
{kind=link}
序章
4カ月前、AMDがジェネレーティブAIのための有能なプラットフォームとして登場し、AMD Instinct GPUを使用してLLMを簡単かつ効率的に訓練する方法を実証したことを紹介した。 今日、我々はヒットが続いていることに興奮している!
AMD GPUのコミュニティでの採用は拡大している:LaminiのようなAIスタートアップは、AMD MI210およびMI250システムを使用して、カスタムLLMの微調整とデプロイを行っており、Morehは1200個のAMD MI250 GPUを使用して、同社のプラットフォーム上で221Bのパラメータ言語モデルをトレーニングすることができた。 さらに、AI2のOLMoのようなオープンソースのLLMも、AMD GPUの大規模クラスタ上でトレーニングされている。
一方、AMDでは、ROCmソフトウェア・プラットフォームがバージョン5.4から5.7にアップグレードされ、FlashAttention用のROCmカーネルがFlashAttention-2にアップグレードされ、大幅な性能向上を実現した。
これと並行して、AMDはTritonコンパイラに多大な貢献をしており、MLエンジニアがカスタムカーネルを一度書くだけで、NVIDIAやAMDを含む複数のハードウェアプラットフォーム上で高いパフォーマンスを発揮できるようにしている。
最後に、MosaicML/Databricksでは、AMDアクセラレータクラウド(AAC)の一部として構築された新しいマルチノードMI250クラスタにいち早くアクセスすることができた。 この新しいクラスタには32ノードがあり、各ノードには4 xAMD Instinct™ MI250 GPUが搭載され、合計128 x MI250が搭載されている。 ノード間の高帯域幅800Gbpsインターコネクトを備えたこのクラスタは、AMDハードウェア上でLLMトレーニングを大規模にテストするのに最適です。
MI250 GPUでの初のマルチノード・トレーニングの結果を共有できることを嬉しく思います!
- ROCm5.7とFlashAttention-2を使用してMI250でLLMをトレーニングした場合、6月にROCm5.4とFlashAttentionを使用した結果と比較して、トレーニング性能が1.13倍向上した。
