データレイクで増分 ETL のメリットを活かす - CDC の課題など
によって John O'Dwyer による投稿
従来のデータウェアハウスでの増分 ETL といえば、CDC(change data capture、変更データキャプチャ)を利用する方法が一般的になっています。しかし、スケーラビリティ、コスト、状態の把握や機械学習との連携が困難であることなどの問題があり、この CDC により増分 ETL を実行する方法は、必ずしも理想的とはいえません。一方、データレイクでの増分 ETL は、これまで、ビッグデータのテーブルのデータ更新や変更データの特定ができないといった理由により不可能とされてきました。しかし今日、データレイクで増分 ETL を利用することが可能になりました!増分 ETL には多くのメリットがあります。効率性やシンプルさ、データサイエンティストやデータアナリストのどちらも利用できる柔軟なデータアーキテクチャの構築などが挙げられます。このブログでは、データレイクで増分 ETL を使用するメリットと、それをサポートするデータアーキテクチャについて解説します。
増分 ETL とは?
まず、増分 ETL とは何かを明らかにしましょう。増分 ETL とは、ソースとデスティネーションとの間の、新規データ/変更データのみの移動を意味します。Web トラフィックのイベントや IoT センサーの測定値(アペンドデータの場合)、エンタープライズデータベースの変更(CDC の場合)など、ビッグデータの種類を問いません。増分 ETL をジョブとしてスケジュールすることも可能です。また、新規データへの継続的アクセスを低レイテンシで行う必要のあるビジネスインテリジェンス(BI)のユースケースにも対応します。下の図は、増分 ETL データが、異なる目的を持つ複数のテーブル間でどのように移動し、変換されるかを示しています。
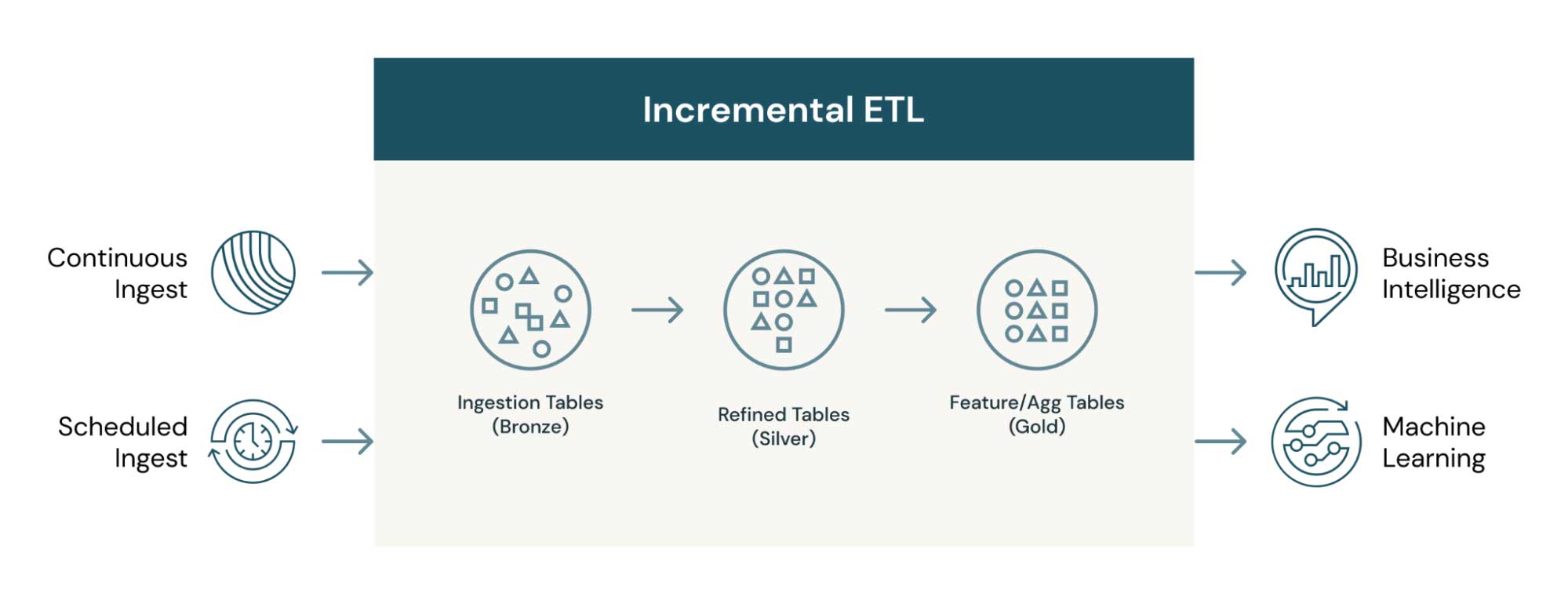
データレイクを活用した増分 ETL のメリット
増分 ETL を活用すべきメリットは多数あります。Delta Lake や Apache Spark™ などのオープンソースのビッグデータテクノロジーでは、ベンダーロックインすることなく、大規模かつ高いコスト効率で増分データ処理をシームレスに実行できます。このアプローチの採用により、次のようなメリットが得られます。
- 低コストなビッグデータストレージ:データウェアハウスではなく、データレイクでもビッグデータストレージを利用することで、ストレージとコンピューティングを分け、コスト増なしで全ての過去データをストレージに保存できます。これにより、設計時には予測できなかった変換の実行にも柔軟に対応できるようになります。
- 効率性:増分 ETL は、新規または変更があったデータなど、処理が必要な増分データのみに実行できるため、効率的な ETL やコストの削減、処理時間の短縮が可能になります。
- 複数のデータセットおよびユースケース:取り込まれたデータセットは、利用される目的も、エンドユーザーのペルソナも異なります。例えば、高精度な集計データセット(ゴールドテーブル)は、データアナリストがレポート作成に使用し、高精度なイベントレベルデータは、データサイエンティストが機械学習モデルの構築��に利用します。メダリオン(ゴールド・シルバー・ブロンズ)テーブルアーキテクチャにより、目的に応じた多くの価値をデータから引き出すことができます。
- 常時利用可能な原子性のデータ:増分的な処理ではデータの誤消去や再処理は発生しないため、いつでもデータを利用できます。そのため、さまざまなペルソナが任意の時点で、中間状態や最終状態のテーブルを利用できるようになります。データの原子性とは、行レベルでその行の処理が完全に成功するか失敗するかを意味します。すなわち、この原子性がデータの読み取りを可能にします。これまでのビッグデータテクノロジーでは、行レベルでの原子性は実現できませんでしたが、増分 ETL により可能になりました。
- 状態の追跡:状態とは、ETL 処理がどの段階にあるかを把握することです。ETL における状態の追跡は極めて困難です。しかし、増分 ETL には、デフォルトで状態を追跡する機能があり、ETL のコーディングを容易にします。これにより、ジョブのスケジュール実行やエラーの発生の際に、いずれも中断したところから再開できます。
