
要約:
大規模言語モデル(LLM)は、ソフトウェア開発における生産性を飛躍的に高め、プログラマーの働き方を革新しました。しかし、市販のLLMは大量のコードで学習されているにもかかわらず、完璧ではありません。特にエンタープライズのお客様にとっての大きな課題は、「自社のデータを活用して適応・推論できること」、すなわちデータインテリジェンスの実現です。これには、自社固有のコーディング概念や知識、好みに対応できることが求められます。
同時に、低レイテンシーかつ低コストであることも重要です。
本ブログでは、小規模なオープンソースのLLMを対話データでファインチューニングすることで、最新レベルの高精度・低コスト・最小限のレイテンシーを実現できることを紹介します。
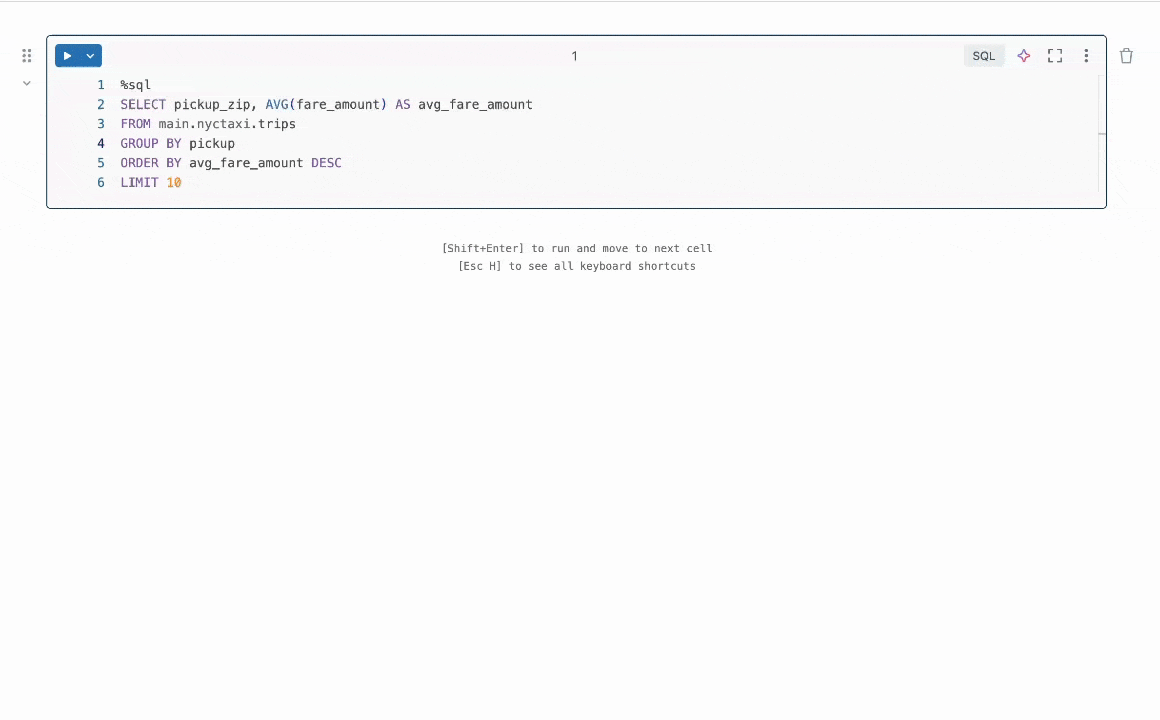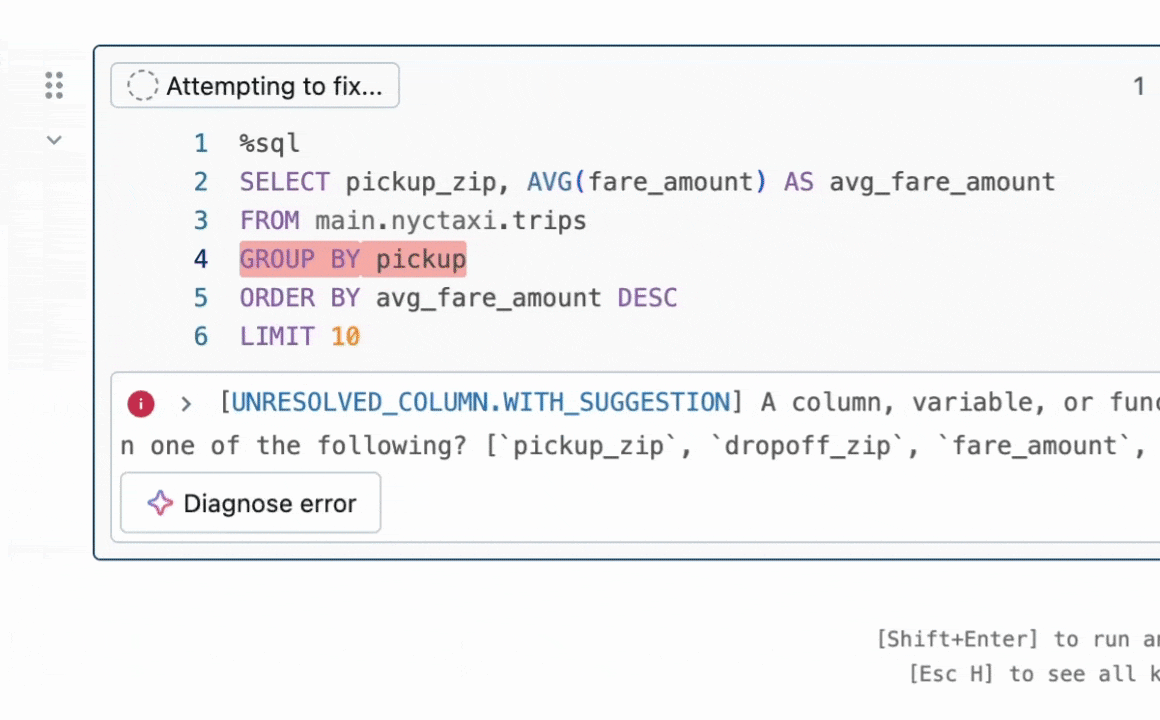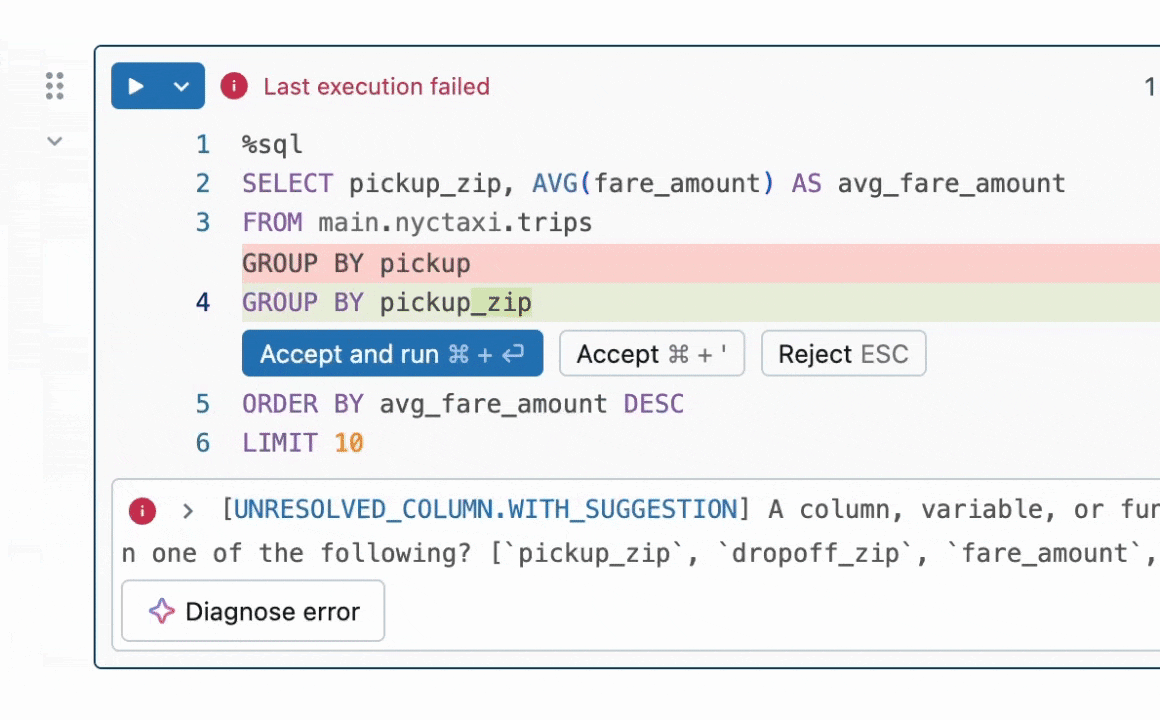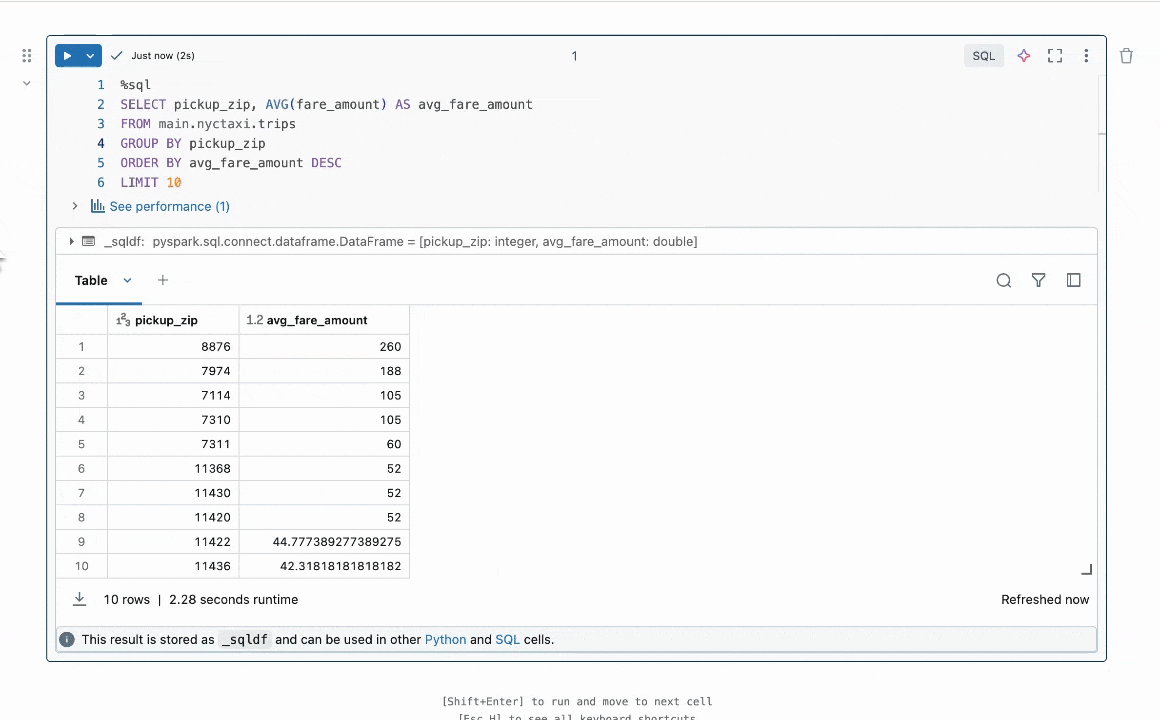
図1:クイックフィックスは、インラインでコード修正を提案することでユーザーがエラーを解決するのを助けます。
結果の要約:私たちは、コードのバグを修正する必要があるプログラム修復のタスクに焦点を当てています。この問題は、LLMなし[1, 2]で広く研究されてきましたが、最近ではLLMを用いて[3, 4]研究されています。業界では、DatabricksのQuick Fixのような実用的なLLMエージェントが利用可能です。図1は、Databricksのノートブック環境でクイックフィックスエージェントが動作している様子を示しています。このプロジェクトでは、テレメトリー分析のためにDatabricksの従業員が書いた内部コードに対してLlama 3.1 8b Instructモデルを微調整しました。微調整されたLlamaモデルは、内部ユーザーに対するライブA/Bテストを通じて他のLLMと比較評価されます。図2で結果を示し、微調整されたLlamaがGPT-4oに対して受け入れ率で1.4倍の改善を達成し、推論遅延を2倍に減少させたことを示しています。
