MapInPandasとDelta Live Tablesで一般的でないファイル形式を大規模に処理する

翻訳:Junichi Maruyama. - Original Blog Link
様々なファイル形式
最新のデータエンジニアリングの世界では、Databricks Lakehouse Platformは信頼性の高いストリーミングおよびバッチdata pipelinesの構築プロセスを簡素化します。しかし、曖昧なファイル形式や一般的でないファイル形式を扱うことは、Lakehouseへのデータ取り込みにおいて依然として課題となっています。データを提供する上流のチームは、データの保存と送信方法を決定するため、組織によって標準が異なります。例えば、データエンジニアは、スキーマの解釈が自由なCSVや、ファイル名に拡張子がないファイル、独自のフォーマットでカスタムリーダーが必��要なファイルなどを扱わなければならないことがあります。このデータをParquetで取得できないかとリクエストするだけで問題が解決することもあれば、パフォーマンスの高いパイプラインを構築するために、よりクリエイティブなアプローチが必要になることもあります。
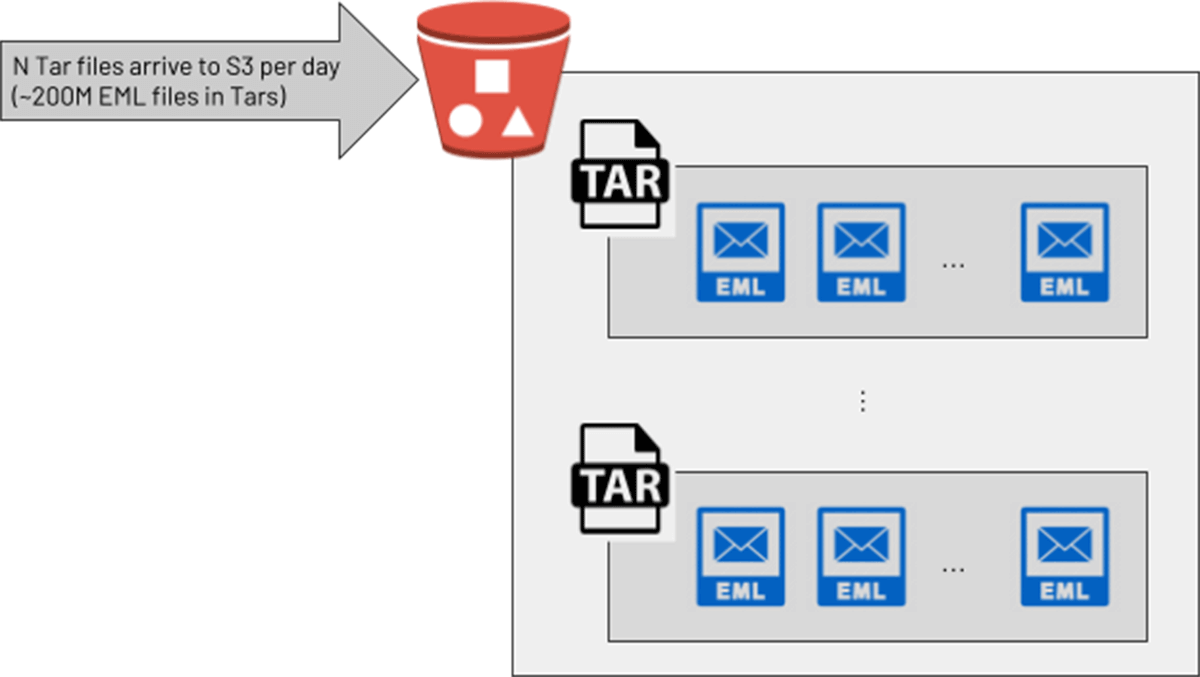
