Apple HealthkitとDatabricksで健康やフィットネスの目標を追跡しよう
Health insights with Big Data

Original : Track health and fitness goals with Apple Healthkit and Databricks
翻訳:saki.kitaoka
データは、健康を含む私たちの生活の多くの側面を改善するために使用することができる強力なツールです。ウェアラブル・フィットネス・トラッカー、健康アプリ、その他のモニタリング・デバイスの普及により、私たちの健康に関するデータを収集し、分析することはかつてないほど容易になりました。これらのデータを追跡・分析することで、私たちは自分の健康とウェルネスに関する貴重な洞察を得ることができ、ライフスタイルや習慣についてより多くの情報に基づいた決定を下すことができるようになります。
健康機器を使えば、自分の健康状態を一元的に把握することができ、自分の健康について十分な情報を得た上で意思決定することができます。このブログでは、デバイスとそのデータを使って、さらに実用的なインサイトを提供する方法を紹介します。今回ご紹介する例では、Apple Healthkitを使って高度な分析と機械学習を行い、関連するKPIと指標を備えたダッシュボードを構築しています。その目的は、これらの指標で自分の週ごと、月ごとのパフォーマンスを追跡し、健康目標を監視して達成できるようにす��ることです。ブログの記事「"You Are What You Measure,"」に触発され、私の意図は、健康への道を測定することです!あなたもこの楽しさに加わってください(Github repo here)
データドリブン・フィットネス・ジャーニーの基礎となるもの
私たちの手元にあるデータ量は爆発的に増え、取得、変換、分析、可視化のためのツールは無数にあり、圧倒されがちです。レイクハウスアーキテクチャは、必要な機能をすべて1つのプラットフォームで利用できるようにすることで、データのユースケースを簡素化します。Databricks Lakehouse Platform - powered by Delta Lake - は、ワークフローとデータチームを統合するだけでなく、データウェアハウスレベルの機能(ACIDトランザクション、ガバナンス、パフォーマンスなど)を、データレイクのスケール、柔軟性、コストで利用できるようになります。