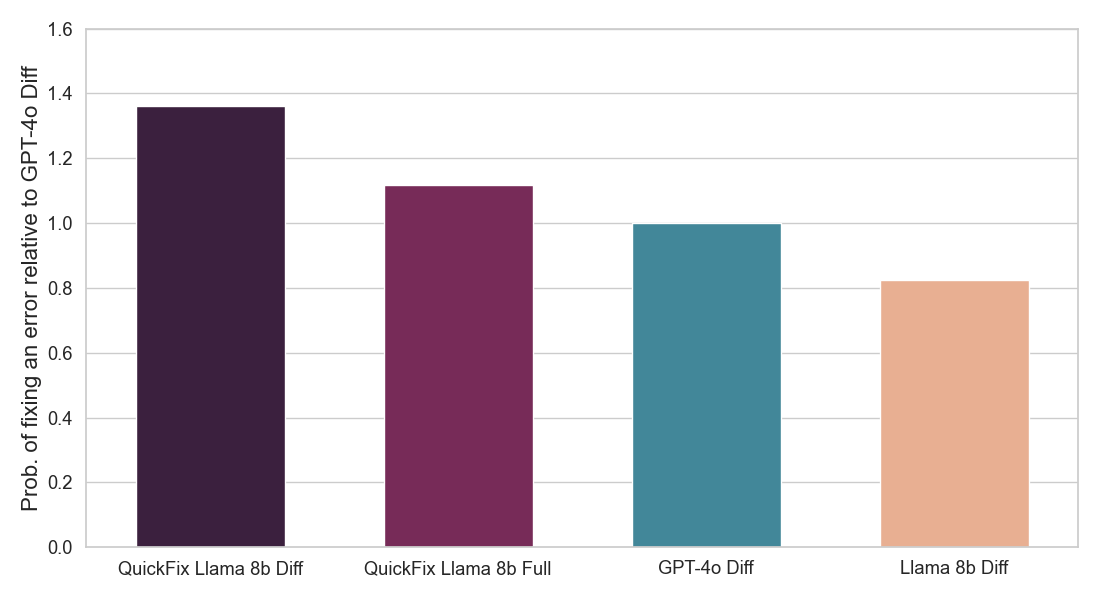
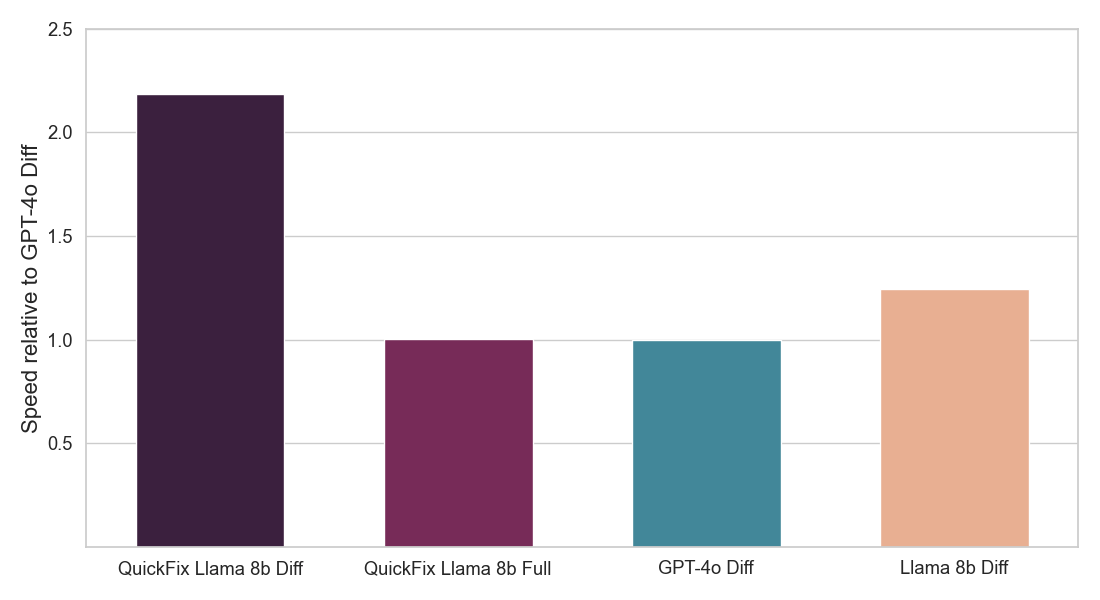
図2:ユーザーが受け入れたLLM修正の割合(上)と各クイックフィックスLLMエージェントの推論速度(下)を示しています。両方の数値はGPT-4oエージェントに対して正規化されています(詳細は以下を参照)。私たちのモデル(QuickFix Llama 8b Diff)は、最高の精度と最低の遅延を両立しています。suffixがdiffのモデルはバグのあるコードに編集を生成し、suffixがfullのモデルは完全なコードを生成します。
なぜそれが重要なのか?多くの組織、特に既存のDatabricksの顧客は、社内の知識、概念、および好みを含むコーディング使用データを持っています。私たちの結果に基づいて、これらの組織は、より良いコード品質と推論速度を達成するために、小規模なオープンソースのLLMを微調整することができます。これらのモデルは、組織または信頼できる第三者によってホストされ、コスト、信頼性、およびコンプライアンスの向上が期待できます。
インタラクションデータでの訓練が特に効果的である理由を3つ強調します。まず、それは自然に生成されるため、注釈の労力は必要ありません。二つ目に、実際に遭遇する例が含まれているため、適度な量でも微調整に特に有用です。最後に、LLMエージェントとのインタラクションによって常にインタラクションデータが生成されるため、新たに生成されたインタラクションデータを繰り返し使用してLLMをさらに微調整することができ、これによりNever Ending Learning(NEL)が��実現します。
