カスタムのテキストからSQL生成するアプリケーションで金融のインサイトを解き放つ!

Summary
Intercontinental Exchange (ICE)との共同作業により、ビジネスユーザーが最も価値のある資産である構造化データ(テーブル)から簡単に洞察を抽出できるようにする、構造化RAGアプリケーションの開拓に新たな地盤を築いています。このアプリケーションは、エンドユーザーがデータモデ��ル、スキーマ、またはSQLクエリを理解する必要性を排除します。これを達成するために、私たちはMosaic AI製品のフルスタック – Unity Catalog、Vector Search、Foundation Model APIs、およびModel Serving – を活用し、堅牢な評価を伴うRAGのエンドツーエンドのライフサイクルを実装しました。私たちは、最先端のテキストからSQLへのアプリケーションに対する広く認識されているSpider評価ベンチマークを、私たちのエンタープライズユースケースに合わせて適応させました。グラウンドトゥルースクエリとLLM生成クエリの間で構文マッチと実行マッチの指標を比較することにより、フューショット学習のための誤ったクエリを特定し、SQLクエリの出力品質を改善することができます。
序章
取得強化生成(RAG)は、大規模言語モデル(LLM)を使用して企業が非構造化知識ベースを活用する方法を革新し、その可能性は広範に影響を及ぼします。インターコンチネンタルエクスチェンジ(ICE)は、世界最大の証券取引所グループであるニューヨーク証券取引所(NYSE)を含む、取引所、クリアリングハウス、データサービス、住宅ローン技術を運営するグローバルな金融組織です。ICEは、既存のアプリケーションからのデータ移動を必要とせずに、構造化されたRAGパイプラインを持つことで、構造化データ製品の自然言語検索のシームレスなソリューション��を先駆的に開発しています。このソリューションは、エンドユーザーがデータモデル、スキーマ、またはSQLクエリを理解する必要性を排除します。
ICEチームはDatabricksエンジニアと協力して、Databricks Mosaic AI製品のフルスタック(Unity Catalog, Vector Search, Foundation Model APIs, and Model Serving)をフル活用し、堅牢な評価を伴うエンドツーエンドのRAGライフサイクルを実装しました。チームは、最先端のテキストからSQLへのアプリケーションに対する広く認識されているSpider評価ベンチマークを、自社のエンタープライズユースケースに合わせて適応しました。ICEは、正解クエリとLLM生成クエリの間の構文マッチと実行マッチのメトリクスを比較することで、フューショット学習のための誤ったクエリを特定し、SQLクエリ出力の品質を洗練しています。
このブログ投稿全体で示されているコードスニペットでは、機密性を保つために、合成データが参照されています。
ビッグピクチャーワークフロー

チームは、関連するテーブルと列の迅速な取得を可能にするために、テーブルメタデータのインデックス作成にベクトル検索を活用しました。 Foundation Model APIsはICEに大規模な言語モデル(LLMs)のスイートへのアクセスを提供し、開発中にさまざまなモデルでの実験をスムーズに行うことができました。
推論テーブルは、Agent Bricks AI Gatewayの一部として、すべての入力クエリと出力レスポンスを追跡するために使用されました。評価指標を計算するために、チームはLLMが生成したレスポンスと基準となるSQLクエリを比較しました。不正確なLLM生成クエリはその後、クエリサンプルテーブルにストリーミングされ、フューショット学習に貴重なデータを提供しました。