ダッシュボードとアナリティクスを強化するために、私たちはApple HealthKitを活用する予定です。しかし、さらに一歩進めるために、レイクハウスのフル活用も予定しています!Apache Spark、Databricks SQL、MLflowを組み合わせて、さらなるインサイト、集計、KPIトラッキングを抽出し、2023年を通して誠実な私を維持します。Delta Live Tablesを利用してストリーミングETLプロセスをオーケストレーションし、メタデータ駆動型ETLフレームワークを使用してデータ変換を行い、関連KPIを備えたダッシュボードを公開してデータ駆動型のアクションを行う方法を説明します!
このブログポストの次のセクションでは、次の方法を紹介します:
- 健康データをエクスポートする
- Delta Live Tablesを使用して、ストリーミングETLをオーケストレーションする
- メタデータ駆動型ETLフレームワークを使用して、データの分類と変換を行う
- 関連するKPIを含むダッシュボードを表示する。
- データドリブンなアクションを起こす
準備編
最初のステップは、データを利用できるようにすることです。Apple Healthkitのデータをエクスポートするには、付属のAPIやサードパーティアプリとの独自の統合を構築するなど、いくつかのオプションがあります。私たちが取るアプローチは、アプリから直接エクスポートすることで、HealthKitの公式ウェブサイトに記載されています。
以下の簡単な手順で、データをエクスポートしてください:
- Health Applicationに関連するデータがあることを確認します(歩数や心拍数など)。
- ヘルスデータをエクスポートし、お好みのクラウドストレージにアップロードします(私はGoogle Driveを使用しています)。
- Googleドライブにexport.zipファイルがあることを確認する。
ハイレベルアーキテクチャ
図1に示すように、データは可視化されるまでの間に色々な段階を経由することになります。データはオブジェクト・ストレージで利用できるようになったら、Medallionフレームワークで処理します。生のXMLを受け取り(ブロンズ)、異種のデータセットを分割し(シルバー)、関連するKPIを分、時、日単位で集約して、サービン��グ層(ゴールド)に提供します。
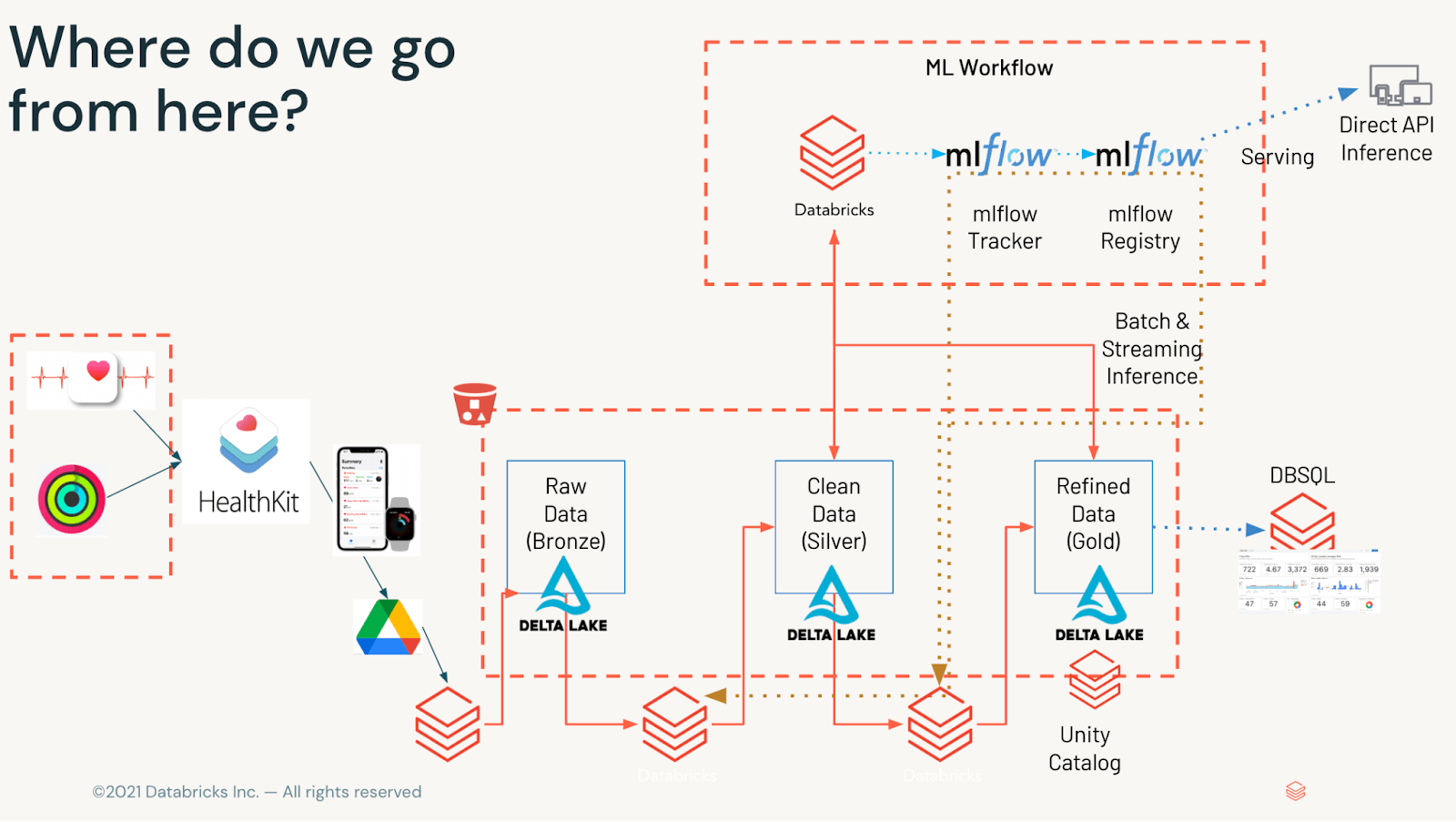
データの確認と共有
データが利用可能であることを確認するには、対象のGoogleドライブアカウント(またはエクスポートがアップロードされた場所)にログインし、ファイル名export.zipを見つけます。見つけたら、ファイルのアクセス権が「リンクを持つ人」になっていることを確認し、後で使用するためにリンクをコピーしてください。