ある大手顧客のデータエンジニアリングチームは、Databricks上でサイバーセキュリティのユースケースのために電子メールの生テキストを処理したいと考えていました。アップストリームのチームはこれをzip圧縮されたTarファイルで提供し、各Tarファイルには多数のメール(.eml)ファイルが含まれていました。PySparkのUDFがPythonの "tarfile "ライブラリを呼び出して各Tarを文字列の配列に変換し、PySparkネイティブのexplode()関数を使用して配列内の各メールに対して新しい行を返します。これはテスト環境では解決策に思えましたが、より大きなTarファイル(Tarringする前のメールファイルは最大300Mb)を扱う本番環境に移行すると、このパイプラインはメモリ不足エラーによるクラスタクラッシュを引き起こし始めました。本番環境では1日あたり2億通のメールを処理することを目標としていたため、よりスケーラブルなソリューションが必要でした。
MapInPandas()であらゆるファイル形式に対応
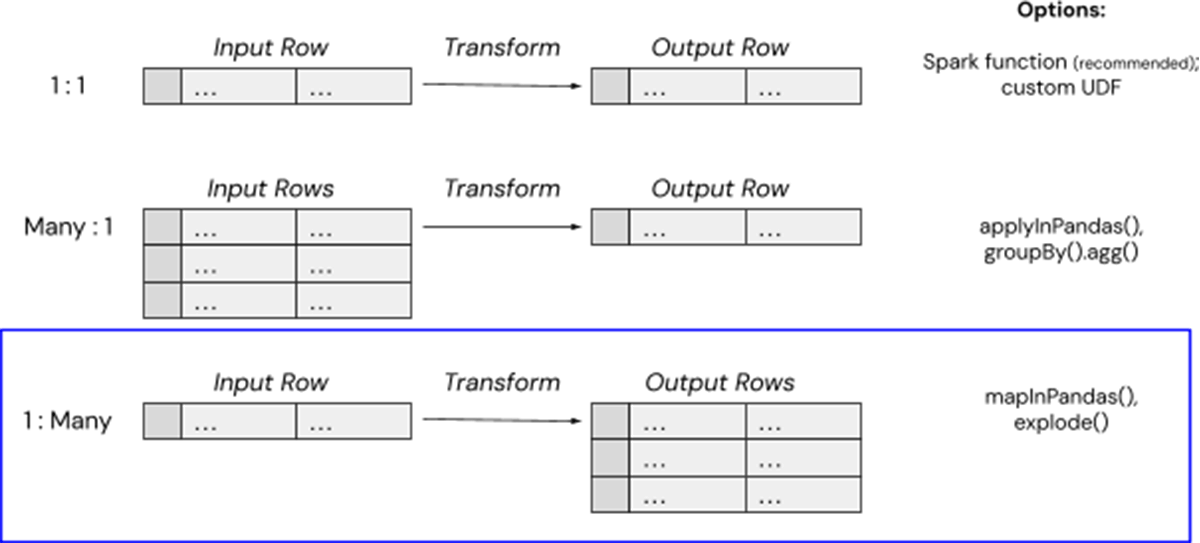
Databricksには複雑なデータ変換を処理するためのシンプルなメソッドがいくつかありますが、今回はmapInPandas()を使って、1つの入力行(例えば大きなTarファイルのクラウドストレージのパス)を複数の出力行(例えば個々の.emlテキストファイルの内容)にマッピングします。Spark 3.0.0で導入されたmapInPandas() は、Pythonネイティブの関数でSpark DataFrameの各行に対して任意のアクションを効率的に実行し、複数の行を返すことができます。