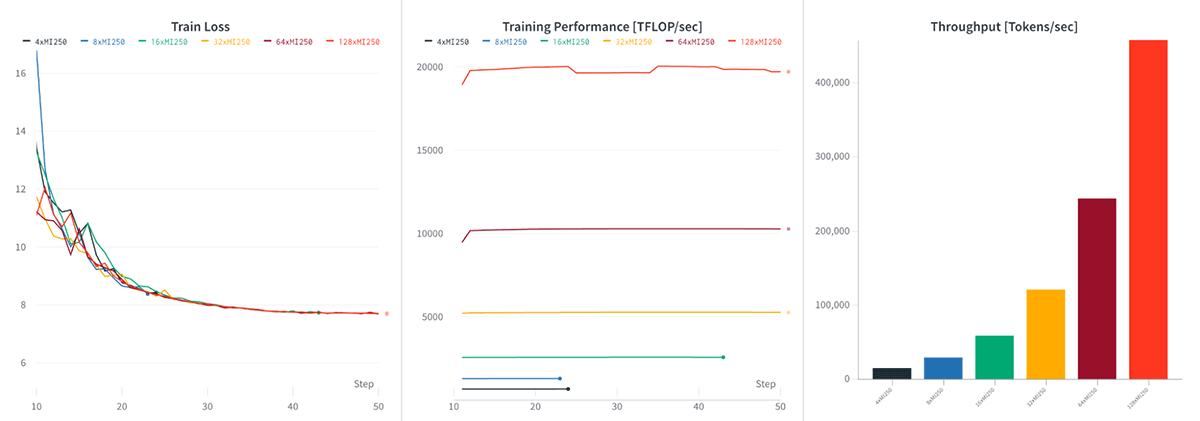
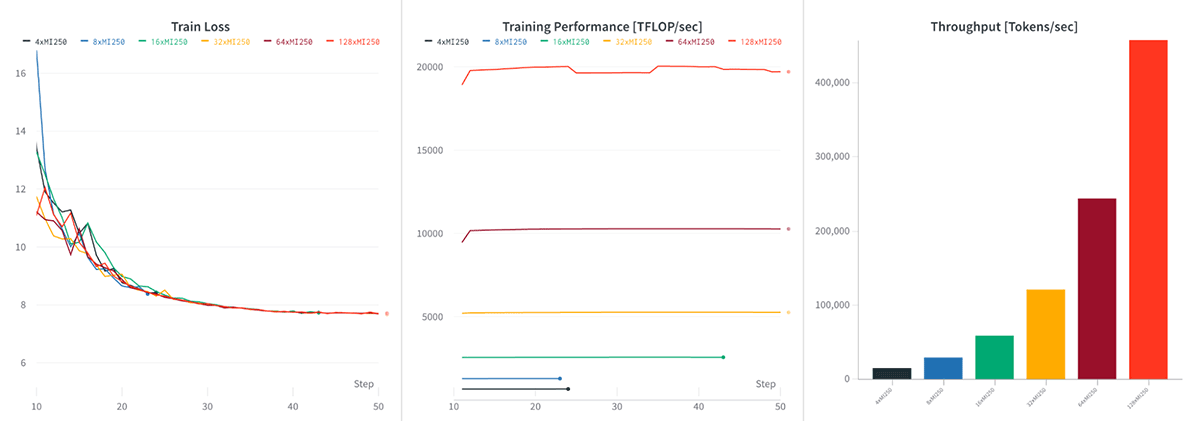
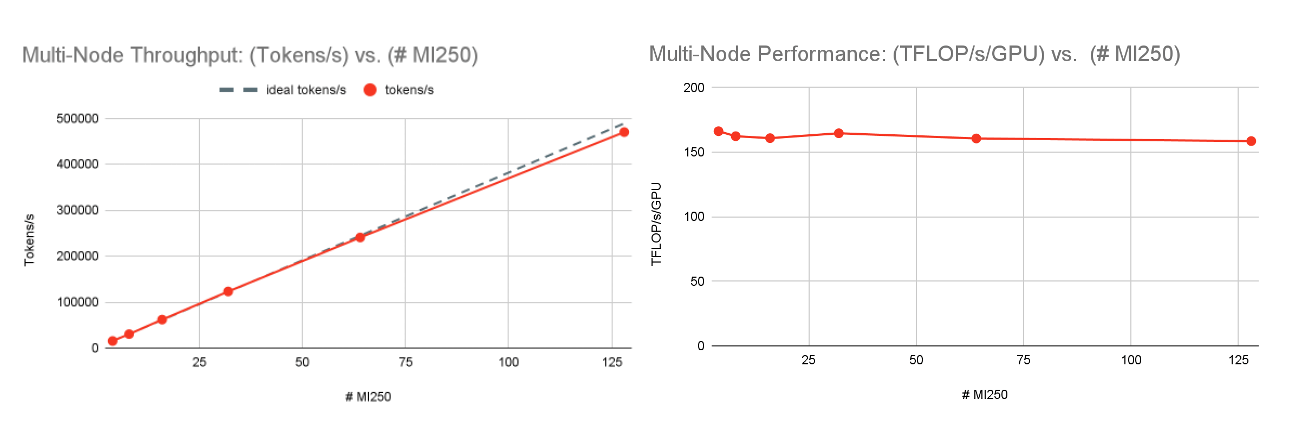
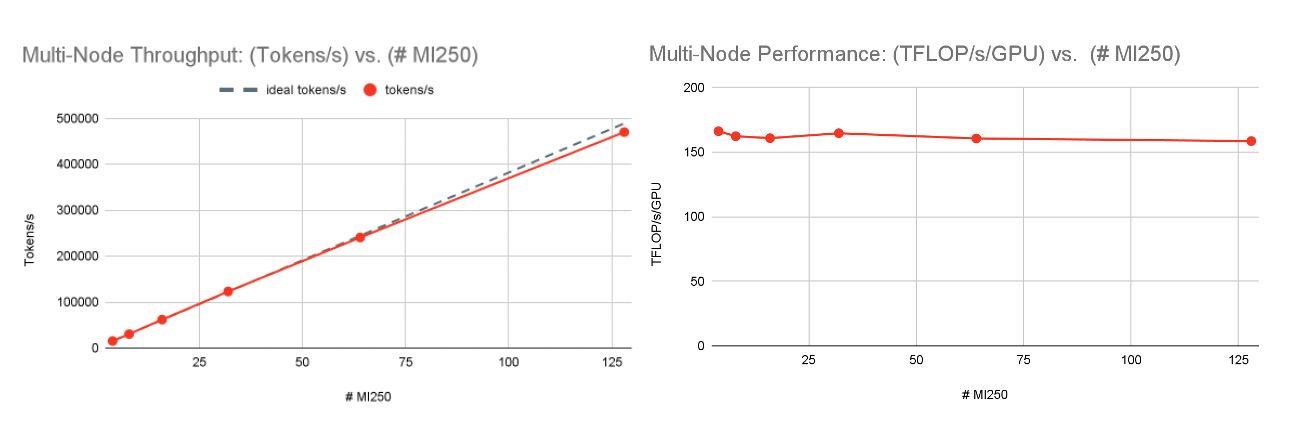
- AACでは、1ノード(4xMI250)で166TFLOP/s/GPU、32ノード(128xMI250)で159TFLOP/s/GPUと、グローバルトレインバッチサイズを一定にした場合、強力なスケーリングが見られました。
- 収束性をテストするために、1Bと3Bのパラメータを持つ2つのMPTモデルを、それぞれ64 x MI250 GPU上でチンチラ最適トークンバジェッ�トでゼロからトレーニングした。 トレーニングは安定しており、最終的なモデルの評価指標は、計算機でマッチングされたオープンソースモデル(Cerebras-GPT-1.3BおよびCerebras-GPT-2.7B)と同様であった。
前回同様、すべての結果は、 Composer 、 StreamingDataset 、 PyTorch FSDPを ベースに構築されたオープンソースのトレーニングライブラリ、 LLM Foundryを 使用して測定されています。PyTorchがCUDAとROCmの両方をサポートしているおかげで、コードを変更することなく、同じトレーニングスタックをNVIDIA GPUでもAMD GPUでも実行することができます。
次世代GPUであるAMD Instinct MI300Xを見据えて、我々のPyTorchベースのソフトウェアスタックがシームレスに動作し、うまくスケールし続けることを期待しています。 私たちはまた、カスタム・モデル・コードやカーネルの移植をさらに容易にするAMD + Tritonの可能性にも期待しています。 例えば、近いうちにNVIDIAとAMDの両方のシステムで同じFlashAttention-2 Tritonカーネルを使用できるようになり、ROCm専用のカーネルが不要になります。
AMDマルチノード・トレーニングの詳細については、こちらをお�読みください。また、AMD MI300Xを提供するかどうか、またはいつ提供するかについては、CSPにお尋ねください!
