Apache ParquetデータレイクをDelta Lakeにシームレスに移行する

Original: Seamlessly Migrate Your Apache Parquet Data Lake to Delta Lake
翻訳: junichi.maruyama
Apache Parquet は、今日のビッグデータの世界で最も人気のあるオープンソースのファイルフォーマットの1つです。列指向であるApache Parquetは、データの保存と検索を効率的に行うことができるため、過去10年間に多くの企業がデータレイクにおけるデータ保存の必須方法として採用しました。中には、Apache Parquetファイルを「データベーステーブル」として利用し、CRUD操作を行う企業もあります。しかし、Apache Parquetファイルは単なるデータファイルであり、トランザクションロギング、統計収集、インデックス作成機能を持たないため、ACIDに準拠したデータベース操作には適していません。このようなツールの構築は、膨大な数の開発チームが独自に開発し、それを維持する必要があるため、途方もない作業です。その結果生まれたのが、Apache Parquet Data Lakeです。その場しのぎのソリューションが精一杯で、ACID準拠の脆さから生じるテーブルの偶発的な破損などの問題に悩まされていました。
その解決策として登場したのが、Delta Lakeフォーマットです。これは、Apache Parquetデータレイクが抱えていた問題を正確に解決するために設計されたものです。Apache ParquetがDelta Lakeのベースとなるデータストレージフォーマットとして採用され、不足していたトランザクションロギング、統計収集、インデックス作成機能が組み込まれ、必要なACIDコンプライアンスと保証を提供しました。オープンソースのDelta Lakeは、Linux Foundationのもと、業界で広く利用されるようになり、力強さを増しています。
しかし、データ移行には計画と適切なアプローチの選択が必要です。Delta Lakeにデータを移行した後も、Apache Parquetデータレイクを共存させる必要があるシナリオもあり得ます。例えば、Apache Parquet Data Lakeに格納されたテーブルにデータを書き込むETLパイプラインがある場合、データを徐々にDelta Lakeに移行する前に詳細な影響分析を行う必要があります。その時まで、Apache Parquet Data LakeとDelta Lakeを同期させておく必要があります。このブログでは、いくつかの類似のユースケースを取り上げ、その取り組み方を紹介します。