データの取得と準備
データが利用できるようになったので、いよいよデータアクセス、ガバナンス、Databricksへの取り込みのためにノートブックをセットアップすることになります。最初のステップは、必要なライブラリのインストールとインポート、そして後のステップで抽出と変換を自動化するために再利用する変数のセットアップを行うことです。
データ取得には、Google Driveからのファイルダウンロードをシンプルかつ効率的に行うための小さなライブラリであるgDownを使用します。この時点では、Google Driveから共有リンクをコピーし、保存先フォルダを指定し、.zipアーカイブを/tmpディレクトリに展開すればよいのです。
export.zipの中身を探索すると、いくつかの興味深いデータセットが用意されています。これらのデータには、ワークアウトのルート(.gpx形式)、心電図(.csv形式)、HealthKitの記録(.xml形式)な�どがあります。私たちの目的では、Apple HealthKitの健康指標のほとんどを追跡するexport.xmlに集中しています。export.xmlに数百万のレコードが含まれている場合(私のように)、処理のためにApache Sparkドライバのサイズを大きくする必要があるかもしれないことに注意してください。参考までにGitHubをご参照ください。
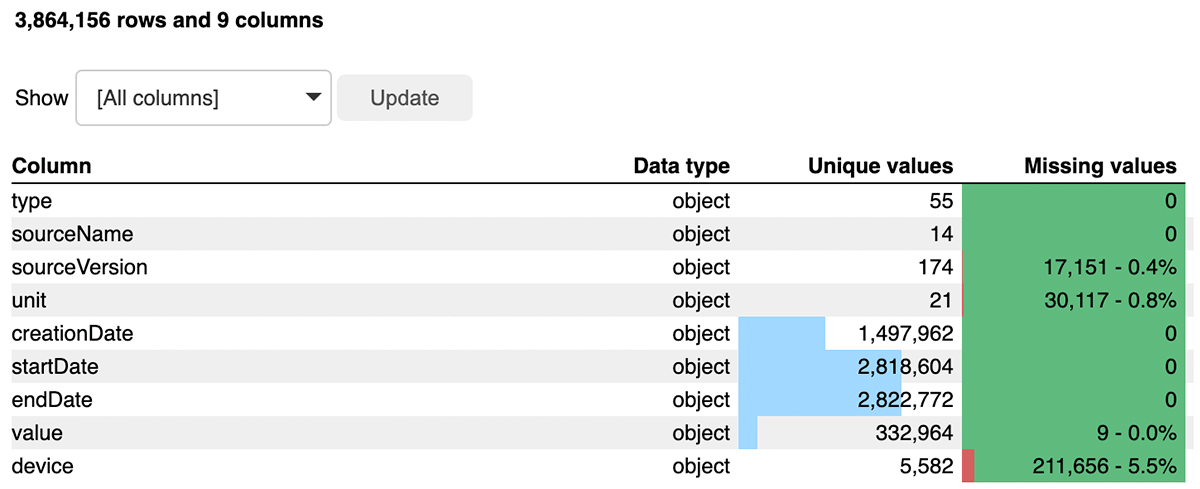
先に進む前に、Bamboolibを使用してデータフレームのクイックレビューを行います。これは、データを探索し、最小限のコードで変換を適用したり、データ型を変更したり、集計を実行するためのローコード/ノーコードのアプローチを提供します。これにより、データに対する大きな洞察を得ることができ、データ品質に関する懸念がある場合には警告を発することができます。EDAノートブックをチェックしてください。
図3からわかるように、export.xmlは55種類のデータからなる3.8M以上のレコードで構成されています。この調査を通じて、これは比較的きれいなデータセットであることがわかります。valueカラムには最小限のNULL値があり、これはカラムタイプに基づいたメトリクスを保存するために重要です。typeカラムは、睡眠トラッキングから1分あたりの心拍数まで、さまざまな利用可能なメトリクスで構成されています。
データの形や関係性を理解したところで、次は楽しい話に移ります!