AMDプラットフォーム
AMDプラットフォームについてよくご存じない方のために、簡単に概要を説明しよう。 より深く掘り下げるには、AMDパート1のブログをご覧ください。
AMD MI250と(将来の)MI300Xは、NVIDIA A100とH100に似たデータセンター・アクセラレーターで、高帯域幅メモリー(HBM)と、高速行列乗算のためのNVIDIAのテンソル・コアに類似したマトリックス・コアを搭載している。 "世代内のGPUを比較する場合" 、MI250とA100を比較するのが最も適切で、MI300XはH100に似ている。 詳細は表1を参照のこと。
| AMD MI250 | NVIDIA A100-40GB | NVIDIA A100-80GB | AMD MI300X | NVIDIA H100-80GB | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| シングルカード | 4x MI250 | シングルカード | 8x A100-40GB | シングルカード | 8x A100-80GB | シングルカード | 8x MI300X | シングルカード | 8x H100-80GB | |
| FP16またはBF16 TFLOP/s | 362 TFLOP/s | 1448 TFLOP/s | 312 TFLOP/s | 2496 TFLOP/s | 312 TFLOP/s | 2496 TFLOP/s | N/A | N/A | 989.5 TFLOP/s | 7916 TFLOP/s |
| HBMメモリ(GB) | 128 GB | 512 GB | 40GB | 320 GB | 80GB | 640 GB | 192 GB | 1536 GB | 80GB | 640 GB |
| メモリ帯域幅 | 3277GB/秒 | 13.1TB/秒 | 1555 GB/秒 | 12.4TB/秒 | 2039GB/秒 | 16.3 TB/s | 5200 GB/秒 | 41.6 TB/s | 3350GB/秒 | 26.8 TB/s |