次のステップこれらの教訓は他のエンタープライズアプリケーションにも当てはまると考えています。組織は、Databricksの微調整サービスを使用して、プログラム修復やその他のタスクのためにLlamaなどのLLMを微調整し、モデルをワンクリックで提供することができます。ここから始めることができます。また、お客様が自身のデータを使用してQuick Fixをパーソナライズする機能を提供することも検討しています。
私たちの研究の詳細
Databricksのワークスペースは、生産性を向上させるための複数のLLMエージェントを提供します。これには、コードの自動補完のためのLLMエージェント、ユーザーを支援するための会話を行うAIアシスタント、プログラム修復のためのクイックフィックスエージェントが含まれます。このブログ投稿では、クイックフィックスエージェント(図1)に焦点を当てています。
プログラム修復は、実際には難しい問題です。エラーは、構文の間違いから間違った列名、微妙な意味の問題まで様々です。さらに、パーソナライゼーションの側面や制約が、既製のLLMによって常に適切に処理されるわけではありません。例えば、Databricksのユーザーは通常、PL/SQLスクリプトではなく、標準のANSIまたはSpark SQLを書きますが、他の組織では異なる形式が好まれるかもしれません。同�様に、コードを修正する際には、提案された修正が正しい場合でも、コーディングスタイルを変更したくありません。GPT-4、o1、Claude 3.5などの独自モデルを使用し、プロンプトエンジニアリングを用いてこれらの制限を解消しようとすることができます。しかし、プロンプトエンジニアリングは微調整ほど効果的ではないかもしれません。さらに、これらのモデルは高価で、レイテンシーは重要な要素であり、ユーザーがコードを自分で修正する前に修正を提案したいからです。コンテキスト内学習[5]や自己反省[6]などのプロンプトエンジニアリングのアプローチは、さらにレイテンシを増加させる可能性があります。最後に、一部の顧客は他所でホストされている独自のモデルを使用することに躊躇するかもしれません。
