大手ベンチャーキャピタル会社が Databricks で GenAI を構築する方法
GenAI アプリケーションをうまく構築するには、最先端の最新モデルを活用するだけでは不十分です。データ、モデル、インフラストラクチャを柔軟かつスケーラブルに統合し、本番運用に対応した複合AIシステムを開発する必要があります。これには、オープンソース モデルと独自モデルの両方、ベクター データベースへのアクセス、モデルの微調整、構造化データのクエリ、エンドポイントの作成、データの準備、コストの管理、ソリューションの監視を行う機能が必要です。
このブログでは、 Databricksへの投資も行っている大手ベンチャーキャピタル会社 (このブログでは「VC」と表記) の GenAI 変革について見ていきます。この VC は、社内でイノベーションを推進するだけでなく、将来の投資を導く GenAI アプリケーションを構築する機会をより深く理解したいと考えていました。この VC は、構造化ファンド データから「 Databricksにいくら投資したか、現在の価値はいくらか」などの情報を照会する Q&A インターフェイスなど、複数の GenAI ユース ケースを開発しました。また、ユーザーの質問に回答するITアシスタントを構築し、 IT部門による回答の所要時間を大幅に短縮しました。追加のユース ケースが急速に開発されており、現在も開発中です。このブログでは、 Databricks Professional サービスとのコラボレーションで現在新しいアプリケーションに拡張されているフレームワークに焦点を当てながら、これら 2 つの初期アプリケーションの詳細について説明します。
ユースケース#1:ファンドデータに関するQ&A
VC には、複数のファンドにまたがるテクノロジー系スタートアップ企業に戦略的に投資するジェネラル パートナー (GP) が多数います。 VC にはすでに多くの GP リクエストを解決する強力なセルフサービス ダッシュボードがありますが、特定の分析は、必要な情報を取得するために SQL クエリを記述して実行する必要がある戦略家やアナリストによる手動プロセスを経る必要があります。 VC は、アナリストと協力して GenAI を使用してこのプロセスを自動化する支援を当社に依頼し��ました。 目標は、GP が尋ねる一般的な質問のほとんどを自動化できる Slackbot を設定し、応答時間を短縮してアナリストがより複雑なタスクに取り組めるようにすることでした。
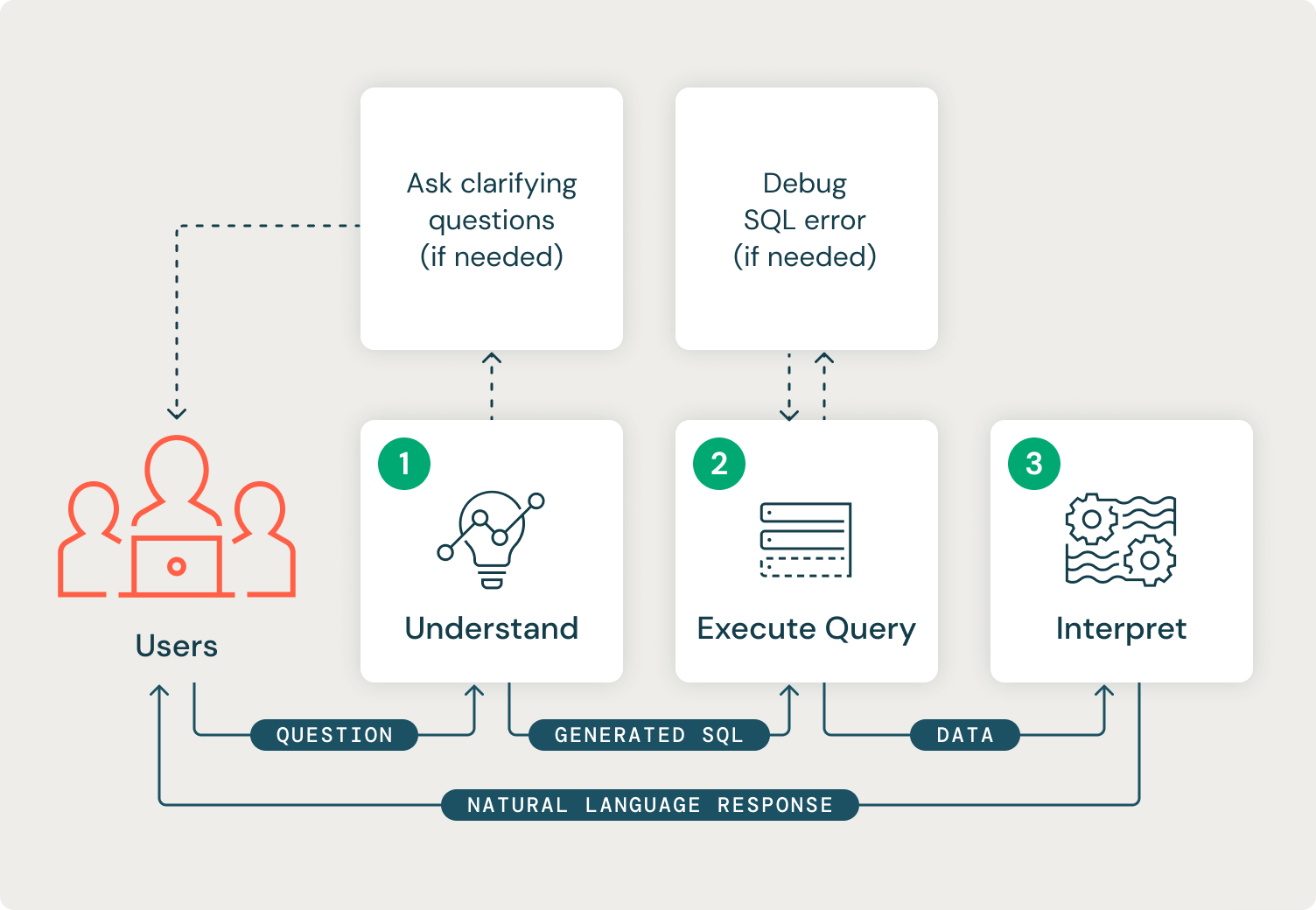
システム設計
