Apache Spark™ 3.5のご紹介
Databricks Runtime 14.0で利用可能になりました

Community Editionに代わり、Free Editionでは無料でより充実した機能をご利用いただけます。ぜひ今日からぜひFree Editionをお試しください。
翻訳:Junichi Maruyama. - Original Blog Link
本日、Databricks Runtime 14.0の一部として、Databricks上でApache Spark™ 3.5が利用可能になったことを発表いたします。Spark 3.5のリリースに多大な貢献をしていただいたApache Sparkコミュニティに深く感謝いたします。
Sparkをこれまで以上にアクセスしやすく、多用途で効率的なものにするという我々のミッションに沿った今回のアップデートには、以下のような新機能と改良が盛り込まれています:
- The English SDK for Apache Spark enables users to utilize plain English as their programming language, making data transformations more accessible and user-friendly.
- Spark Connectは、Scalaクライアントの一般的な利用可能性、分散トレーニングと推論のサポート、SPARK上のPandas APIの同等性、構造化ストリーミングの互換性の向上により、より多くのシナリオをサポートします。
- 配列操作用の組み込みSQL関数、SQL IDENTIFIER句、Scala、Python、R API用の拡張SQL関数サポート、SQL関数呼び出しの名前付き引数サポート、HyperLogLog近似集計のSQL関数サポート、Arrow最適化Python UDF、Pythonユーザー定義テーブル関数、PySparkテストAPI、PySparkの拡張エラークラスなど、PySparkとSQL関数の新機能で開発者の生産性を向上。
- Sparkクラスタ上のDeepSpeedによる分散トレーニングの簡素化。
- RocksDBステートストア・プロバイダのパフォーマンスと安定性が改善され、インメモリ・ステートストア・プロバイダと比較した場合のトレードオフが減少。
- English SDK for Apache Sparkにより、ユーザーはプログラミング言語として平易な英語を利用できるようになり、データ変換がより身近でユーザーフレンドリーになります。
このブログポストでは、Apache Spark 3.5のハイライトを説明し、その画期的な機能と拡張機能のスナップショットを提供します。これらのエキサイティングなアップデートの詳細については、今後のブログ記事にご注目ください。細かい詳細については、包括的な Apache Spark 3.5 release notesをご覧になることをお勧めします。このリリースノートには、すべての Spark コンポーネントにわたる主要な機能と解決済みの JIRA チケットの完全なリストが含まれています。
Spark Connect
Spark 3.4.0のリリース以降、Spark Connectの実装に関連するコミットが約680件ありました。変更を自由に閲覧する here.