Llama 8b、Gemma 4b、R1 Distill Llama 8b、Qwen 7bなどの小規模なオープンソースモデルは、異なるトレードオフを提供する代替手段となります。これらのモデルは安価で速く、組織または信頼できる第三者によって訓練およびホストされ、より良いコンプライアンスが実現できます。しかし、それらは上記の一部の独自モデルよりも大幅に性能が低下する傾向があります。図1で見ることができるように、Llama 3.1 8bの指示モデルは、テストされたモデルの中で最も性能が低いものです。これは次のような疑問を提起します:
小規模なオープンソースモデルを適応させ、精度、コスト、速度で既製の独自モデルを上回ることは可能でしょうか?
プロンプトエンジニアリングは一部の利益を提供します(以下の結果を参照)、しかし、LLMの微調整よりも効果的ではない傾向があります、特に小型モデルの場合は。しかし、効果的な微調整を行うためには、適切なドメインデータが必要です。それはどこから得られるのでしょうか?
あなたのインタラクションデータを使用してLlama 8bを微調整する
プログラム修復タスクの場合、ユーザーが自然に生成するインタラクションデータを使用して微調整を行うことができます。これは次のように機能します(図3):
 図3: LLMの微調整にデプロイメントログを使用し、LLMの絶えず微調整するために使用できます。
図3: LLMの微調整にデプロイメントログを使用し、LLMの絶えず微調整するために使用できます。
- ユーザーがエラーを引き起こすコードセルを初めて実行したときのバグのあるコードを記録します。 y,また、エラーメッセージ、周囲のコードセル、メタデータ(例えば、利用可能なテーブルとAPIのリスト)。
- 次に、ユーザーが元々バグのあるセルのコードを正常に実行するたびにコードをログに記録します。このレスポンスは、クイックフィックスラマエージェント、ユーザー自身、または両者によって生成される可能性があります。
- ファインチューニングのためのデータセットに(x, y, y')を保存します。