このシステムを構築するには、LLM のパワーを活用して SQL コードを生成し、生成された SQL を実行およびデバッグし、返された構造化データを解釈して自然言語で質問に答える必要がありました。
また、アナリストがこれらのリクエストを完了する際には、次のような暗黙の知識も考慮しました。
- 要求は、列の使用方法に関する注意事項を含め、データ テーブル スキーマを理解していることを前提とする必要があります。
- 要求は、特に指定がない限り、最新のデータに基づいて行う必要があります。
- ファーストネームを含むリクエストはジェネラルパートナーの名前とみなされま��す(例: 「ラファエルは今年何に投資しましたか?」)。
- 会社名はデータベース内の会社名と完全に一致しない場合があります (「databricks」と「Databricks, Inc.」など)。
ユーザーの質問から意図が明確でない場合は、 システム で明確にする質問をする必要があります。たとえば、ユーザーが「アダムの投資」について質問し、アダムという名前のジェネラル パートナーが 2 人いる場合は、ユーザーがどのアダムについて知りたいのかを明確にする必要があります。
また、私たちのシステムは、3つの異なる段階を経て継続的に進歩する必要があります。 最初の段階は、ユーザーの要求の意図を理解することです。 この段階では、システムは利用可能なデータ テーブルを理解し、目的のタスクを実行するために有効な SQL クエリを生成するためにユーザーから十分な情報があるかどうかを判断する必要があります。 情報が十分でない場合は、ユーザーに明確な質問をしてプロセスを再開する必要があります。 最初のステージの出力は有効な SQL 文字列になります。
2 番目の段階では、生成された SQL を実行し、返されたエラーやデータの問題の自動デバッグを実行します。 このステージの出力は、ユーザーの質問に答えるために必要なデータを含むデータ フレームになります。
最後の第 3 段階��では、データ結果を解釈して、ユーザーへの自然言語応答を生成します。 このステージの出力は文字列応答になります。
このシステムは、エージェントアプローチ(ReAct)または有限状態マシン(FSM)を使用して構築できます。 エージェント アプローチは、タスクをさまざまな組み合わせや順序で使用する必要がある場合や、タスク選択の選択があいまいな場合など、複雑で動的な環境で優れた効果を発揮します。 エージェントは、デバッグ、メモリ管理、制御性、解釈可能性において複雑さをもたらす傾向があります。 FSMベースのシステムは、よりシンプルで明確に定義されたプロセスに適用し、決定論的な結果をもたらします。 FSM の簡素化された決定論的なフローにより、デバッグと解釈が容易になります。 FSMは、エージェントベースのシステムよりも柔軟性が低い傾向があり、多くの可能な状態が必要な場合、スケーリングが困難な場合があります。