エンタープライズ AI の可能性を最大化する機会と戦略

GOLD - Medallionフレームワークを目指せ!
よくよく考えてみると、このXMLはそれほど単純なものではありません。Bamboolibの分析によると、1つのXMLに含まれるものの、実際には55の異なるメトリクスが追跡されているのです。レイクハウスの登場です!レイクハウスでETL Medallionフレームワークを適用して、データレイクを管理し、データサイエンスやBIチームが下流で利用できるようにデータを処理する予定です。
このデータを�処理し、Deltaフォーマットに落とし込むことで、生データを保持したまま、メリットを享受し始めることができるのです。
ELTプロセスの一環として、私たちはDelta Live Tables(DLT)を活用し、データ処理を自動化・簡素化する予定です。DLTは、チェックポイントや自動スケーリングなどのストリーミング・パイプライン・タスク、期待値によるデータ検証タスク、パイプラインの観測性メトリクスなど、エンジニアリング・チームが手動で開発するような機能を自動化する宣言型フレームワークの利点を提供します。
データの探索と操作
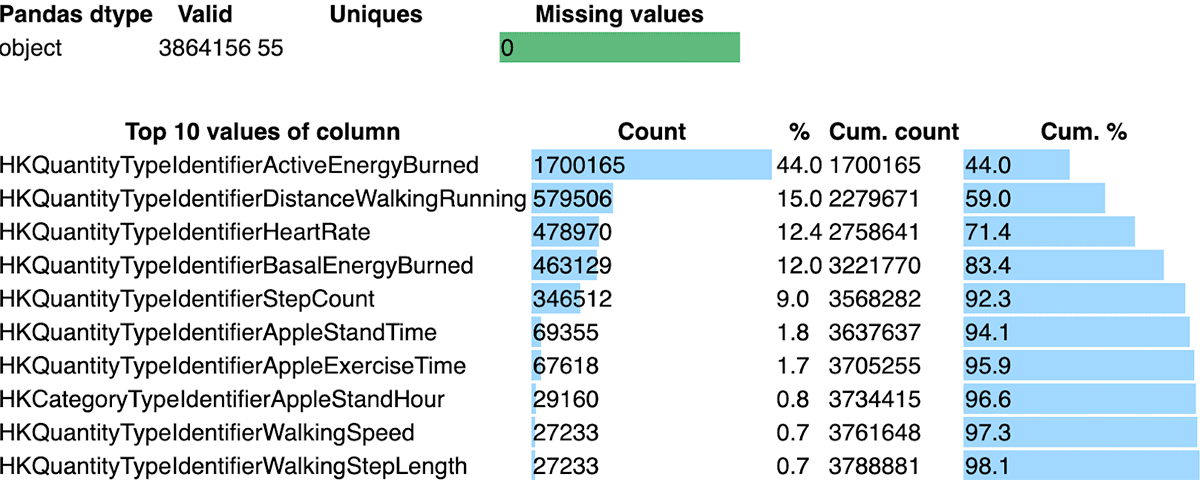
その後の分析は、ペイロードのデータを定義する「type」列をベースに行います。例えば、HeartRate型とActiveEnergyBurned型とでは、追跡されるメトリクスが異なります。以下のように、私たちのxmlファイルには、Apple healthKitによって追跡された55以上のメトリクス(少なくとも私の場合、YMMV)が含まれています。
これらのソースはそれぞれ、健康全般のさまざまな側面に関して、Apple HealthKitによって追跡される独自のメトリックを表しています。例えば、環境のデシベルレベルやワークアウトの緯度・経度から、心拍数や消費カロリーに至るまで、さまざまな測定値を取得します。ユニークな測定値に加えて、ワークアウトごと、1日ごと、1秒ごとの測定など、さまざまなタイムスケールが提供されます。
クリーンアップ!
