Apache Spark Structured Streamingでレイテンシが1秒未満になりました
Improving Offset Management in Project Lightspeed

Original: Latency goes subsecond in Apache Spark Structured Streaming
翻訳: saki.kitaoka
Apache Spark Structured Streamingは、オープンソースのストリーム処理プラットフォームの代表格です。the Databricks Lakehouse Platformのストリーミングを支える中核技術でもあり、バッチ処理とストリーム処理のための統一APIを提供しています。ストリーミングの採用が急速に進む中、多様なアプリケーションがストリーミングを活用してリアルタイムな意思決定を行いたいと考えています。これらのアプリケーションのうち、特に運用型のアプリケーションでは、より低いレイテンシーが要求されます。Sparkの設計は、高いスループットと使いやすさを低コストで実現する一方で、サブセカンドレイテンシーに最適化されていません。
本ブログでは、Structured Streamingの固有の処理レイテンシーを低減するために、オフセット管理に関する改良に焦点を当てます。これらの改良は、主に、シンプルでステートレスなリアルタイムのモニタリングやアラートなどの運用ユースケースを対象としています。
これらの改良を広範囲に評価した結果、10万イベント/秒、50万イベント/秒、100万イベント/秒のスループットにおいて、レイテンシは700-900ミリ秒から150-250ミリ秒へと68-75%(最大3倍)改善されました。Structured Streamingは、250ms以下のレイテンシーを実現し、多くの運用ワークロードのSLA要件を満たすことができるようになりました。
この記事は、読者がSpark Structured Streamingの基本的な��理解を持っていることを前提にしています。
詳細については、以下のドキュメントを参照してください:
https://www.databricks.com/spark/getting-started-with-apache-spark/streaming
https://docs.databricks.com/structured-streaming/index.html
https://www.databricks.com/glossary/what-is-structured-streaming
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
モチベーション
Apache Spark Structured Streamingは、Apache Spark SQLエンジンの上に構築された分散ストリーム処理エンジンです。開発者がバッチクエリと同じようにストリーミングクエリを書いてデータストリームを処理できるAPIを提供し、ストリーミングアプリケーションの推論やテストが容易になります。Mavenのダウンロードによると、Structured Streamingは現在最も広く使われているオープンソースの分散ストリーミングエンジンです。その人気の主な理由の1つはパフォーマンスで、高いスループットを低コストで実現し、エンドツーエンドのレイテンシを数秒未満に抑えています。構造化ストリーミングは、スループット、コスト、レイテンシーの間のトレードオフのバランスを取る柔軟性をユーザーに提供します。
企業におけるストリーミングの採用が急速に進む中、多様なアプリケーションでストリーミングデータアーキテクチャを使用�できるようにしたいという要望があります。多くのお客様との会話の中で、一貫して秒以下のレイテンシーを必要とするユースケースに遭遇しました。このような低レイテンシーのユースケースは、運用アラートやリアルタイムモニタリングなどのアプリケーション、つまり「運用ワークロード」から発生します。こうしたワークロードをStructured Streamingに対応させるため、2022年、私たちはProject Lightspeedの下、パフォーマンス改善イニシアチブを開始しました。このイニシアチブでは、処理遅延を改善するために使用できる潜在的な領域と技術を特定しました。本ブログでは、そのような改善領域の1つである進捗追跡のためのオフセット管理と、運用ワークロードのサブセカンドレイテンシーを実現する方法について詳しく説明します。