FSMのアプローチに決めたのは、以下の理由からです。
- システムのフローはユーザークエリごとに一貫しており、ステージの入力と出力は非常��に明確に定義されています。
- 解釈可能性とデバッグ機能はこのプロジェクトにとって最も重要であり、状態ベースのアプローチによりこれが設計上可能になります。
- 現在の状態に応じて、システムのアクションをより直接的に制御できます。
私たちのシステムを構築するためには、モデルを実行し、Slackbot からのリクエストに応答できるホストされたエンドポイントが必要でした。Databricks Model Serving を使用することで、MLflowのあらゆるネイティブモデルをホストできる、簡単でスケーラブルな本番環境対応のモデルエンドポイントを実現できます。Databricks External Models および Model Serving を使用することで、さまざまなモデルを迅速にベンチマークし、最もパフォーマンスの高いモデルを選択することができました。Databricks には、実験、評価、およびデプロイメントを 1 つのインターフェイスで簡単に管理できる MLflow のビルトイン統合機能が備わっています。特に MLflow では、汎用 Python 関数モデル(pyfunc)の追跡が可能です。汎用Python関数モデルは、任意のPythonクラスをモデルとして素早くラップし、ログに記録するために使用できます。私たちはこのパターンを使用して、ユニットテスト可能なコアクラスを素早く反復し、それをpyfuncでラップしてMLflowに記録しました。
FSMの各ステートには、明確に定義された入力、出力、および実行パターンがありました。
- 理解 : 関数呼び出し が 可能なチャット フレーバー LLM が必要です 。関数呼び出し LLM には、ユーザーのクエリとともに使用可能な関数を定義する構造化データ オブジェクトが提供されます。LLM は、使用可能な関数を呼び出すか、自然言語応答で応答するかを決定します。私たちのシステムでは、SQL 文字列を入力として受け取る `sql_query` 関数を LLM に提供しました。次に、LLM にデルタ テーブル スキーマを提供し、使用可能な関数を呼び出せなかった場合にユーザーに明確な質問をするように指示しました。
- クエリの実行:シ�ステムは、最初のステップで生成されたSQLクエリを実行し、返される可能性のあるSQLエラーをデバッグします。モデル サービング エンドポイントから、システムは Databricks Databricks Databricks SDK Python使用して Databricks デルタ テーブルに認証し直すことができます。このステップの出力は、 SQLクエリから返された、解釈できる状態のデータ フレームです。