このクローズドループアプローチは、テキストからSQLへのシステムの継続的な改善を可能にし、進化するSQLクエリへの洗練と適応を可能にします。このシステムは、YAMLファイルを通じて簡単に調整可能なコンポーネント設定を持つように設計されています。このモジュラリティは、システムが適応性を保ち、将来的に最良のソリューションと統合できるようにすることを保証します。
ICEとDatabricksがこのテキストからSQLへのシステムを構築するためにどのように協力したかについて、詳しくは以下をご覧ください。
RAGの設定
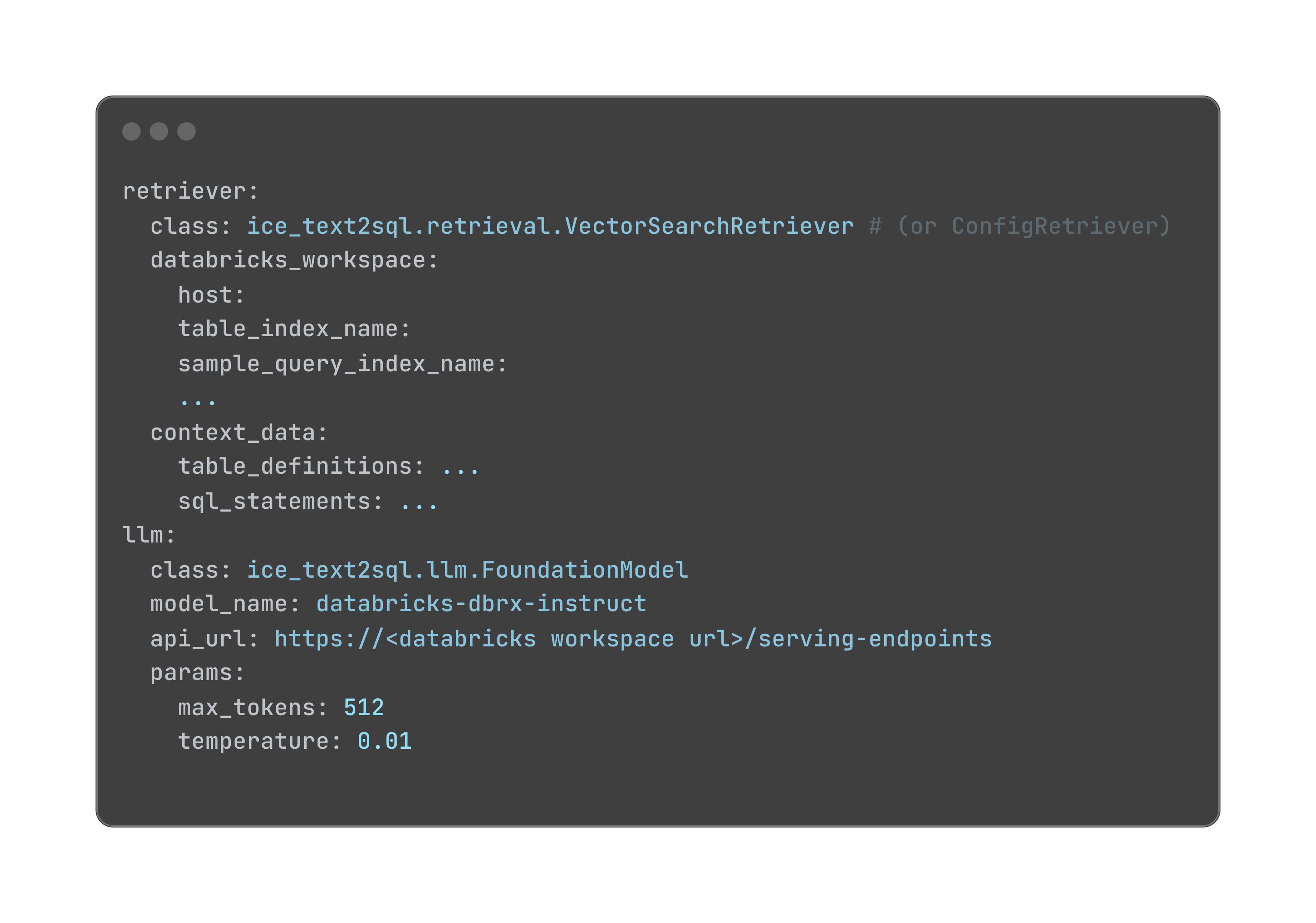
自然言語入力から正確なSQLクエリを生成するために、私たちはプロンプトでフューショット学習を使用しました。さらに、関連するコンテキスト(テーブルDDL、サンプルデータ、サンプルクエリ)を��使用して入力質問を補強し、2つの特化したリトリーバーを使用しました:ConfigRetriever と VectorSearchRetriever。
ConfigRetrieverは、YAML設定ファイルからコンテキストを読み取り、ユーザーがUnity Catalogでテーブルとベクトルインデックスを作成する必要なく、異なるテーブル定義とサンプルクエリを素早く試すことができます。このリトリーバーは、テキストからSQLへのシステムをテストし、洗練するための柔軟で軽量な方法を提供します。以下はYAML設定ファイルの例です:
VectorSearchRetriever は、2つのメタデータテーブルからコンテキストを読み取ります: table_definitions と sample_queries。これらのテーブルには、データベーススキーマとサンプルクエリに関する詳細な情報が格納されており、ベクトル検索を使用してインデックス化され、関連するコンテキストの効率的な取得を可能にします。 VectorSearchRetrieverを活用することで、テキストからSQLへのシステムは、クエリ生成に役立つ豊富なコンテキスト情報を引き出すことができます。
メタデータテーブル
テーブルとクエリに関する情報を保存するための2つのメタデータテーブルを作成しました:
table_definitions:table_definitionsテーブルは、データベース内のテーブルに関するメタデータを保存しています。これには、列名、列のタイプ、列の説明/コメント、テーブルの説明が含まれます。
テーブルのコメント/説明は、COMMENT ON TABLEを使用してデルタテーブルで定義することができます。個々の列のコメント/説明は、ALTER TABLE {table_name} ALTER COLUMN {column} COMMENT \”{comment}\”を使用して定義することができます。テーブルDDLは、SHOW CREATE TABLEコマンドを使用してデルタテーブルから抽出することができます。これらのテーブルレベルと列レベルの説明は、GitHubを使用して追跡およびバージョン管理されています。
table_definitionsテーブルは、ベクターサーチを介したテーブルデータ定義言語(DDL)によってインデックス化され、関連するテーブルメタデータの効率的な取得が可能になります。
sample_queries:sample_queriesテーブルは、テキストからSQLへのシステムの出発点となる質問と対応するSQLクエリのペアを保存します。このテーブルは、事前に定義された質問-SQLペアのセットで初期化されます。
ランタイム時に、質問とLLMによって生成されたSQL文は推論テーブルに記録されます。レスポンスの精度を向上させるために、ユーザーは基準となるSQLを提供でき、これはLLMによって生成されたSQLの評価に利用されます。不正確なクエリはsample_queriesテーブルに取り込まれます。これらの不正確なクエリの基準となる情報は、関連する今後のクエリのコンテキストとして利用できます。
