Apache Sparkのための新しいプログラミング言語としての「英語」

翻訳: Masahiko Kitamura
オリジナル記事:Introducing English as the New Programming Language for Apache Spark
はじめに
私たちは、皆様のSpark体験を豊かにするために設計された革新的なツールである、Apache Sparkの英語SDKを発表できることを嬉しく思います。Apache Spark™は、世界208の国と地域から年間10億以上のダウンロードを記録し、大規模データ分析を大きく発展させました。ジェネレーティブAIの革新的なアプリケーションであるEnglish SDKは、Sparkをこれまで以上にユーザーフレンドリーで親しみやすいものにすることで、この活気あるコミュニティの拡大を目指します!
動機
GitHub Copilotは、AIによるコード開発の分野に革命をもたらした。強力な反面、ユーザーは生成されたコードを理解してコミットする必要がある。レビュアーもコードを理解しないとレビューできない。これは、より広範に採用されるための制限要因になるかもしれない。また、特にSparkのテーブルやDataFrameを扱うときに、コンテキストで苦労することがある。添付のGIFはこの点を示しており、Copilotはウィンドウの仕様を提案し、存在しない'dept_id'カラムを参照しています。

AIを副操縦士として扱うのではなく、AIを運転手にして、私たちは豪華な後部座席に座ろうか?そこで英語SDKの出番だ。過去10年以上にわたって、APIドキュメント、オープンソースプロジェクト、質問と回答、チュートリアル、書籍など、オープンで高品質なコンテンツを大量に提供してきた素晴らしいSparkコミュニティのお��かげで、最先端の大規模言語モデルはSparkを熟知していることがわかりました。そして今、私たちはGenerative AIのSparkに関する専門知識を英語版SDKにベイクした。複雑な生成コードを理解する代わりに、多くの人が理解できる英語の簡単な指示で結果を得ることができる:
英語版SDKは、SparkのテーブルとDataFrameを理解しているため、複雑な処理に対応し、DataFrameを直接かつ正確に返します!
私たちの旅は、英語をプログラミング言語として使用し、Generative AIがこれらの英語の命令をPySparkとSQLコードにコンパイルするというビジョンから始まりました。この革新的なアプローチは、プログラミングへの障壁を下げ、学習曲線を単純化するように設計されています。このビジョンがEnglish SDKの原動力であり、私たちの目標はSparkのリーチを広げ、この非常に成功したプロジェクトをさらに成功させることです。
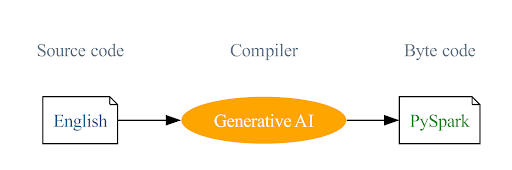
英語SDKの特徴
英語版SDKは、以下の主要機能を提供することで、Sparkの開発プロセスを簡素化します:
- データの取り込み: SDKは、提供された説明を使用してウェブ検索を実行し、LLMを使用して最も適切な結果を決定し、この選択されたウェブデータをSparkにスムーズに取り込むことができます。
- DataFrameの操作: SDKは、与えられたDataFrameに対して、変換、プロッ�ト、および英語の記述に基づく説明を可能にする機能を提供します。これらの機能により、コードの可読性と効率が大幅に向上し、DataFrameに対する操作が簡単かつ直感的になります。
- User-Defined Functions (UDFs): SDKは、UDFを作成するための合理化されたプロセスをサポートしています。シンプルなデコレーターを使用すると、docstringを提供するだけで、AIがコード補完を処理します。この機能により、UDFの作成プロセスが簡素化され、AIが残りを処理する間、あなたは関数の定義に集中することができます。
- キャッシング:SDKは、実行速度の向上、結果の再現性の向上、コスト削減のためにキャッシングを組み込んでいます。
例
英語版SDKの使い方を説明するために、いくつかの例を見てみよう:
データの取り込み
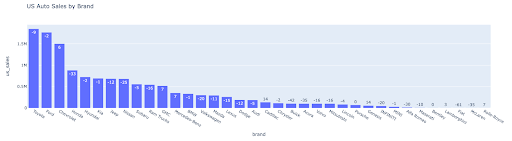
もしあなたがデータサイエンティストで、アメリカの自動車販売台数2022台をインジェストする必要があるなら、たった2行のコードでこれができる:
データフレーム操作
SDKでは、DataFrame dfが与えられると、df.aiで始まるメソッドを実行することができます。これには、変換、プロット、DataFrameの説明などが含まれます。
PySpark DataFrameの部分関数をアクティブにする:
auto_df`の概要を説明する:
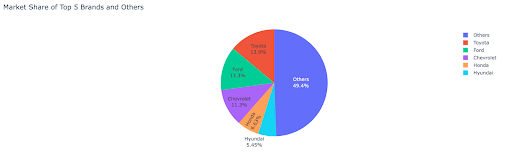
自動車関連企業��の市場シェア分布を見る:
最も成長したブランドを手に入れること:
| brand |
us_sales_2022 |
sales_change_vs_2021 |
|
Cadillac |
134726 |
14 |
DataFrameの説明を得る:
要約すると、この DataFrame は、2021 年と比較して 2022 年の売上変動が最も大きいブランドを検索しています。売上高の変化で降順にソートされた結果が表示され、一番上の結果のみが返されます。
User-Defined Functions (UDFs)
SDKはシンプルで洗練されたUDF作成プロセスをサポートしています。spark_ai.udfデコレーターを使用すると、docstringで関数を宣言するだけで、SDKが裏で自動的にコードを生成します:
これで、SQLクエリやDataFrameでUDFを使用できるようになりました。
結論
English SDK for Apache Sparkは、開発プロセスを大幅に向上させる非常にシンプルかつ強力なツールです。複雑なタスクを簡素化し、必要なコードの量を減らし、デー�タから洞察を得ることに集中できるように設計されています。
英語SDKは開発の初期段階にありますが、私たちはその可能性に大きな期待を寄せています。この革新的なツールを探求し、その利点を直接体験し、プロジェクトへの貢献を検討することをお勧めします。あなたの洞察と参加は、English SDKを改良し、Apache Sparkのアクセシビリティを拡大する上で非常に貴重なものとなるでしょう。
英語の命令をPythonコードにコンパイルするように設計されたEnglish SDK for Apache Sparkで、ジェネレーティブAIのイノベーションを体験してください。この革命的なツールは、プログラミングの学習曲線を簡素化するだけでなく、データから価値ある洞察を抽出することに集中できます。革命を観察するだけでなく、その一部になりましょう。今すぐpyspark.aiでEnglish SDKのパワーを体験してください。