- 解釈:元のユーザーの質問、生成された SQL クエリ、および取得されたデータのデータ フレームをモデルに渡し、ユーザーの質問に答えるように要求する LLM 呼び出しで構成されます。
VC は、モデルサービングエンドポイントへの API 呼び出しを Slackbot でラップし、社内の Slack ワークスペースにデプロイしました。 私たちは Slack の組み込みスレッドを利用して会話状態を保存し、GP がフォローアップの質問をできるようにしました。
評価
このプロジェクトで特に難しかったのは評価でした。このシステムは、意思決定を行う一般開業医に財務情報を提供するため、応答の正確さが最も重要です。生成されたSQLクエリ、返されたデータ、およ�び最終応答を評価する必要がありました。非構造化 RAG では、最終結果を評価セットの参照回答と比較するために、 ROUGEなどのメトリクスがよく使用されます。私たちのシステムでは、言語が似ているために ROUGE スコアが高くても、応答の数値結果がまったく間違っている可能性があります。
SQL クエリの評価も難しい場合があります。 同じことを実現するために、さまざまな SQL クエリを記述することが可能です。 また、列名にエイリアスが付けられたり、評価データでは想定されていなかった追加の列が取得されたりする可能性もあります。 たとえば、「ラファエルの今年の投資は?」というような質問です。 投資先の企業名のみを返す SQL クエリの生成をトリガーしたり、投資額を追加で含めたりすることができます。
私たちは、評価セットで 3 つのメトリックを評価することで上記の問題を解決しました。
- それは正しいものを照会しましたか? ⇒ クエリされたテーブルと列の リコール
- クエリは正しいデータを取得しましたか? ⇒ データ応答内の重要な文字列と数値を思い出してください
- 最終的に生成された回答は正しい言語でしたか? ⇒ ROUGE (最終的に生成された応答)
結果
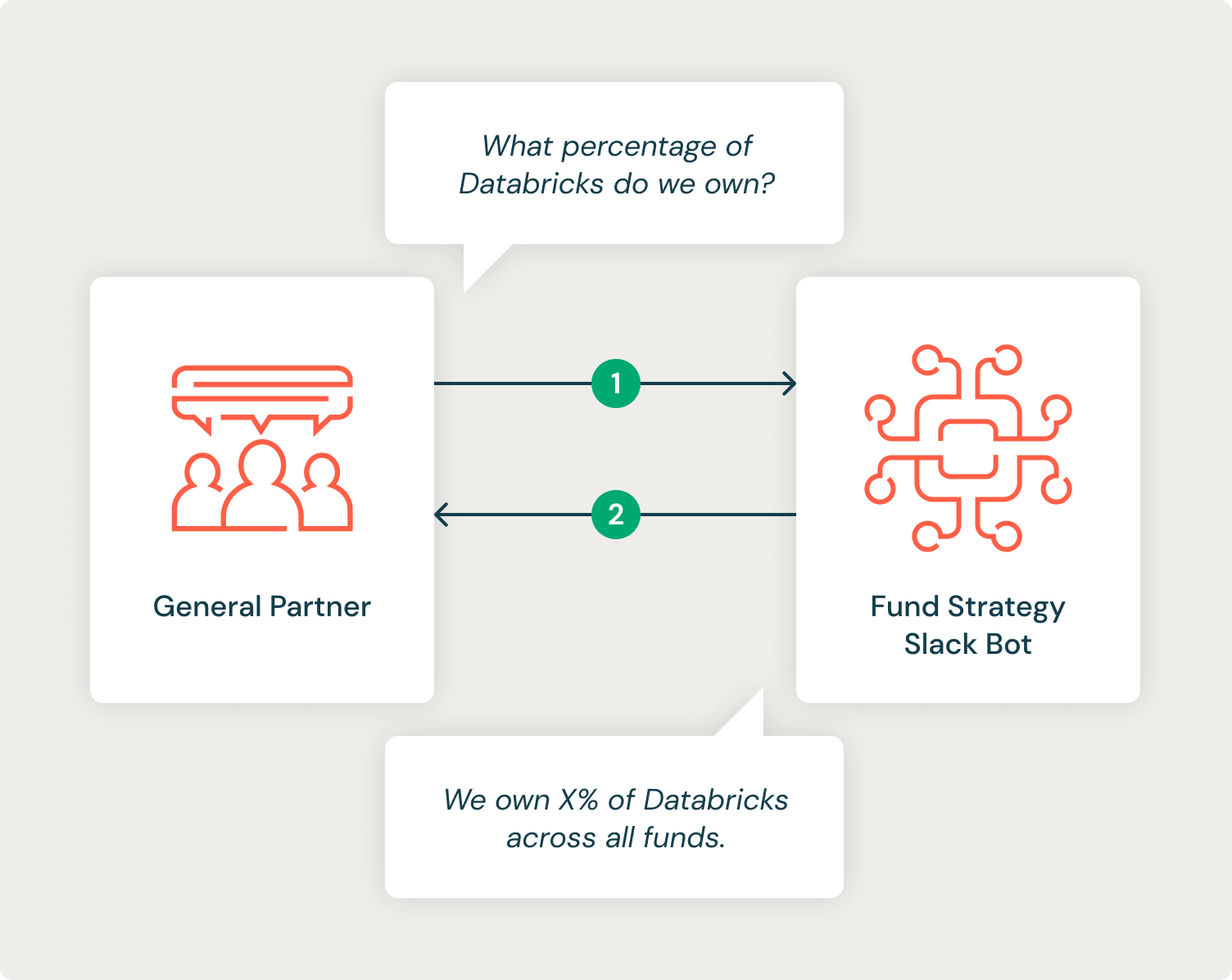
社内の VC 関係者からのフィードバックは非常に好意的で、モデル作成中に高いメトリクスが観察されました。 会話の例(識別情報の削除)を以下に示します。

ユースケース #2: IT ヘルプデスク アシスタント