Spark 3.5とSpark Connectコンポーネントの重要な成果物は、Spark Connect用のScalaクライアントの一般提供です(SPARK-42554)。この作業の一部は、クラスパス分離のためにクライアントに必要な依存関係のセットを減らすために、sqlサブモジュールをクライアント(sql-api)とサーバー互換(sql)モジュールに分割する大規模なリファクタリングでした(SPARK-44273)
Spark 3.5がリリースされるまでは、Apache SparkのMLlibをSpark Connectで直接使用することはできませんでした。Spark 3.5では、PyTorchベースの新しい分散実行フレームワーク(SPARK-42471)を使用して、Spark Connectを使用して分散学習と推論を行う機能を導入しました。現在、このモジュールはロジスティック回帰分類器、基本的な特徴変換器、基本的なモデル評価器、MLパイプライン、クロスバリデーションをサポートしています。このフレームワークは、Sparkのベクトル化されたPython UDFフレームワークとシームレスに統合され、バリア実行モードを使用してUDFを実行する機能を拡張します。
前回のリリースでは、Spark Connectを使用してPandas API on Spark のパリティを提供することに取り組み(SPARK-42497)、PythonとScalaの両方で構造化ストリーミ�ングワークロードのためのSpark Connectクライアントの互換性を改善し続けました(SPARK-49238)
最後に、コミュニティはGolangでのSpark Connectのクライアント(SPARK-43351)の開発を開始しました。こちらは別のリポジトリで開発されています: https://github.com/apache/spark-connect-go
PySpark Features
このリリースでは、Arrow に最適化された Python User Defined Functions (UDFs)、Python User Defined Table Functions (UDTFs)、改善されたエラーメッセージ、PySpark のユーザビリティ、パフォーマンス、テスト容易性を大幅に改善する新しいテスト API など、PySpark の重要な機能強化が導入されています。
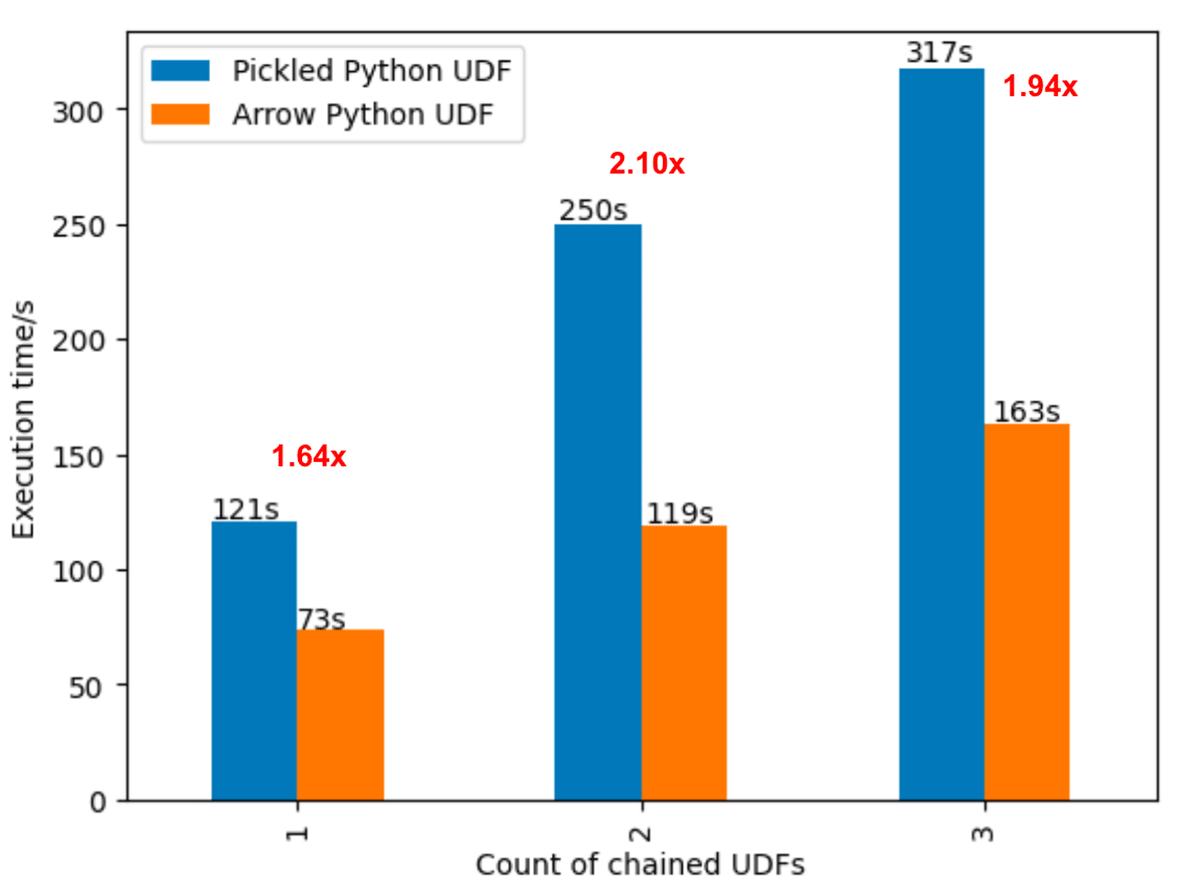
Arrow-optimized Python UDFs (SPARK-40307): 以下の例に示すように、spark.sql.execution.pythonUDF.arrow.enabled設定がTrueに設定されているか、UDFデコレータを使用してuseArrowがTrueに設定されている場合、Python UDFはArrowカラムナーフォーマットを活用してパフォーマンスを向上させます。この最適化により、Python UDFはベクトル化されたI/Oにより、最新のCPUアーキテクチャでpickled Python UDFよりも最大2倍高速に実行できます。
Pythonユーザー定義テーブル関数 (SPARK-43798): ユーザー定義テーブル関数(UDTF)はユーザー定義関数の一種で、単一のスカラー結果値の代わりに出力テーブル全体を返します。PySparkのユーザは、Pythonのロジックを統合した独自のUDTFを書き、PySparkとSQLで使用できるようになりました。
