オープンAPIを用いてUnity Catalogのアセットに外部から安全にアクセスする
さまざまな計算エンジン間でのシームレスな相互運用性

公開日: December 20, 2024
によって ラメシュ・チャンドラ、ジーシャン・パッパ、ミシェル・レオン、サチン タクール、Andrew Li、ヴィクトリア・ブクタ による投稿
Summary
- 資格情報の発行は、オープンソースAPIを通じて外部エンジンがUnity Catalogのアセット(テーブルなど)に安全にアクセスできるようにします。
- Apache Spark™、DuckDB、Daft、PuppyGraph、StarRocks、Spice AI、Microsoft Fabric、Salesforce Data Cloud、TrinoやDremioのようなIceberg RESTカタログエンジンなど、幅広いエンジンやツール間でのシームレスな相互運用性を促進します。
- 中央集権的なアクセス制御、権限管理の簡素化、そして高度なガバナンス機能の基礎となるビルディングブロックを提供します。
Unity CatalogのオープンAPI向けの資格情報の発行(クレデンシャルベンディング)のパブリックプレビューを発表できることを嬉しく思います。これにより、外部クライアントがオープンソースのUnity REST APIを通じてUnity Catalogの外部およびマネージドテーブルに安全にアクセスし、Iceberg REST Catalog APIを通じてUniForm対応テーブルにアクセスできるようになります。この機能は、Apache Spark™、DuckDB、Daft、PuppyGraph、StarRocks、Spice AI、Microsoft Fabric、Salesforce Data Cloud、Iceberg RESTカタログエンジンのようなTrinoやDremioなど、幅広いエンジンやツールとのシームレスな相互運用性を実現します。
データとAI資産のための業界唯一の統一されたオープンガバナンスソリューションとして、Unity Catalogは、現代のデータとAIスタック全体での相互運用性に焦点を当てて進化を続けてい��ます。このオープンなアプローチは、組織がデータとAIのユースケースに最適なソリューションを採用しつつ、ベンダーロックインを避けることを可能にします。オープンAPIのための資格情報の発行は、私たちの包括的なオープンソースのロードマップの重要な部分であり、Unity Catalogのオープンソース化の発表を2024年のData + AI Summitで行った後に続いています。資格情報の発行はまた、オープンソースのUnity Catalog 0.2リリースでも利用可能です。