運用ワークロードとは?
ストリーミングのワークロードは、分析ワークロードと運用ワークロードに大別されることができます。図1は、分析用ワークロードと運用用ワークロードの両方を示しています。分析ワークロードは通常、リアルタイムでデータを取り込み、変換、処理、分析し、AWS S3、Azure Data Lake Gen2、Google Cloud StorageなどのオブジェクトストレージにバックアップされたDelta Lakeに結果を書き込む。これらの結果は、下流のデータウェアハウスエンジンや可視化ツールによって消費されます。
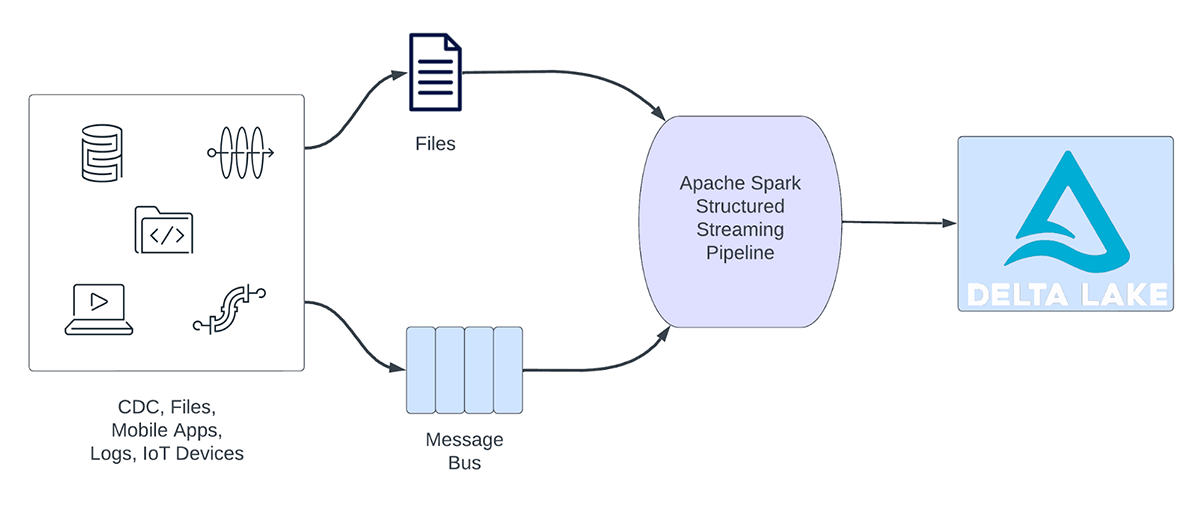
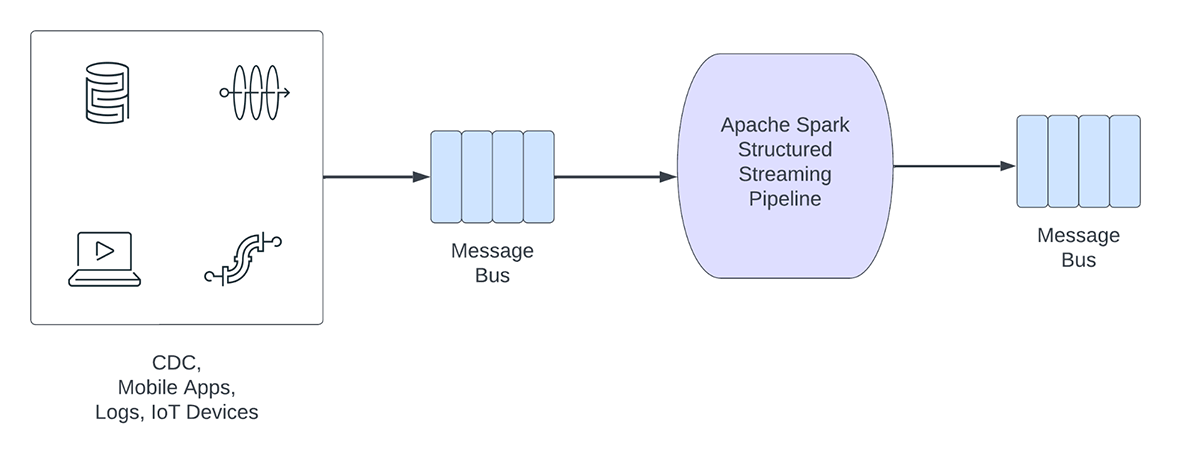
Figure 1. Analytical vs Operational Workloads
分析ワークロードの例として、以下のようなものがあります:
- 顧客行動分析: マーケティング会社では、ストリーミング解析を使用して、リアルタイムで顧客の行動を分析することができます。クリックストリームデータ、ソーシャルメディアフィード、その他の情報源を処理することで、システムはパターンや嗜好を検出し、より効果的に顧客をターゲティングするために使用することができます。
- センチメント分析: ソーシャルメディアアカウントのストリーミングデータを使用して、顧客の感情をリアルタイムで分析することができます。例えば、自社の製品やサービスに対して肯定的な感情や否定的な感情を示している顧客を探し出すことができます。
- IoTアナリティクス: スマートシティでは、ストリーミング分析を使って、交通の流れや空気の質などの指標をリアルタイムで監視することができます。街中に埋め込まれたセンサーからのデータを処理することで、トレンドを検出し、交通パターンや環境政策に関する意思決定を行うことができます。
一方、運用ワークロードは、リアルタイムでデータを取り込み処理し、自動的にビジネスプロセスを起動させます。
このようなワークロードの例としては、以下のようなものがあります:
- サイバーセキュリティ: ある企業は、ネットワークからのストリーミングデータを使用して、セキュリティやパフォーマンスの問題を監視することができます。例えば、トラフィックの急増やネットワークへの不正アクセスを確認し、セキュリティ部門に警告を送ることができます。
- 個人を特定できる情報の漏えい: マイクロサービスのログを監視し、解析して個人を特定できる情報(PII)が漏れているかどうかを検出し、漏れている場合はマイクロサービスの所有者に電子メールで通知することができる。
- エレベーターの配車: ある企業は、エレベーターのストリーミングデータを使用して、エレベーターの警報ボタンが作動したことを検出することができます。作動した場合、データを強化するためにエレベーターの追加情報を調べ、セキュリティ担当者に通知を送ることが考えられます。
- プロアクティブメンテナンス: 発電機のストリーミングデータを使用して温度を監視し、ある閾値を超えたら監督者に通知します。
運用中のストリーミング・パイプラインには、次のような特徴があります:
- 待ち時間は通常1秒以下
- パイプラインはメッセージバスから読み込む
- パイプラインは、通常、データ変換またはデータエンリッチメントを伴う単純な計算を行う
- パイプラインは、Apache KafkaやApache Pulsarなどのメッセージ・バスや、Apache CassandraやRedisなどの高速キーバリューストアに書き込み、下流のビジネス・プロセスに統合する
これらのユースケースにおいて、構造化ストリーミングのプロファイリングを行ったところ、マイクロバッチの進捗を追跡するためのオフセット管理にかなりの時間がかかることが判明しました。次章では、既存のオフセット管理について確認し、それ以降でどのように改善したかを説明します。
Databricks アプリのハンズオンガイド

オフセット管理とは?
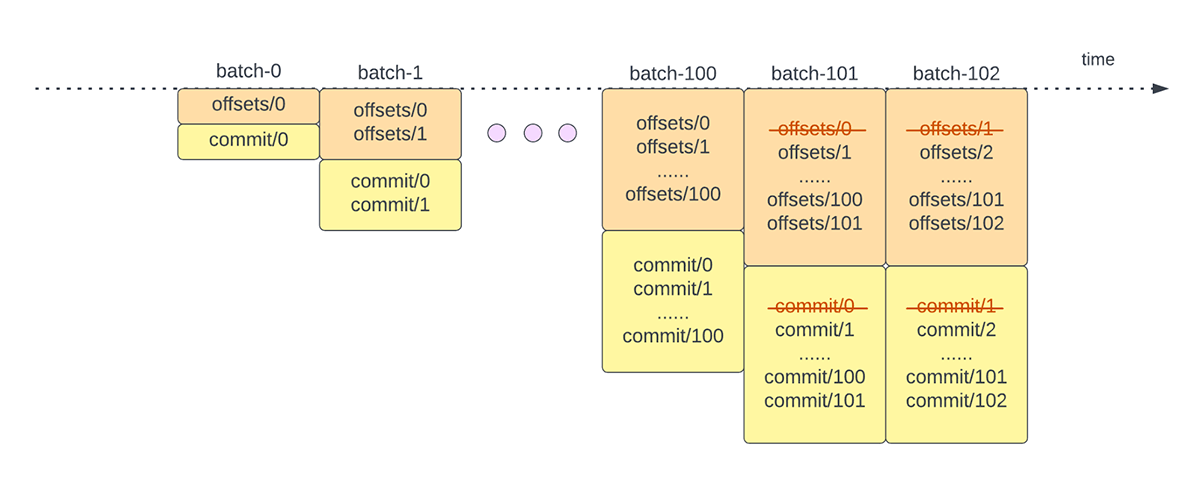
Spark Structured Streamingでは、データがどの時点まで処理されたかを追跡するために、進捗指標として使用されるオフセットの永続化と管理に依存しています。通常、オフセットはソースコネクタによって具体的に定義されます。なぜなら、システムによって�データの進捗や位置を表現する方法が異なるからです。たとえば、オフセットの具体的な実装として、ファイル内のデータがどの程度処理されたかを示すファイルの行番号を挙げることができます。このようなオフセットを保存し、マイクロバッチの完了を示すために、耐久性のあるログ(図2に示す)が使用されます。
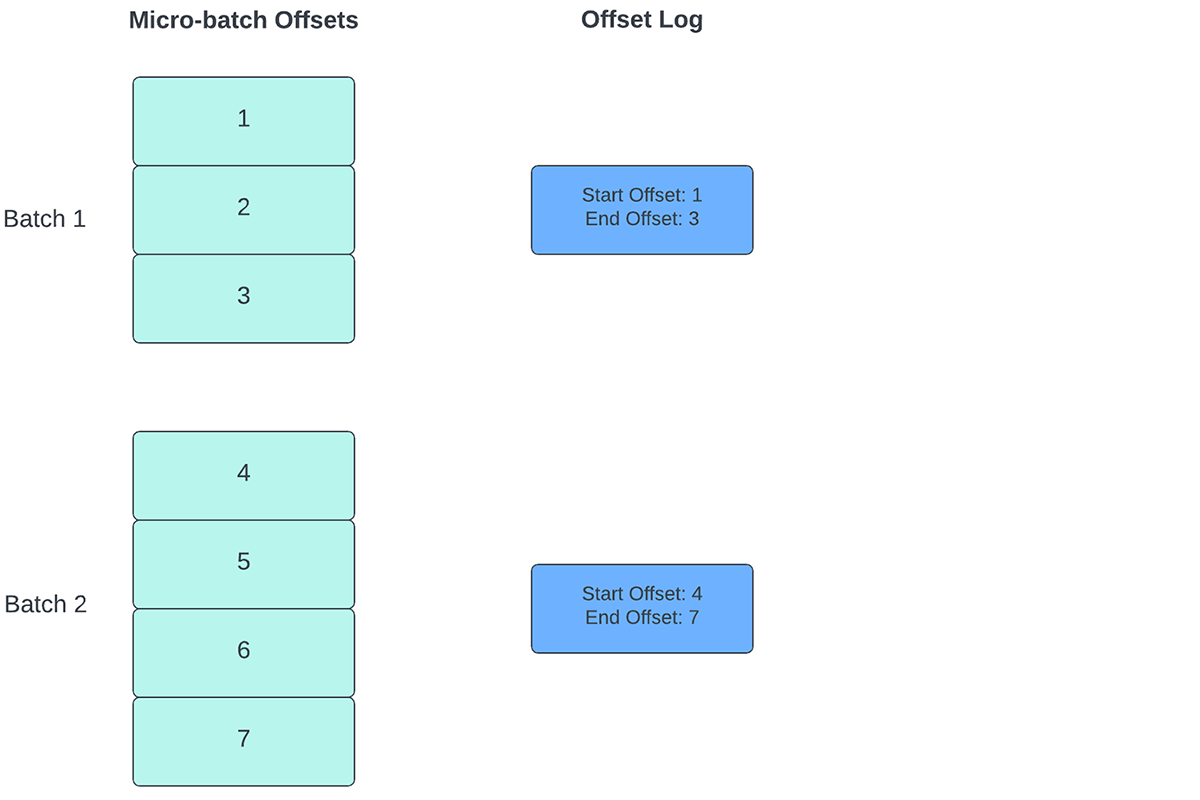
Structured Streamingでは、データはマイクロバッチという単位で処理されます。各マイクロバッチに対して、2つのオフセット管理操作が行われます。1つは各マイクロバッチの開始時、もう1つは終了時です。
- 各マイクロバッチの開始時(データ処理が実際に開始される前)に、ターゲットシステムから読み込める新しいデータに基づいてオフセットが計算されます。このオフセットは、チェックポイント・ディレクトリの「offsetLog」と呼ばれる耐久性のあるログに永続化されます。このオフセットは、「この」マイクロバッチで処理されるデータの範囲を計算するために使用されます。
- 各マイクロバッチが終了すると、「この」マイクロバッチが正常に処理されたことを示すために、「commitLog」と呼ばれる耐久性のあるログにエント�リが永続的に保存されます。
以下の図3は、現在行われているオフセット管理のオペレーションを示したものです。
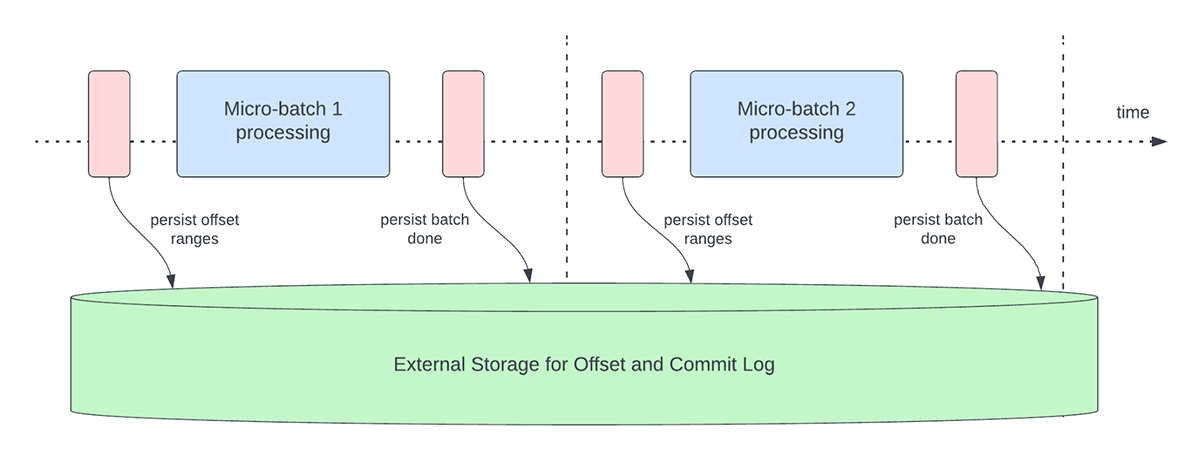
もう 1 つのオフセット管理操作は、各マイクロバッチの終了時に実行されます。この操作は、offsetLogとcommitLogの両方から古いエントリや不要なエントリを削除/切り捨てるクリーンアップ操作で、これらのログが無制限に増大することがないようにします。
これらのオフセット管理操作は、クリティカルパス上で、実際のデータ処理とインラインで実行されます。つまり、これらの操作の時間は処理のレイテンシーに直接影響し、こ��れらの操作が完了するまでデータ処理を行うことができません。これは、クラスタの使用率にも直接影響します。
ベンチマークとパフォーマンス・プロファイリングを通じて、オフセット管理オペレーションが処理時間の大部分を占めることを確認しました。特に、運用アラートやリアルタイム監視のユースケースでよく使用されるステートレス・シングルステート・パイプラインの場合です。
構造化ストリーミングの性能向上
非同期プログレス・トラッキング(Asynchronous Progress Tracking)
この機能は、進捗追跡を目的としたオフセットの永続化によるレイテンシのオーバーヘッドを解決するために作成されました。この機能を有効にすると、Structured Streamingパイプラインは、マイクロバッチ内の実際のデータ処理と非同期かつ並行して、オフセットログとコミットログの更新という進捗状況をチェックすることができます。つまり、オフセット管理操作によって実際のデータ処理がブロックされることがないため、アプリケーションのレイテンシーが大幅に改善されます。以下の図5は、オフセット管理に関するこの新しい動作を示しています。
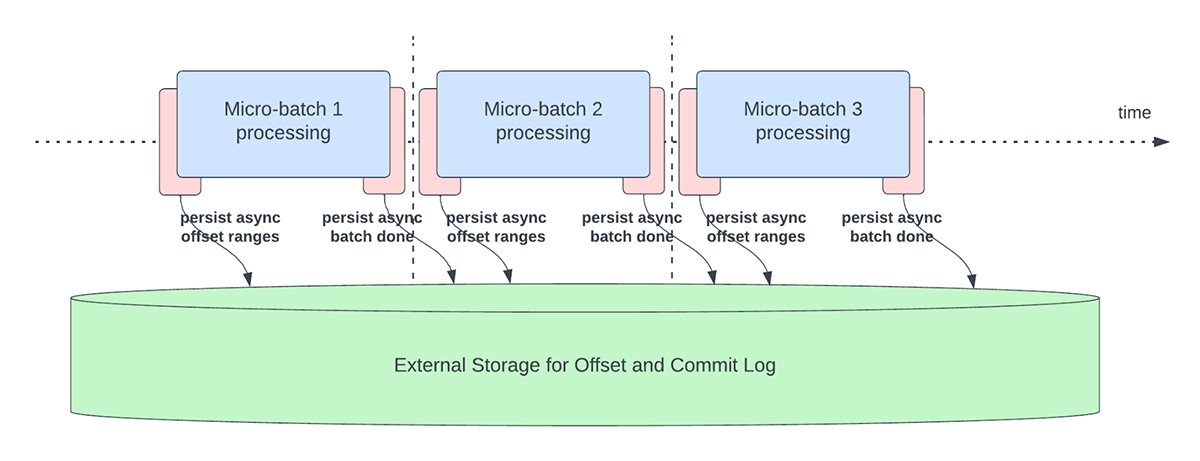
非同期でアップデートを実行することに関連して、ユーザーは進捗状況をチェックポイントする頻度を設定することができます。
これは、オフセット管理操作が処理可能な速度よりも高い速度で発生するシナリオに役立ちます。これは、オフセット管理業務に比べ、実際にデータを処理する時間が著しく少ないパイプラインで起こります。このようなシナリオでは、オフセット管理業務のバックログが増加し続けることになります。このようなバックログの増加を食い止めるには、データ処理をブロックしたり、速度を落としたりする必要があり、これにより、オフセット管理操作がデータ処理と同時に実行された場合と同じような処理動作になります。適切なデフォルト値が設定されるため、ユーザーは通常、チェックポイントの頻度を構成または設定する必要はない。