パイプラインを通して、データ品質に関する問題を確実に追跡したい。先ほどの調査では、いくつかの値が不正に測定された可能性があるようでした(心拍数が200以上?) 幸いなことに、DLTは期待値とパイプラインメ��トリクスを用いて、データ品質の問題を管理できるようにします。DLTの期待値とは、イベントに期待する特定の条件(例えばIS NOT NULL OR x>5)であり、DLTはそれに対してアクションを起こすことができます。これらのアクションは、追跡のためだけのもの(「dlt.expect」)、あるいは、イベントのドロップ(「dlt.expect_or_drop」)、テーブル/パイプラインの失敗(「dlt.expect_or_fail」)などを含むことができる。DLTとExpectationsの詳細については、以下のページ(link)をご参照ください。
メタデータのFTW
上記のように、それぞれのタイプは、あなたの健康全般についてユニークな洞察を与えてくれます。55種類以上のタイプやメトリクスがあると、管理するのが大変な作業になります。特に、新しいメトリクスやデータソースがパイプラインに追加された場合はなおさらです。そこで、メタデータ駆動型のフレームワークを活用し、パイプラインをシンプルかつモジュール化します。
次のステップでは、10以上のユニークなソースを、特定のカラムと必要な変換を持つ個々のシルバーテーブルに配信し、データをMLとBIに対応させることにしました。ブロンズテーブルから特定の値を選択し、個々のシルバーテーブルに変換するために、異なるデータソース間での開発を簡素化し、スピードアップするメタデータ駆動型フレームワークを使用します。