Databricksのワークフローを利用したLakehouseのオーケストレーション

公開日: June 13, 2023
によって Ori Zohar、リチャード・トムリンソン、ビラル・アスラム、エリカ・エーリ、Roland Fäustlin による投稿
Original: Lakehouse Orchestration with Databricks Workflows
翻訳: junichi.maruyama
業界を問わず、組織はレイクハウス・アーキテクチャを採用し、すべてのデータ、アナリティクス、AIのワークロードに統一プラットフォームを使用しています。ワークロードを本番環境に移行する際、組織はワークロードのオーケストレーションの方法が、データとAIソリューションから引き出すことのできる価値にとって重要であることに気づいています。オーケストレーションが正しく行われれば、データチームの生産性を向上させ、イノベーションを加速させることができ、より良いインサイトと観測性を提供でき、最後にパイプラインの信頼性とリソース利用を改善することができる。
Databricks Lakehouse Platformの活用を選択したお客様にとって、オーケストレーションがもたらすこれらの潜在的なメリットはすべて手の届くところにありますが、Lakehouseとうまく統合されたオーケストレーションツールを選択した場合に限られます。Databricks WorkflowsはLakehouseのための統合オーケストレーションソリューションであり、他の選択肢と比較した場合、最良の選択と言えます。
適切なオーケストレーションツールの選択
データエンジニアリングチームは、ワークロードオーケストレーションの実装方法を検討する際に、複数の選択肢から選ぶことができます。データエンジニアの中には、自社でオーケストレーターを構築したいという衝動に駆られる人もいれば、外部のオープンソースツールを好む人や、クラウドプロバイダーがデフォルトで提供しているサービスを選択する人もいます。これらの選択肢はいずれも有効ですが、Lakehouseプラットフォーム上でワークロードをオーケストレーションするとなると、いくつかの明確な欠点が思い浮かびます:
エンドユーザーの複雑化 - オーケストレーションツールの中には、ワークフローの定義が複雑で、専門的な知識とツールへの深い理解が必要なものもあります。Apache Airflowは、特にワークフローの作成と管理に不慣れなユーザーにとって、学習曲線が急であることを考慮してください。DAG(Directed Acyclic Graphs)、オ��ペレータ、タスク、および接続のプログラムによる作成は、最初は圧倒され、Airflowを効果的に使用することに熟練するためにかなりの時間と労力を必要とすることがあります。その結果、データアナリストやデータサイエンティストが独自のオーケストレーションワークフローを定義し管理することが難しくなり、オーケストレーションを専門とするデータエンジニアリングチームに依存する傾向があります。このような依存関係は、イノベーションを遅らせ、データエンジニアに大きな負担をかけることになります。さらに、外部ツールはユーザーをDatabricks環境から引き離し、不必要な「コンテキストスイッチ」と摩擦の増加によって日々の作業を遅らせることになります。
モニタリングや観測可能な機能が限られている - オーケストレーションツールを選択する際の重要な要素は、ユーザーとしてどの程度の観測性を提供できるかということです。パイプラインの監視は非常に重要であり、特に本番環境では迅速な障害の特定が重要です。ワークロードが動作するデータプラットフォームの外で動作するオーケストレーションツールは、通常、浅いレベルの観測性しか提供できないことになります。ワークフローが失敗したことは分かっても、どのタスクが失敗の原因になったのか、なぜ失敗したのかについては十分な情報が得られないことがあります。多くのオーケストレーターは基本的なモニタリングとロギング機能を提供していますが、トラブルシューティングとデバッグは、複雑なワークフローでは困難な場合があります。依存関係の追跡、データ品質の問題の特定、エラーの管理には、さらなる労力とカスタマイズが必要になることがあります。このため、トラブルシューティングが難しく、問題が発生したときにチームが迅速に復旧することができません。
