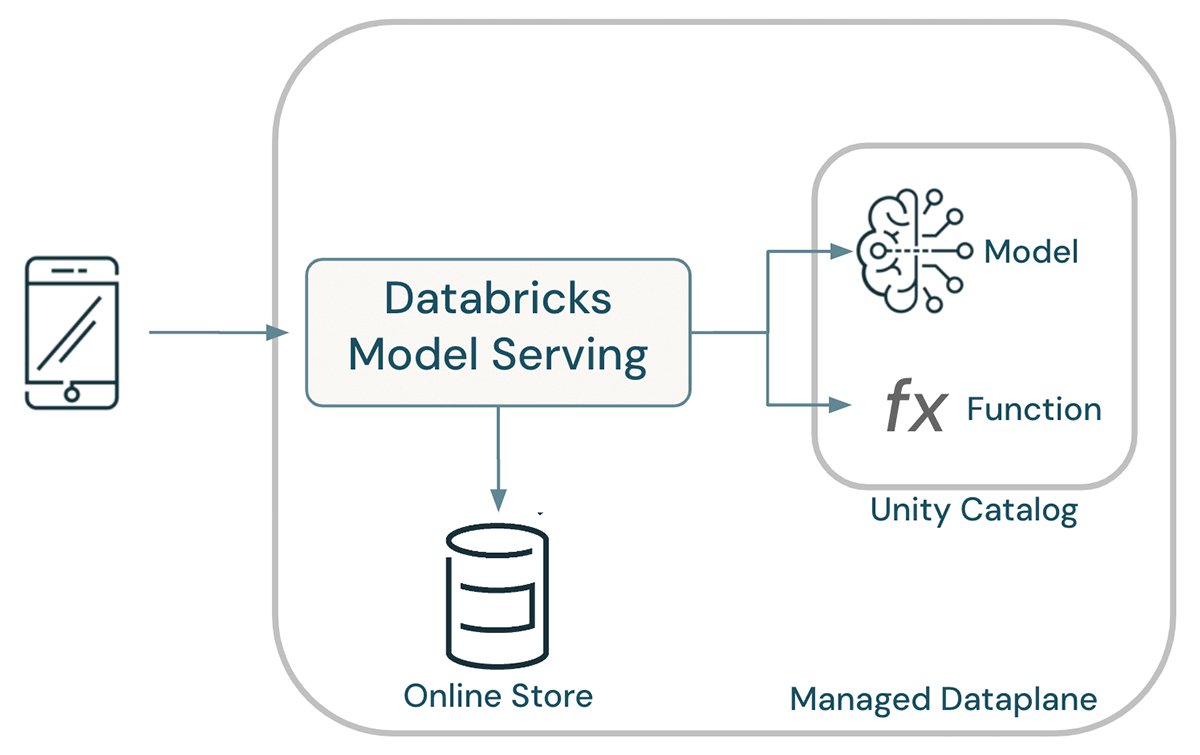
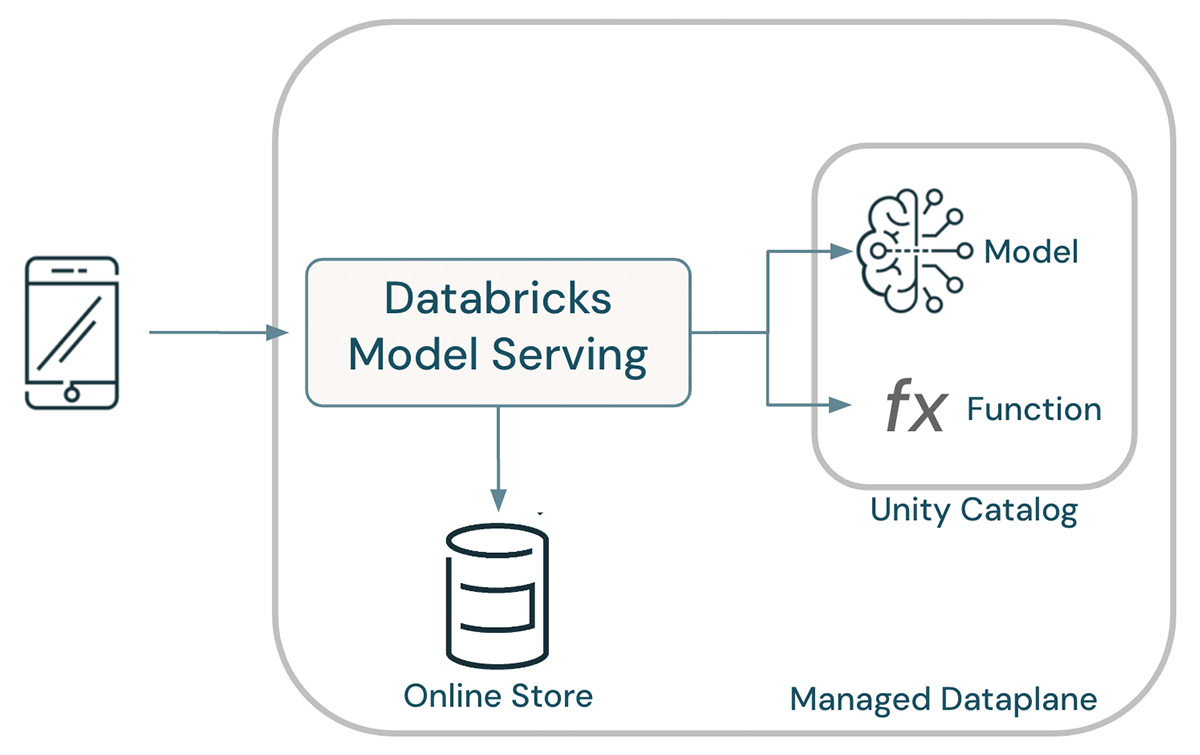
モデル、ファンクション、データはすべてUnity Catalog内に共存し、統一されたガバナンスを実現する。 共有カタログにより、データサイエンティストはモデリングにフィーチャーや関数を再利用することができ、組織全体でフィーチャーの計算方法に一貫性を持たせることができる。 その際、モデルの系統は、モデルへの入力として使用される関数とテーブルを決定するため��に使用され、トレーニングに起因するスキューの可能性を排除する。 全体として、この結果、アーキテクチャは劇的に簡素化された。
Lakehouse AIはモデルのデプロイを自動化する。モデルがデプロイされると、Databricks Model Servingはフィーチャーのライブ計算を可能にするために必要なすべての機能を自動的にデプロイする。 リクエスト時には、事前にマテリアライズされたフィーチャーがオンラインストアから検索され、オンデマンドのフィーチャーはPython UDFのボディを実行することで計算される。
単純な例 - 平均ホバー時間
この例では、オンデマンド機能がJSON文字列を解析し、ウェブページ上のホバー時間のリストを抽出している。 これらの時間は平均化され、平均値は特徴量としてモデルに渡される。
モデルへのクエリは、ホバー時間を含むJSON blobを渡す。 例えば、こうだ:
このモデルはオンデマンドで平均ホ��バータイムを計算し、平均ホバータイムを特徴としてモデルを採点する。
洗練された例 - レストランまでの距離
この例では、レストラン推薦モデルは、ユーザーの位置情報とレストランIDを含むJSON文字列を受け取る。 レストランの位置は、オンラインストアに公開されたマテリアライズ済みのフィーチャーテーブルから検索され、オンデマンド機能がユーザーからレストランまでの距離を計算する。 この距離はモデルの入力として渡される。
この例では、レストランの場所を検索し、そのレストランからユーザーまでの距離を計算する変換が行われている。
詳しく見る
APIドキュメントと追加ガイダンスについては、Pythonユーザー定義関数を使用したオンデマンド機能の計算を参照してください。
Databricksと共有したいユースケースをお持ちですか? お問い合わせは、[email protected]まで。



{kind=link}
{kind=link}