Apache Parquet からDelta Lakeへの移行のメリット
- 何が変更されたか」を追跡するトランザクションログを持たない、Apache Parquetファイルのみで構成されたデータセットは、ACIDトランザクションに対して脆い挙動をもたらします。このような動作は、既存データの追加や変更時に、一貫性のない読み込みを引き起こす可能性があります。書き込みジョブが途中で失敗した場合、部分的な書き込みが発生する可能性があります。このような不整合は、再現性、監査、ガバナンスを必要とする規制環境において、関係者のデータに対する信頼を失わせる可能性があります。一方、Delta Lakeフォーマットは、ACIDに完全に準拠したデータストレージフォーマットです。
Delta Lakeのタイムトラベル機能により、チームはデータセットのバージョンや進化を追跡できるようになります。データに何らかの問題があった場合、ロールバック機能により、チームは以前のバージョンに戻ることができます。そして、修正策を実施した後に、データパイプラインを再生することができます。
Delta Lakeは、トランザクションログ、ファイルメタデータ、データ統計、クラスタリング技術などの帳票処理により、Apache Parquetベースのデータレイクよりもクエリパフォーマンスを大幅に向上させることができます。
スキーマエンフォースメントは、テーブルに適合しない新しいカラムやその他のスキーマの変更を拒否します。これらの高い基準を設定し、維持することで、アナリストやエンジニアは、データが最高レベルの完全性を持っていることを信頼し、明確な根拠を持って�、より良いビジネス上の意思決定を行うことができるようになります。Delta Lakeでは、ユーザーはスキーマを制御するためのシンプルなセマンティクスにアクセスすることができ、これには、ユーザーが誤ってテーブルをミスやゴミデータで汚してしまうことを防ぐスキーマエンフォースメントが含まれています。
スキーマエボリューションは、意図したスキーマの変更を自動的に行うことを容易にすることで、エンフォースメントを補完するものです。Delta Lakeは、リッチデータの新しいカラムが属する場合に、自動的に追加することを簡単にします。
Delta Lakeの内部機能については、こちらのDatabricks Blog シリーズをご参照ください。
Delta Lakeに移住する前に考えること
Apache Parquet Data LakeからDelta Lakeへの移行に採用すべき方法は、以下のマトリックスに記載されている1つまたは複数の移行要件に依存します。