| ピーク消費電力 | 560W | 3000 W | 400W | 6500 W | 400W | 6500 W | N/A | N/A | 700 W | 10200 W |
| ラックユニット(RU) | N/A | 2U | N/A | 4U | N/A | 4U | N/A | N/A | N/A | 8U |
表1:NVIDIAとAMD GPUのハードウェアスペック。 なお、2023年10月現在、MI300Xのスペックは一部しか公表されていない。
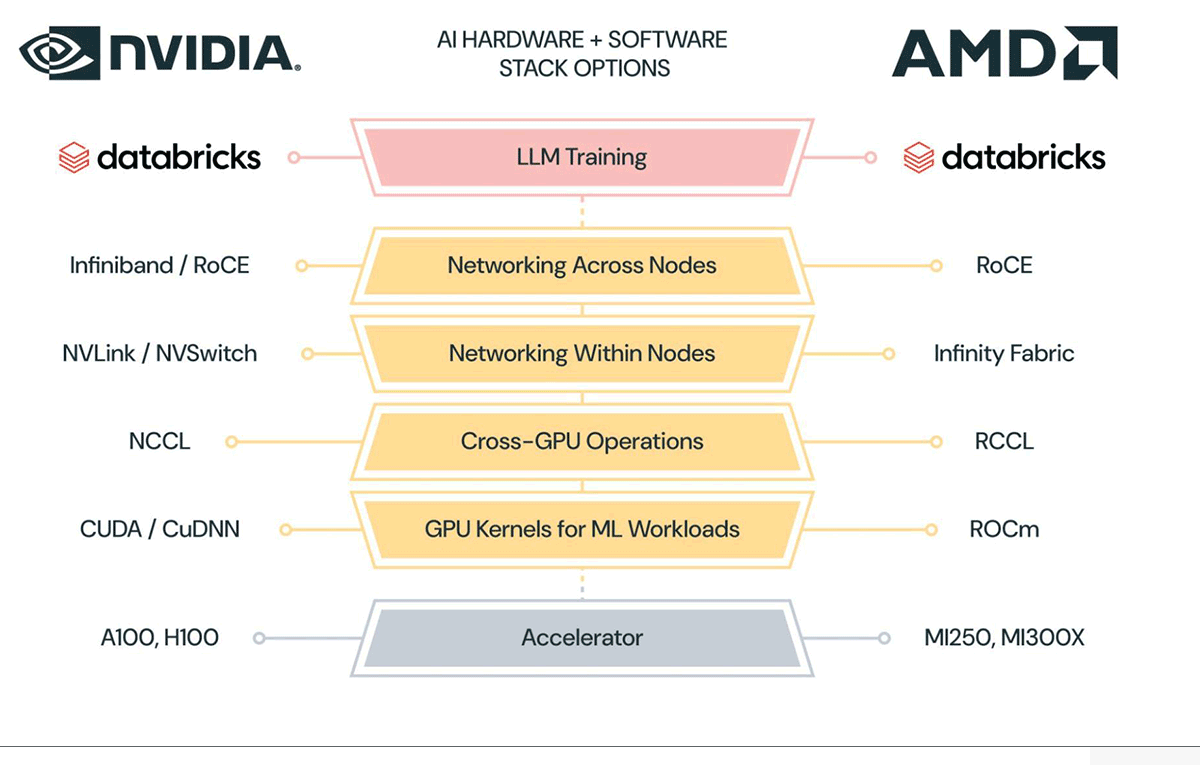
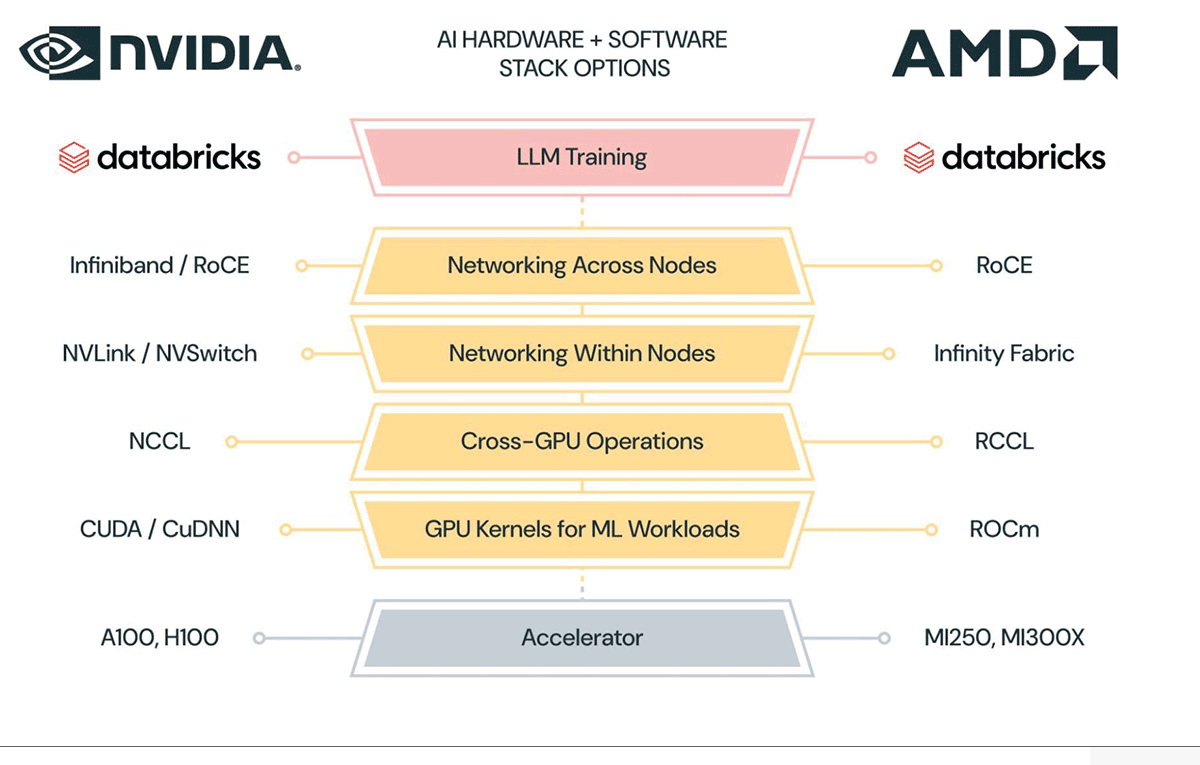
これらのアクセラレーターに加え、AMDはソフトウェアとネットワーキング・インフラを開発した:
- ROCmドライバ、ツール、高性能GPUカーネルのライブラリ。
- RCCL:Gather, scatter, reduceのような分散トレーニングに使用される高性能なクロスGPU操作のための通信ライブラリ。
- Infinity Fabric:ノード内の広帯域ネットワーキング。
- InfinibandまたはRoCE:ノード間の広帯域ネットワーキング。
スタックの各層で、AMDはソフトウェア・ライブラリ(ROCm、RCCL)やネットワーキング・インフラ(Infinity Fabric)を構築したり、既存のネットワーキング・インフラ(InfinibandやRoCE)を採用したりして、LLMトレーニングのようなワークロードをサポートしている。 NVIDIAのプラットフォームをご存じであれば、AMDのプラットフォームの多くのコンポーネントがNVIDIAのプラットフォームに直接マッピングされていることがおわかりいただけるでしょう。 横並びの比較は図2を参照。
{kind=link}
MLプログラマーに最も人気のあるライブラリの1つがPyTorchで、前回のブログで報告したように、PyTorchはMI250のようなAMD GPU上でイーガーモードでシームレスに動作する。 Fully-Sharded Data Parallelism (FSDP)のような高度な分散トレーニング技術であっても、すぐに動作するため、NVIDIA GPUで動作するPyTorchプログラム(LLM Foundryなど)があれば、AMD GPUでも動作する可能性が高い。 