我々は二つの極端なケースをフィルタリングします:提案された修正コードy'が実際のコードyと同じである場合(例えば、設定を他の場所で変更することで権限問題を修正するなど、外部の理由によるバグ修正を示す)、およびy'がyと大幅に異なる場合(ターゲット修正ではなく、潜在的な書き換えを示す)。このデータを使用して、バグのあるコード y とコンテキスト x を与えられたときに y' を生成するように学習することで微調整を行うことができます。
我々は、上記のように処理されたDatabricks自身の内部インタラクションデータを使用して、Llama 3.1 8bの指示モデルを微調整します。我々は2種類のモデルを訓練します - 一つは全体の修正コードを生成するもの(フルモデル)、もう一つはバグのあるコードを修正するために必要なコード差分のみを生成するもの(差分モデル)。後者はトークンを少なく生成する必要があるため、通常は速いですが、より難しいタスクを解決します。我々はDatabricksの微調整サービスを使用し、異なる学習率と訓練イテレーションでスイープを行いました。図2のA/Bテスト�の結果は、我々の微調整したLlamaモデルが既製のLLMよりもバグの修正に優れており、また速度も大幅に向上していることを示しています。
最適なハイパーパラメータを選択するために、私たちはインタラクションデータの保持されたサブセットでの完全一致精度を測定するオフライン評価を使用します。完全一致精度は、バグのあるコード y とコンテキスト x が与えられたときに、私たちのLLMが修正されたコード y' を生成できるかどうかを測定する0-1のスコアです。これはA/Bテストよりもノイズが多い指標ですが、ハイパーパラメータ選択のための有用な信号を提供することができます。図4でオフライン評価の結果を示します。元のLlamaモデルはGPT-4oモデルよりも大幅に劣っていますが、微調整されたLlamaモデルは全体的に最も優れています。さらに、コンテキスト内学習(ICL)を通じたプロンプトエンジニアリングは大幅な利益を提供しますが、微調��整を行うことほど効果的ではありません。