Methods ⇩ |
Complete overwrite at source | Incremental with append at source | Duplicates data | Maintains data structure | Backfill data | Ease of use |
|---|---|---|---|---|---|---|
| Deep CLONE Apache Parquet | Yes | Yes | Yes | Yes | Yes | Easy |
| Shallow CLONE Apache Parquet | Yes | Yes | No | Yes | Yes | Easy |
| CONVERT TO DELTA | Yes | No | No | Yes | No | Easy |
| Auto Loader | Yes | Yes | Yes | No | Optional | Some configuration |
| Batch Apache Spark job | Custom logic | Custom logic | Yes | No | Custom logic | Custom logic |
| COPY INTO | Yes | Yes | Yes | No | Optional | Some configuration |
表1 - マイグレーションの選択肢を示すマトリックス
それでは、マイグレーション要件と、それがマイグレーション手法の選択にどのような影響を与えるかについて説明します。
Requirements
- ソースでの完全な上書き: この要件は、データ処理プログラムが実行されるたびにソースのApache Parquetデータレイク内のデータを完全にリフレッシュすることを指定し、変換が開始された後にターゲットデルタレイク内のデータを完全にリフレッシュする必要があります。
- ソースでアペンドするインクリメンタル: この要件は、データ処理プログラムが実行されるたびに、UPSERT(INSERT、UPDATEまたはDELETE)を使用してソースApache Parquetデータレイク内のデータを更新し、変換��が開始された後にターゲットデルタレイクのデータが増分的に更新されるべきであることを指定します。
- データを重複させる: この要件は、Apache Parquet Data LakeからDelta Lakeへデータを新しい場所に書き込むことを指定します。データの重複が好ましくなく、既存のアプリケーションに影響がない場合は、Apache Parquet Data LakeをDelta Lakeに変更する。