多くの企業と同様に、VC の従業員はITヘルプデスクからサポートを受けるためにIT E メール エイリアスに E メールを送信することができ、これによりITチケット システムにチケットが作成されます。 IT 部門は社内ドキュメントを Confluence に保存しており、このユースケースの目標は、適切な Confluence ドキュメントを見つけ、関連するドキュメントへの��リンクとユーザーのリクエストを解決するための手順を IT チケットに返信することでした。
システム設計
APIsITGenAI ユースケースでは、 チケット システムによって提供される を使用して、新しいチケットを定期的にチェックし、それらをバッチで処理するジョブを実行します。生成された要約、リンク、および最終応答は、IT チケット システムに返送されます。 これにより、IT 部門は GenAI ソリューションから得られた情報を活用しながら、選択したツールを引き続き使用できるようになります。
Confluence からのITドキュメントはAPIによって抽出され、取得用にベクター ストア ( Databricks Vector Search 、FAISS、Chroma など) に格納されます。社内ドキュメントのナレッジ リポジトリでの RAG でよくあることですが、私たちは Confluence ページを繰り返し処理してコンテンツをクリーンアップしました。生の E メール スレッドを渡すと、E メール署名などのノイズ要素が原因で Confluence コンテキストの取得が不十分になることがすぐにわかりました。取得前にLLMステップを追加して、E メール チェーンを 1 文の質問に要約しました。これには 2 つの目的がありました。取得が大幅に改善され、 IT部門は E メールのやり取りをスクロールせずに、リクエストの 1 文の要約を読むことができるようになりました。

適切な Confluence ドキュメントを取得した後、GenAI ヘルプデスク アシスタントは、ユーザーの要約された質問に対する潜在的な回答を生成し、すべての情報 (要約された質問、Confluence リンク、および回答) を IT 部門のみが閲覧できるプライベート メモとして IT チケットに投稿します。 IT 部門はこの情報を使用して、ユーザーのチケットに応答できます。
前のユースケースと同様に、この RAG 実装は、新しいレコードが到着するとそれを処理できるストリーミング ジョブに簡単にデプロイできるように、ラップされた PyFunc として記述されています。