チェックポイントの間隔が長くなると、障害復旧時間が長くなることに注意することが重要です。失敗した場合、パイプラインは、前回のチェックポイントが成功した時点までのすべてのデータを再処理しなければなりません。ユーザーは、通常処理時の低レイテンシーと障害発生時の復旧時間のトレードオフを考慮することができます。
この機能を有効にし、設定するために、以下の設定が導入されています:
- asyncProgressTrackingEnabled - 非同期プログレス・トラッキングを有効または無効にする。
- デフォルト:false
- asyncProgressCheckpointingInterval - オフセットと完了コミットを行う間隔。
- デフォルト:1分
以下のコードは、この機能を有効にする方法を説明するものです:
Note:Trigger.onceやTrigger.availableNowは、パイプラインを手動/スケジュールで実行するため、この機能は使えませんのでご注意ください。そのため、非同期の進捗管理は意味を持ちません。前述のトリガーを使用してクエリーを送信した場合、クエリーは失敗します。
適用範囲と制限事項
現在のバージョンにはいくつかの制限があり、この機能を進化とともに変更される可能性があります:
現在、非同期進捗管理はKafka Sinkを使用したステートレスパイプラインでのみサポートされています。
バッチ用のオフセット範囲は障害発生時に変更できるため、この非同期プログレス・トラッキングでは、正確に一度だけエンド・ツー・エンドの処理はサポートされないでしょう。しかし、Kafkaシンクのような多くのシンクでは、at-least once保証しかサポートしていないので、これは新しい制限ではないかもしれません。
非同期ログパージ
この機能は、マイクロバッチ内で並んで行われていたログのクリーンアップのレイテンシーオーバーヘッドを解決するために作られました。このログのクリーンアップ/パージ操作を非同期かつバックグラウンドで行うことで、この操作が実際のデータ処理に与えるレイテンシーのオーバーヘッドを取り除くことができます。また、これらのパージはマイクロバッチごとに行う必要はなく、より緩やかなスケジュールで実行することができます。