これは、PyTorchの内部で`torch.matmul(...)`のような演算子をCUDAカーネルまたはROCmカーネルにマッピングすることで可能になっている。
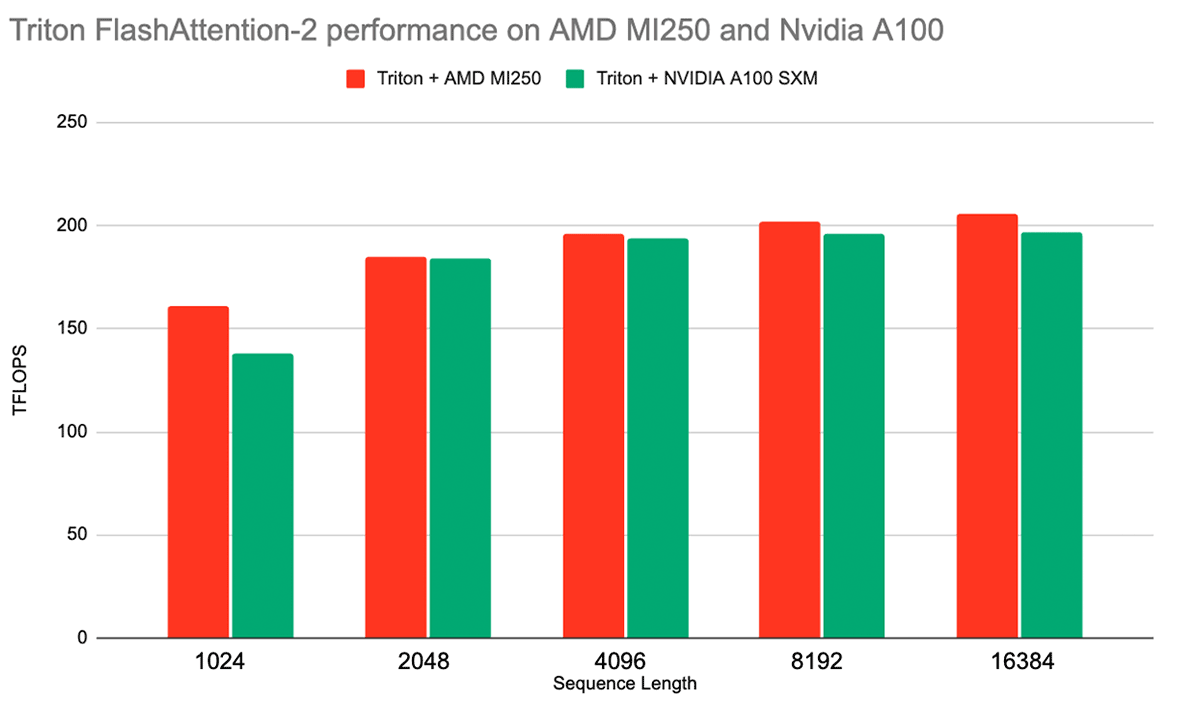
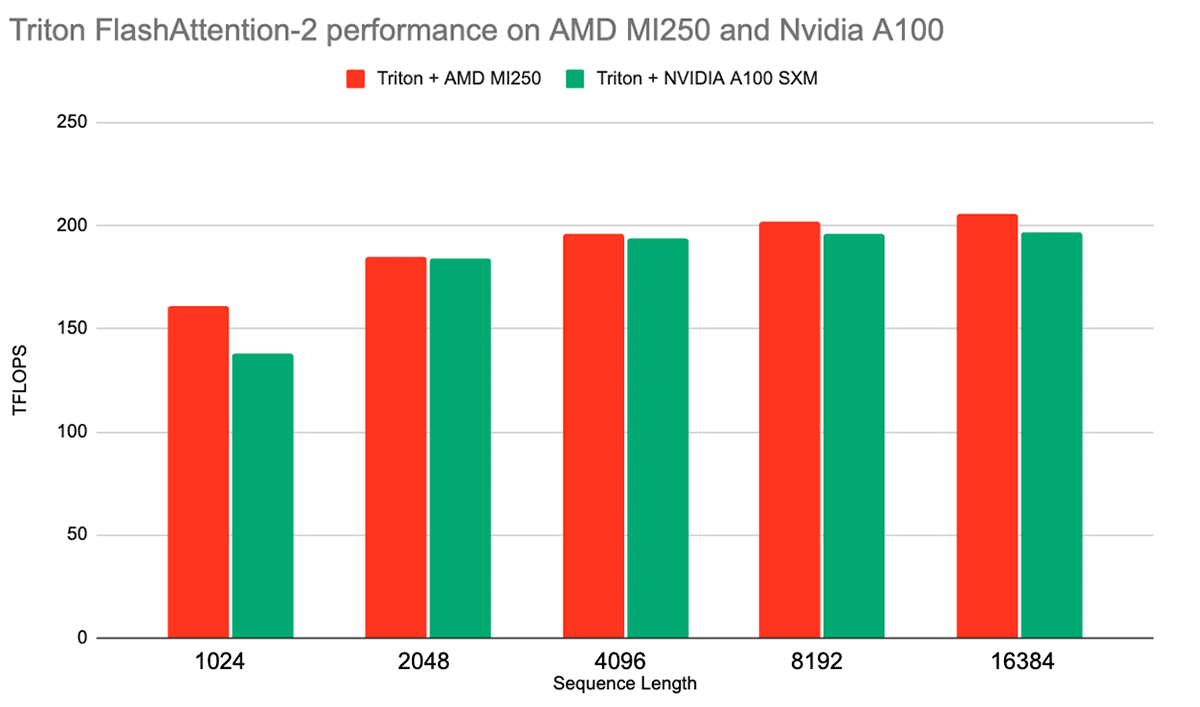
AMDプラットフォームのもう一つのエキサイティングなソフトウェア改良は、Tritonコンパイラーとの統合である。 TritonはPythonライクな言語であり、基礎となるプラットフォーム・アーキテクチャの大部分を抽象化しながら、パフォーマンスの高いGPUカーネルを書くことができる。 AMDはすでにTritonで、サードパーティのバックエンドとして同社のGPUをサポートしている。 また、FlashAttention-2のような様々なパフォーマンスが重要な演算のためのカーネルが、AMDプラットフォーム向けに、推論とトレーニングの両方で、競争力のあるパフォーマンスで提供されている(図3参照)。
{kind=link}
AMDがTritonをサポートすることで、同社のプラットフォームとNVIDIAのプラットフォーム間の相互運用性がさらに向上します。AMDとNVIDIAの両方のGPUでTritonベースのFlashAttention-2を使用するために、当社のLLM Foundryをアップグレードすることを楽しみにしています。 ROCmでのTritonサポートの詳細については、2023 Triton Developer ConferenceでのAMDのプレゼンテーションをご覧ください。
LLM研修の実績
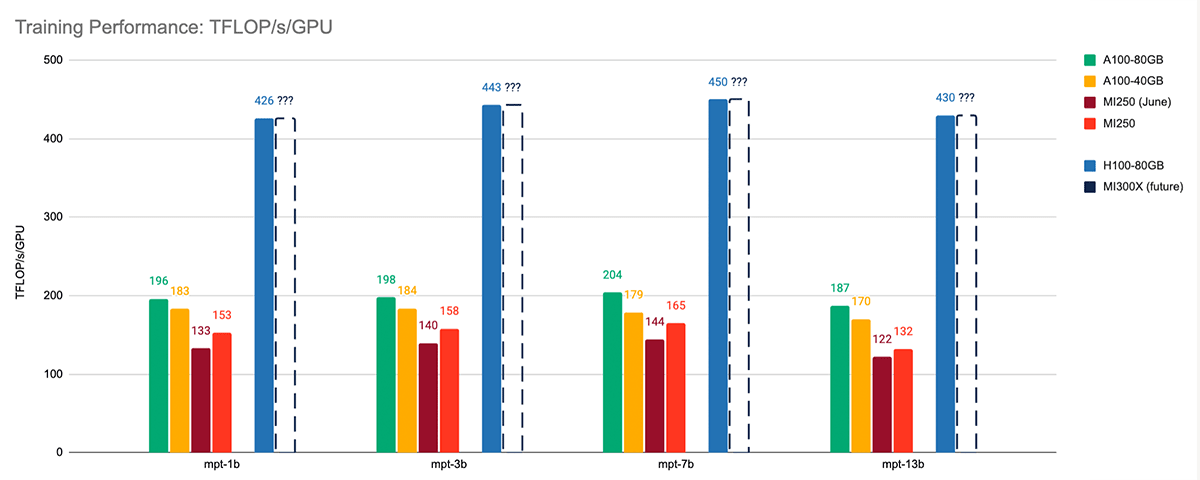
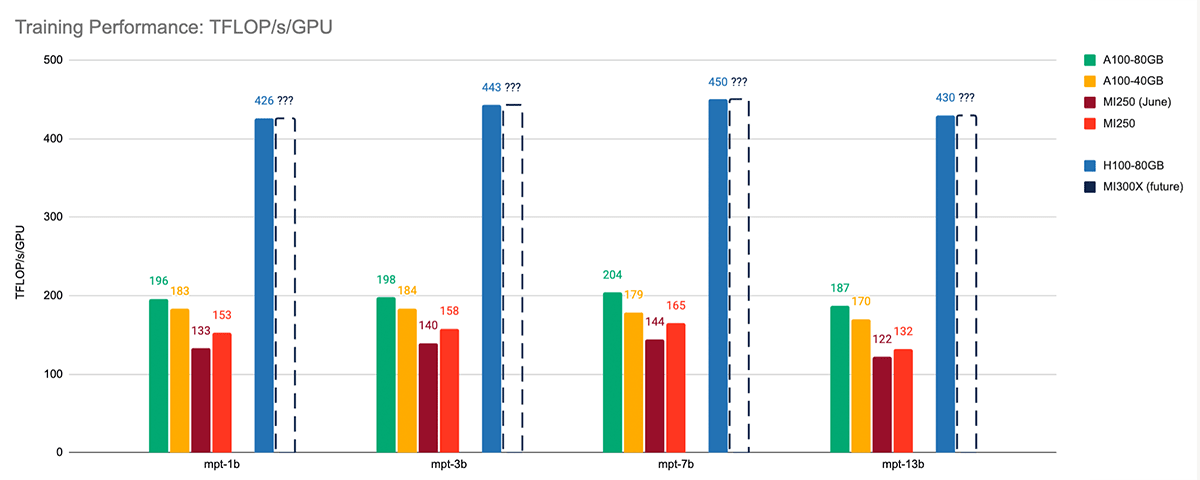