任意のエンジンに対する統一されたガバナンスと資格情報の提供
資格情報の発行なしのガバナンスの課題
クラウド環境でのクエリ実行は、メタデータとデータの取得の両方に対して静的で広範なアクセスポリシーに依存し�ていたため、スケールアップが困難でした。Apache Spark™のようなクエリエンジンは、メタデータカタログへの広範なアクセスを許可され、クラウドストレージからデータを取得するためにクラウドストレージのアクセスポリシーに依存しています。例えば、ユーザーがクエリを実行するとき、エンジンはカタログからメタデータを、そしてAWS S3、Azure ADLS、GCSのようなクラウドストレージから実際のデータにアクセスする必要があります。管理者は通常、エンジンに対してメタデータカタログ(例えばHiveメタストア)への完全なアクセスを許可し、ユーザーの権限に基づいてエンジンがアクセスできるクラウドストレージの場所を定義するために、インスタンスプロファイル/マネージドサービスアイデンティティを作成します。これらのインスタンスプロファイルは、ユーザーレベルのアクセスを特定のデータストレージポリシーにマッピングします。
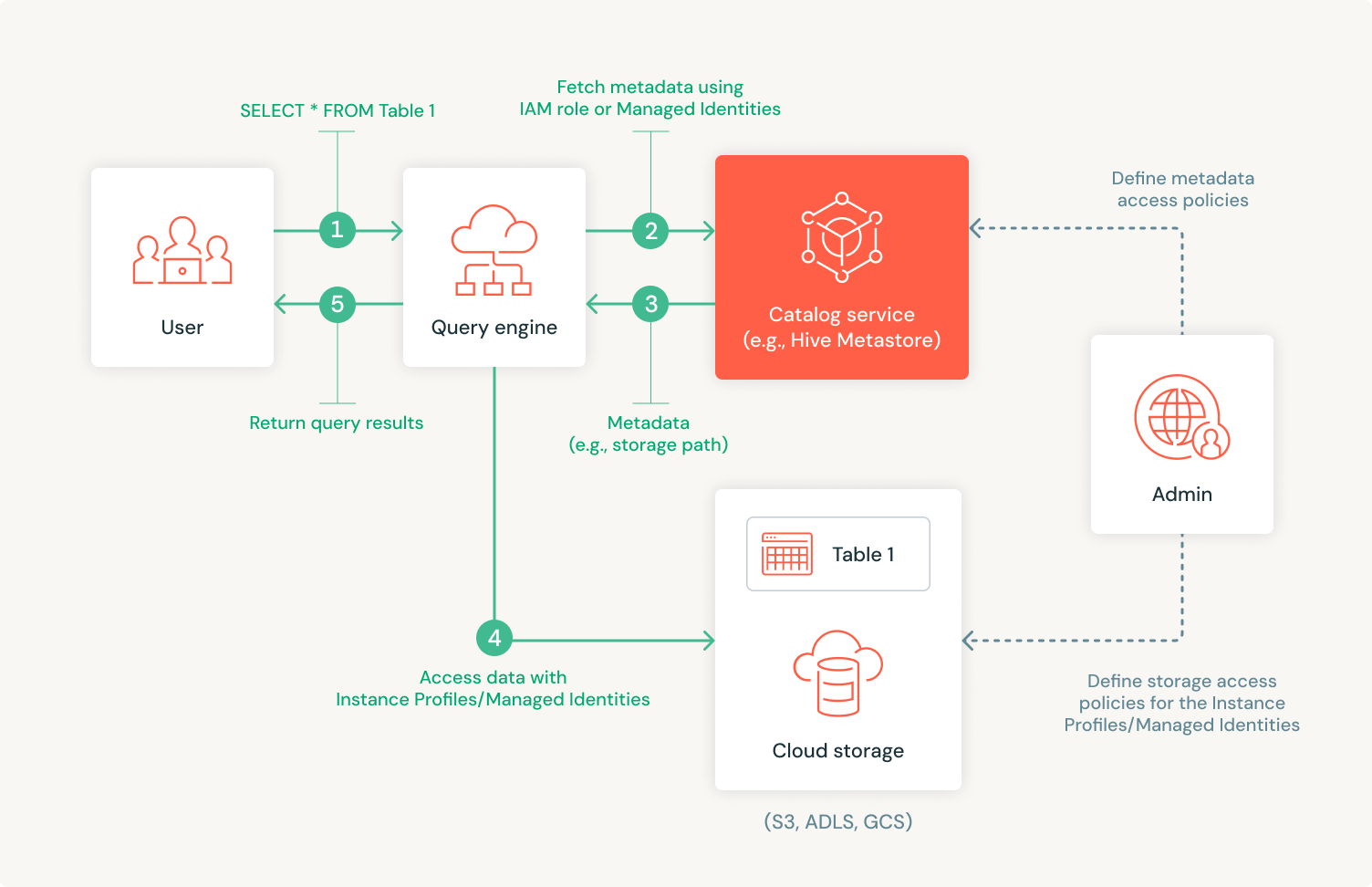
このモデルは、ユーザーやデータセットが少ない小規模な環境では機能しますが、数千人のユーザー、異なるツール/計算エンジン、数十万のデータオブジェクトを持つ大規模な組織にスケールアップすると問題が生じます。管理者はカタログとストレージの権限が同期していることを確認する必要がありますが、ユーザーやデータアセットの数が増えるとこれが難しくなることがあります。この静的なアプローチは、複雑さ、エラーの可能性、持続性の難しさが増すにつれて、効率性、セキュリティリスク、スケール時のガバナンスの課題を引き起こします。
資格情報の発行によるスケーラブルなガバナンス
資格情報の発行(クレデンシャルベンディング)は、カタログがデータ処理を行うエンジンに対して一時的にストレージへのアクセスを許可することを可能にします。これは、オンデマンドで生成される、時間制限のある、ダウンスコープされたストレージ資格情報を通じて行われます。これらの資格情報は、テーブルなどの上位レベルのオブジェクトに必要な特定のストレージに制限されます。カタログはメタデータとガバナンスの両方を管理します。つまり、カタログはすべてのデータに永続的にアクセスできますが、エンジンはジャストインタイムのアクセスしか取得できません。たとえば、エンジンがAWS S3上のパスに保存されている特定のテーブルにアクセスする必要がある場合、カタログはそのパスに限定された資格情報を生成し、エンジンに提供してアクセスを許可します。資格情報の発行は、AWSセッショントークンやAzure委任SASトー�クンなど、クラウドプロバイダーが提供するダウンスコープメカニズムを活用します。