APIのテスト (SPARK-44042): Apache Spark™ 3.5では、DataFrameスキーマとDataFrame内のデータの違いを明確に示す、詳細で色分けされたテストエラーメッセージを含む、新しいDataFrame等値テストユーティリティ機能が導入されました。これにより、開発者は、アプリケーションの生産性を向上させるために、実用的な結果を生成する等式テストを簡単に追加することができます。新しいAPIは以下の通りです:
pyspark.testing.assertDataFrameEqualpyspark.testing.assertPandasOnSparkEqualpyspark.testing.assertSchemaEqual
PySparkのエラーメッセージの強化 (SPARK-42986): 以前は、Python Sparkドライバからスローされる例外のセットは、Apache Spark™ 3.3で導入されたエラークラスを活用していませんでした。DataFrameとSQLからのエラーは全て移行され、適切なエラークラスとコードを含んでいます。
SQL Features
Apache Spark™ 3.5では、SQLの新機能と改良点が多数追加され、SparkでSQL/DataFrame APIを使用したクエリの構築や、他の一般的なデータベースからSparkへの移行が容易になりました。
配列を操作するための新しい組み込み SQL 関数 (SPARK-41231): Apache Spark™ 3.5には、ユーザーが配列値を簡単に操作できるように、多くの新しい組み込みSQL関数が含まれています。このために組み込み関数を使用すると、同じ目的のためにユーザー定義関数を作成するよりも簡単で、多くの場合より効率的です。
IDENTIFIER 句 (SPARK-41231): 新しいIDENTIFIER句は、SQLインジェクション攻撃のリスクなしに、新しいSQLクエリー・テンプレートを安全に構築するための柔軟性を提供します。例えば、文字列リテラルでIDENTIFIER句を使用してテーブル/列/関数名を指定することは、以前のSparkリリースで追加されたクエリパラメータ機能と組み合わせると非常に強力です。
Scala、Python、Rの各APIにおけるSQL関数のサポートを拡充 (SPARK-43907): Spark 3.5以前は、Scala、Python、RのDataFrame APIでは利用できないSQL関数がたくさんあり�ました。そのため、ユーザーは自動補完の助けを借りずに文字列リテラルで関数名を入力する必要があり、DataFrame内で関数を呼び出すのが困難でした。Spark 3.5では、150以上のSQL関数がDataFrame APIで利用できるようになり、この問題が解消されました。
SQL関数呼び出しの名前付き引数のサポート (SPARK-44059): Pythonと同様に、SparkのSQL言語では、パラメータ名の前に値を付けて関数を呼び出すことができるようになりました。これは標準SQLの仕様と一致しており、関数に多くのパラメータがある場合や、いくつかのパラメータにデフォルト値がある場合に、より明確で堅牢なクエリ言語になります。
Apache Datasketchesに基づくHyperLogLog近似集計のための新しいSQL関数のサポート (SPARK-16484): Apache Spark™ 3.5には、グループ内の一意な値を正確かつ効率的にカウントするための新しいSQL関数が含まれており、中間計算の結果をスケッチバッファに保存し、ストレージに永続化し、後でロードし直すことができます。これらの実装は、オープンソースコミュニティとの一貫性と他のツールとの容易な統合のために、Apache Datasketchesライブラリを使用しています。例えば