- データ構造を維持する: この要件は、変換時にソースでのデータパーティショニング戦略が維持されるかどうかを指定します。
- データの埋め戻し: データの埋め戻しには、新しいシステムで過去の欠落したデータや古いデータを埋めるか、古いレコードを更新することが含まれます。このプロセスは、データの異常や品質の問題により、データウェアハウスに不正なデータが入力された後に行われるのが一般的です。このブログの文脈では、「バックフィルデータ」要件は、変換開始後に変換元に追加されたデータのバックフィルをサポートする機能を指定します。
- 使いやすさ: この要件は、データ変換を構成し実行するためのユーザーの労力のレベルを指定します。
細部までこだわったメソッド
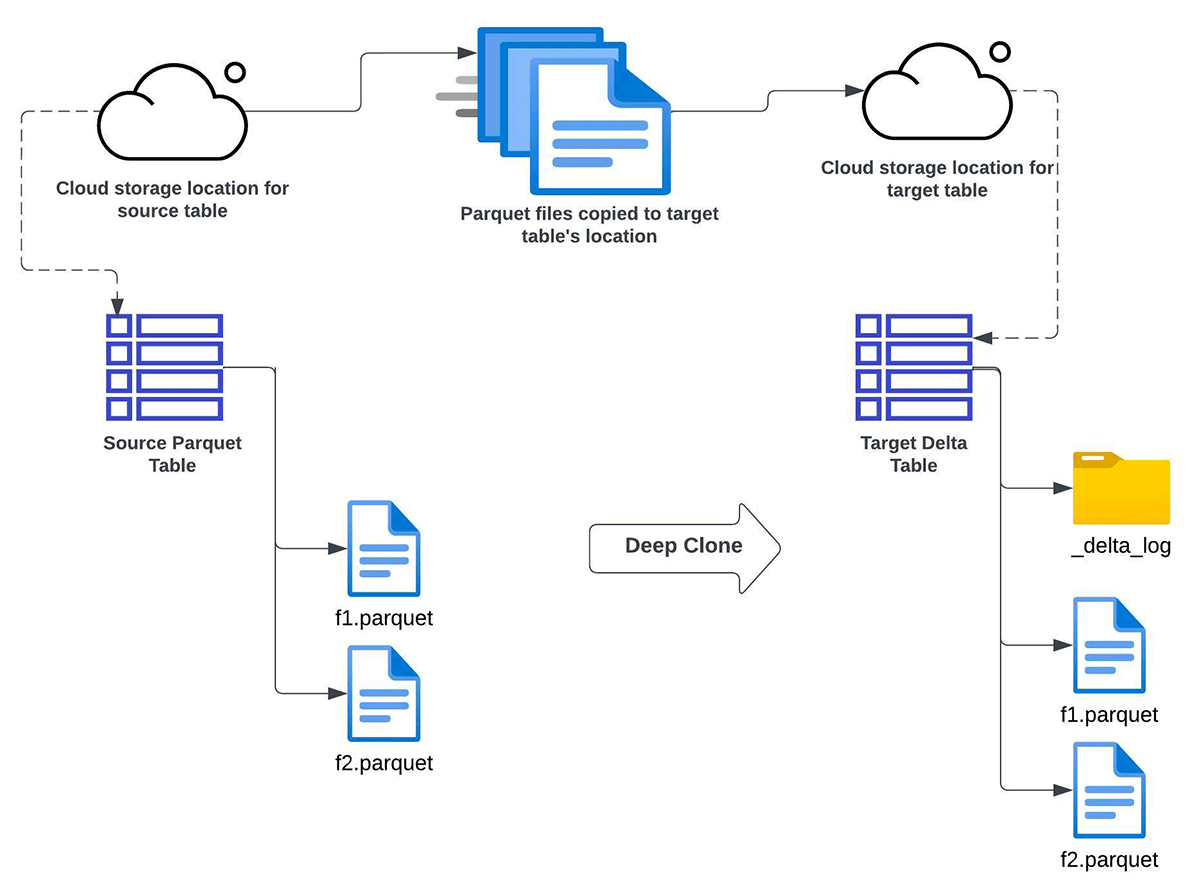
Deep CLONE Apache Parquet
Databricks のdeep clone 機能を使用して、Apache Parquet Data lake から Delta Lake にデータを段階的に変換することができます。この方法は、以下の条件を��すべて満たす場合に使用します:
- Apache ParquetテーブルからターゲットDelta Lakeテーブルを完全にリフレッシュするか、インクリメンタルにリフレッシュする必要がある。
- Delta Lakeへのインプレースアップグレードが不可能である。
- データの複製(複数のコピーの維持)が可能である。
- ターゲットスキーマはソーススキーマと一致する必要があります。
- データバックフィルの必要性がある。この文脈では、将来的にソーステーブルに追加データが入る可能性があることを意味します。そのような新しいデータは、その後のDeep Clone操作によって、ターゲットのDelta Lakeテーブルにコピーされ、同期されます。
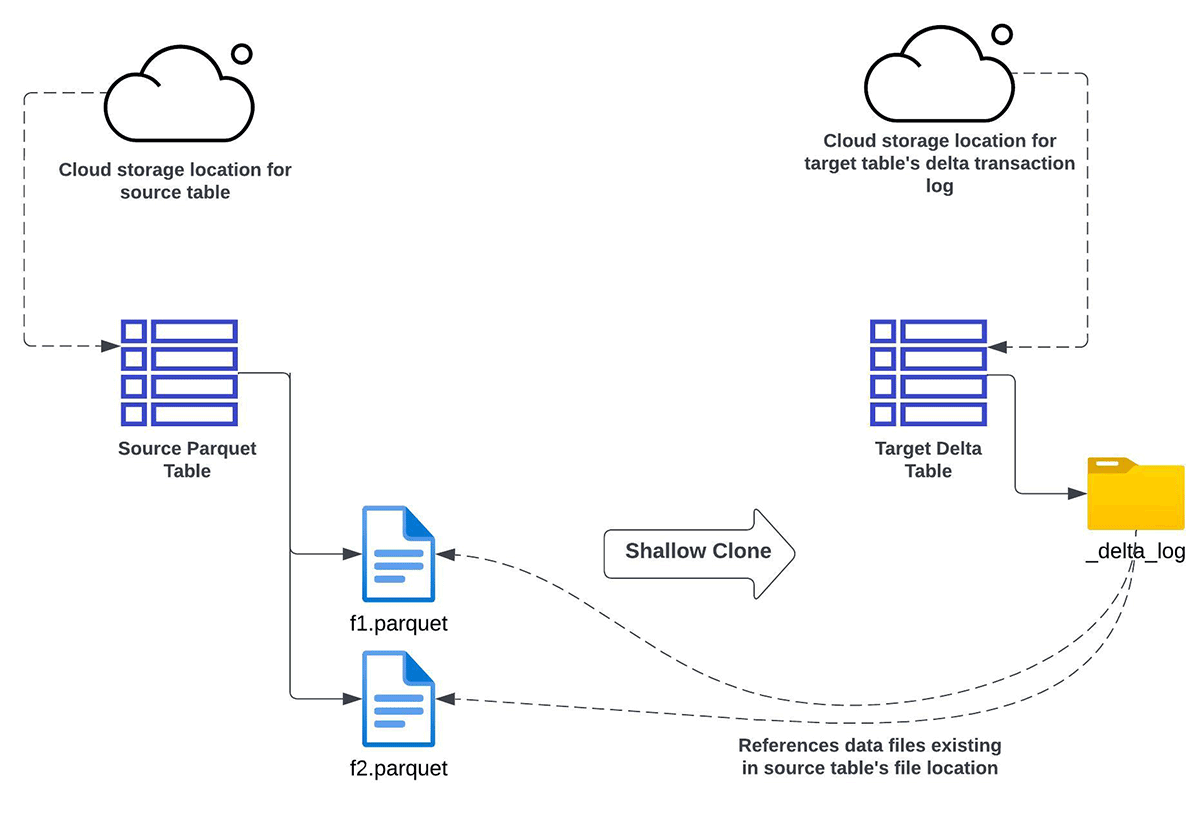
Shallow CLONE Apache Parquet
Databricks のshallow clone機能を使用して、Apache Parquet Data lake から Delta Lake へデータをインクリメンタルに変換することができます:
- Apache ParquetテーブルからターゲットDelta Lakeテーブルを完全にリフレッシュするか、インクリメンタルにリフレッシュしたい
- データを複製(コピー)したくない
- ソースとターゲットの��間で同じスキーマを使用したい