主なメリット
- 一元化されたアクセス制御:カタログを通じてデータアクセス権限の一元管理を可能にし、各データソースごとにアクセス制御を別々に設定する必要がなくなります。
- 一時的で範囲指定されたアクセス:データへのアクセスに一時的で範囲を絞った資格情報を提供し、アクセストークンの有効期限と権限を制限することでセキュリティを強化します。
- 権限管理の簡素化:管理者は個々のストレージバケットポリシーやIAMロールを更新する必要はありません - 権限はカタログを通じて中央で管理することができます。
- 高度なガバナンス機能のための基盤:高レベルのアクセスポリシーを実装するための基本的な構成要素を提供します。これには、基本的なアクセス制御や、より高度なポリシー、例えば動的な性質を持つRBAC(ロールベースのアクセス制御)やABAC(属性ベースのアクセス制御)などが含まれます。
Unity Catalogで一度ポリシーを実装し、どこでも適用
資格情報の発行が外部クライアントの安全なアクセスをどのように可能にするか
Unity CatalogはオープンソースのREST APIを提供し、外部クライアントがテーブルなどのオブジェクトに安全にアクセスできるようにします。管理者は、Unity Catalogでこれらのオブジェクトのアクセスポリシーを定義することができ、Unity Catalogは永続的なストレージアクセスを保持します。外部のエンジン、例えばApache Spark™が、PATやOAuthトークンのようなUCの資格情報を使用してREST APIを通じてテーブルへのアクセスを要求すると、Unity Catalogはユーザーの特定のIAMロールやマネージドアイデンティティに基づいてストレージアクセスを制御するための一時的な資格情報とURLを発行し、データの取得とクエリの実行を可能にします。これにより管理が簡素化され、エンジンやツール間の相互運用性が向上し、RBACやABACのような高度なガバナンス機能への基盤を築くことができます。
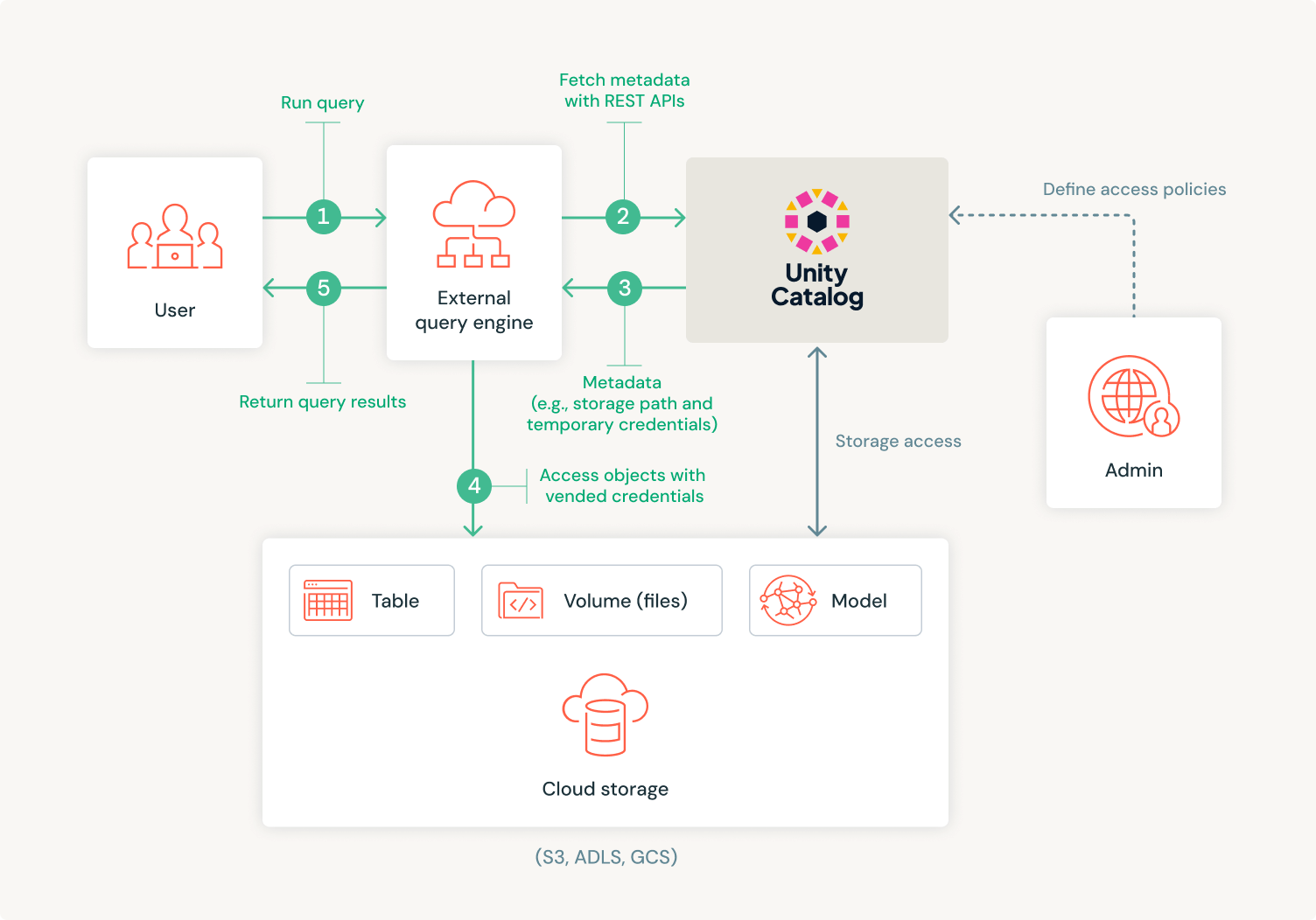