シングルノードのLLMトレーニング性能から見ると、ROCm 5.7 + FlashAttention-2は、以前のROCm 5.4 + FlashAttentionパッケージよりも大幅に高速である。 様々なサイズのMPTモデルをトレーニングしたところ、6月のトレーニング結果に対して平均1.13倍のスピードアップが見られた。 図4を参照。
各アクセラレータ上で、シーケンス長2048のMPTモデル、BF16混合精度、FlashAttention-2(NVIDIAシステムではTritonベース、AMDシステムではROCmベース)、PyTorch FSDP(sharding_strategy)を使用して、LLM Foundryの同じトレーニングスクリプトを実行しました:FULL_SHARD。 また、各システムで各モデルのマイクロバッチサイズをチューニングし、最大のパフォーマンスを達成した。 すべてのトレーニング性能測定は、ハードウェアFLOPsではなくモデルFLOPsを報告している。 詳しくはベンチマークREADMEをご覧ください。
MI250と同世代のA100を比較したところ、2つのアクセラレーターは同程度の性能を持っていることがわかった。 平均して、MI250のトレーニングパフォーマンスはA100-40GBの85%以内、A100-80GBの77%以内である。
AMD MI250を新しいNVIDIA H100-80GBと比較した場合、登るべき坂がかなりある。 しかし、H100-80GBのメモリ帯域幅3.35TB/秒に対して5.2TB/秒という次期MI300Xに関する公開情報によれば、MI300XはH100と非常に競争力があると予想される。
{kind=link}
マルチノードの性能に目を移すと、128 x MI250クラスタはLLMトレーニングにおいて優れたスケーリング性能を示した。 図5を参照。 1,2,4,8,16,32]ノードで固定グローバルバッチサイズサンプルでMPT-7Bモデルをトレーニングしたところ、1ノード(4xMI250)で166TFLOP/s/GPUから32ノード(128xMI250)で159TFLOP/s/GPUまで、ほぼ完璧なスケーリングを確認しました。 これは、FSDPパラメータ・シャーディングによるもので、スケールするにつれてGPUメモリが解放され、より大きなデバイス数でわずかに大きなマイクロバッチサイズが可能になる。