- データバックフィリングの必要性がある。これは、将来的にソース側に追加データが入る可能性があることを意味します。その後に行うシャロークローン操作によって、そのような新しいデータはターゲットのDelta Lakeテーブルで認識される(コピーされない)
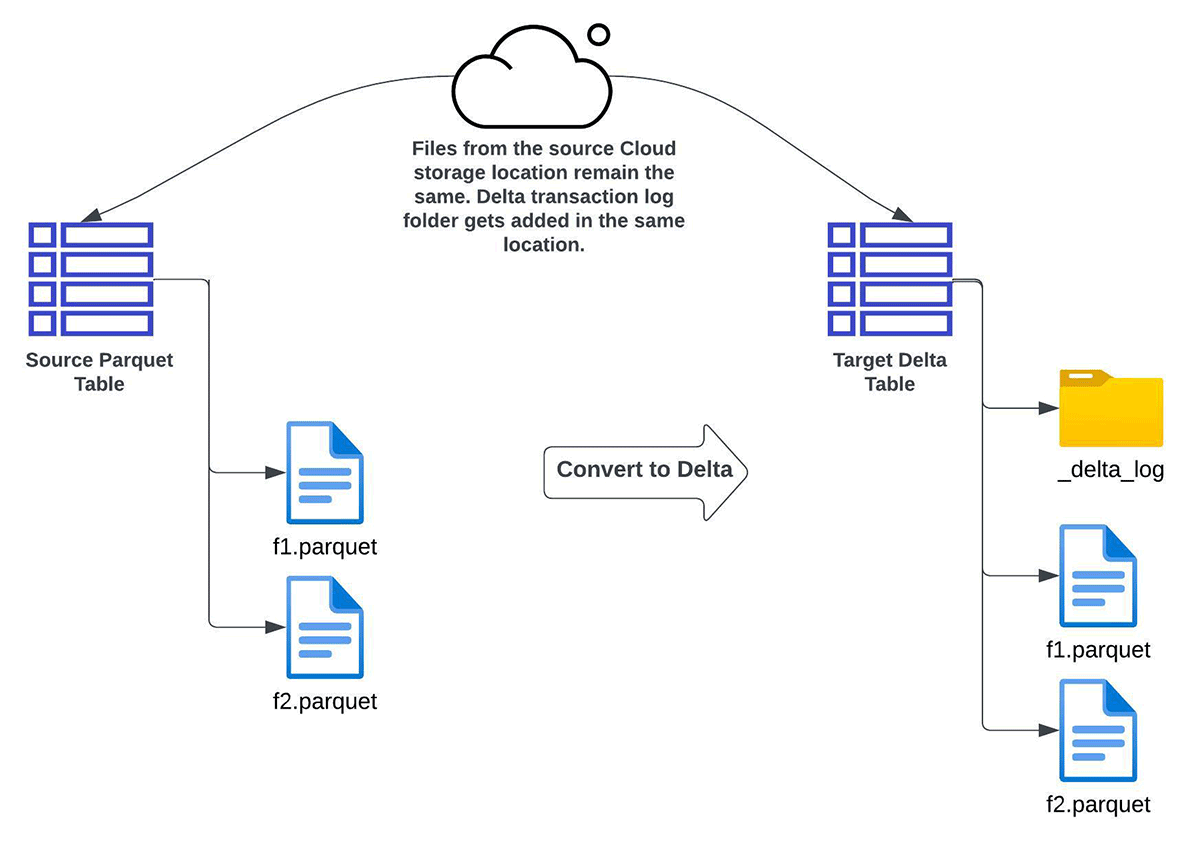
CONVERT TO DELTA
以下のような要件がある場合、Convert to Delta Lake 機能を使用することができます:
- ターゲットとなるDelta Lakeテーブルの完全なリフレッシュ(インクリメンタルリフレッシュではない)。
- データの複数コピーがない、つまりデータはその場で変換する必要がある。
- ソーステーブルとターゲットテーブルのスキーマが同じであること。
- データの埋め戻しがないこと。この文脈では、変換開始後にソースディレクトリに書き込まれたデータが、結果的にターゲットデルタテーブルに反映されない可能性があることを意味します。
ソースはインプレースでターゲットの Delta Lake テーブルに変換されるため、ターゲットテーブルに対する今後のすべての CRUD 操作は、Delta Lake ACID トランザクションを通じて行われる必要があります。
注意 - CONVERT TO DELTA オプションを使用する前に、注意事項を参照してください。変換処理中にデータファイルの更新や追加を行うことは避けるべきです。テーブルが変換された後、すべての書き込みがDelta Lakeを経由することを確認してください。
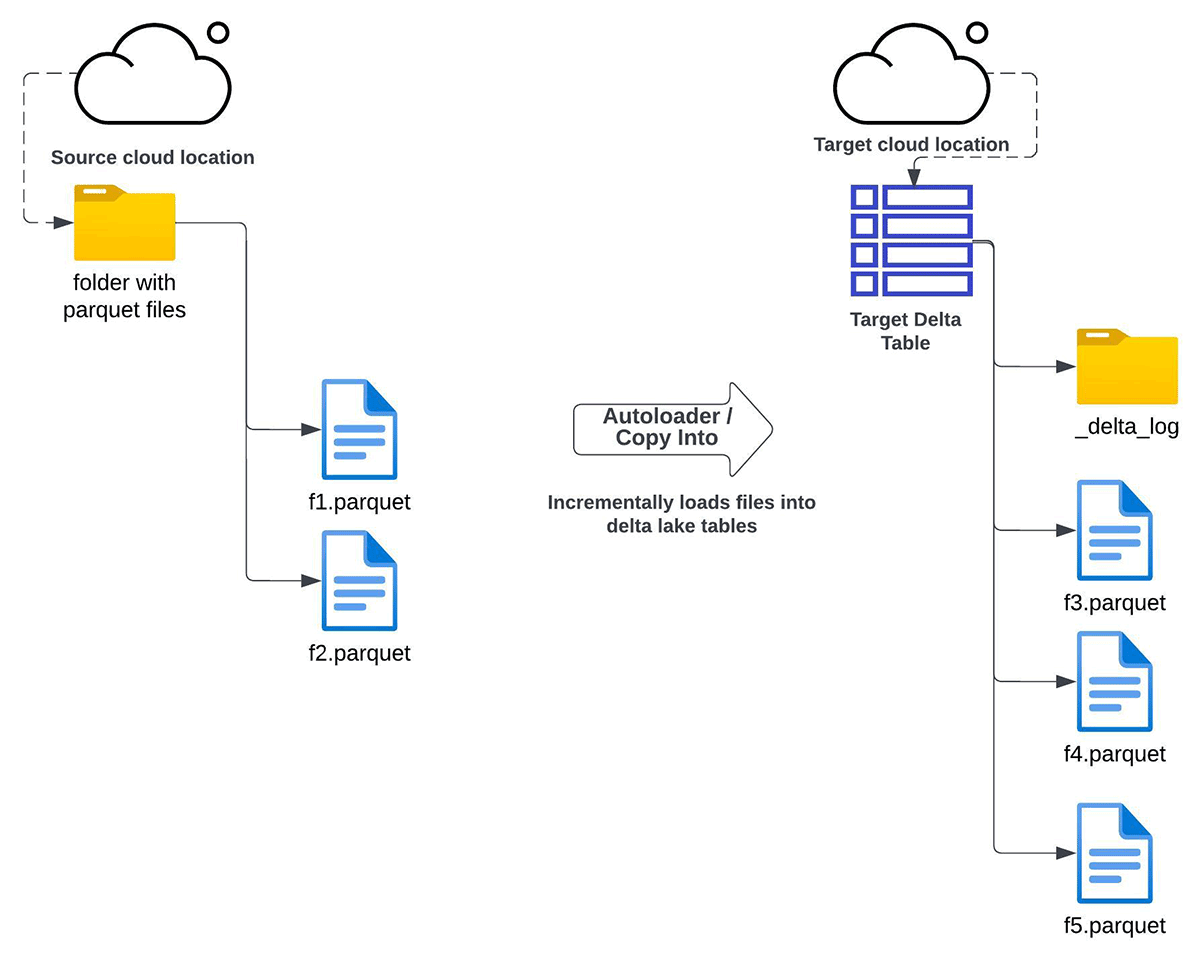
Auto Loader
Auto Loaderを使用すると、指定されたクラウドストレージディレクトリからターゲットDeltaテーブルにすべてのデータをインクリメンタルにコピーすることができます。この方法は、以下のような場合に使用できます:
- クラウドオブジェクトストレージに保存されているApache Parquetファイルから、Delta Lakeの完全なリフレッシュまたはインクリメンタルリフレッシュのいずれかを行う必要がある場合。
- Delta Lakeテーブルへのインプレースアップグレードが不可能である。
- データの複製(ファイルの複数コピー)が可能である。
- 移行後のソースとターゲット間のデータ構造(スキーマ)の維持は必須条件ではない
- データバックフィリングは特に必要ないが、将来的に必要な場合はオプションとして持っておきたい。
COPY INTO
COPY INTO SQLコマンドを使用すると、指定されたクラウドストレージディレクトリからターゲットDeltaテーブルにすべてのデータをインクリメンタルにコピーすることができます。この方法は、以下のような条件で使用することができます:
- クラウドオブジェクトストレージに保存されているApache ParquetファイルからDelta Lakeテーブルの完全リフレッシュまたは増分リフレッシュのいずれかの要件がある場合。
- Delta Lakeテーブルへのインプレースアップグレードが不可能である。
- データの複製(ファイルの複数コピー)は可能です。
- 移行後のソースとターゲットの間で同じスキーマに準拠することは必須ではない
- データの埋め戻しが特に必要でない。
Auto LoaderとCOPY INTOのどちらも、データ移行プロセスを設定するための豊富なオプションが用意されています。COPY INTOとAuto Loaderのどちらかを選択する必要がある場合は、こちらのリンクを参照してください。
Batch Apache Spark job
最後に、カスタムApache Sparkロジックを使用してDelta Lakeに移行することができます。これは、ソースシステムから異なるデータを移行する方法とタイミングを制御する大きな柔軟性を提供しますが、ここで説明した他の方法論にすでに組み込まれている機能を提供するために、大規模な構成とカスタマ�イズが必要になる場合があります。
バックフィルや増分移行を行うには、データソースのパーティション構造に頼ることができるかもしれませんが、最後にソースからデータをロードしてからどのファイルが追加されたかを追跡するカスタムロジックを記述する必要があるかもしれません。Delta Lakeのマージ機能を使用すれば、重複したレコードの書き込みを避けることができますが、大きなParquetソーステーブルのすべてのレコードと大きなDeltaテーブルの内容を比較することは、複雑で計算量の多いタスクです。
Apache Parquet Data LakeをDelta Lakeに移行する方法論の詳細については、このlinkを参照してください。
まとめ
このブログでは、Apache Parquet Data LakeをDelta Lakeに移行するためのさまざまなオプションについて説明し、要件に基づいて正しい手法を決定する方法について説明しました。Apache ParquetからDelta Lakeへの移行の詳細と開始方法については、ガイド(AWS, Azure, GCP)を参照してください。このNotebooksでは、移行を開始し、さまざまなオプションを試すことができるように、いくつかの例を提供しています。また、Delta Lakeに移行した後は、Databricksの最適化ベストプラクティスに従うことを常に推奨します。