この機能には、どのようなパイプラインやワークロードで使用できるかという制限はありません。したがって、この機能は、すべての構造化ストリー�ミング・パイプラインでデフォルトでバックグラウンドで有効になっています。
ベンチマーク
非同期進捗追跡と非同期ログパージのパフォーマンスを理解するために、いくつかのベンチマークを作成しました。このベンチマークの目的は、エンドツーエンドのストリーミング・パイプラインにおいて、オフセット管理の改善による性能の違いを理解することです。ベンチマークは、2つのカテゴリーに分かれています:
- レートソースから統計シンクへ - このベンチマークでは、基本的なステートレスで統計情報を収集するソースとシンクを使用しました。これは、外部依存のないコアエンジンのパフォーマンスの違いを判断するのに便利です。
- KafkaソースからKafkaシンクへ - このベンチマークでは、KafkaソースからKafkaシンクへデータを移動しました。これは実運用シナリオに近いもので、実運用シナリオでどのような違いが出るかを確認します。
これらのベンチマークでは、異なるデータ入力レート(100Kイベント/秒、500Kイベント/秒、1Mイベント/秒)でエンドツーエンドのレイテンシー(50パーセンタイル、99パーセンタイル)を測定しました。
ベンチマークの方法論
主な方法論は、特定の一定のスループットでソースからデータを生成することでした。生成されたレコードには、そのレコードがいつ作成されたかという情報が含まれています。シンク側では、Apache DataSketchesライブラリを使用して、シンクがレコードを処理する時刻と、各バッチでレコードが作成された時刻の差を収集します。これを用いてレイテンシーを算出します。すべての実験に、同じノード数の同じクラスタを使用しました。
注:Kafkaベンチマークでは、Kafkaの実行とKafkaに供給するデータの生成のために、クラスタのいくつかのノードを確保しました。レコードのレイテンシは、レコードがKafkaに正常にパブリッシュされた後(シンク上)にのみ計算されます。