トレーニングの設定やパフォーマンスの測定方法の詳細については、LLM Foundryトレーニングのベンチマークページをご覧ください。
{kind=link}
これらの結果を踏まえると、我々は、より多くのデバイス数でのMI250の性能について非常に楽観的であり、将来、より大規模なMI250/MI300Xクラスタでのプロファイリングと結果の共有が待ち遠しい!
LLMコンバージェンス
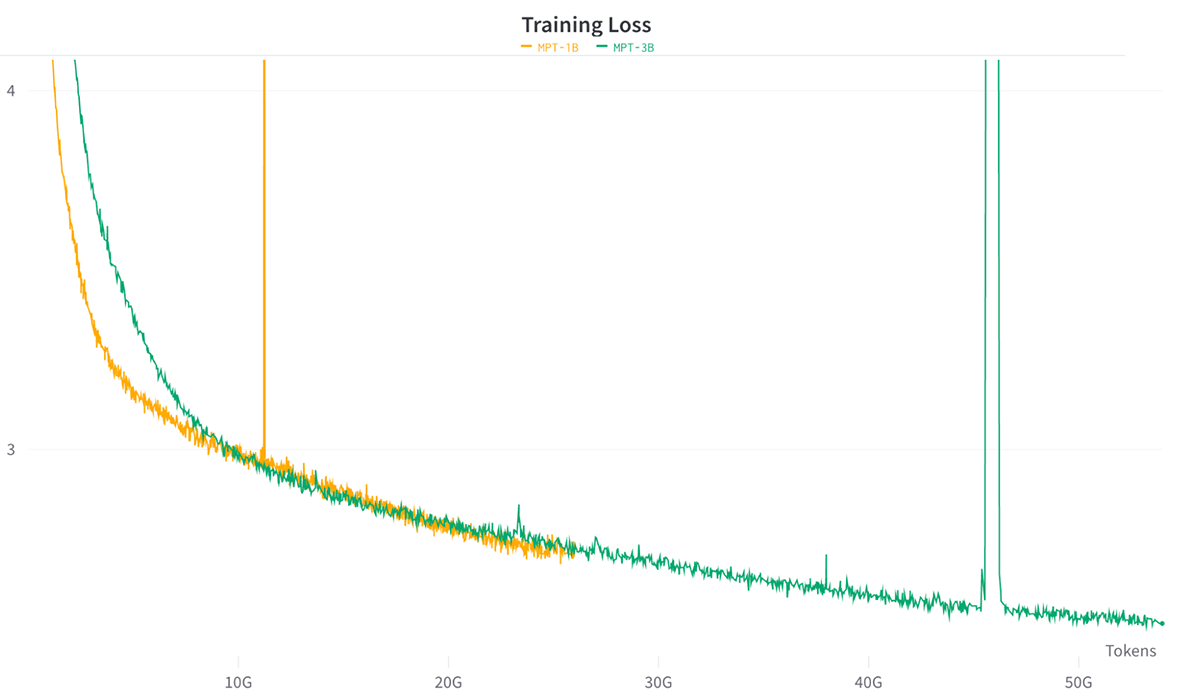
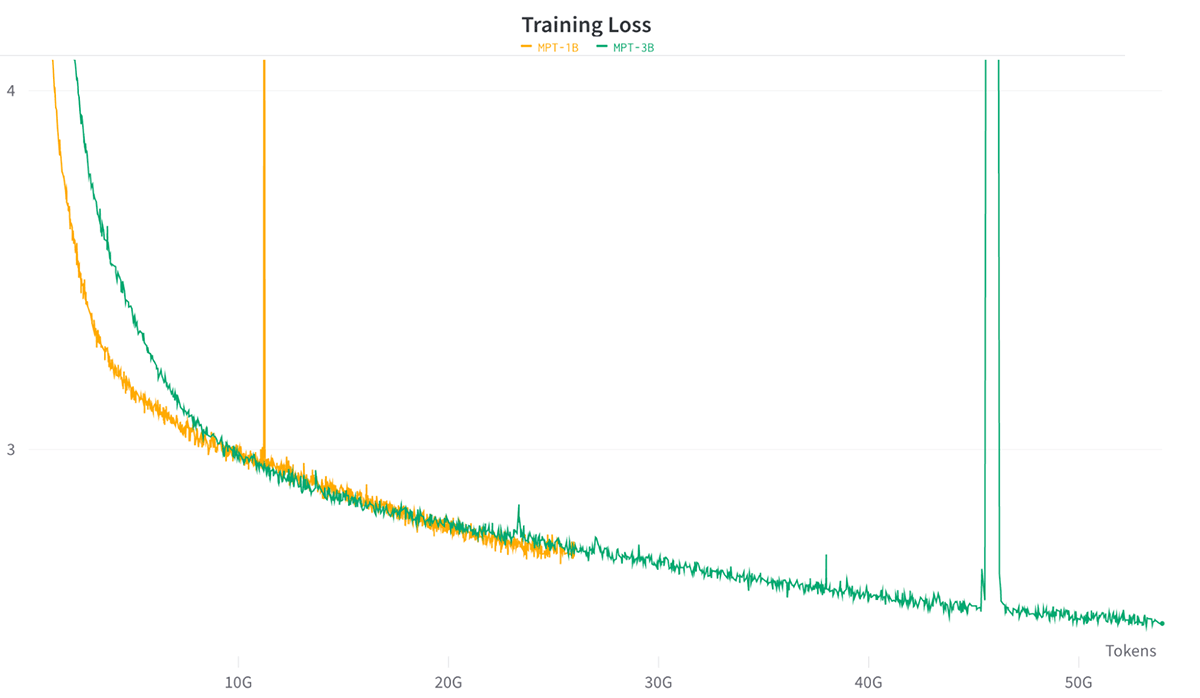
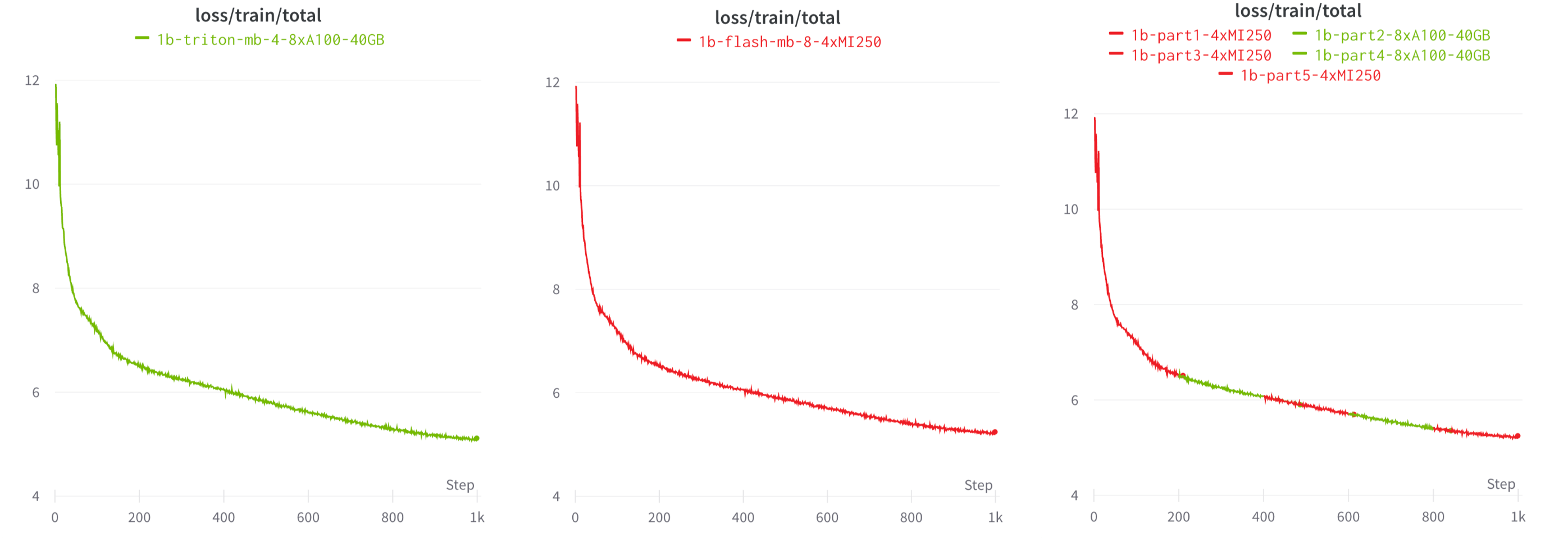
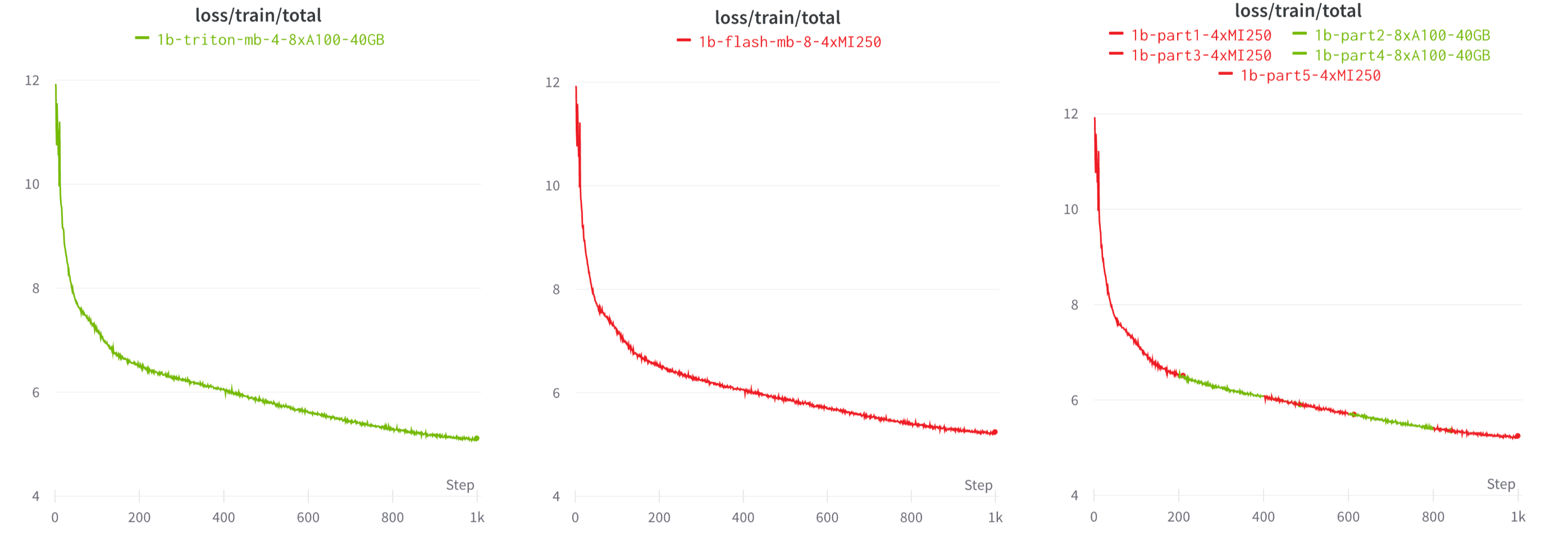
AMD MI250上でのトレーニングの安定性をテストするために、我々は、チンチラ最適トークンバジェットを使用して、C4データセット上でゼロからMPT-1BとMPT-3Bモデルをトレーニングすることにしました。
各モデルを64 x MI250でBF16混合精度とFSDPで学習させた。 全体として、トレーニングは安定しており、FSDP+分散チェックポイントは完璧に機能することがわかった(図6参照)。
最終モデルを標準的なICL(in-context-learning)ベンチマークで評価したところ、AMD MI250で学習させたMPT-1BおよびMPT-3Bモデルは、Cerebras-GPT-1.3BおよびCerebras-GPT-2.7Bと同様の結果を達成した。 これらは、同じパラメータ数とトークンバジェットで訓練されたオープンソースのモデルのペアであり、モデルの品質を直接比較することができる。 結果は表2を参照。 すべてのモデルは、LLM Foundryの評価ハーネスを使用し、同じプロンプトを使用して評価された。
これらの収束結果は、AMD上で高品質なLLMを訓練しても、他のハードウェア・プラットフォームと比較して、浮動小数点数値演算による大きな問題は生じないという確信につながります。
{kind=link}