DeepSpeed Distributor
今回のリリースでは、PySparkにDeepspeedTorchDistributorモジュールが追加され、Sparkクラスタ上でのDeepSpeedによる分散学習を簡素化できるようにな�りました(SPARK-44264)。これはApache Spark 3.4™でリリースされたTorchDistributorモジュールを拡張したものです。DeepspeedTorchDistributorは、Deepspeedに必要な環境と通信チャネルを初期化します。このモジュールは、シングルノードのマルチGPUクラスタとマルチノードのGPUクラスタの両方でトレーニングジョブの分散をサポートします。以下に使用方法のコード例を示します:
詳細とノートブックの例, see https://docs.databricks.com/en/machine-learning/train-model/distributed-training/deepspeed.html
ストリーミング
Apache Spark™ 3.5では、複数のステートフルな演算子のサポートの完了や、RocksDBステートストア・プロバイダーの改善など、ストリーミングに関する様々な改善が導入されている。
複数のステートフル・オペレーターのサポート完了 (SPARK-42376): Apache Spark™ 3.4では、連鎖したタイムウインドウ集約を含め、同じクエリ内でステートフルな演算(集約、重複排除、ストリームストリーム結合など)を複数回実行できるようになりました。Apache Spark™ 3.4では、ストリームストリームのタイムインターバル結合に続いて別のステートフル演算がサポートされていませんでしたが、Apache Spark™ 3.5でようやくサポートされ、より複雑なワークロード(広告やクリックのストリームの結合、時間ウィンドウの集約など)が可能になりました。
RocksDBステートストア・プロバイダの変更履歴チェックポイント機能 (SPARK-43421): Apache Spark™ 3.5では、RocksDBステート・ストア・プロバイダーに新しいチェックポイント・メカニズムが導入された。これによりコミットレイテンシが大幅に短縮され、エンドツーエンドのレイテンシも大幅に短縮される。この機能を有効にするには、spark.sql.streaming.stateStore.rocksdb.changelogCheckpointing.enabledプロパティをtrueに設定します。既存のチェックポイントでもこの機能を有効にできることに注意してください。
RocksDBステート・ストア・プロバイダーのメモリ管理の強化 (SPARK-43311): RocksDBのステート・ストア・プロバイダーは、ステートのメモリ問題に対処するのに有用であることはよく知られていますが、きめ細かなメモリ管理はなく、RocksDBでメモリ問題が発生することがありました。Apache Spark™ 3.5では、よりきめ細かいメモリ管理が導入され、同じエクゼキュータ・プロセス内のRocksDBインスタンス全体のメモリ使用量に上限を設定できるようになり、エクゼキュータ・プロセスごとのメモリ使用量を�推論・設定できるようになった。