この機能は、Iceberg RESTカタログインターフェースを通じてUnity Catalogで管理されるIcebergテーブルにも拡張され、同じ一時的な資格情報の発行プロセスを利用してIcebergテーブルを読み取ることができます。Unity REST APIを通じて統合されたさまざまな外部エンジンのアクセシビリティを向上させることで、Apache Spark™、DuckDB、Daft、PuppyGraph、StarRocks、Spice AI、Microsoft Fabric、Salesforce Data Cloud、TrinoやDremioなどのIceberg RESTカタログエンジンを含む組織は、選択したツールを活用しつつ、プラットフォーム間で一貫した発見とガバナンスの経験を維持することができます。また、ボリューム(非構造化データ、任意のファイル)を含む他のUnity Catalog資産への資格情報の発行サポートを拡張する予定です。お楽しみに!
Apache Spark™とUnity Catalogでの実行の流れ
Unity CatalogのオープンAPIは、Apache Spark™のような外部クライアントが統一されたガバナンスでカタログと対話できるようにします。一時的な資格情報を提供することで、Deltaテーブルの作成、読み取り、書き込みなどの操作を実行することができます。これにより、ワークロードのIAM権限を確認したり、それを異なるシステム間で同期させる管理が不��要になります。
次の例は、AWS S3に保存されたテーブルにアクセスするためにDatabricks上のUnity Catalogに接続するためのSparkセッションの設定方法を示しています。
テーブルの読み取りアクセスは、カタログ/スキーマ/テーブルの権限によって管理されています。ユーザーは、テーブルを読み取るためにUSE CATALOG, USE SCHEMA, EXTERNAL USE SCHEMA, SELECTの権限が必要です。
テーブルを作成するには、ユーザーは外部ストレージの場所にCREATE EXTERNAL TABLE とカタログの権限USE CATALOG, USE SCHEMA and EXTERNAL USE SCHEMAが必要です。
同様に、Iceberg REST APIを通じてUnity CatalogからUniForm Icebergテーブルをクエリします。これにより、新たな依存関係を導入することなく、Iceberg RESTをサポートする任意のクライアントからこれらのテーブルにアクセスできます!
次のステップ
これは、あらゆるデータやAIアセット、あらゆる形式、あらゆるワークロード、そしてあらゆる計算エンジンやツールと互換性のある、オープンアクセスと統一されたガバナンスを提供するための、私たちの継続的なロードマップの始まりに過ぎません。資格情報の発行はガバナンスの強力な構成要素であり、ボリューム(非構造化データ、任意のファイル)への安全な外部アクセスをサポートするためのさらなるアップデートにご期待ください。