これはまさに、Spark UDFによるメモリオーバーヘッドを回避しながら、各メールの内容を含む複数の使用可能な行に圧縮ファイルを "解凍 "するために、このハイテク顧客が必要としていたものです。
ファイル解凍のための mapInPandas()
さて、基本を理解したところで、この顧客がこれをどのように彼らのシナリオに適用したかを見てみよう。下図は、関係するアーキテクチャー・ステップの概念モデルである:
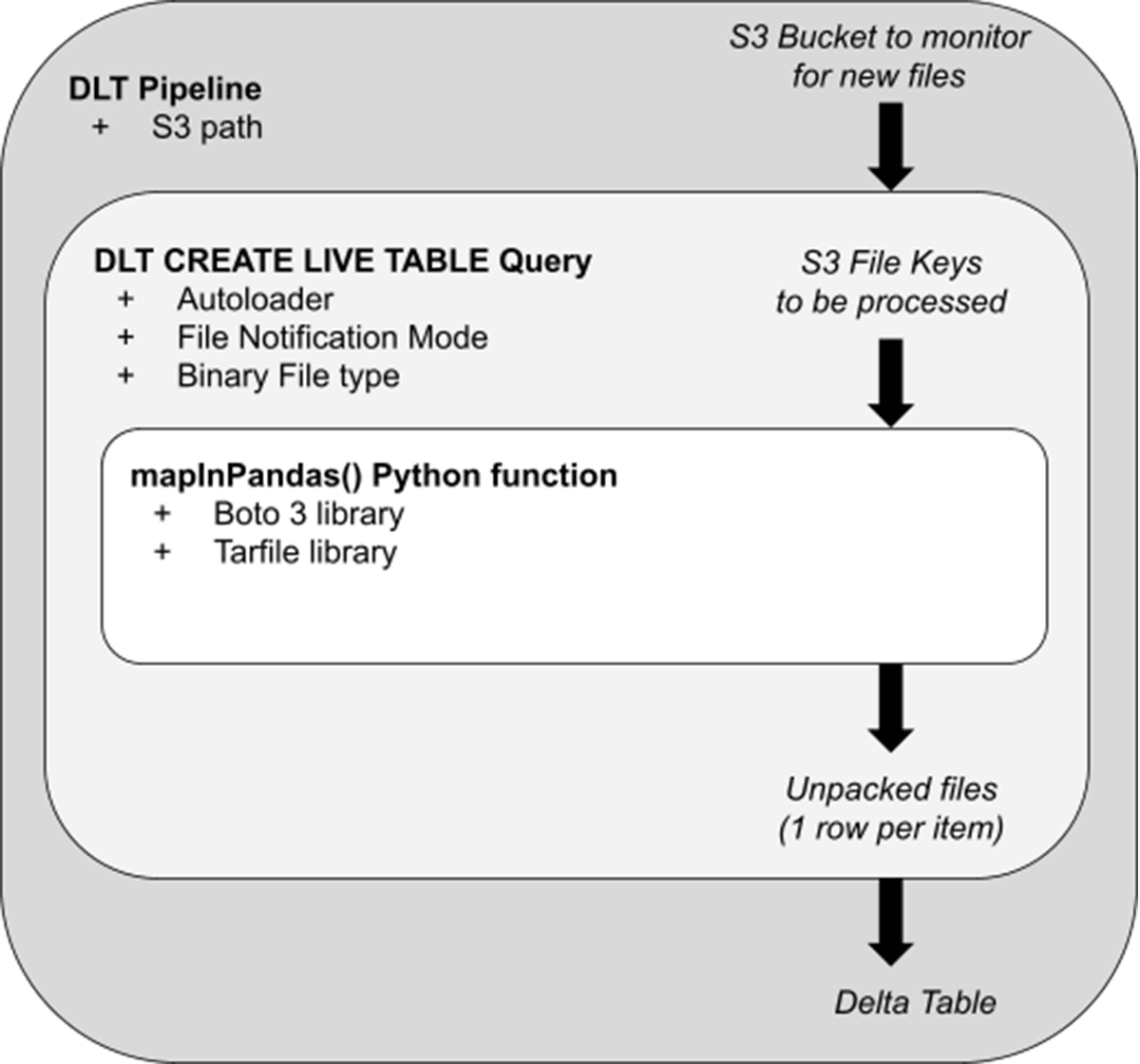
- Delta Live Tables (DLT)パイプラインは、解凍やその他のロジックのオーケストレーションレイヤーとして機能します。本番モードでは、このス�トリーミング・パイプラインはS3に到着した新しいTarファイルをピックアップし、解凍します。非Photonパイプラインでの予備テストでは、デフォルトのDLTクラスタ設定で、最大430MbのTarファイルがクラスタにメモリを圧迫することなく迅速に処理されました(バッチあたり30秒未満)。強化された自動スケーリングにより、各ワーカーが並列に解凍を実行するため、DLTクラスタは入力されるファイル量に合わせてスケールアップ/ダウンします。
- パイプライン内では、"CREATE STREAMING TABLE "クエリが、パイプラインがインジェストするS3パスを指定します。File Notificationモードでは、パイプラインは到着した新しいTarファイルのリストを効率的に受け取り、それらのファイルの "キー "を最も内側のロジックで解凍するために渡す。
- mapInPandas()関数に渡されるのは、pandas DataFramesのイテレータ形式で処理するファイルのリストです。標準のBoto3ライブラリとtar専用のPython処理ライブラリ(Tarfile)を使用して、各ファイルを解凍し、生のメールごとに1行を返します。
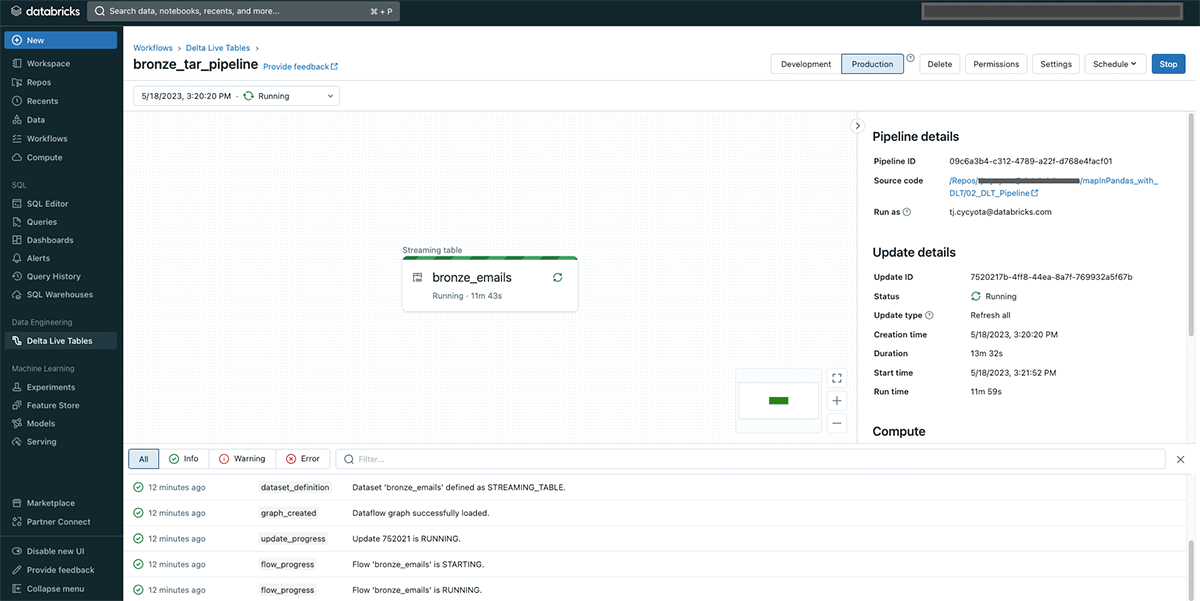
最終的には、Databricks SQLやノートブックからクエリ可能な、分析可能なDeltaテーブルができあがります。Deltaテーブ��ルには、Eメールデータが含まれ、email_idカラムは、梱包を解いたEメールを一意に識別します:
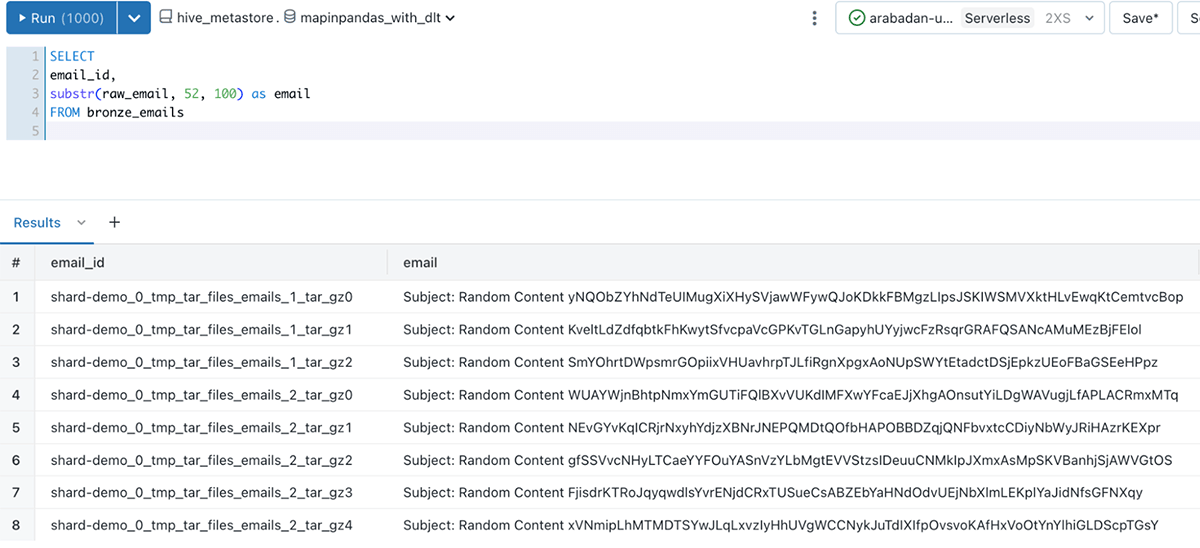
このソリューションを紹介するノートブックには、mapInPandas()の完全なロジックとパイプラインの構成設定が含まれています。こちらをご覧ください。here
さらなる応用
ここで説明したアプローチにより、重要なビジネスアプリケーションのために、低レイテンシでTarメールファイルを処理するスケーラブルなソリューションを手に入れることができました。Delta Live Tablesは、ファイルの到着量に合わせて素早く調整することができ、基礎となるコードに変更を加えることなく、パイプラインを連続からトリガーに切り替えることができます。この例では、S3から生ファイルを取り込む "ブロンズ "レイヤーに焦点を当てていますが、このパイプラインは、ビジネスユーザーや機械学習アプリケーションがこの貴重なデータソースを利用できるように、クレンジング、エンリッチメント、集計ステップで簡単に拡張することができます。
しかし、より一般的には、このmapInPandas()アプローチは、Sparkで他の方法で困難なあらゆるファイル処理タスクに効果的です:
- Sparkでサポートされているコーデック/フォーマットがないファイルの取り込み
- ファイル名にfiletypeが��ないファイルの処理:file123が実際には "tar "タイプのファイルであるが、.tar.gzファイル拡張子なしで保存された場合。
- Zstandard圧縮アルゴリズムのような独自の拡張子やニッチな拡張子を持つファイルの処理:MapInPandas関数の最も内側のループを、行を生成するために必要なPythonライブラリで置き換えるだけ。
- 大きなファイル、モノリシックなファイル、非効率的に保存されたファイルを、メモリ不足になることなくDataFrameの行に分解する。
デルタ・ライブ・テーブル・ノートブックの他の例はこちらで、DLTを本番でどのように使用しているかはこちらでご覧ください。