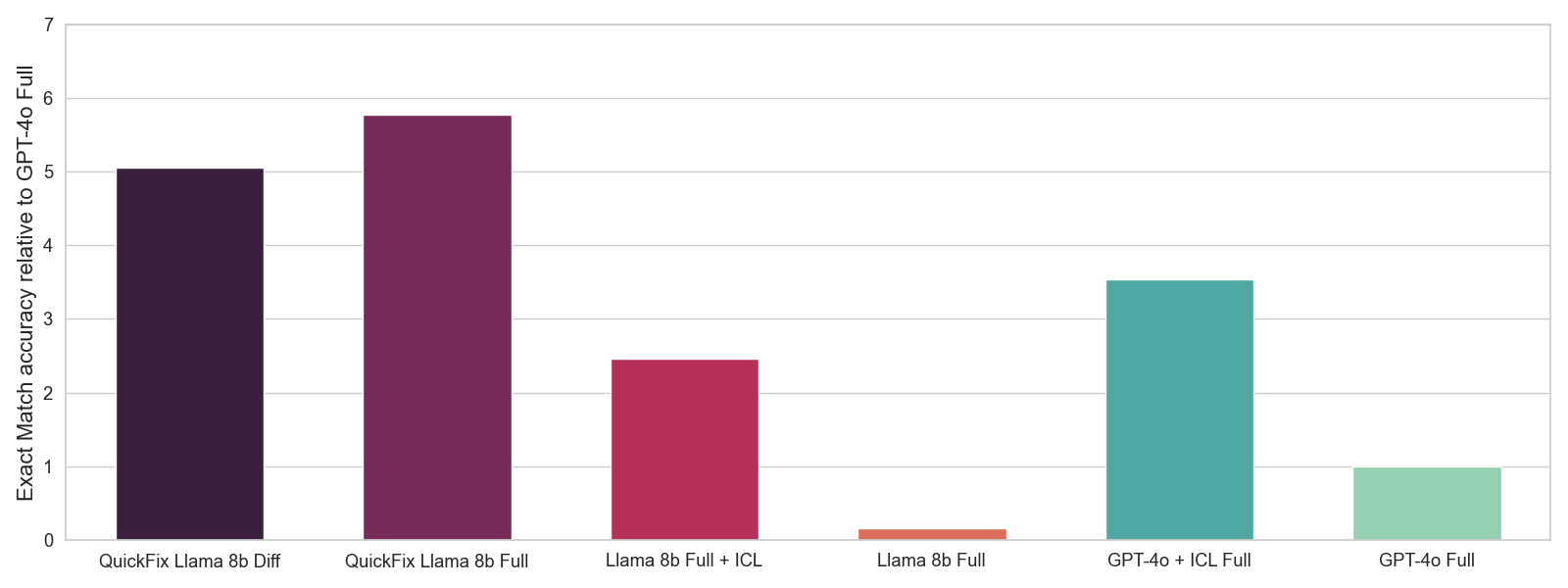 図4:異なるLLMとのオフライン評価。ICLのために5つの例を使用します。生成された修正が真実の修正と一致するかどうかに基づいて、0-1の正確な一致精度の平均を報告します。GPT-4oの精度に対して精度を正規化します。
図4:異なるLLMとのオフライン評価。ICLのために5つの例を使用します。生成された修正が真実の修正と一致するかどうかに基づいて、0-1の正確な一致精度の平均を報告します。GPT-4oの精度に対して精度を正規化します。
最後に、我々のクイックフィックスLlamaモデルは何を学びますか?利点を示すために、以下に2つの例を挙げます。
 例1:GPT-4oとQuickFix Llamaモデルによる予測。実際のテーブル名と定数は削除されました。
例1:GPT-4oとQuickFix Llamaモデルによる予測。実際のテーブル名と定数は削除されました。
最初の例では、GPT-4oエージェントがバグのあるSQLコードを誤ってPySpark SQLに変換しましたが、微調整されたQuickFix Llamaモデルは元のコードスタイルを保持しました。GPT-4oの編集により、ユーザーが不必要な差分を元に戻すための時間を費やすことになり、バグ修正エージェントの利点が減少する可能性があります。
 例2: GPT-4oとQuickFix Llamaモデルによる予測。簡潔さのためにコンテキストを表示していませんが、このケースではコンテキストには、テーブル table2 のための列 _partition_date が含まれています。実際のテーブル名と定数は削除されました。
例2: GPT-4oとQuickFix Llamaモデルによる予測。簡潔さのためにコンテキストを表示していませんが、このケースではコンテキストには、テーブル table2 のための列 _partition_date が含まれています。実際のテーブル名と定数は削除されました。