これらの変換は、ブロンズテーブルのtypeカラムに基づいて行われます。この例では、データ・ソースのサブセットを抽出しま�すが、メタデータ・テーブルは、新しいデータ・ソースが発生したときに、追加のメトリクスやテーブルを含めるように簡単に拡張できます。メタデータ・テーブルには、ソース名、テーブル名、カラム、期待値、コメントなど、DLTフレームワークを駆動するカラムが含まれています。

メタデータテーブルをDLTパイプラインに組み込むには、python APIで利用可能なループ機能を活用します。
SQLとPythonの機能を組み合わせることで、DLTは開発と変換のための非常に強力なフレームワークとなります。
Deltaテーブルをを読み込み、(ただし、Sparkがデータフレームに読み込めるものであれば何でもかまいません; repoのmetadata.jsonをご覧ください。)
table_iterator 関数を使用して、シルバーテーブルのメタデータ変数を抽出するためにループ処理を実行します。

このシンプルなコードの断片は、メタデータテーブルを伴って、ブロンズからデータを読み込み、10以上の下流のシルバーテーブルに抽出と固有のカ�ラムを提供します。このプロセスは「DLT_bronze2silver」ノートブックでさらに定義されており、銀テーブルのデータ取り込み(オートローダー)とメタデータ駆動の変換が含まれています。以下は、Apple HealthKitで利用可能なさまざまなソースに基づいて作成されたDLT DAGの一例です。
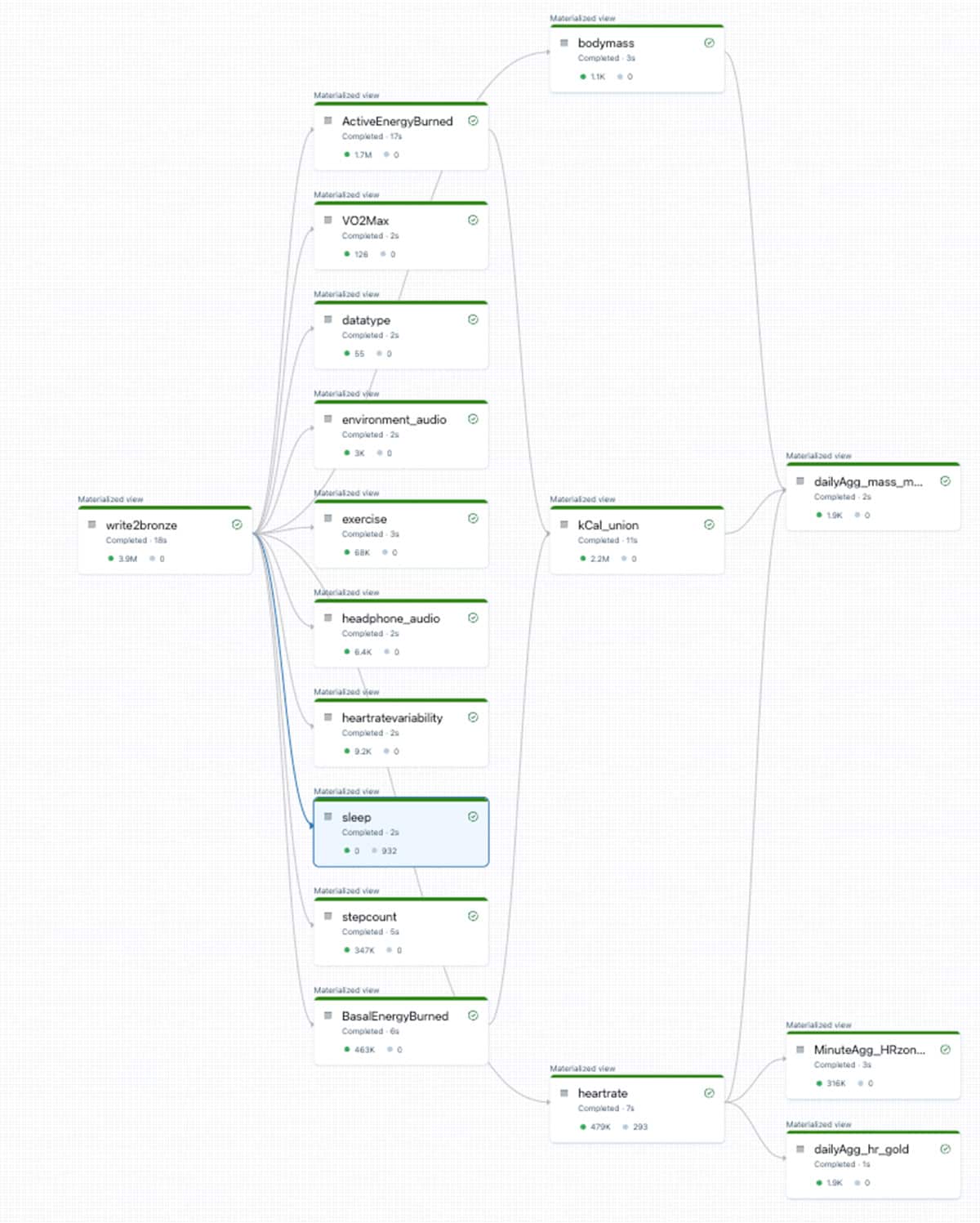
And clean datasets!