レートソースからスタットシンクへのベンチマーク
このベンチマークでは、Databricksランタイム(11.3)を使用する7つのワーカーノード(i3.2xlarge - 4コア、61GiBメモリ)のSparkクラスタを使用しました。各改善点の寄与を定量化するため、以下のシナリオについてエンド・ツー・エンドのレイテンシーを測定しました。
- 現在の構造化ストリーミング - 前述の改善策を適用しない場合のベースラインのレイテンシーです。
- 非同期ログパージ - 非同期ログパージのみを適用した場合のレイテンシーを測定します。
- Async Progress - 非同期のプログレス・トラッキングを適用した場合のレイテンシーを測定します。
- Async Progress + Async Log Purge - 両方の改良を適用した後のレイテンシーを測定します。
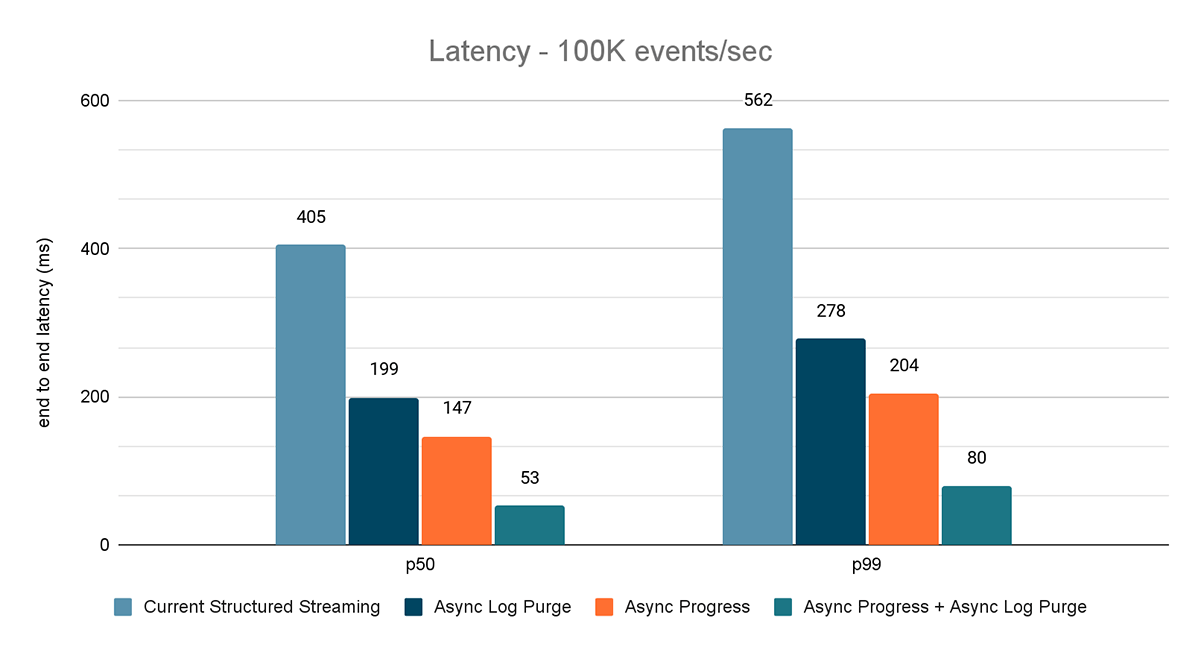
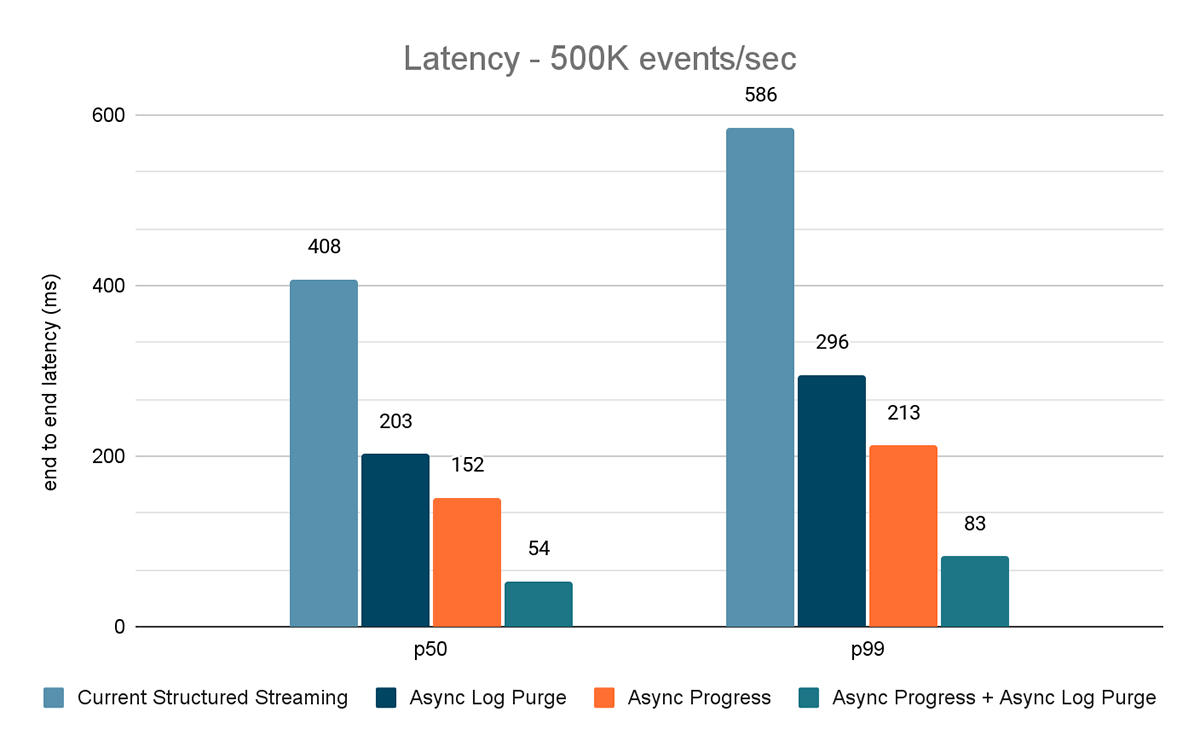
これらの実験の結果を図6、図7、図8に示します。ご覧のように、非同期ログパージは一貫してレイテンシーを約50%削減します。同様に、非同期プログレス・トラッキングだけでもレイテンシは約65%改善されます。一緒に組み合わせることで、レイテンシは85~86%減少し、レイテンシは100msを下回るようになります。
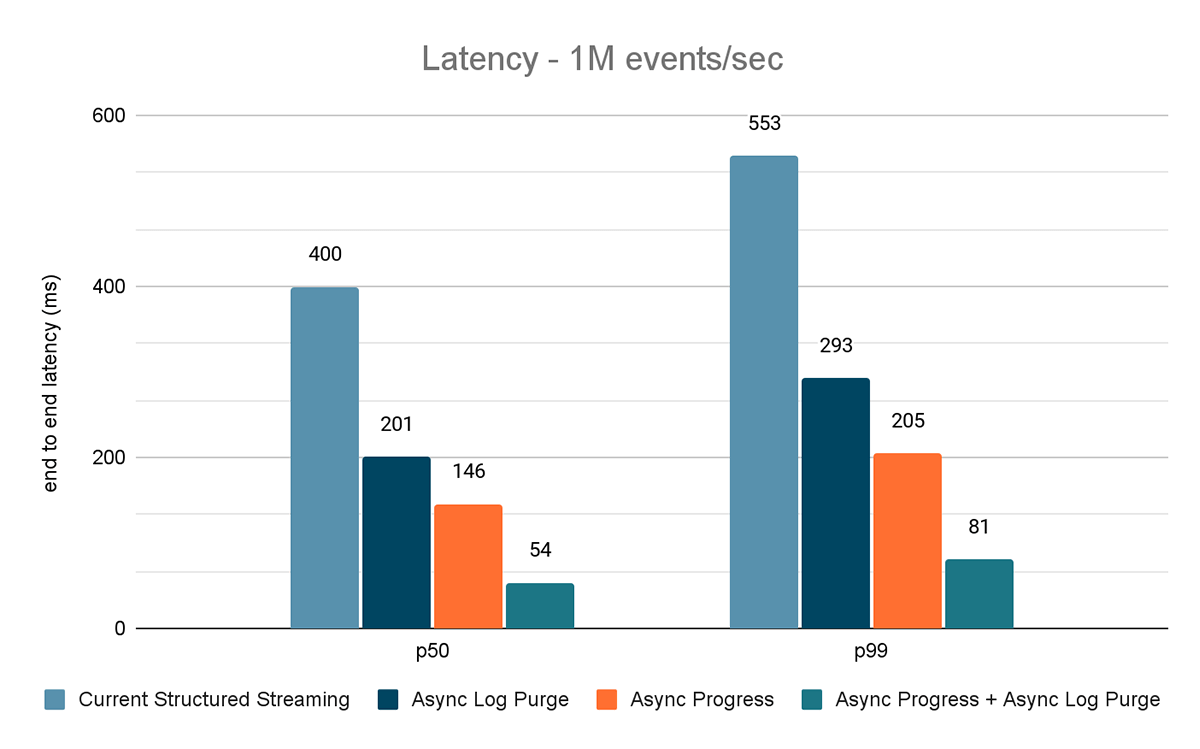
KafkaソースからKafkaシンクへのベンチマーク
Kafkaベンチマークでは、5つのワーカーノード(i3.2xlarge - 4コア、61GiBメモリ)からなるSparkクラスタ、Kafkaを実行する3ノードの別クラスタ、Kafkaソースに追加するデータを生成する追加2ノードを使用しました。私たちのKafkaトピックには40のパーティションがあり、レプリケーションファクターは3です。
データジェネレーターはデータをKafkaトピックにパブリッシュし、構造化ストリーミングパイプラインはデータを消費して別のKafkaトピックに再パブリッシュします。性能評価の結果を図9、図10、図11に示します。ご覧のように、非同期プログレスと非同期ログパージを適用すると、さまざまなスループットでレイテンシが65~75%、3~3.5倍減少しています。