Mosaic AI ベクトル検索
関連するコンテキストを効率的に取得するために、ベクトル検索を使用してメタデータテーブルの両方をインデックス化し、類似性検索を介してクエリに基づいて最も関連性の高いテーブルを取得しました。
コンテキストの取得
質問が提出されると、埋め込みベクトルが作成され、table_definitionsおよびsample_queriesテーブルのベクトルインデックスと照合されます。これにより、次のコンテキストが取得されます:
- 関連するテーブルDDL:入力質問に関連するテーブルのテーブルDDLとカラムの説明(コメント)を取得します。
- サンプルデータ: Unity Catalogから関連する各テーブルのいくつかのサンプルデータ��行を読み取り、データの具体的な例を提供します。
- 例の質問-SQLペア:私たちは、sample_queriesテーブルから入力質問に関連するいくつかの例の質問-SQLペアを抽出します。
プロンプトの拡張
取得したコンテキストは、入力質問を補完するために使用され、LLMに対して関連するテーブル、データ、クエリの豊かな理解を提供するプロンプトを作成します。プロンプトには以下が含まれます:
- 入力質問
- 関連するテーブルのDDLとカラムの説明
- 関連する各テーブルのサンプルデータ
- 例:質問-SQLペア
以下は、取得したコンテキストで補強されたプロンプトの例です:

拡張されたプロンプトは、選択したLLM、例えば、Llama3.1-70Bに送信されます。ファンデーションモデルAPIを通じて。LLMは提供されたコンテキストに基づいてレスポンスを生成し、その中から私たちは正規表現を使用してSQLステートメントを抽出します。
モダンアナリティクスへのコンパクトガイド

評価
人気のある Spiderベンチマークを適応させ、私たちのテキストからSQLへのシステムのパフォーマンスを包括的に評価しました。 SQL文は、同一の結果を生み出しながらも、さまざまな構文的に正しい形式で書くことができます。この柔軟性を考慮に入れるため、私たちは2つの補完的な評価アプローチを採用しました:
- 構文的一致:生成されたSQLステートメントの構造と構文を、基準となるクエリと比較します。
- 実行マッチング:生成されたSQL文が実行されたときに、基準となるクエリと同じ結果を生み出すかどうかを評価します。
Spider評価フレームワークとの互換性を確保するため、生成されたLLMのレスポンスを前処理して、その形式と構造を標準化しました。このステップでは、SQLステートメントを評価フレームワークの期待する入力形式に合わせて修正します。例えば:

初期の応答を生成した後、生成されたテキストからSQL文を抽出するための後処理関数を適用しました。この重要なステップでは、SQLクエリを周囲のテキストやメタデータから分離し、正確な評価と真実のSQL文との比較を可能にします。
この効率的な評価と処理のアプローチは、2つの重要な利点を提供します:
- これにより、大規模なデータセットでの評価が容�易になり、推論テーブルから直接オンラインで評価することが可能になります。
- これにより、生成された応答にスコアを割り当てるために通常は恣意的に人間が定義した採点ルーブリックに依存するLLMを判断役として関与する必要がなくなります。
これらのプロセスを自動化することで、私たちのテキストからSQLへのシステムのパフォーマンスを一貫して、客観的に、かつスケーラブルに評価することを確保し、継続的な改善と洗練の道を開きます。このブログ記事の後半で、評価プロセスの詳細を提供します。
構文的一致
生成したSQLクエリの構文的な正確さを評価するために、コンポーネントの一致と正確な一致の評価のためのF1スコアを計算しました。以下に詳細を記載します:
- コンポーネントマッチング:この指標は、SELECT、WHERE、GROUP BYなどの個々のSQLコンポーネントの精度を評価します。予測は、コンポーネントのセットが提供された地上真実のステートメントと完全に一致する場合に正しいと見なされます。
- 完全一致:これは、予測されたSQLクエリ全体がゴールドクエリと一致するかどうかを測定します。予測は、すべてのコンポーネントが正しい場合にのみ正しいとされ、順序に関係なく、これによりSELECT col2, col2はSELECT col2, col1と同じように評価されます。
この評価では、地上真実のSQLステートメントを持つ48のクエリがあります。SpiderはSQL Hardness Criteriaを実装しており、クエリを簡単、中程度、難しい、非常に難しいの4つの難易度レベルに分類します。クエリは、簡単なものが0、中程度のものが36、難しいものが7、非常に難しいものが5ありました。このカテゴリー化は、クエリの難易度の異なるレベルでのモデルのパフォーマンスを分析するのに役立ちます。
構文マッチングのための前処理
構文マッチングメトリクスを計算する前に、テーブルスキーマがSpiderの形式に準拠していることを確認しました。Spiderでは、テーブル名、列名、列タイプはすべて個別のリストで定義され、それらはインデックスによってリンクされています。以下はテーブル定義の例です:

各列名は、それが属するテーブルと列名のタプルです。テーブルは、そのテーブルがtable_namesリスト内のインデックスで表される整数です。列の型は列名と同じ順序です。
もう一つの注意点は、テーブルエイリアスは as キーワードで定義する必要があるということです。選択節の列エイリアスはサポートされておらず、評価前に削除されます。真実地と予測からのSQL文は、評価を実行する前に特定の要件に従って前処理されます。
実行マッチング
構文的な一致に加えて、生成されたSQLクエリの精度を評価するために実行一致を実装しました。同じデータセット上で正解のSQLクエリとLLM生成のSQLクエリを実行し、以下のメトリクスを使用して結果のデータフレームを比較しました:
- 行数:各クエリによって返される行の数。
- コンテンツ:各クエリによって返される実際のデータ値。
- 列のタイプ: 各クエリによって返さ��れる列のデータタイプ。
要約すると、この二本柱の評価戦略は、構文的一致と実行一致の両方を含めることで、私たちのテキストからSQLへのシステムのパフォーマンスを堅牢かつ決定的に評価することを可能にしました。生成されたクエリの構文的正確さと機能的等価性の両方を分析することで、私たちのシステムの能力について包括的な洞察を得ることができました。このアプローチは、システムの強みをより微妙に理解するだけでなく、改善のための特定のエリアを特定するのにも役立ち、テキストからSQLへの解決策の継続的な洗練を促進しました。
継続的改善
私たちのテキストからSQLへのシステムのパフォーマンスを効果的に監視するために、モデルサービング内の推論テーブル機能を活用しました。推論テーブルは継続的にサービングリクエストの入力(ユーザーが提出した質問)とレスポンス(LLMが生成した回答)をMosaic AIモデルサービングエンドポイントから取り込みます。すべての質問と回答を一つの推論テーブルにまとめることで、監視と診断のプロセスを簡素化しました。この一元化されたアプローチにより、LLMの動作のトレンドとパターンを検出することができます。推論テーブルから抽出した生成されたSQLクエリを、モデルのパフォーマンスを評価するための基準となる真実のSQLステートメントと比較します。
グラウンドトゥルースのSQLを作成するために、推論テーブルからユーザーの質問を抽出し、テーブルを.csvファイルとしてダウンロードし、それをLabel Studioというオープンソースのラベリングツールにインポートしました。専門家はStudioでグラウンドトゥルースのSQL文を追加でき、そのデータはDatabricksの入力テーブルとして再度インポートされ、テーブルキーdatabricks_requests_idを使用して推論テーブルとマージされます。
次に、上記で説明した構文マッチング方法と実行マッチング方法を使用して、予測を地上真実のSQLステートメントと比較評価しました。不正確なクエリは検出され、sample_queries テーブルに記録されます。このプロセスにより、不正確なSQLクエリを特定し、それらのクエリをフューショット学習に使用する連続ループが可能になります。これにより、モデルは自身の誤りから学習し、時間とともにパフォーマンスを向上させることができます。このクローズドループアプローチにより、モデルは常に学習し、変化するユーザーのニーズとクエリパターンに適応していきます。
モデルの提供
このテキストからSQLへのアプリケーションをPythonライブラリと�して実装することを選択しました。これは完全にモジュール式で設定可能で、取得ツール、LLM名、推論パラメータなどの設定可能なコンポーネントは、YAML設定ファイルに基づいて動的にロードでき、アプリケーションの簡単なカスタマイズと拡張が可能です。基本的なConfigRetrieverは、YAML設定でハードコーディングされたコンテキストに基づいて素早くテストするために利用できます。本番レベルのデプロイメントでは、VectorSearchRetrieverを使用して、Databricks LakehouseからテーブルのDDL、サンプルクエリ、データを動的に取得します。
このアプリケーションをPython .whlとしてデプロイしましたファイルをUnity Catalog Volumeにアップロードし、モデルの依存関係としてログに記録できます。その後、このモデルをModel Servingエンドポイントを使用してシームレスに提供することができます。MLflowモデルからクエリを呼び出すためのコードスニペットは次のとおりです:

影響と結論
たった5週間で、DatabricksとICEチームは、非技術的なビジネスユーザーの質問に対する答え��を驚くほど正確に提供する堅牢なテキストからSQLへのシステムを開発することができました:約50のクエリに対して、77%の構文的正確さと96%の実行一致率を達成しました。この達成は、2つの重要な洞察を強調しています:
- テーブルや列の詳細なメタデータを提供することは非常に重要です
- 質問-応答ペアとSQLステートメントの評価セットを準備することは、反復的な開発プロセスを指導する上で重要です。
Databricks Data Intelligence Platformの包括的な機能、データストレージとガバナンス(Unity Catalog)、最先端のLLMクエリ(Foundation Model APIs)、シームレスなアプリケーションデプロイメント(Model Serving)は、多様なツールスタックの統合に通常関連する技術的な複雑さを排除しました。この効率的なアプローチにより、数週間で高品質なアプリケーションを提供することができました。
結果的に、DatabricksプラットフォームはICEによる生の金融データから行動可能な洞察への旅を加速させ、彼らのデータ駆動型の意思決定プロセスを革新しました。
このブログ記事は、Anand Pradhanが率いるNYSE/ICE AIセンターオブエクセレンスチームとの共同作業で書かれました。その他のメンバーには、Suresh Koppisetti(AIおよび機械学習技術のディレクター)、Meenakshi Venkatasubramanian(リードデータサイエンティスト)、Lavanya Mallapragada(データサイエンティスト)がいます。