二つ目の例では、GPT-4oエージェントがエラーメッセージで与えられたヒントに過度に依存して、列の日付を_event_timeに誤って置き換えたことがわかりました。しかし、正しい編集は、コンテキストから_partition_dateという名前の列を使用することで、これはユーザーとQuickFix Llamaが行うことです。GPT-4oの編集は、SQLエンジンが提案した時間変数を使用して表面的には正しいように見えます。しかし、この提案は、微調整によって修正できるドメイン固有の知識の欠如を実際に示しています。
まとめ
組織には、カスタムLLMエージェントが最適に対応する特定のコーディングニーズがあります。私たちは、LLMの微調整がコーディング提案の品質を大幅に向上させることができ、プロンプトエンジニアリングのアプローチを上回ることができることを発見しました。特に�、微調整した小型のLlama 8Bモデルは、大幅に大きな独自モデルよりも速く、安く、正確でした。最後に、トレーニング例は、追加の注釈コストなしで利用可能なインタラクションデータを使用して生成することができます。これらの結果は、プログラム修復タスクを超えて一般化すると考えています。
Mosaic AI Model Trainingを使用すると、お客様はLlamaなどのモデルを簡単に微調整することができます。DatabricksでオープンソースのLLMを微調整し、デプロイする方法についてはここで詳しく学ぶことができます。あなたの組織向けのパーソナライズされたQuick Fixモデルに興味がありますか?詳細を知りたい方は、Databricksのアカウントチームにお問い合わせください。
謝辞: 貴重なアドバイス、助け、注釈を提供してくれたMichael Piatek、Matt Samuels、Shant Hovsepian、Charles Gong、Ted Tomlinson、Phil Eichmann、Sean Owen、Andy Zhang、Beishao Cao、David Lin、Yi Liu、Sudarshan Seshadriに感謝します。
参照
- Automated program repair, Goues, et al., 2019. In Communications of the ACM 62.12 (2019): 56-65.
- Semfix: Program repair via semantic analysis, Nguyen et al. 2013. In the 35th International Conference on Software Engineering (ICSE). IEEE, 2013.
- Inferfix: End-to-end program repair with LLMs, Jin et al., 2023. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering.
- RepairAgent: An Autonomous, LLM-Based Agent for Program Repair, Bouzenia et al., 2024. In arXiv https://arxiv.org/abs/2403.17134.
- Language models are few-shot learners, Brown et al. 2020. In the Advances in Neural Information Processing Systems (NeurIPS).
- Automatically correcting large language models: Surveying the landscape of diverse self-correction strategies, Pan et al., 2024. In Transactions of the Association for Computational Linguistics (TACL).
*著者はアルファベット順にリストされています