dropDuplicatesWithinWatermarkを導入(SPARK-42931): ストリーミング・クエリで dropDuplicates() を使用して蓄積された経験を受け、Apache Spark™ 3.5 では新しい API dropDuplicatesWithinWatermark() が導入されました。この API は、イベントのタイムスタンプがウォーターマーク遅延内に収まるほど近ければ、イベント時刻のタイムスタンプが同じでなくてもイベントを重複排除します。この新機能により、ユーザーは、"イベントのタイムスタンプが異なっていても、イベントを重複とみなすことができる "ようなケースに対処することができます。例えば、ユーザがidempotent producerなしでKafkaにインジェストし、レコード内の自動タイムスタンプをイベント時刻として使用するような場合です。
English SDK
English SDK for Apache Sparkは、英語をプログラミング言語として使用することで、データエンジニアリングとアナリティクスのワークフローに革命をもたらす画期的なツールです。複雑な操作を合理化するように設計されたこのSDKは、コードの複雑さを最小限に抑え、データから価値ある洞察を引き出すことに集中できるようにします。
平易な英語でDataFrameを変換する
`df.ai.transform()`メソッドを使うと、簡単な英語のフレーズを使ってDataFrameを操作することができます。例えば
内部的には、このコマンドは以下のSQLクエリに変換され、それが実行され、結果が新しいDataFrameに格納される:
��平易な英語でデータを可視化する
`df.ai.plot()`メソッドはデータを視覚化する簡単な方法を提供します。プロットの種類と含めるデータを指定することができます。例えば
その他のリソース
より詳細な情報や例については、GitHub repositoryやblog postをご覧ください。
見出しを越えて Apache Spark™ 3.5の詳細
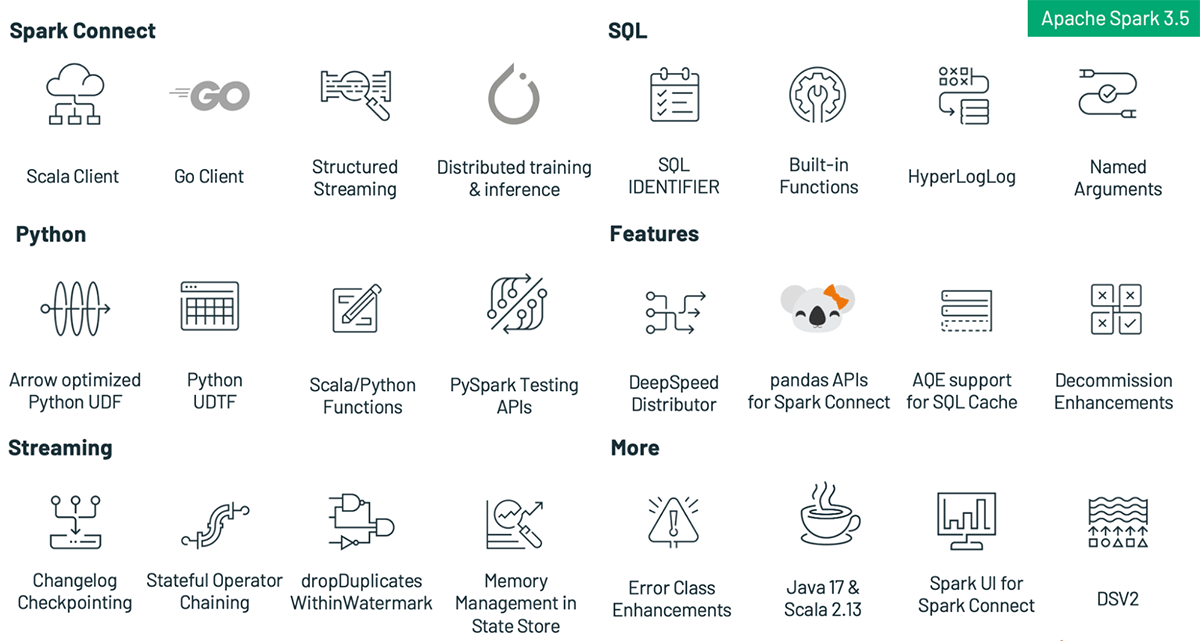
画期的な機能にスポットライトが当たりがちですが、永続的なプラットフォームの真の特徴は、使いやすさ、安定性、そして漸進的な改善に重点を置いていることです。この目的のために、Apache Spark 3.5は、198人以上の貢献者の共同作業により、驚くべき1324の問題に取り組み、解決しました。これらは単なる個人ではなく、Databricks、Apple、Nvidia、Linkedin、UBS、Baiduなどの影響力のある企業のチームです。このブログ記事では、SQL、Python、ストリーミングにおけるヘッドラインの進歩に焦点を絞ってきたが、Spark 3.5では、ここで説明されていない他にも多くの機能強化が行われている。SQLキャッシュの適応型クエリ実行、デコミッションの強化、新しいDSV2拡張など、ほんの一部を挙げればきりがない。これらの追加機能の詳細については、リリースノートをご覧いただきたい。
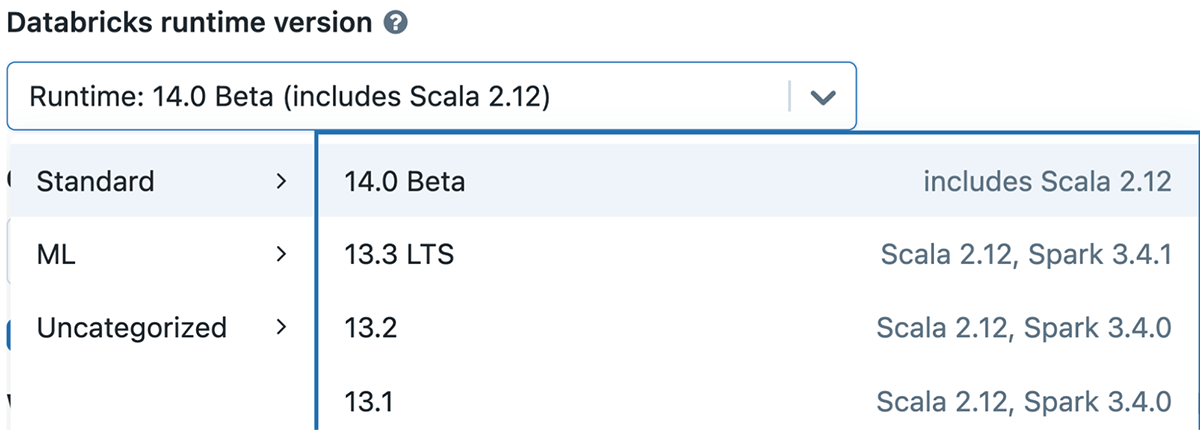
今すぐSpark 3.5を使い始める
Databricks Runtime 14.0上でApache Spark 3.5を試したい場合は、無料のDatabricks Community EditionまたはDatabricks Trialにサインアップすることで簡単に試すことができます。一旦サインアップすれば、Spark 3.5でクラスタを立ち上げるのは、バージョン "14.0 "を選択するのと同じくらい簡単です。