| モデル | パラメーター | トークン | ARC-c | アークイー | ブールキュー | ヘラスワグ | PIQA | ウィノグラード | ウィノグランド | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|
| セレブラ-GPT-1.3B | 1.3B | 26B | .245 | .445 | .583 | .380 | .668 | .630 | .522 | .496 |
| AMD-MPT-1B | 1.3B | 26B | .254 | .453 | .585 | .516 | .724 | .692 | .536 | .537 |
| セレブラ-GPT-2.7B | 2.7B | 53B | .263 | .492 | .592 | .482 | .712 | .733 | .558 | .547 |
| AMD-MPT-3B | 2.7B | 53B | .281 | .516 | .528 | .608 | .754 | .751 | .607 | .578 |
表2:MPT-[1B, 3B]とCerebras-GPT-[1.3B]のトレーニング詳細と評価結果、 2.7B]. 両モデルのペアは、同様の構成で訓練され、標準的な文脈内学習(ICL)タスクで同様のゼロショット精度に達する。
次はどうする?
このブログでは、AMD MI250がマルチノードのLLMトレーニングにとって魅力的な選択肢であることを示した。 最初の結果では、128 x MI250までの強力な線形スケーリング、安定した収束、最近のソフトウェアの改良のおかげで、MI250はA100-40GBとの性能差を縮めている。
また、PyTorch、Triton、およびオープンソースライブラリ(Composer、StreamingDataset、LLM Foundryなど)の相互運用性のおかげで、ユーザーは同じLLMワークロードをNVIDIAでもAMDでも実行することができ、図7で示すように、プラットフォームを切り替えることもできます。
{kind=link}
AMD MI300Xとさらに大規模なトレーニングに関する今後のブログにご期待ください!