- レイテンシ:増分 ETL では、ジョブの周期を日単位から時間単位または連続実行に、容易に変更できます。レイテンシとは、データが処理可能になってから処理されるまでの時間差のことで、ジョブの周期を短くすることで短縮できます。
- 過去のデータセット/再現性:データの順序や取り込み方が整理されているため、エラーが発生した場合や ETL の再現が必要な場合にも対応できます。
増分 ETL が普及していない 5 つの理由
増分 ETL は、優れているのにあまり実装されていないのが実情です。このアーキテクチャの一部や、高コストなデータウェアハウスでの運用については知られています。ここではまず、このようなアーキテクチャの実現がなぜ今まで困難であった理由を探り、次に、増分 ETL を可能にするビッグデータテクノロジーについて説明します。
- コスト:変更データキャプチャ/イベント駆動型の ETL は、データウェアハウスの世界では新しいものではありません。しかし、全ての過去データをデータウェアハウスに保持し、アーキテクチャにおけるデータ移行で複数のテーブルを利用可能にするには、膨大なコストがかかります。増分 ETL の継続実行(データウェアハウスでの ELT)にかかるコストやリソースも考慮しなければなりません。データウェアハウスアーキテクチャでは、抽出、ロード、そして変換という ELT が広く使用されています。
- データの更新:最近までデータレイクにおけるデータ更新は極めて困難でした。特にデータが大規模な場合や、データを同時に読み込む場合には、実行不可能なこともありました。
- 状態:前回の ETL ジョブがどこで中断してどこで再開すべきかを常に知ることは、状態を把握していない限りは困難です。しかし今は、中断したところからの再開を容易にするテクノロジーが存在します。この問題は、例外が発生しプロセスが予期せず停止した場合に、さらに深��刻になる可能性があります。
- 非効率:処理が変更だけではなく他にもある場合、かなりの時間とリソースが必要になります。
- 増分データソースとしてのビッグデータテーブル:Delta Lake などの特定のビッグデータテーブルの原子性により、増分データソースが利用できるようになりました。これにより、中間テーブルのアーキテクチャが可能になります。
増分 ETL を可能にするビッグデータテクノロジー
Apache Spark™ と Delta Lake における多くのイノベーションが、増分 ETL を基盤としたデータアーキテクチャの実現と容易な構築を可能にしています。以下は、そのビッグデータテクノロジーの詳細です。
- Delta Lake の ACID トランザクション:Delta Lake は ACID(原子性、一貫性、独立性、永続性)トランザクションを提供します。これはビッグデータアーキテクチャには斬新な機能であり、データレイクハウスにおいて不可欠です。ACID トランザクションは、ソース/Delta Lake の中間テーブルにおける行レベルでの更新および変更の特定を可能にします。また、MERGE オペレーションにより、アップサート処理(行レベルでの挿入や更新を一度に行うこと)が極めてシンプルになります。
- チェックポイント: Spark 構造化ストリーミングのチェックポイント機能により、ETL ジョブが中断した際の本質的な状態をアーキテクチャで把握できるため、状態管理が容易になります。
- トリガーワンス:トリガーワンス(Trigger.Once )は Spark 構造化ストリーミングの機能です。Apache Kafka からの読み込みなどの継続的なユースケースをスケジュールジョブに変換します。これは、継続的かつ低レイテンシな ETL が範囲外である場合でも、多くの機能を採用できることを意味します。また、スケジュールジョブの周期の変更が可能な柔軟性も備えており、最終的にはアーキテクチャを変更することなく、継続的なユースケースを実現します。
ビッグデータとオープンソーステクノロジーを利用した増分 ETL が可能になった今、組織では、必要なキュレーションデータセットを効率的かつ容易に構築できる増分 ETL の利用価値を評価する必要があります。
増分 ETL を可能にするオープンソーステクノロジーについて詳しくは、delta.io または spark.apache.org をご覧ください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。