ソリューション・アクセラレーターのご紹介: 製造業のためのLLM

翻訳:Saki Kitaoka. - Original Blog Link
GoogleのVaswaniらによるトランスフォーマーに関する画期的な論文(seminal paper on transformers by Vaswani et. al.)が発表されて以来、大規模言語モデル(LLM)は生成AIの分野を支配するようになりました。間違いなく、OpenAIのChatGPTの登場は、多くの必要な宣伝をもたらし、個人的な使用と企業のニーズを満たすものの両方で、LLMの使用に対する関心の高まりにつながりました。ここ数ヶ月の間に、GoogleはBardを、MetaはLlama 2モデルをリリースし、大手テクノロジー企業による激しい競争を示しました。
製造業やエネルギー産業では、運用コストの上昇に加え、より高い生産性を実現することが課題となっています。データ先進企業はAIに投資しており、最近ではLLMにも投資しています。要するに、データフォワード企業はこれらの投資から大きな価値を引き出しているのです。
DatabricksはAIテクノロジーの民主化を信じています。
私たちは、すべての企業がLLMを訓練する能力を与えられ、データとモデルを所有すべきだと信じています。製造業やエネルギー産業では、多くのプロセスが専有されており、これらのプロセスは、厳しい競争に直面している中で、リードを維持したり、営業利益率を改善したりするために不可欠です。秘密のソースは、特許や出版物を通じて一般に公開されるのではなく、企業秘密として秘匿することで保護されます。一般に入手可能なLLMの多くは、知識の明け渡しを必要とするこの基本要件に適合していません。
ユースケースという点では、この業界でしばしば生じる疑問は、より多くのアプリやデータを氾濫させることなく、いかにして現在の労働力を増強するかということです。そこには、労働力により多くのAIを搭載したアプリを構築し、提供するという課題があります。しかし、ジェネレーティブAIとLLMの台頭により、これらのLLMを搭載したアプリは、複数のアプリの依存性を減らし、知識を補強する機能をより少ないアプリに集約できると考えていま��す。
業界には、LLMの恩恵を受けられるユースケースがいくつかあります。これには以下が含まれますが、これらに限定されるものではありません:
- 顧客サポート担当者の強化:カスタマー・サポート・エージェントは、該当する顧客の未解決/未解決の問題を照会し、AIガイド付きのスクリプトを提供して顧客を支援できるようにしたいと考えています。
- 対話型トレーニングによるドメイン知識の獲得と普及:この業界は、しばしば「部族的」知識として表現される深いノウハウに支配されています。労働力の高齢化に伴い、このドメイン・ナレッジを永続的に捕捉することが課題となっています。LLMは知識の貯蔵庫として機能し、トレーニングのために容易に普及させることができます。
- フィールド・サービス・エンジニアの診断能力の強化:フィールド・サービス・エンジニアは、相互に絡み合った膨大なドキュメントへのアクセスにしばしば直面します。LLMがあれば、問題の診断にかかる時間を短縮することができ、結果的に効率を高めることができます。
このソリューション・アクセラレータでは、上記の項目(3)に焦点を当てます。これは、インタラクティブなコンテキスト認識Q/Aセッションの形で、フィールド・サービス・エンジニアを知識ベースで補強するユースケースです。メーカーが直面する課題は、独自のドキュメントからデータをどのように構築し、LLMに組み込むかという�ことです。LLMをゼロからトレーニングするのは非常にコストのかかる作業で、数百万ドルどころか数十万ドルもかかります。
その代わりに、MosaicMLのMPT-7B や MPT-30のような事前にトレーニングされたLLMモデルを利用し、自社独自のデータでこれらのモデルを補強し、微調整することができます。これにより、コストは数百ドルとは言わないまでも、数十ドルにまで下がり、実質的に10000倍のコスト削減になります。ファインチューニングへの全経路を左から右へ、Q/Aクエリへの経路を右から左へ示したのが下の図1です。
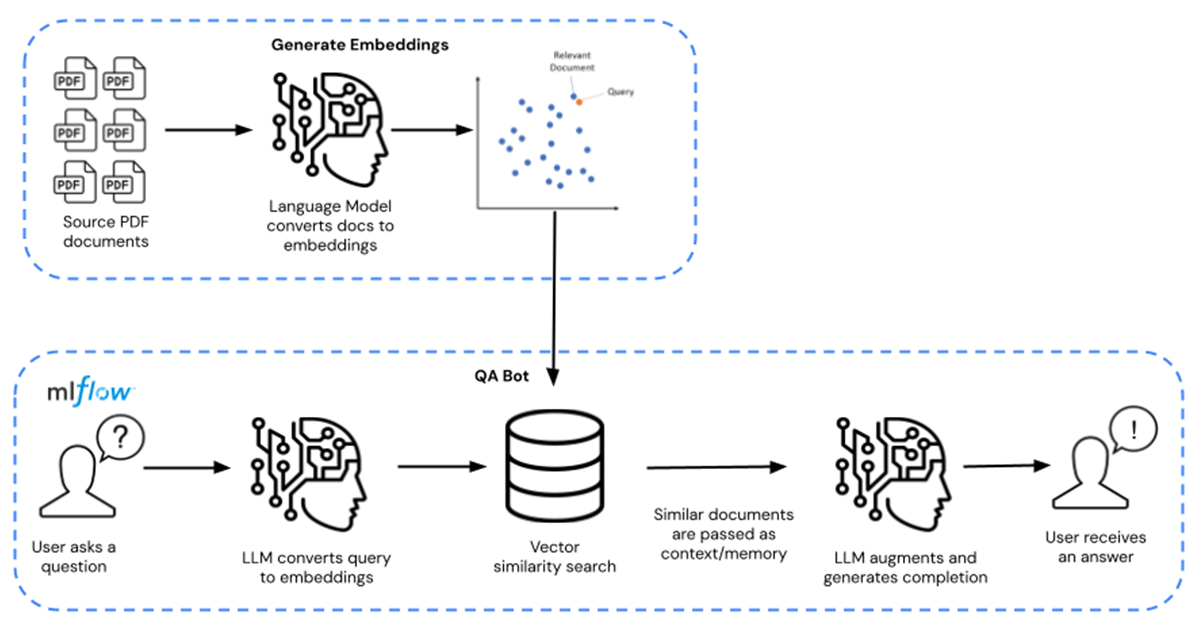
このソリューション・アクセラレータでは、LLMはPDF文書の形で配布される一般に入手可能な化学物質のファクトシートに追加されます。このファクトシートは、任意の独自データと置き換えることができます。ファクトシートはエンベッデ��ィングに変換され、モデルのリトリーバとして使用されます。次に Langchain を使用してモデルをコンパイルし、Databricks MLflow上でホストします。デプロイメントには、GPU推論機能を備えたDatabricks Model Servingエンドポイントを使用します。
これらのアセットをダウンロード( downloading these assets here)することで、今すぐエンタープライズを強化することができます。なぜDatabricksがLLMの構築と配信に最適なプラットフォームなのか、Databricksの担当者にご相談ください。
ソリューションアクセラレータについてはこちらをご覧ください。