最後に、いくつかの興味深いデータセット(この場合、心拍数とワークアウト情報)を組み合わせます。そして、補助的なメトリクス(HeartRate Zonesなど)を作成し、分単位や日単位の集計を行い、下流の分析をより高性能で適切な消費にする。これは、レポの「DLT_AppleHealth_iterator_Gold」ノートブックでさらに定義されています。
データが利用可能になり、クリーンアップされたので、私たちの旅を追跡して視覚化するのに役立ついくつかのダッシュボードを構築することができます。今回は、Databricks SQLに含まれる機能を使って、ワークアウト時間、心拍変動、ワークアウトの努力、全体平均、短期および長期のトレンド�など、目標達成に役立つKPIを追跡するシンプルなダッシュボードを作成しました。もちろん、他のデータ可視化ツール(Power BIやTableauなど)に精通している場合は、Databricksを既存のワークフローに完全に統合することができます。
以下は、関連する指標を7日平均と30日平均で分割したシンプルなダッシュボードです。私は、KPIと時間のすべてを1つのダッシュボードで見ることができるのが気に入っています。これは、継続的な向上をめざして私の活動プログラムをガイドするのに役立ちます!
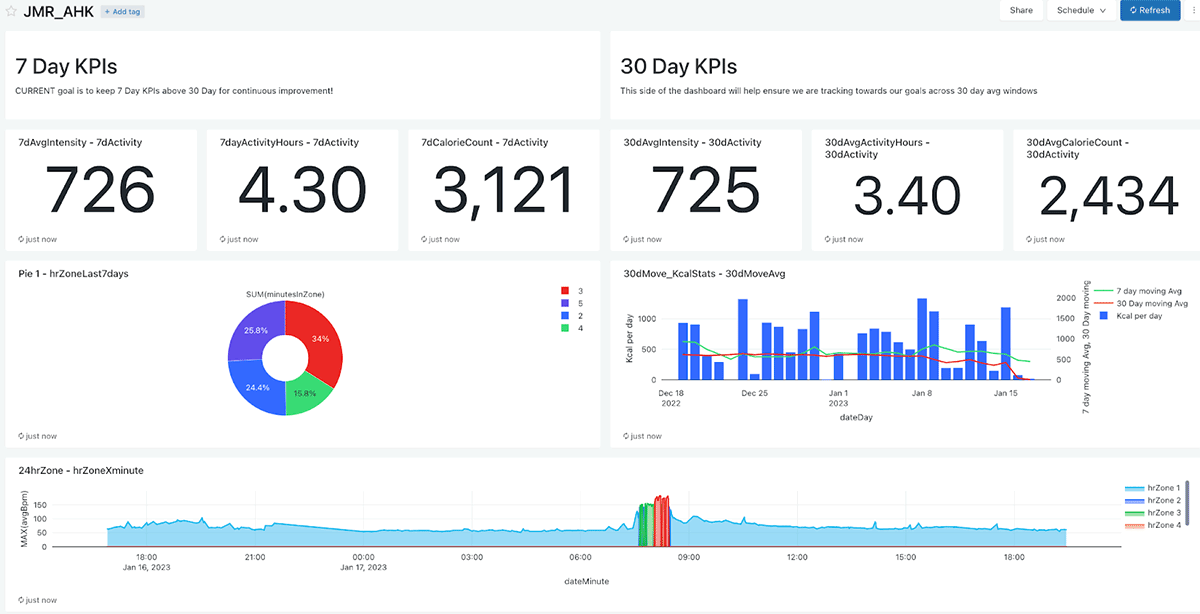
このような豊富なデータセットがあれば、MLを掘り下げて、健康のあらゆる指標を分析することもできます。私はデータサイエンティストではないので、autoMLの内蔵機能を活用して、いくつかの金と銀のテーブルに基づいて体重減少を予測しました!AutoMLは、モデルのトレーニング、ハイパーパラメータのチューニングの自動化、実験のトラッキングとモデルのServingのためのMLflowとの統合を、簡単で直感的な方法で提供します!

Summary
今回の実験で、Databricksとそのプラットフォームで利用可能な素晴らしい機能の一部を、簡単に紹介できたと思います。
今度はあなたが、データの力を活用して行動をポジティブに変えていく番です!さっそく実験(experiment)してみましょう。