DatabricksワークフローとSpark 構造化ストリーミングを利用して、MLflow ITからモデルを読み込み、Databricks LLMチケットに適用し、結果をポストバックしました。 外部モデルを 使用すると、 モデルを簡単に切り替えて、パフォーマンスが最適なモデルを見つけることができます。この設計パターンにより、より安価で、より高速で、より優れたオプションが利用可能になったときに、モデルを簡単に切り替えることができます。 ワークフロー Databricksは、ワークフローをCI/CD システムに本番環境化するための のソリューションであるDatabricks Asset Bundles を使用して自動的にデプロイされました 。
結果
IT ヘルプデスク アシスタントは即座に成功を収め、各 IT チケットに重要な情報を追加して、IT ヘルプデスクの解決を迅速化しました。 以下は、IT チケットと IT ヘルプデスク アシスタントからの応答の例です。
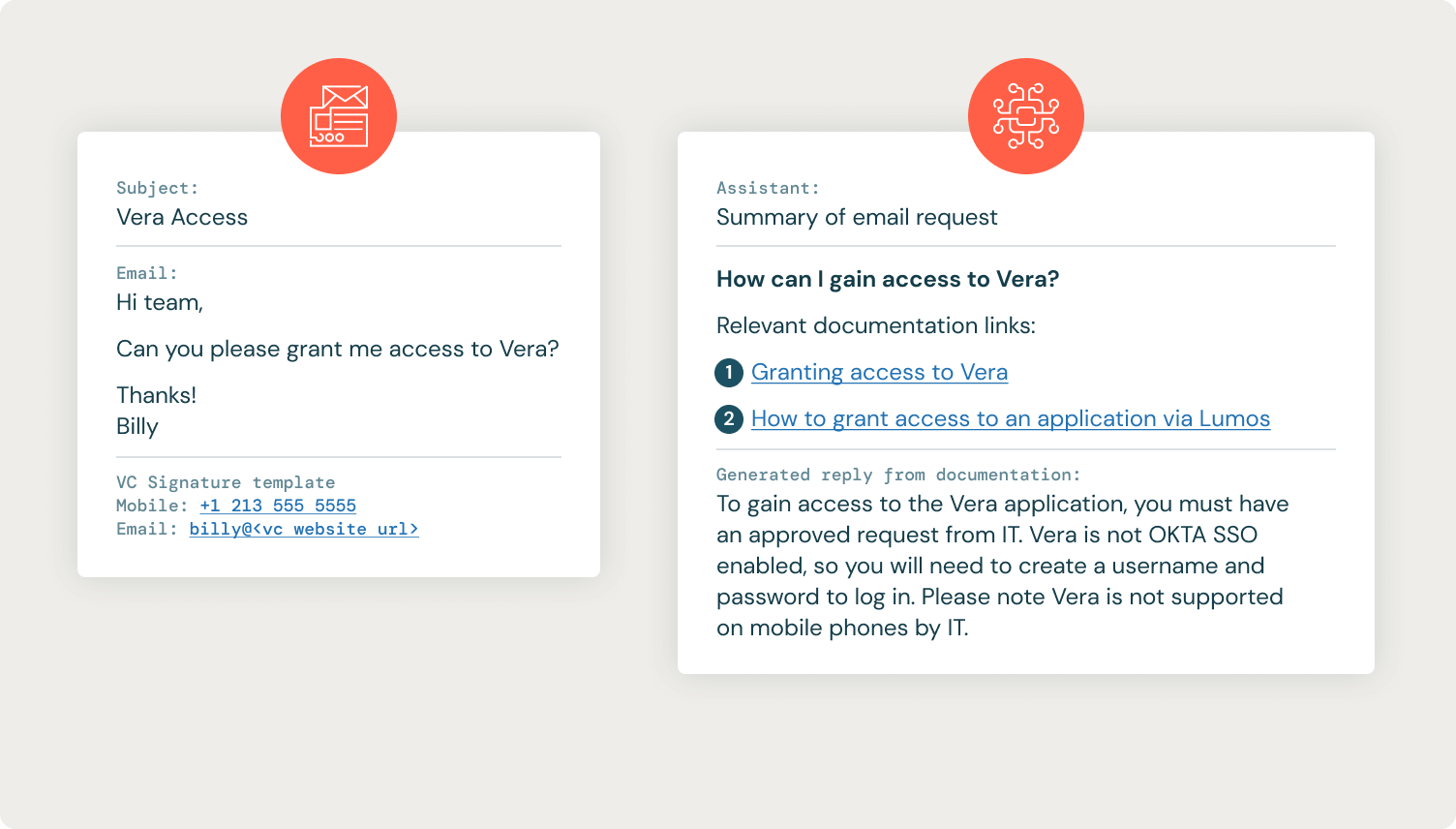
多くのリクエストは依然としてIT部門による手動処理が必要ですが、必要な手順の簡単な概要を提供し�、 ITヘルプデスクを関連する Confluence ドキュメント ページに直接リンクすることで、解決プロセスをスピードアップすることができました。
結論と次のステップ
これらのソリューションにより、VC は初の本番運用 GenAI アプリケーションとプロトタイプ ソリューションを新しいユースDatabricks AIケース向けにリリースすることができました。 Databricks は、 GenAI 成熟プロセス にわたって次世代の複合 システムを実現します 。データ処理、ベクトル検索、エンドポイントの導入、ファインチューニングモデル、結果モニタリングのための一連のツールを標準化することで、企業はアプリケーションの作成、コスト管理、新しいイノベーションへの適応をより簡単にする本番運用GenAIフレームワークを作成できます。この急速に変化する環境の中で。
VC はファインチューニングを評価しながら、これらのプロジェクトをさらに開発しています。たとえば、GenAI ITアシスタントの応答の口調をIT部門に似せるように調整しています。Databricksは MosaicML を買収したDatabricksで、ファインチューニング プロセスを簡素化し、企業が指示ファインチューニングまたは継続的な事前トレーニングを通じて自社のデータで GenAI モデルを簡単にカスタマイズできるようにしています。今後の機能により、 Databricksは組織全体でユーザー フィードバックを収集できるチャットのようなインターフェイスに RAG システムを迅速に展開できるようになります。Databricks Databricks 、あらゆる業界の組織が GenAI を急速に採用しており、技術的な障壁を迅速に克服する方法を見つけた企業が強力な競争上の優位性を獲得できることを認識しています。
詳細情報:

