本番運用 - Databricksを使用した高品質の RAG アプリケーション
Vector Searchの一般提供開始とモデルサービングのメジャーアップデートのお知らせ
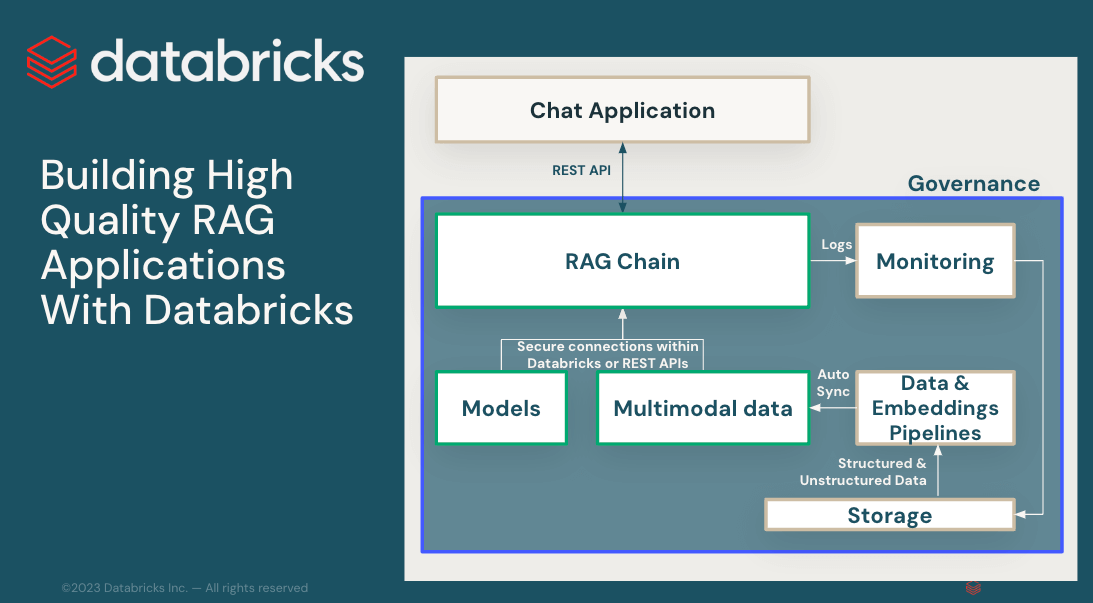
12 月に、Databricks はRetrieval Augmented Generation (RAG) を使用して AI アプリケーションを本番運用するための新しいツールを発表しました。それ以来、 Databricks Data Intelligence Platform上で何千もの顧客によって構築される RAG アプリケーションが爆発的に増加しています。
本日、 DatabricksVector Searchの一般提供やモデルサービングのメジャーアップデートなど、 Data Intelligence Platform で直接利用できるネイティブ機能を使用して、企業が高品質の RAG アプリケーションを簡単に構築できるようにするためのいくつかの発表をいたします。
高品質AIアプリケーションの課題
お客様と緊密に連携してAIアプリケーションを構築および展開する中で、最大の課題は、お客様向けシステムに求められる高い品質基準を達成することであると認識しました。開発者は、 AIアプリケーションの出力が正確で安全であり、管理されたものであることを確認してからお客様に提供するために、膨大な時間と労力を費やしており、これらのエキサイティングな新技術の価値を引き出す上での最大の障害として、正確性と品質を挙げることがよくあります。
従来、品質を最大化するための主な焦点は、最高品質のベースライン推論および知識機能を提供する LLM を導入することにありました。 しかし、最近の調査では、ベースモデルの品質は AI アプリケーションの品質を決定する多くの要因の 1 つにすぎないことがわかっています。 企業のコンテキストとガイダンスのない LLM は、デフォルトではデータを十分に理解していないため、依然としてハルシネーションを起こします。 AI アプリケーションは、ガバナンスを理解しておらず、適切なアクセス制御がない場合、機密データや不適切なデータを公開する可能性もあります。
コーニングは、ガラスおよびセラミックスの技術が多くの産業および科学用途で使用されている材料科学企業です。 私たちは、Databricks を使用して AI 研究アシスタントを構築し、米国特許庁のデータの 2,500 万件の文書をインデックス化しました。 LLM を搭載したアシスタントが質問に高い精度で応答することは、研究者が取り組んでいるタスクを見つけてさらに進めるために、私たちにとって非常に重要でした。 これを実装するために、Databricks Vector Search を使用して、LLM に米国特許庁のデータを追加しました。 Databricks ソリューションにより、検索速度、応答品質、精度が大幅に向上しました。 - コーニング社 主席ソフトウェアエンジニア Denis Kamotsky 氏
品質に対するAIシステムアプローチ
GenAIアプリケーションで本番運用品質を達成するには、データ準備、検索モデル、言語モデル( SaaSまたはオープンソース)、ランキング、後処理パイプライン、プロンプトエンジニアリングなど、GenAIプロセスのすべての側面をカバーする複数のコンポーネントを含む包括的なアプローチが必要です。カスタムエンタープライズデータに関するトレーニング。これらのコンポーネントが一緒になってAIシステムを構成します。
Ford Direct では、ディーラーがパフォーマンス、在庫、傾向、顧客エンゲージメントの指標を評価できるように、統合チャットボットを作成する必要がありました。 Databricks Vector Search独自のデータとドキュメントを、検索拡張生成 (RAG) を使用する生成 AI ソリューションに統合できるようになりました。 Vector Search と Databricks Delta Tables および Unity Catalog の統合により、デプロイ済みのモデルやアプリケーションを変更したり再デプロイしたりすることなく、ソース データが更新されるたびにベクター インデックスがリアルタイムでシームレスに作成できるようになりました。 - フォードダイレクト、アナリティクス担当副社長、トム・トーマス氏
本日、お客様が本番運用品質の GenAI アプリケーションを構築できるようにするための主要なアップデートと詳細を発表できることを嬉しく思います。
- 顧客がエンタープライズ データで LLM を拡張できるように特別に構築されたサーバーレス ベクトル データベースでVector Searchの一般提供が開始されました。
- 今後数週間以内にモデルサービング基盤モデルAPIが一般提供され、サービスエンドポイントから最先端のLLMにアクセスしてクエリを実行できるようになります。
- モデルサービング のメジャーアップデート
- 新しいユーザーインターフェースにより、LLMのデプロイ、提供、監視、管理、クエリがこれまでになく簡単になりました。
- Claude3、Gemini、DBRX、Llama3などの最新モデルを追加でサポート
- 大規模な LLM のデプロイとクエリのパフォーマンスの向上
- ガバナンスと監査性の向上により、すべてのタイプのサービスエンドポイントで推論テーブルがサポートされます。
また、本番運用品質の GenAI の導入に役立つ以下の機能も以前に発表しました。
- Feature Serving の一般提供が開始され、RAG アプリで構造化コンテキストを利用できるようになります
- RAG アプリの本番運用パフォーマンスを監視するための柔軟な品質モニタリング インターフェイス。
今週は、これらの新機能を使用して高品質の RAG アプリを構築する方法についての詳細なブログを公開します。また、 LLMDatabricksが作成したオープンな汎用である DBRX の構築方法についてのインサイダーのブログも公開します。
こちらもご覧ください
- GenAI Payoffバーチャルイベントを見る
- Vector Searchとモデルサービングのドキュメントを参照してください
- データ + AI サミットにご参加ください
Databricksの投稿を見逃さないようにしましょう
次は何ですか?


データサイエンス・ML
October 30, 2024/1分未満