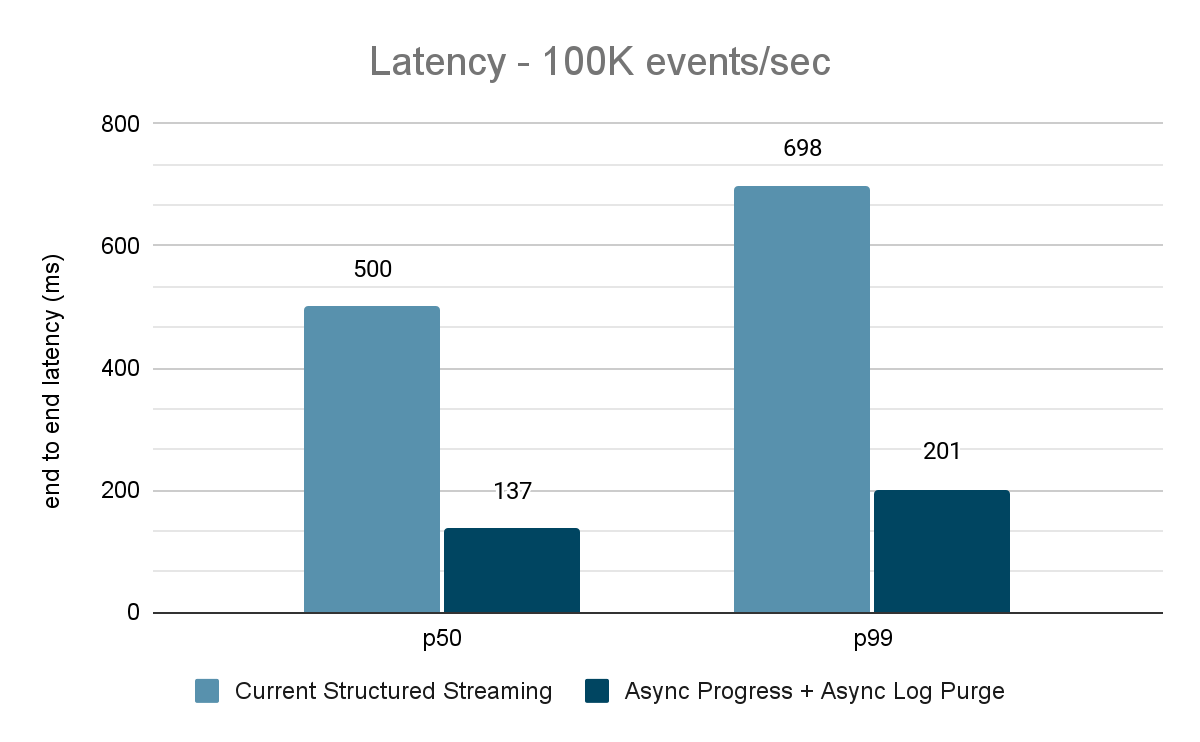
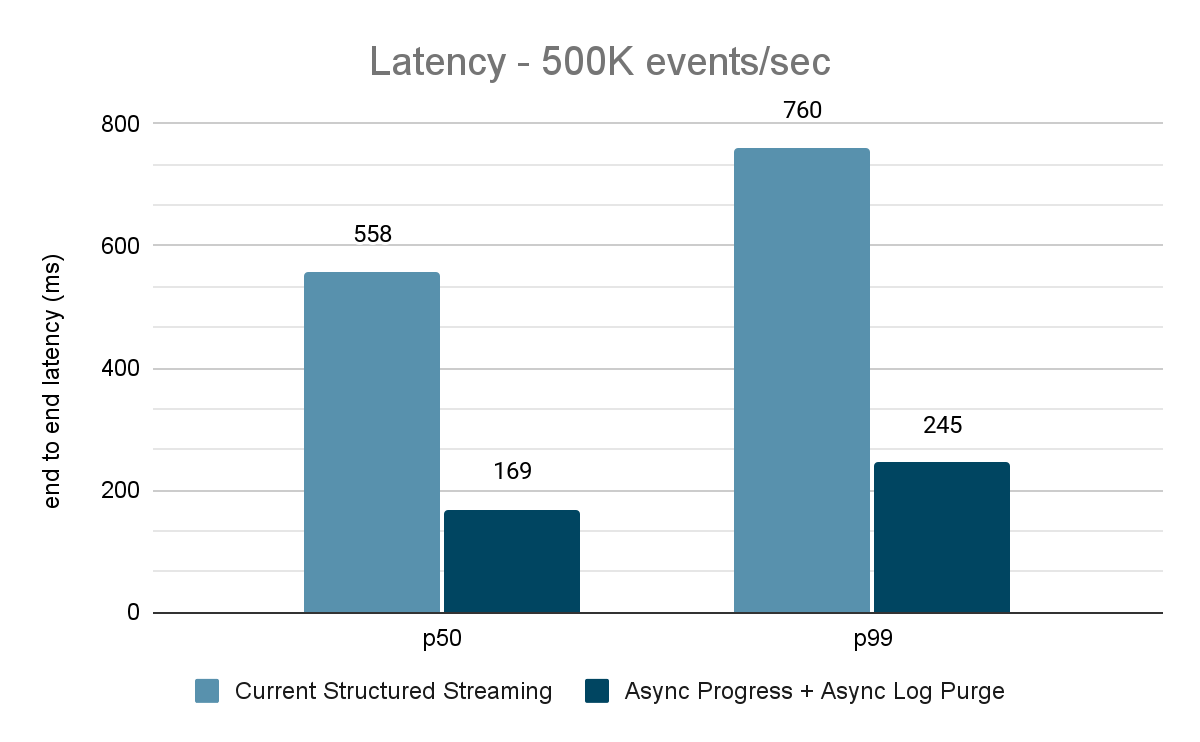
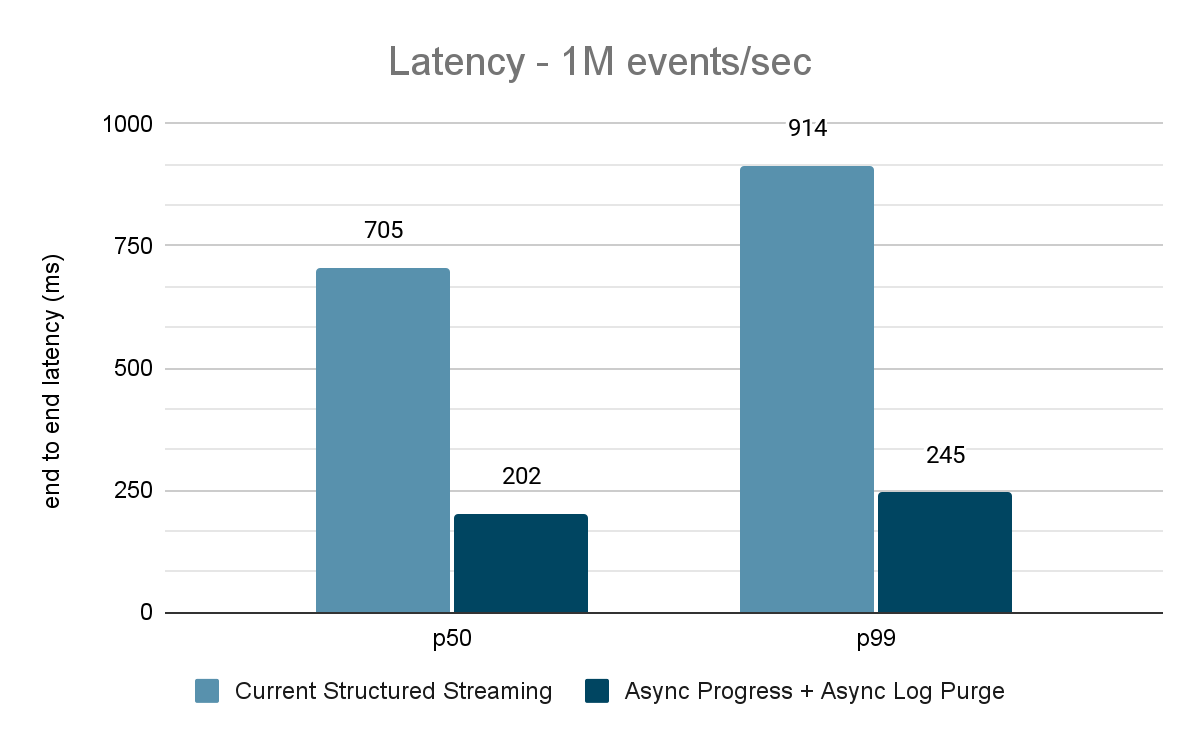
パフォーマンス結果のまとめ
新しい非同期プログレス・トラッキングと非同期ログ・パージにより、両方の構成でレイテンシーが3倍も削減されていることがわかります。一緒に使うことで、すべてのスループットでレイテンシが大幅に削減されます。また、節約された時間は通常一定の時間(各構成で200~250ミリ秒)であり、両構成を合わせて約500ミリ秒を削減できることがチャートからわかります(バッチ計画やクエリー処理に十分な時間を確保できます)。
利用可能なランタイム
これらのパフォーマンス改善は、Databricks Lakehouse PlatformのDBR 11.3以降で利用可能です。非同期ログパージは、DBR 11.3以降のリリースでデフォルトで有効になっています。さらに、これらの改良はオープンソースSparkに提供され、Apache Spark 3.4以降で利用可能です。
今後の展望
現在、非同期進捗追跡機能でサポートされるワークロードとシンクのタイプには、いくつかの制限があります。今後、この機能でより多くの種類のワークロードをサポートすることを検討する予定です。
これは、Project Lightspeedの一環としてStructured Streamingで構築している予測可能な低レイテンシー機能のほんの始まりに過ぎません。さらに、Structured Streamingのベンチマークとプロファイリングを継続し、より多くの改善点を見出す予定です。ご期待ください!
6月26日~29日にサンフランシスコで開催されるData and AI Summitに参加し、 Project LightspeedとDatabricks Lakehouse Platform上のデータストリーミングについてさらに詳しく学びましょう。