信頼性の低い、非効率な生産ワークフロー - 自社で構築したオーケストレーションソリューションや、専用のクラウドインフラに導入した外部ツールの管理には、インフラ料金に加え、メンテナンス費用がかかり、障害やダウンタイムが発生しやすい。例えばAirflowは、大規模なワークフローを効率的に処理するために、独自の分散型インフラを必要とします。特に、専門的な知識を持たない企業にとっては、追加のクラスタの設定と管理は複雑でコストがかかる。これは、パイプラインの障害がデータ利用者や顧客に大きな影響を与えるような本番環境では特に深刻です。さらに、データプラットフォームとうまく統合されていないツールを使用すると、コストとパフォーマンスに直接影響する効率的なリソース割り当てとスケジューリングのための高度な機能を活用することができません。
Lakehouse オーケストレーター「Databricks Workflows」をご紹介します
Databricks Lakehouse Platform上でワークロードを最適にオーケストレーションする方法という問題にアプローチする場合、Databricks Workflowsが明確な答えとなります。Lakehouse と完全に統合された Databricks Workflows は、機械学習のトレーニング、モデルの展開、推論を通じて、ETL パイプライン、SQL 分析、BI など、あらゆるワークロードをオーケストレーションすることができる、フルマネージドオーケストレーションサービスです。上記の検討事項に関して言えば、これらはDatabricks Workflowsで十分に満足できるものです:
すべてのデータ実務担当者のためのシンプルなオーサリング - 新しいワークフローの定義は、Databricks UIで数回クリックするだけで、またはIDEを介して実現することができます。データエンジニア、データアナリスト、データサイエンティストのいずれであっても、新しいツールを学んだり、他の専門チームに依存することなく、必要なカスタムワークフローを簡単に作成・管理することができます。
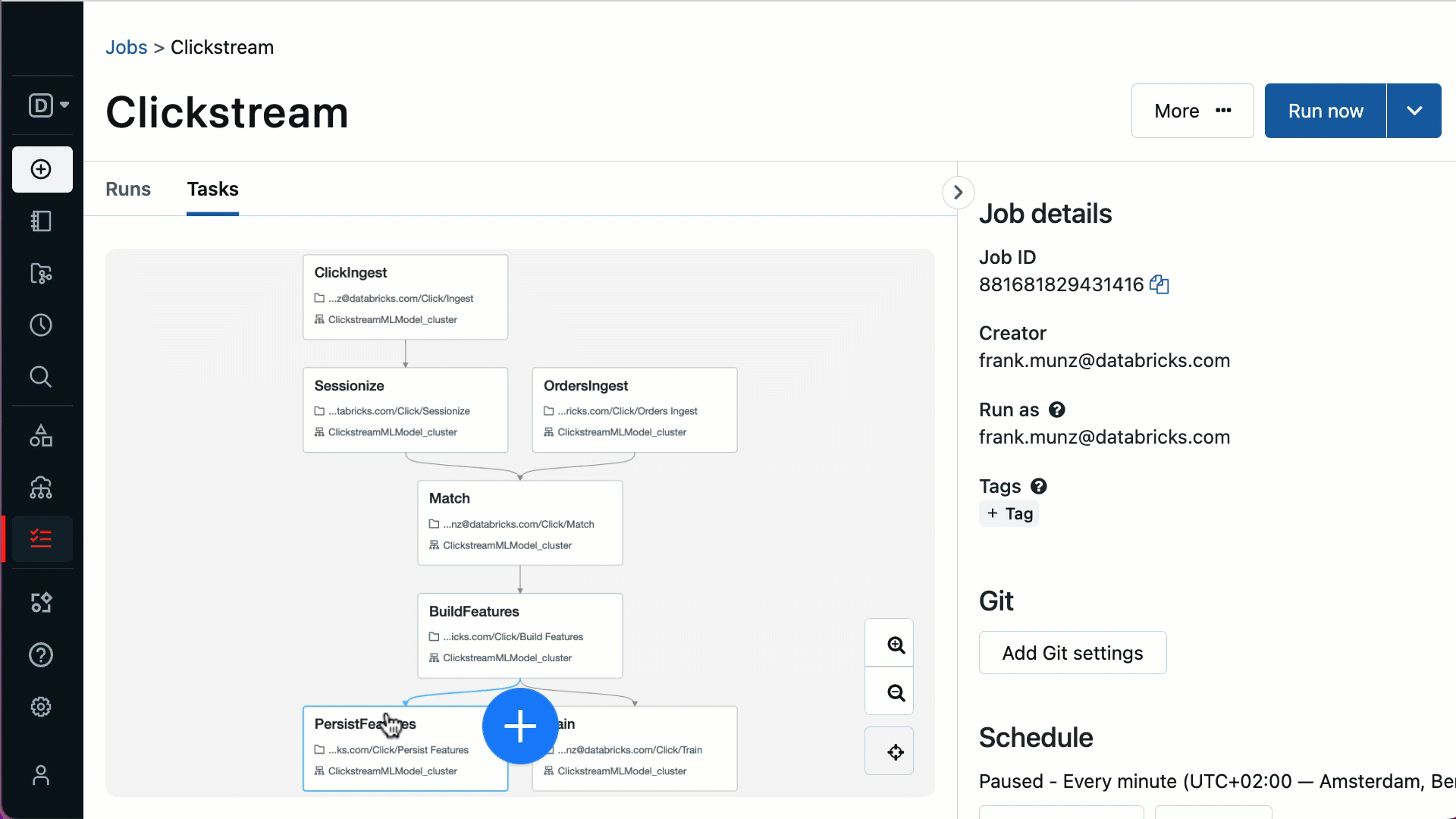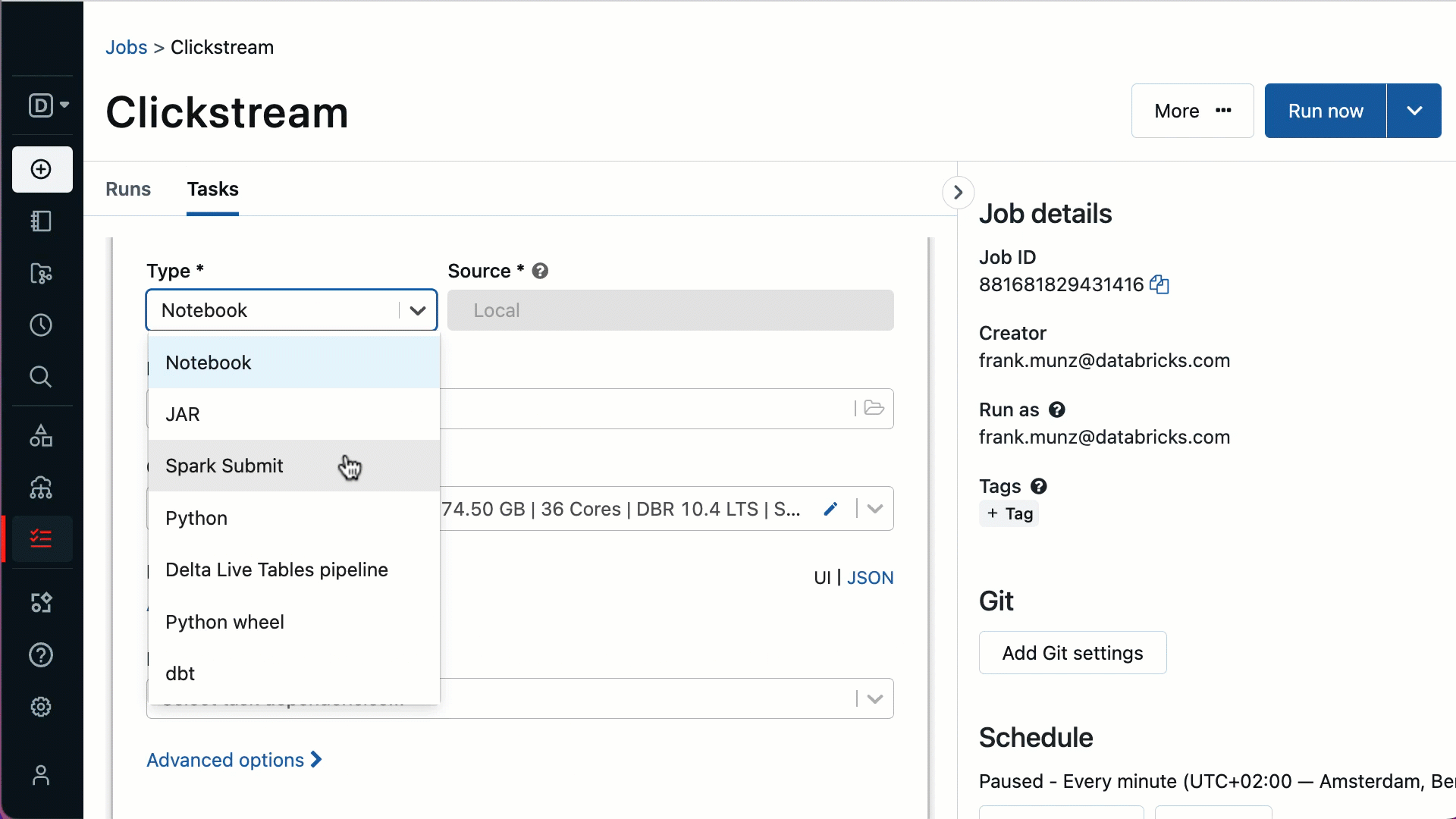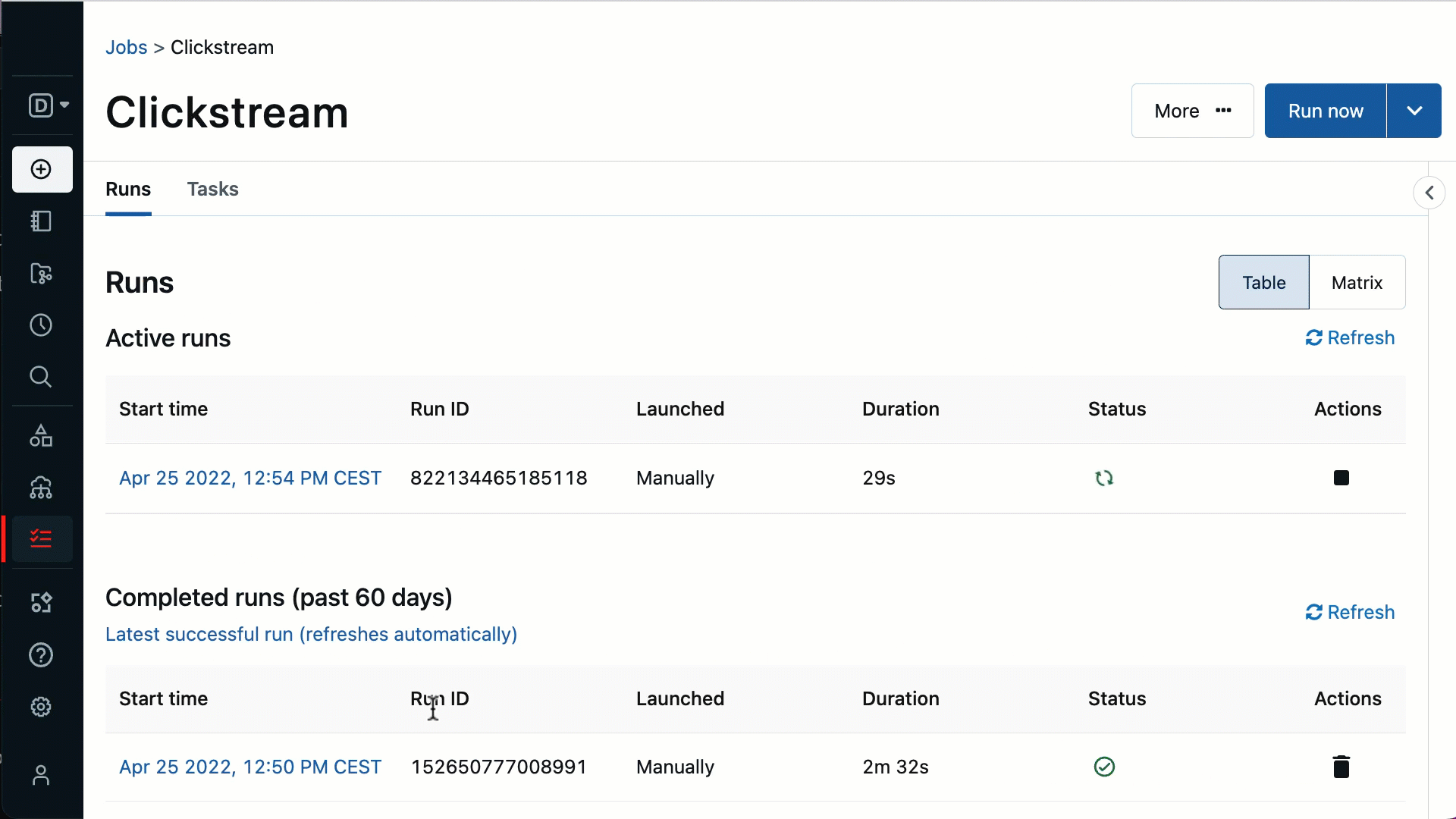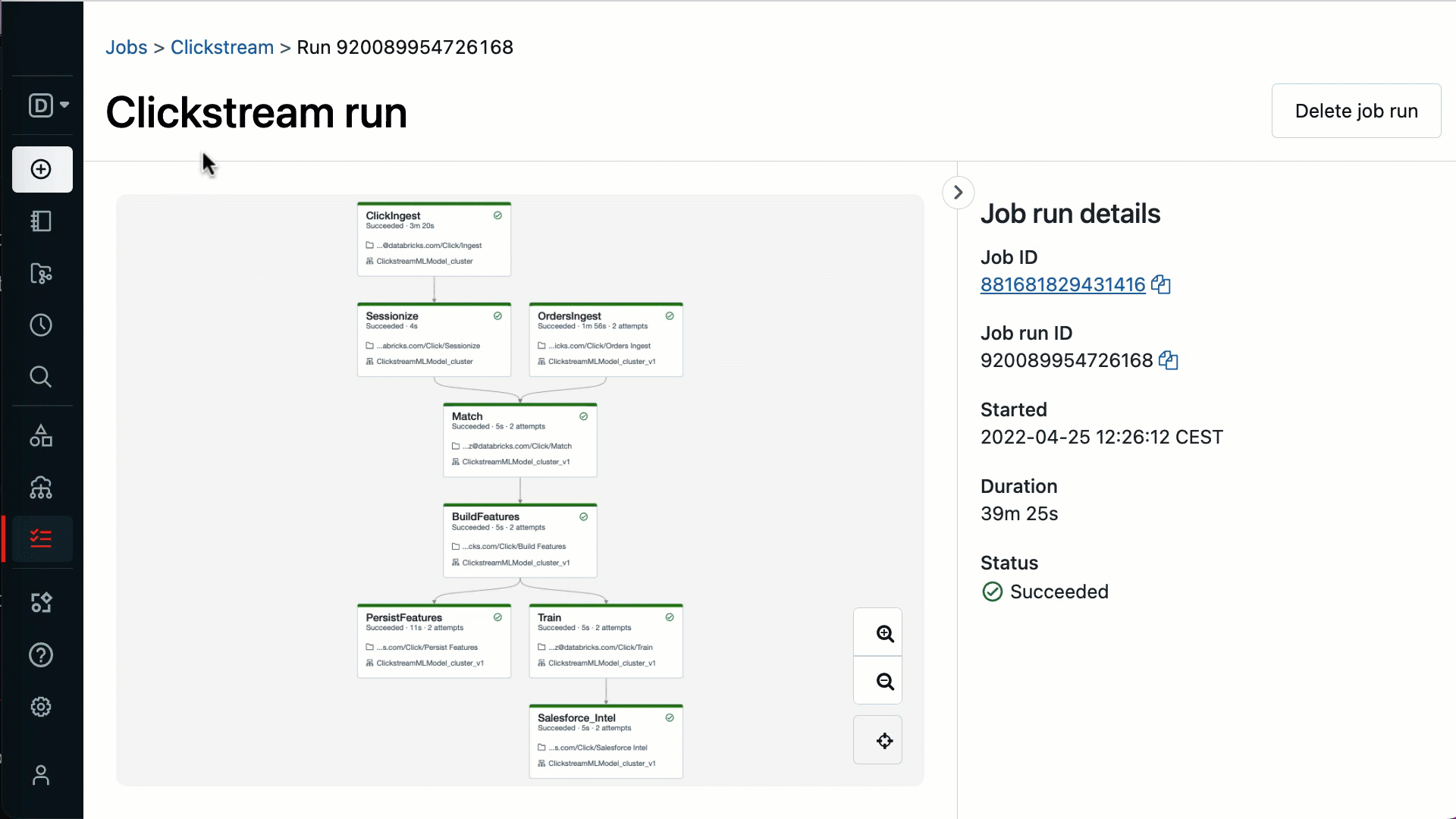
リアルタイムでモニタリングし、実用的なインサイトを提供します - レイクハウスとのネイティブな統合は、すべてのワークフローで実行されている各タスクをリアルタイムで完全に可視化することを意味します。タスクが失敗すると、アラートですぐに通知され、詳細な情報を得ることができるため、トラブルシューティングや迅速な復旧が可能になります。
生産現場で実証された信頼性 - Databricks Workflowsはフルマネージドなので、運用に必要な追加コストやメンテナンスは不要です。99.95%の稼働率を誇るDatabricks Workflowsは、毎日何百万もの本番ワークロードを実行している何千もの組織から信頼を得ています。ジョブクラス�ターへのアクセスや、タスク間でクラスターを共有する機能も、リソースの効率的な活用とコスト削減を意味します。
Databricks Workflowsの革新の1年
1年前にDatabricks Databricks Workflowsを発表して以来、Databricksユーザーがオーケストレーションされたワークフローをよりコントロールできるように、より多くのユースケースを処理し、より良い結果を得られるように、より多くの機能を実現してきました。これらのイノベーションの一部をご紹介します:
- トリガー - ワークフローをスケジュール、ファイル到着、連続実行でトリガーする機能
- 以下を含む、多くの新しいタスクタイプをサポート:
- Databricks SQLダッシュボード、クエリ、アラート
- SQLファイル
- dbtプロジェクト
- コンテキストの共有 - ワークフロー内のタスク間でコンテキストを共有することができます。
- より良いアラート機能 - 新しい通知機能により
- ユーザーインターフェースの改善
オーケストレーションの正しい使い方
Databricks Lakehouse上にデータ�およびAIソリューションを構築し、Databricks Workflowsの利点を活用する組織がますます増えています。オーケストレーションを正しく行っているDatabricksのお客様の素晴らしい例には、以下のようなものがあります:

データチームのスケールアップを支援するセルフサービスデータプラットフォームの構築
Ahold Delhaize, 世界最大級の食品・消耗品小売企業である株式会社エヌ・ティ・ティ・ドコモは、データを活用し、顧客の食事や時間の節約、生活の向上に貢献しています。同社は、オーケストレーターとしてAzure Data Factoryから移行し、Databricks Workflowsを使用して、すべてのデータチームが独自のパイプラインを簡単にオーケストレートできるセルフサービス型のデータプラットフォームを構築しました。また、より安価な自動ジョブクラスターとクラスタの再利用を活用することで、デプロイメント時間を短縮しながらコストを削減することができました。

Simplifying ETL orchestration
YipitData は、数百の投資ファンドや革新的な企業に対して、正確な粒状のインサイトを提供しています。これらの洞察を得るには、複雑なETLパイプラインで数十億のデータポイントを処理する必要があります。同社は、既存のApache Airflowオーケストレーターで、データエンジニアがDatabricksプラットフォーム以外の外部の複雑なアプリケーションを保守・運用するために必要な多大な時間的負担などの課題に直面しました。同社はDatabricks Workflowsに移行し、社内のアナリストのユーザーエクスペリエンスを簡素化することができ、新規ユーザーの導入が容易になりました。

サイロを壊し、コラボレーションを向上させる
Wood Mackenzie は、エネルギーや天然資源の分野でカスタマイズされたコンサルティングや分析サービスを提供しています。これらのサービスを支えるデータパイプラインは、毎週120億件のデータを取り込み、複数のステージで構成され、それぞれデータチームの異なるオーナーが担当しています。Databricks Workflowsを使用してETLパイプラインのオーケストレーション方法を標準化することで、データチームは、潜在的な問題のリスクを低減する自動化を導入し、コラボレーションを改善し、CI/CDを導入することで信頼性と生産性を高め、コスト削減と処理時間の80-90%短縮に成功しました。
Get started
- Webpage: Databricks Workflows - Databricks Workflowsの詳細についてはこちらをご覧ください。
- Quickstart: Create your first workflow - ステップバイステップで、わずか数分で最初のワークフローを開始することができます。
- Webinar: Building Production-Ready Data Pipelines on the Lakehouse - データパイプラインを本番に導入する際の課題と、Delta Lake、Databricks Workflows、Delta Live Tablesがどのようにこれらの課題に取り組むことができるかをご紹介します。
- Ebook: The Big Book of Data Engineering 2nd Edition - データエンジニアリングのベストプラクティス集を、実際に使える例とコードリファレンス付きで入手できます。
Join us at Data and AI Summit
2023年6月26日~29日にサンフランシスコで開催されるData and AI Summitは、データおよびAIコミュニティから最新かつ最高の情報を得ることができる絶好の機会です。特にDatabricks Workflowsについては、これらのセッションに参加することで、より良い概要を把握し、いくつかのデモを見たり、ロードマップで期待される新機能のスニークプレビュ��ーを得たりすることができます:
- Introduction to Data Engineering on the lakehouse
- Seven things you didn't know you can do with Databricks Workflows
- What's new in Databricks Workflows
Register now! To attend physically or virtually

